基于MongoDB的地名信息管理
2014-08-05段丽娟亢晓琛
刘 亚,段丽娟,亢晓琛,孙 镇,赵 捷
(1.北京中诚盛源技术发展有限公司,北京 100020;2.武汉大学,湖北武汉 430079;3.中国测绘科学研究院,北京 100830;4.国家组织机构代码管理中心,北京 100026)
基于MongoDB的地名信息管理
刘 亚1,段丽娟1,亢晓琛2,3,孙 镇4,赵 捷4
(1.北京中诚盛源技术发展有限公司,北京 100020;2.武汉大学,湖北武汉 430079;3.中国测绘科学研究院,北京 100830;4.国家组织机构代码管理中心,北京 100026)
一、引 言
地名是人们对具有特定方位、地理范围的地理实体赋予的专有名称,其本质属性包括两个方面:指位性与社会性。指位性指地名所代表的地理实体在地球表面上具有一定的空间位置;社会性是指地名的命名、更名、发展、演变始终受到社会因素制约。地名信息系统(geographic names information system,GNIS)是由美国地质勘察局(U.S.Geological Survey)联合地名委员会(U.S.Board on Geographic Names)建立的自然与文化中包含了地理位置与名称的数据库,其目的在于促进地名信息的标准化[1]。在地理信息系统中,实体的定位依据是实体所在的地理位置[2]。地理位置是一个抽象的概念,难以进行操作,因此在城市地名库的建立过程中,地名成为人与计算机或者手持设备进行沟通的纽带。Excite是全球领先的个性化门户网站,提供顶级搜索功能、门户网站,邮件服务,即时通信等服务,根据该网站统计,与地理位置相关的查询约占所有查询的1/5,而出现频率最高的关键字是地名[3]。在二维空间与三维空间应用中,地名数据可用于各类名称检索、空间范围查询,用于辅助空间信息可视化。在基于Web方式的地名标注应用中,不同的地物点往往对应不同类型、不同个数的字段。这种特殊的需求对传统的模式化关系数据库提出了极大的挑战。在城市快速发展的背景下,城市地名表现出数量多、密度大、使用率极高等一系列特点[4]。因此,需要良好的数据组织模型与数据库解决方案来支持地名的快速查询。
MongoDB是一个基于分布式文件存储的数据库,能够为Web应用提供可扩展的高性能数据存储解决方案,具有模式自由、支持二维地理空间索引、可存储二进制数据对象、支持查询和网络访问等一系列优点[5]。MongoDB将关系型数据库中“行”的概念转换为“文档”,支持文档数据的内嵌。由于无模式限制,MongoDB可为不同的地名提供多样化的字段定义,而无须大量迁移数据,从而使得数据模型具备灵活变更的能力。此外,MongoDB默认的存储引擎中使用了内存映射文件,将内存管理交付操作系统,其传输协议采用预分配策略,用空间换取性能稳定,优越的性能使其具备存储管理大规模地名数据、应对多样化存储需求的能力。
本文所设计的地名信息管理系统以MongoDB为底层存储解决方案。在此基础上,设计了基于K-means聚类算法的地名层次组织模型,并用文档字段来表征不同地名之间的级别关系。为便于地名应用访问地名库,设计与实现一系列地名文档信息操作接口,用于支持地名入库、建立空间索引、地名修改、地名查询(范围查询、邻近查询及名称查询)等。
二、地名数据组织模型
地名数据组织模型描述了整个地名信息库的层次组织结构,而这种层次关系需要通过单个地名文档的结构字段来表达。具体定位一个位置时,还需要空间索引来辅助操作以提高地名检索的效率。
1.基于K-means聚类算法的地名数据树模型
在二维或三维可视化应用中,为了确保显示效率与地图要素不过于拥挤,单次显示地名不能过于密集。在城市地区,即使很小的地理范围,对应的地名数据可能较众多。而在农村偏远地区,地名分布则可能较为稀疏。此外,地名具有行政归属,即不同地名节点之间可能具有从属关系(如海淀区节点属于北京市节点)。因此,必须采用分级的策略,同时兼顾地名密度。
K-means算法是经典的基于划分的聚类算法,其基本思想是:以空间中的k个点为中心进行聚类,对靠近他们的对象进行归类。通过迭代方法,逐次更新聚类中心的值,直至得到理想的聚类结果。
为了同时兼顾地名行政归属与地名分布密度,首先将主要的地名按行政级别划分为4个级别:0级(国家级)、1级(省、自治区、直辖市级)、2级(省会城市及地级市)、3级(区、县、县级市)。然后对从属于3级的大量的低级地名进行聚类划分,使得4级地名(聚类中心)与5级地名(村、镇)均保持有相对平衡的节点数目。地名的层次结构如图1所示。

图1 地名层次结构图
2.地名结构描述
为了在数据库中表达以上的层次关系,所有地名节点必须需具备最基本的一系列字段,用于反映上下级地名之间的关系。通过基本字段描述,整个地名数据库的逻辑结构可得到有效表达。其他可选字段则是可根据需求动态进行添加、删除、编辑。地名节点的字段列举如下:
1)地名标识(必选):唯一值,不允许重复,用于标识唯一一个节点。
2)地名名称(必选):描述该节点的地理名称。
3)地名位置(必选):以经纬度方式表达的独立坐标位置。
4)地名级别(必选):取0~5中的一个值。
5)子节点个数(必选):从属于当前节点的子节点个数。
6)父节点标识(必选):所属节点标识。
7)标注信息1(可选):如文字信息。
8)标注信息2(可选):如图片信息。
9)标注信息3(可选):如视频信息。
10)……
对于任意一个地名(假设标识为N,父节点标识为M,级别位L),可以获取它的父节点及子节点列表。由于每个地名记录存储了父节点标识,根据标识M可直接访问父节点的地名信息。由于子节的地名与父节点地名的级别差为1,联合查询级别与父节点标识两项字段即可返回当前地名的下级地名信息,即查询级别为L-1,且父节点为N的所有地名文档。为了加速索引过程,需要对标识、父节点标识及地名级别建立索引。
在MongoDB数据库中,采用了JSON(javascript object notation)格式来表述。单个地名的文本表达方式如下(以最低级的村庄地名文档为例):

3.索 引
在进行空间检索之前,需对空间范围内的地理要素构建空间索引,以便于按范围访问。由于地名数据位置信息为空间点位置,对应的空间索引也针对点集进行构建。Mongodb将整个地理范围划分为坐标网格,并采用geohash方式对网格进行编码,然后计算各个坐标位置对应的geohash值。计算geohash需要将二维空间范围迭代划分为4个象限,然后为对每个象限进行双位编码。如图2所示,一个4象限可以表达为4个两位数字(如00,10,01,11)。每个两位数对应一个象限与所有位于对应象限内的坐标位置。这样,所有位于左下角的点,均对应的geohash值均为00,以此类推,左上为01,右下为10,右上为11。要提高检索精度,可对每个象限作进一步划分。这样,每个坐标位置将对应更长的检索位。

图2 空间划分与空间索引
在将地名信息导入到数据库后,选择标识地理位置的字段(如经度、纬度)创建空间索引。MongoDB已经提供了空间范围的默认划分方式,并提供了对球面计算与平面几何计算的支持,只需要调用相关命令创建即可。
三、地名库接口设计与实现
地名数据管理系统需要实现基本的数据录入、数据修改,空间索引建立、各种空间查询接口,以便于外部应用访问。
数据录入接口提供了按行读取文本方式,字段的定义在首行。通过对首行文本的分析,可得到所有字段名称及类型。其格式定义如下:
Field1(Type)Field2(Type)Field3(Type)……
读取首行信息后,可得到基本的地名结构描述定义,从而录入各个字段。数据录入接口的定义较为简单,只需要提供文件路径即可,其定义如下:
void ImportFromTxt(const char∗filepathname)
空间索引是进行空间查询的基础,必须在查询之前进行构建。构建空间索引时,需要指定坐标对的具体字段。本系统支持二维空间坐标索引,需提供标识横坐标与纵坐标的两个字段。接口定义如下:
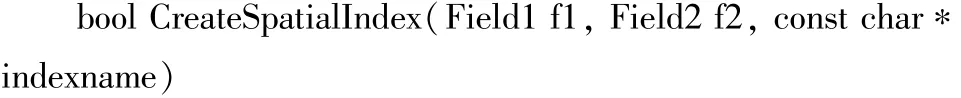
数据修改针对某个具体记录进行,需提供对应的记录标识。为了快速定位修改对象,需要对所有记录预先按照标识字段构建索引。其接口定义如下:

空间查询包括了按照范围、空间临近及按字段名称查询。其定义为:

其中,f定义了被查询的字段,value定义了被查询值。
地名管理引擎的实现基于MongoDB所提供的C++driver完成。通过封装成动态链接库或可执行文件,以方便在二维与三维应用中调用。在应用中,往往需要组合调用多个接口来实现特定的数据更新需求。一般流程为:①选择所需的查询接口来定位需要更新的地名文档;②根据定名标识逐个更新地名。
四、应 用
本系统已成功应用于基于Web方式的地名标注地理信息系统与三维地名可视化系统平台。在地名标注地理信息系统中,用户可在地图背景下动态添加点或线类型的地名标注。对于不同的标注项,用户可以个性化地增加标注内容,如文字,图片及上传的其他相关文件。不同标注项对标注内容的个数没有限制。Web端所标注的信息可动态插入到对应地名文档中,各地名文档均不受模式约束。
在三维应用中,地名数据以独立的显示图层加载到三维引擎中。为确保地名渲染速度及解决图面地名拥挤问题,地名的展示应依尺度进行变化,即随着可视化尺度的变化,地名数据可动态显示或隐藏,以确保显示调度的效率。图3与图4为同一地区两个不同尺度的地名显示状态。在图3对应的尺度下,仅显示了地级市级别的地名(如长沙市、南昌市)。在此基础上,经过地图放大,县级市的地名则全部显示出来(如图4所示)。通过地名层次组织结构,不同的层次细节信息得到调度显示。

图3 三维地名可视化―――尺度1

图4 三维地名可视化―――尺度2
五、结束语
基于MongoDB的地名数据管理可支持大量地名信息存储,查询方式及自定义方式更新等需求。传统关系型数据的模式化限制得到有效解决,从而支持多样化地名标注。内置的空间索引功能,使得基于关系数据库开发地名信息系统的复杂度得到有效降低。通过在地名标注地理信息系统与三维地名可视化应用中发现,基于MongoDB的地名信息管理是可行的技术方案。
[1]HILL L L,FREW J,ZHENG Q.Geographic Name[J]. D-Lib Magazine,1999,5(1):17.
[2]江春发.城市地名库的建立[J].测绘通报,2000 (9):23-24.
[3]SANDERSON M,KOHLER J.Analyzing Geographic Queries[C]∥SIGIR Workshop on Geographic Information Retrieval.[S.l.]:[s.n.],2004,2.
[4]傅立宪.上海市地名管理信息系统设计思想[J].中国地名,1997(2):29-30.
[5]MEMBREY P,PLUGGE E,HAWKINS T.The Definitive Guide to MongoDB:the noSQL Database for Cloud and Desktop Computing[M].[S.l.]:Apress,2010.
Geographic Names Management Based on MongoDB
LIU Ya,DUAN Lijuan,KANG Xiaochen,SUN Zhen,ZHAO Jie
地名数据具有数据量大、数据结构复杂、查询方式多样等一系列特征。传统的关系型数据库在存储地名信息数据时,往往需要预先定义数据表结构,难以实现动态增加多样化地名属性信息的功能。此外,复杂的地理查询需求也难以得到满足。本文提出一种基于非关系型数据库MongoDB的地名数据存储管理方式,可满足地名存储的各种需求。同时,属性查询、空间邻近查询、空间范围查询均能得到有效支持。
MongoDB;地名数据;地名存储;地名查询
P208
B
0494-0911(2014)10-0117-04
2013-10-08
国家科技支撑计划(2012BAH24B 02;2013BAK07B03)
刘 亚(1977―),男,重庆巫山人,工程师,主要研究方向为信息系统架构、商业智能及数据挖掘。
刘亚,段丽娟,亢晓琛.基于MongoDB的地名信息管理[J].测绘通报,2014(10):117-120.
10.13474/j.cnki.11-2246.2014.0346
