PDF文档的跨终端发布技术
2014-08-04昌磊陆阳吴雷
昌磊,陆阳,吴雷,2
1.合肥工业大学计算机与信息学院,合肥 230009
2.安徽教育网络出版有限公司,合肥 230601
PDF文档的跨终端发布技术
昌磊1,陆阳1,吴雷1,2
1.合肥工业大学计算机与信息学院,合肥 230009
2.安徽教育网络出版有限公司,合肥 230601
1 引言
PDF(Portable Document Format)文件格式是由美国Adobe公司提出的,因其能够再现原稿的字符、颜色以及图像且使用易于传输储存的工业标准压缩算法、包含重要结构的定位信息等特点,使得它已经成为国内外大多数出版社用于保存电子文档的主流格式。但是,PDF文件重在描述文档的打印格式,并没有描述文档内容的数据结构[1],无法根据终端设备的屏幕大小对内容进行动态重组。目前,人们借助于平板电脑、智能手机的移动阅读逐渐成为主流的阅读方式,增加了对出版社数字内容进行跨终端发布的技术需求。因此,基于PDF的数字内容管理方式成为了制约数字内容跨终端发布的瓶颈。
XML是W3C推荐的数据交换的标准[2]。它的出现扩大了网络表达的语义集合。XML是Internet环境中跨平台的、依赖内容的技术,是面向内容的文件格式,因此能够弥补PDF文件格式在语义描述方面的不足,采用XML作为出版社文档的保存格式,使得数字内容跨终端发布成为可能。
XML采用结构化的方式对电子文档的信息进行了描述,能够在输出时按照给定的格式信息对内容进行布局计算,动态生成符合当前终端屏幕尺寸的版面,是一种适合于描述文件结构和内容的工具[3]。因此为了更有效地利用文档跨终端数字内容出版,有必要将PDF文档转换为XML文档。
本文将首先重点介绍跨终端数字内容发布过程中涉及的关键技术,即:PDF版面信息抽取和数字内容跨终端自适应重组技术。
2 PDF文档预处理
PDF文档的内容信息和显示信息存在于不同的对象中,对象内容存在不同的编码方式。PDF文档的内容信息包含了文字、图片以及矢量。矢量是指由直线、曲线、矩形等组成的PDF对象。需要将PDF文档进行预处理,把PDF文档中的内容信息和显示信息反应出来。
要对PDF预处理,需要了解PDF的结构特点。PDF结构有物理结构和逻辑结构。PDF的物理结构描述了PDF的组成部分,而PDF的逻辑结构则是由一些称作“对象”的模型组成,描述PDF的结构化特性。
2.1 PDF物理结构
PDF的文件物理结构分为四个部分:文件头、文件主体、交叉引用表和文件尾[4]。如图1所示。

文件头(Header)文件主体(Body)交叉引用表(Cross-Reference Table)文件尾(Trailer)
(1)文件头(Header)描述PDF文件的版本号。
(2)文件主体(Body)由一系列的PDF间接对象组成。这些间接对象构成了PDF文件的具体内容,如字体、页面、图像等。
(3)交叉引用表(Cross-Reference Table)则是为了能对间接对象进行随机存取而设立的一个间接对象的地址索引表。交叉引用表中定义了PDF文档中所有对象的偏移地址,从而控制整体PDF文档。
(4)文件尾(Trailer)声明了交叉引用表的地址,指明文件体的根对象(Catalog)。根据Trailer提供的信息,PDF的应用程序可以找到交叉引用表和整个PDF根对象,从而控制整个PDF文件。
2.2 PDF逻辑结构
PDF的逻辑结构是一种树型的层次结构[5-6],如图2,反映的是文件中的间接对象之间的层次关系。树的根接点就是Catalog对象,下面有四棵子树,分别是Page Tree,Outline Tree,Thread Tree和Name Destination。PDF的页面内容,如文字、图形、图像等都保存在页面对象的content关键字对应的流对象(Content Stream)中。
(1)Page tree,包含着该文件的页面对象最重要的信息,比如使用的字体、内容、注释(Annotation)、缩略图(Thumbnail)的引用等。
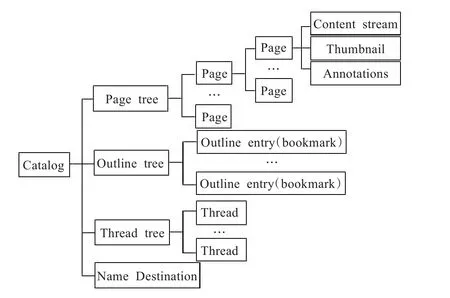
图2 PDF的逻辑结构图
(2)Outline tree,每个节点都是一个书签Bookmark,书签名和具体的页面位置一一对应,能够根据书签名来访问文档的内容。
(3)Thread tree,按照树型结构来组织文章线索和线索下的文章块。
(4)Name Destination,建立了一个字符串和页面区域之间的关联。
2.3 PDF预处理过程
PDF文档的预处理[7],首先要找到PDF文档的文件尾Trailer,从Trailer中读取交叉引用表的地址和PDF文档的根对象Catalog,然后解析内容流Content Stream和大纲对象Outline tree中每个Bookmark信息,输出得到基本单元字符集合。具体的解析步骤如下:
(1)找到根对象Catalog:利用文件尾Trailer中交叉引用表的偏移地址,找到表示根对象Catalog的偏移地址。
(2)访问内容流Content Stream:通过Page tree子节点找到页对象,访问页对象page中内容流Content Stream。根据对象中关键字Filter提供的算法类型来进行相应的PDF内容解析。PDF中使用的工业标准的压缩算法[8-11]有十种标准的过滤器。
(3)内容流Content Stream解析:包括字符解析、图片解析、矢量解析。字符解析,利用FlateDecod等过滤器,直接解析PDF文档中文字的坐标和属性,如字体大小、颜色、类型、字符间距等。在进行字符解析时,会按照字符在PDF中的先后顺序即在PDF中的坐标,形成一个字符的链表,方便之后的版面分析。图片解析:利用DCTDecode(针对彩色和灰度图像)和CCITTFaxDecode(针对单色图像)等过滤器,得到图片的大小,在文档中的位置信息以及图片解码方式。矢量解析:矢量的解析可以利用图片的解析技术,描绘出矢量的区域,按照图片方式保存处理。
(4)访问Bookmark:对于PDF的文档的篇章结构信息,需要解析PDF中的Bookmark判断一个文档大致的篇章结构。由于PDF中的Outline tree是一个树型层次结构。其中每一个节点都是一个Bookmark,每个Bookmark指向一个文档中的一个位置。因此采用Bookmark确定文档的篇章结构。Outline tree中每个Bookmark节点的深度对应着转换成文档中章节的层次结构,Bookmark的文本内容可以作为指向章节的标题。
如图3所示为PDF预处理过程。
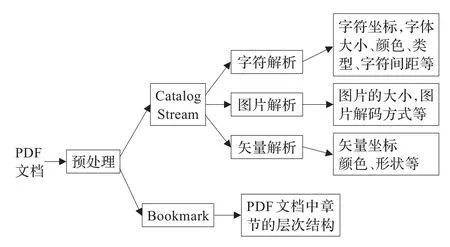
图3 PDF预处理过程
3 版面信息抽取
版面信息抽取就是利用计算机对PDF文档进行自动的处理和分析,识别PDF上的文字、图像、图形等区域的位置、属性和逻辑关系。
目前版面分析方法主要有两类,自顶向下和自底向上。自顶向下的方法采用某种算法将整个文本进行递归分割,直至得到版面块的分布结果为止。优点是分析速度快,缺点是对复杂的文本分析能力差。自底向上方法,则是一个从局部到整体的过程。这类方法的优点是分析精度高,适合各种类型的版面。由于出版社的PDF文档的版面类型比较繁多,结构复杂因此采用自底向上方法。
经过预处理的PDF文档能够得到基本单元字符,根据得到基本单元字符的属性信息,如位置、字体、字号、颜色、辅助信息、版式风格等,先构建文本行、段落快、页面,进而得到整个文档结构。下面是版面分析的具体方法。
步骤1文本行描述,PDF预处理得到了字符的坐标、字体、字号等属性信息的字符链表,根据字符的这些属性信息,定义自己的文本行描述规则对字符进行文本行的描述。比如具有相同或者相似的坐标、字体大小、对其方式等的字符会被作为一行处理;不满足规则的会被作为另外一行进行处理。如此下去,形成一个个文本行。
步骤2文本段描述,PDF文档中没有提供段落信息的描述。而如果要形成一段的话,在版面是具有相同的行属性,如:文本行间具有相同的行间距、文本行具有相同的字体类型、对齐方式等。所以我们可以根据文本行描述得到的信息进行文本段描述。下面一种或者几种方法可以作为判断的标准:
(1)行间距:如果两个文本行之间的距离大于平均距离或者大于前两个文本行之间的距离,则认为这两行出于不同的段落中。
(2)行头或行尾坐标:如果一行的首个字符的横坐标大于前一行的首字符的横坐标,则认为这是一个新的段落的开始;如果一行文本的最后一个字符的横坐标小于前一行文本的行尾横坐标,则认为下一行开始为段落的开始。
(3)根据文本行的属性,如字体类型,对齐方式,段落间距等。
步骤3页面描述:将之前得到的文本段的以及图片、矢量等在页面中的位置坐标关系,形成整个页面。
在进行页面描述时,需要将考虑到文本段、图片以及矢量在页面中的位置关系。现实中常常遇到图片或者矢量嵌入在文本段中,因此需要选择一种策略,描绘出文本段的边界区域,以及图片、矢量在段落中的关系。如图4所示。

图4 边界区域描绘
描绘出文本段的边界区域,需要将文本行的边界坐标连接起来,对于横排文本行,需要从文本行的左上角开始,如图中所示的顺序,连接起来所有的左边的边界坐标,再连接起右边的坐标。下面是具体的算法设计:
①将所有的文本行按照中心点坐标自上而下进行排序。
②定义矢量L,将文本行的左上点和左下点坐标加入到矢量L中。
③遍历矢量L,如果Li到Li+1是向右上方移动,则将Li+1从L中移出;如果Li到Li+1是向左上方移动,则将Li从L中移出;如此类推,直至L为空。
④类似的定义矢量R,将文本行的右上点和右下点坐标加入到矢量R中;遍历矢量R,如果Ri到Ri+1是向右下方移动,则将Ri从R中移出;如果Ri到Ri+1是向左下方移动,则将Ri+1从R中移出;如此类推,直至R为空。
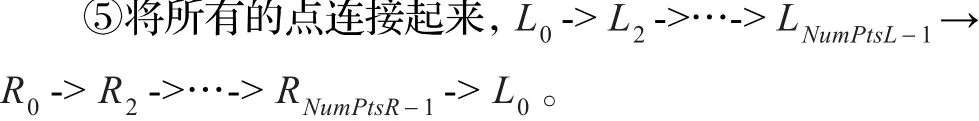
⑥类似的,对于纵向排版的文本行也是类似的处理。
如图5所示,版面分析的效果图。同时支持独立段落模块之间的合并、拆分功能,实现PDF的文档内容的编辑。

图5 版面分析的效果图
通过版面分析可以识别PDF中的各种数据元素,如:段落、标题、插图、页眉、页脚、公式、表格等。PDF进行版面分析与信息抽取输出结果为具有自描述性的XML文档。以进行重新转换或者输出。
4 终端自适应重组
数字内容跨终端的实现是由服务器端根据客户端的请求生成适合阅读终端的页面,下载到终端并在终端上进行显示[12]。服务器端负责数字内容的绘制工作。经过版面分析与信息抽取得到的具有自描述性的XML文档,根据XML标签定义的是图片(或矢量,矢量预处理阶段作为图片进行处理)还是文本,根据终端设备信息,如屏幕大小等,选择相应的自适应算法,进行终端的重新描述,实现数字内容的跨终端发布。具体的实现过程如流程图6和伪码。
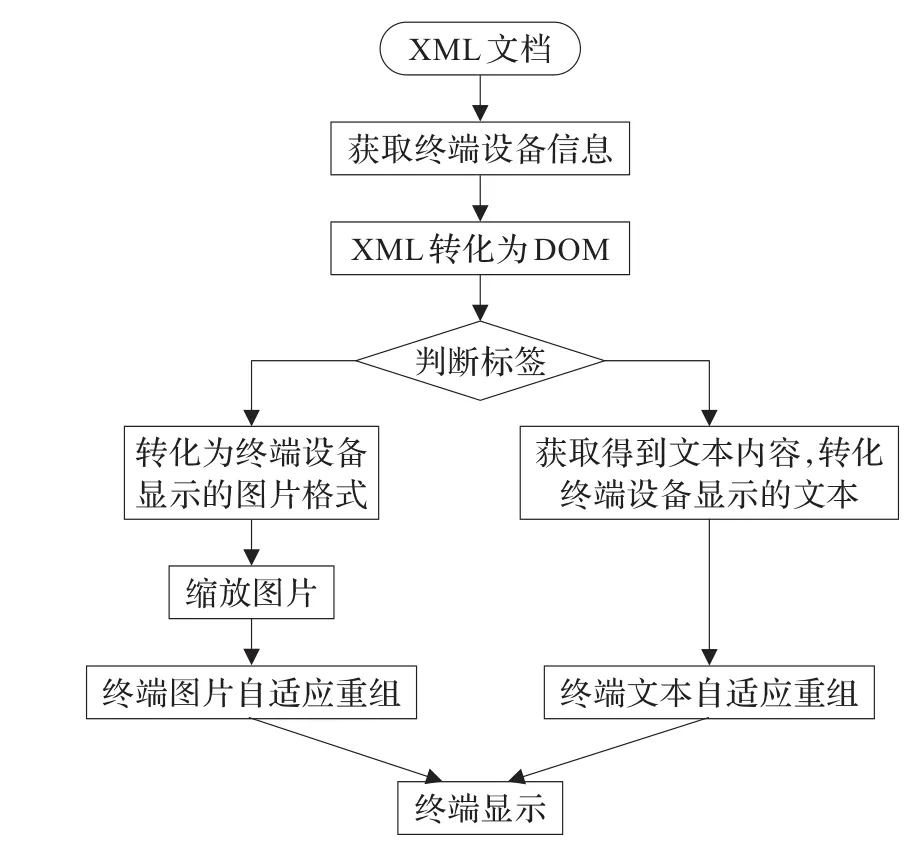
图6 终端自适应流程图

5 实验结果与结论
根据文章描述的版面分析与信息抽取以及数字内容终端自适应重组技术,设计了一个基于XML的数字内容跨终端出版系统。整个系统分为PDF文档处理模块、版面分析信息抽取模块、跨终端自适应重组模块。提供由用户上传PDF文档到跨终端设备上出版的一套解决方案。如图7所示的系统设计图。
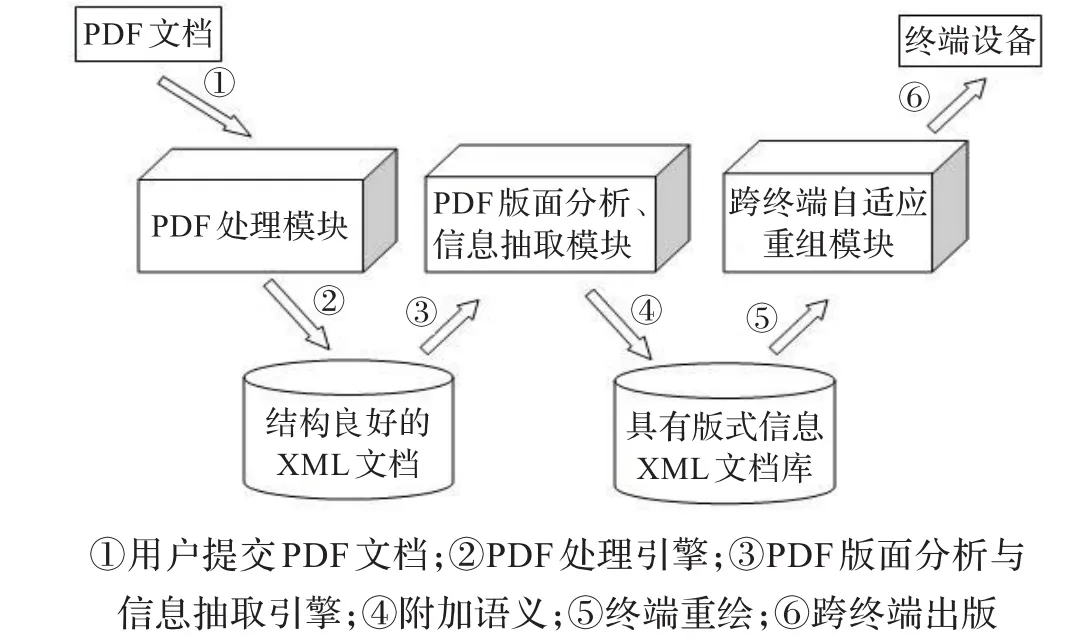
图7 系统设计图

图8 相同的文档在终端上面的显示效果
上述跨终端出版系统已经应用于安徽教育出版社的全媒体数字出版运营服务平台中,能够很好地针对不同的PDF图书文档,进行文本内容的抽取和图片的处理,并能够根据不同终端设备的特性,呈现出最佳的显示效果。在实际应用中,已取得了良好的结果,解决了不同终端的出版问题,并证明了系统的实用性。如图8所示,相同的文档在不同终端设备上的显示效果。
与其他的PDF转换系统相比,本系统能够将PDF的内容进行准确的版面描述,利用很好的人机交互界面,用户根据PDF文档的内容进行版面分析,进而形成具有版面信息的XML文档。版面分析的结果能够很好的保留版面信息,因此在终端设备上的显示不再是简单的流式文档的显示,具有了一定的版式特色,且可以根据用户的需求自定义一些特色版式风格。
[1]Adobesystemincorporatedreference[Z].2nded.Adobe Portable Document Format Version1.4.
[2]Extensible Markup language(XML)1.0[EB/OL](2008-11-26). http://www.w3.org/TR/xml/2008-11-26.
[3]葛一兵,余智华.基于XML的PDF文档内容与结构的表示的实现[J].计算机工程与应用,2004,40(14):120-122.
[4]李珍,田学东.PDF文件信息的抽取和分析[J].计算机应用,2003,23(12):145-147.
[5]Portable document format[EB/OL][2010-09-06].http://www. docin.com/p-34849642.html.
[6]宋艳娟,张德文.基于XML的PDF文档信息抽取系统的研究[J].现代图书情报技术,2005,9:10-12.
[7]Hui Chao,Jian Fan.Layout and content extraction for PDF documents[C]//Document Analysis Systems VI,6th International Workshop,2004:213-224.
[8]李强,刘时进.PDF阅读器的设计与实现[J].计算机工程与设计,2010,31(7):1635-1638.
[9]杨道良.面向对象的中文PDF阅读器的设计与研究[J].计算机应用,1999,19(6):1-4.
[10]陈云榕,刘立柱,丁志鸿.PDF中关键信息的提取与组织方法研究[J].计算机工程与设计,2007,28(7):1688-1690.
[11]张波.PDF文档语义信息抽取研究[D].保定:河北大学,2004.
[12]邹进波.基于CEBX的跨终端在线阅读系统的设计与研究[D].北京:北京邮电大学,2011:30-36.
CHANG Lei1,LU Yang1,WU Lei1,2
1.School of Computer&Information,Hefei University of Technology,Hefei 230009,China
2.Anhui Education Publishing House,Hefei 230601,China
Facing on the issues when the press publishes digital content across the terminals,this paper lays special stress on the research of technologies on layout information extraction and across terminal adaptive recombination for the PDF document.The methods of extraction and layout structure analysis to the texts and pictures in the PDF document are proposed. Then the terminal adaptive recombination algorithm is applied to publish the digital content across the terminals.A set of publishing system through which the digital content is published across the terminals based on the above technologies. The experimental results prove that the approach is practical in real-world application.
Portable Document Format(PDF);cross terminal adaptive recombination;layout information extraction
围绕目前出版社在对数字化内容进行跨终端发布时遇到的问题,重点对PDF文档的版面信息抽取和跨终端自适应重组等技术进行研究,提出了针对PDF文档中文本、图片等信息的抽取方法和版面结构分析方法,利用终端自适应重组算法对数字化内容进行跨终端发布;以此为基础设计了一套数字内容跨终端发布的系统,并应用在出版社的实际工作中,实验结果证明了方案的可行性。
PDF文件格式;跨终端自适应重组;版面信息抽取
A
TP391
10.3778/j.issn.1002-8331.1212-0345
CHANG Lei,LU Yang,WU Lei.PDF document across terminal publishing technology.Computer Engineering and Applications,2014,50(22):158-162.
国家自然科学基金(No.61070220);高等学校博士学科点专项科研基金(No.20120111110001);安徽省年度重点科研计划项目(No.11070203002)。
昌磊(1989—),男,硕士研究生,主要研究方向:信息检索、数字出版;陆阳(1967—),男,教授,博导,主要研究方向:可信系统、传感器网络等;吴雷(1981—),男,博士研究生,主要研究方向:数字出版。E-mail:changlei19890804@163.com
2012-12-28
2013-03-07
1002-8331(2014)22-0158-05
CNKI网络优先出版:2013-03-29,http://www.cnki.net/kcms/detail/11.2127.TP.20130329.1540.003.html
