一种面向大规模微博数据的话题挖掘方法
2014-08-04王文帅杜然程耀东陈刚
王文帅,杜然,程耀东,陈刚
1.中国科学院高能物理研究所计算中心,北京 100049
2.中国科学院大学,北京 100049
一种面向大规模微博数据的话题挖掘方法
王文帅1,2,杜然1,2,程耀东1,陈刚1
1.中国科学院高能物理研究所计算中心,北京 100049
2.中国科学院大学,北京 100049
1 引言
近年来社交网站在国内外得到迅猛发展,微博逐渐融入人们的日常生活,微博作为信息发布和传播的平台,得到越来越多机构的关注。与传统新闻媒体相比,微博的信息提供者更广泛,更新速度和传播速度更快,内容涵盖主题更加宽泛。微博话题发现对行业调研、舆情监管都有十分重要的作用,这使得微博话题的挖掘成为当前的一个研究热点。
据新浪公开数据,截至2012年底,新浪微博注册用户数就已达到5亿以上,2013年第四季度微博日均活跃用户为6 140万。在庞大的微博用户中存在一定数量的“网络水军”使微博数据充斥着一些重复的垃圾数据,从海量的微博信息中挖掘出有效的话题信息显得尤为重要。
2 相关工作
2.1 传统的话题挖掘模型
早期的话题挖掘方法使用的是向量空间模型(Vector Space Model,VSM)由Salton[1]等人在20世纪70年代提出。VSM模型广泛应用于新闻文档的话题挖掘领域,文本表示成高维的向量,通过构造词语-文本特征矩阵来挖掘话题。而微博文本内容简短,同一个词出现在不同文本中的概率远小于普通的新闻文档。这就会导致特征矩阵高度稀疏,使结果难以令人满意。
Deerwester等人引入语义维度提出潜在语义分析(Latent Semantic Analysis,LSA)模型[2]对文本进行挖掘,其主要思想是将文档和词汇映射到与语义相关联的一个低维的向量空间,本质上是考虑词与词在文档中的共现情况。LSA通过对高维的TF-IDF矩阵进行奇异值分解,是一种线性代数的分析方法,算法复杂度较高。
1999年,Hofmann在LSA的基础上提出基于概率统计的生成模型pLSA[3],pLSA通过概率模型来模拟文档中词语的生成过程,然而在pLSA中对文本-主题的分布和主题-词语的分布只看作是参数,而非随机变量。
2003年Blei等人[4]在pLSA的基础上引入Dirichlet先验分布,提出了LDA(Latent Dirichlet Allocation)模型。LDA模型是一个“文本-主题-词语”的三层贝叶斯产生式模型。假定文本集D中有M个文本D={d1,d2,…,dm},每个文本有N个词语W={w1,w2,…,wn},文本集有T个主题。每个文本可以表示为一系列潜主题的随机混合分布p(z),每个主题都是文本集中全部词语的概率分布p(w|z),这样每一个文本中每个词语wi的概率分布可以表示为:
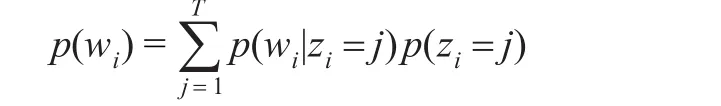
图1所示为LDA的概率图模型。LDA模型生成文本的过程为:
(1)选择主题与词语的关系ϕ,ϕ~Dirichlet(β)。
(2)对每个文本d:
①选择文本与主题的关系θd,θd~Dirichlet(α);
②按如下方法选择N个词语的每个词语:
(a)选择主题zdn,zdn~Multinomial(θd);
(b)选出词语wdn,wdn~Multinomial(φzdn)。
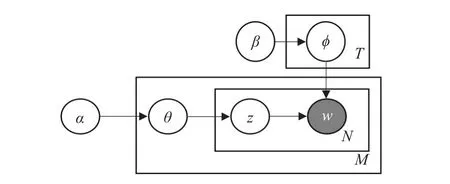
图1 LDA的概率图模型
LDA模型通过将T个主题的概率权重看为Dirichlet分布的T维随机变量,克服了pLSA的参数过多的缺点,并且避免pLSA中参数数目随文本数增加而增加的缺点,从而避免了过度拟合问题。在LDA模型的基础上也衍生出了许多基于LDA的其他主题模型。
2.2 微博话题挖掘
微博数据中丰富的转发、评论关系信息为话题挖掘提供了更丰富的数据基础,而传统的话题挖掘模型不能很好地利用这些信息。近年来,在微博话题挖掘方面,国内外研究人员多以Twitter为研究对象,基于LDA提出了一些主题分析方法。路荣等使用LDA模型挖掘短文本的隐主题信息,以此度量短文本间的相似度,对短文本进行聚类分析[5]。有学者提出改进的LDA模型,如Twitter-LDA[6]、MB-LDA[7]等。Twitter-LDA先将相同作者的文本聚合成一个大的“用户文档”,然后引入背景主题,取得了不错的效果,但没有根据背景主题对数据进行进一步处理,挖掘出的不同主题中仍然会包含比较多的背景词,影响主题的独立性。MB-LDA认为与同一联系人存在关联的文本主题往往也相关,引入联系人与主题的分布,并根据转发标识关联转发文本和原文本的关系。由于中英文表达和结构的差异,以及Twitter和国内微博数据结构的不同,针对Twitter的研究不能适应微博分析的需求。中文微博的研究多以新浪微博为研究对象,谢昊等人基于提出一种RT-LDA模型[8]引入作者的主题分布和对转发微博的处理。马雯雯等人引入话题热度概念,提出一种基于LSA的两阶段聚类话题发现方法[9]。
3 面向大规模微博数据的话题挖掘
3.1 数据采集
为了能对新浪微博数据进行话题挖掘首先要进行微博采集工作。新浪提供了开放API接口,利用API可以获得丰富的微博数据。新浪对API的调用设置了较多的限制,为提高数据采集效率,本文利用中科院高能物理研究所计算中心的微博大数据爬虫开放平台[10]进行数据的采集工作。实验从新浪微博抓取了914 036个用户共1 452 565条与2014年两会相关的微博。对大规模的数据集进行统计分析发现,每个用户平均发布1.6条微博,发布10条以上微博的用户仅占总用户数的1.02%,在这样大规模的数据集上使用基于作者(用户)主题分布的模型或算法复杂度较高的LSA模型都不太合适。
3.2 方法的基本流程
针对大规模微博数据的特点,本文提出的方法是,首先使用Bloom Filter算法[11]对重复信息进行删除,减少不必要的存储成本和分析的复杂度;然后提取出微博间的转发、评论关联关系,以备后续分析使用;使用正则表达式去除微博中的干扰信息,对微博进行分词、去停止词处理;最后使用改进的LDA模型SNLDA模型进行主题挖掘得到微博话题及其分布情况。方法的整体框架如图2所示。
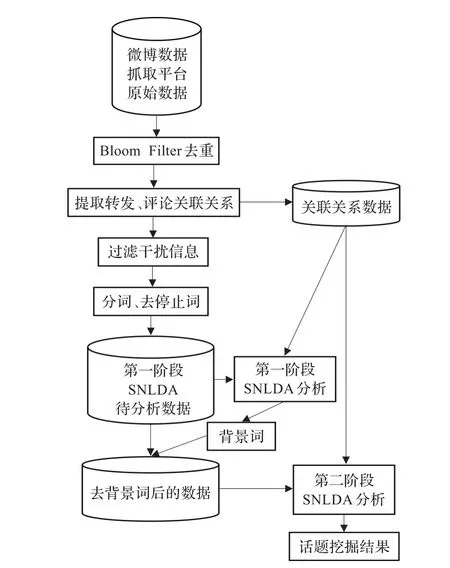
图2 整体框架图
3.3 数据预处理
3.3.1 Bloom Filter算法去重
经过对新浪微博数据的分析发现,在数据中存在比较多的重复信息,主要是“网络水军”通过多个微博帐号发布同样的内容对某件事或某产品进行炒作。为了减少数据存储并顺利挖掘出有效话题,需要去除这些重复数据进行。判断一条微博是否和已有微博重复,最基本的方法是查找这条微博是否已属于已有微博的集合,用普通的顺序查找方法,效率很低,不能很好地满足需求。
布隆过滤器(Bloom Filter)是由Howard Bloom在1970年提出的。他仅使用了一系列的bit位来保存数据,就可以检测一个元素是否已经存在于集合内,因此这种算法有着很好的空间利用率。但是为了节约空间,这种算法也存在着问题,它会对元素产生错判:把一个不属于该集合的元素误判为属于该集合。但是这种误判率非常低,对于大规模的微博话题挖掘来说,个别微博这种错误是可以容忍的,因此,布隆过滤器仍是一个比较合适的算法。
使用Bloom Filter算法进行微博文本去重时,为微博设置一个bool属性,记录微博是否重复,把每条微博的内容看作一个元素,先初始化一个空的布隆过滤器,每读入一条微博,就判断布隆过滤器是否包含该元素,若不包含,就把该元素加入布隆过滤器,微博的bool属性设置为false,这样完成对微博内容的去重处理。伪代码如下:

3.3.2 提取关联关系
新浪微博存在大量的转发、评论等社交网络特有的关联关系信息,对话题的挖掘有帮助,特别是用户转发时没有追加新内容或用户评论内容极短时关联起原微博信息才能明确用户参与的话题,提取出这些关联信息很有必要。对新浪微博进行分析发现三种情况:(1)用户B单纯转发用户A一条微博,在用户B的页面上会显示“转发微博”并在下面以特定格式显示用户A的原始微博;(2)用户B转发并评论用户A一条微博,在用户B的页面上会显示评论内容并在下面以特定格式显示用户A的原始微博;(3)用户C对用户A的微博进行了评论,用户B又对用户C的评论进行评论并转发,在用户B的页面上会显示以“回复@用户C:”开头的用户B评论内容,后面是以“//@用户C:”开头的用户C评论的内容,并在下面以特定格式显示用户A的原始微博。微博数据抓取平台得到的社交网络数据信息包括用户ID、微博ID、微博URL、微博内容、转发/评论源ID等属性。其中微博内容不包含并以特定格式显示的原始微博。如果某条微博是对其他微博的转发评论,转发/评论源ID属性即为被转发/评论原始微博的ID,如果是原创微博,该属性为0。通过该属性可以把原始微博内容与转发/评论部分的内容相关联,使文本特征得到扩展。
3.3.3 过滤干扰信息
微博中还存在大量的对话题挖掘意义不大的特征信息,如“//@人民日报:我想说环境治理刻不容缓,不能再以牺牲环境来换取经济的发展了,我们不要雾霾!我们要蓝天白云^&**&^我在:玉泉路”这条信息中,“//@人民日报:”、“我在:玉泉路”这些信息本身对话题挖掘意义不大,反而容易造成干扰,需要去除掉;“^&**&^”这种特殊字符则是噪声词也需要去除掉。
通过对微博文本特征进行分析,发现以下干扰信息需要过滤掉:(1)URL链接;(2)以“@”开头部分字符串;(3)以“我在:”或“我在这里:”开头的部分字符串(微博结尾部分的位置信息);(4)特殊字符。通过配置相应的正则表达式可以很好的过滤掉这些干扰信息。
对文本进行分词处理后,还需要去除掉助词、副词等停止词,实验使用加载停止词典的方法去除停止词。
3.4 SNLDA模型
因为大量转发、评论类微博文本较短,使用标准的LDA模型对微博进行挖掘会存在数据高维稀疏的问题。利用从社交网络提取的微博关联信息可以扩展文本特征,转发、评论类微博关联上原始微博可以很好地确定主题。相比新闻类文章而言,微博内容短小,可以认为一条微博只涉及一个主题。在微博中去除噪声后仍有一些背景词大量出现,以两会相关的微博为例,“两会”、“中国”等词语就多次出现在大量微博中,这些词是数据集的背景词,不具备挖掘意义。
图3所示为SNLDA的图模型,模型中各参数符号说明如表1所示。SNLDA引入反馈机制,设置背景词典,文本中的背景词不再参与主题挖掘,保证各主题的独立性和可辨识性。模型分为两个阶段,虚线上方为第一阶段,推导得出背景词典,根据背景词典对数据集进行裁剪处理,再进行虚线下方的第二阶段推导。
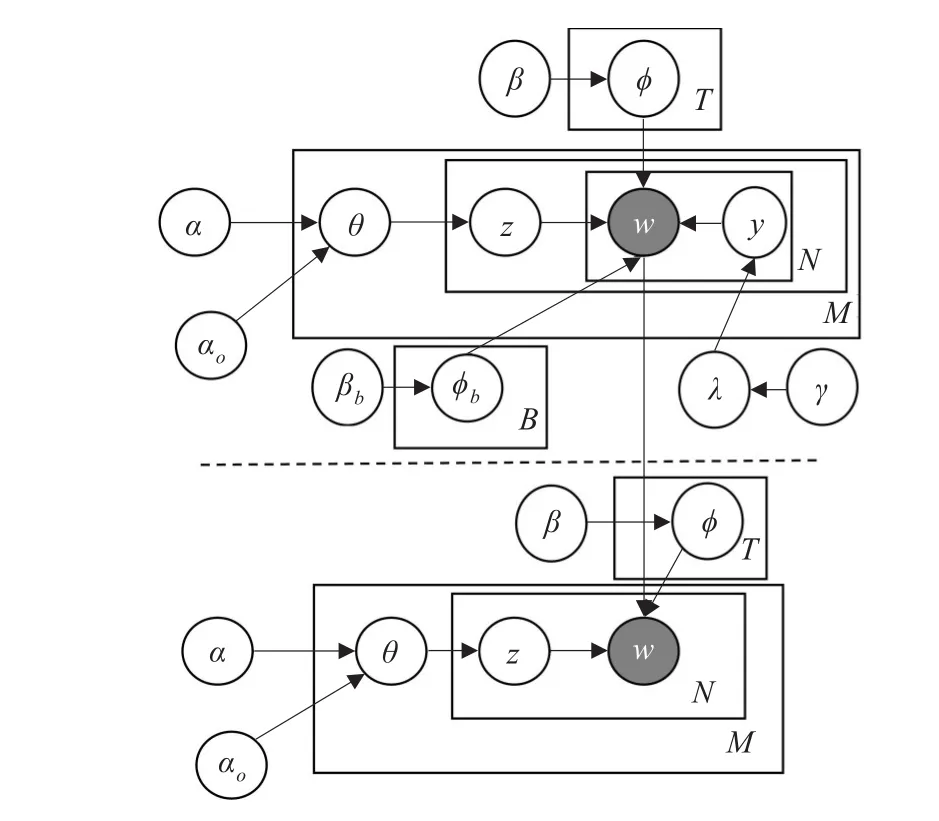
图3 SNLDA图模型

表1 SNLDA模型参数符号说明
第一阶段微博文本的生成过程如图4所示:首先用参数γ生成伯努利分布λ,λ服从Dirichlet分布,即λ~Dir(γ),用参数βb生成φb,φb~Dir(βb)。对每一个主题,用参数β生成φ,ϕ~Dir(β)。对每条微博,根据微博关系判断是否为转发评论类微博,如果是,则关联原微博用参数αo生成θd,θd~Dir(αo);如果不是,则用参数α生成θd,θd~Dir(α)。根据θd抽取微博主题zd,zd~Multinomial(θd)。主题确定后从参数为λ的伯努利分布中抽取y,确定是从背景词中抽取词语还是从主题zd中抽取词语,如果y=0,从背景词中抽取;如果y=1,从参数为φzd的多项分布中抽取词语。

图4 微博生成过程
第一阶段可以得到y的分布情况,从而确定背景词的分布,与去停用词类似,在词汇表中对背景词进行裁剪处理。之后进行第二阶段推导,得出相对独立的主题分布。
如SNLDA模型第一阶段微博生成过程所述,每条微博d的主题的后验分布θd的概率可表示为:
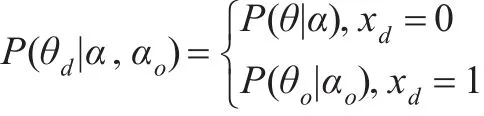
式中xd=0表示原创微博,xd=1表示转发评论微博。
由于每条微博d只有一个主题,主题的概率可表示为:
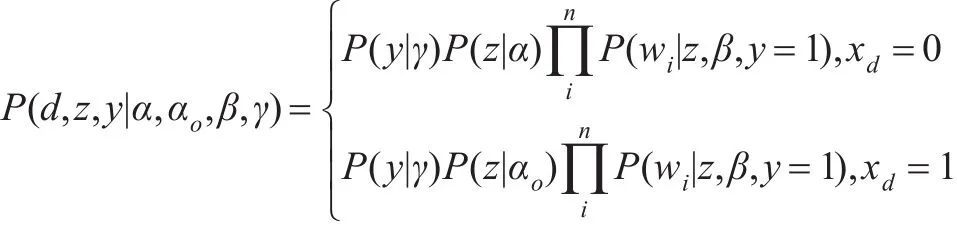
3.5 模型推导
LDA主题模型求解常用的有三种非精确推导方法:吉布斯采样法,变分法和基于期望推进的方法。实验采用简单快速的吉布斯采样法[12]。
吉布斯采样法采样一条微博属于某个主题的条件概率可表示为:
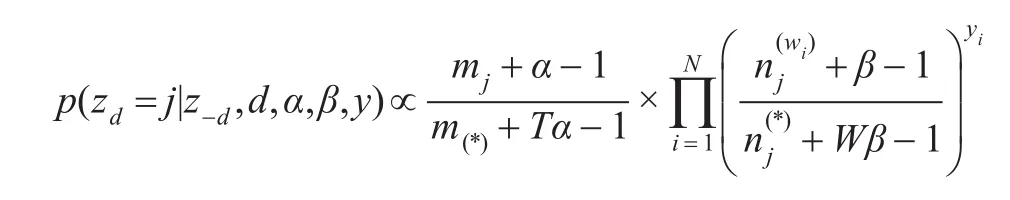
其中zd=j表示微博d当前主题是j,z-d表示除去微博d之外其他微博的主题,N为微博d中词语的数量,yi表示词语wi是否选自主题词,n(wi)j表示微博d中词语wi分配到主题j的数量,n(*)j表示分配到主题j的词语的总数,mj表示分配到主题j的微博数量,m(*)表示微博的总数量。
决定微博中每个词语是否主题词的y分布的概率表示为
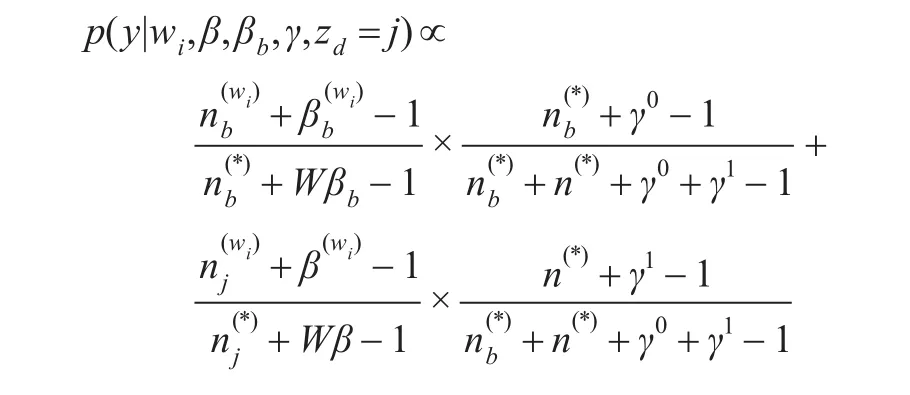
在吉布斯采样过程中,通过对上述公式反复迭代使抽样结果达到稳定状态,获得参数结果:

4 实验分析
4.1 数据预处理结果
实验对1 452 565条数据进行去重,去重后剩余714 950条数据,节省了50.78%的存储空间,也大大降低了之后话题挖掘阶段的计算量。
4.2 参数设置
根据参考文献中对主题模型参数设置的研究,本实验参数设置为经验值[13]:α=αo=50/T,β=βb=0.01,γ=0.5,话题数T设为50,吉布斯采样迭代次数设置为300次。
4.3 实验结果
4.3.1 高概率主题词效果
分别使用SNLDA模型和LDA模型进行微博话题挖掘。在每个主题内部根据词语概率高低进行主题词排序,可以选择具有最高概率的6个词语评估话题挖掘效果[14]。表2所示是取了SNLDA模型结果中的前10个话题及其关键词,表3所示是取了LDA模型结果中的前10个话题及其关键词。

表2 SNLDA模型微博话题挖掘结果
表2中话题1关注的是司法改革,话题2关注的是房地产调控,话题3关注的是两会矿泉水实名制,话题4关注的是昆明火车站暴力事件,话题5关注的是城镇化改革,话题6关注的是雾霾治理问题,话题7关注的是乌克兰局势,话题8关注的是教育公平问题,话题9关注的是转基因食品安全问题,话题10关注的是医改问题。话题挖掘结果具有很好的可读性,而且与现实中的事件相吻合。

表3 LDA模型微博话题挖掘结果
表3中话题关键词交叉现象比较多,话题可辨识性较差。使用SNLDA模型得到的结果要优于LDA模型。
4.3.2 Perplexity指标评估效果
实验使用Perplexity指标对模型进行量化评估。Perplexity常用来衡量语言模型对语料建模时性能的好坏,一般来说,Perplexity取值越小表示模型性能越好[15]。该指标计算公式如下:

其中D为数据集,wd为微博d中的词语,Nd为微博d的词语数。
在相同参数下,取主题数T为50,计算LDA模型与SNLDA模型的Perplexity值,结果如图5所示。从结果可以发现,相同条件下SNLDA模型的Perplexity取值更小,说明SNLDA模型对语料建模的性能要更好。
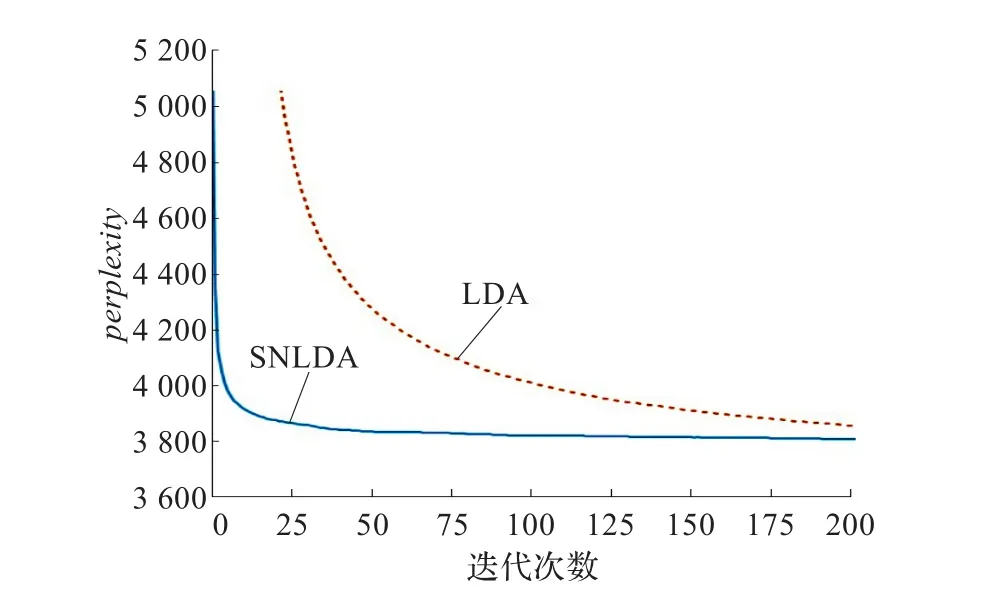
图5 模型Perplexity值比较
5 结束语
本文提出了一种针对大规模短文本的话题挖掘方法。首先对大规模文本进行去重处理,再针对微博特有的结构进行数据过滤处理,综合考虑转发、评论等关联关系和背景词语影响等因素提出一个两阶段微博主题挖掘模型SNLDA。实验表明模型能较好地挖掘出微博的主题。今后的研究工作中将继续优化模型,一方面探索使用云计算平台对微博数据进行主题挖掘,另一方面探索高效的增量式主题挖掘模型。
[1]Salton G,Wong A,Yang C S.A vector space model for automaticindexing[J].CommunicationsoftheACM,1975,18(11):613-620.
[2]Deerwesster S,Dumais S T,Fuvnas G W.Indexing by latent semanticanalysis[J].JournaloftheAmericanSociety for Information Sciens,1990,41(6):391-407.
[3]Hofmann T.Unsupervised Learning by Probabilistic Latent SemanticAnalysis[J].MachineLearning,2001,42(1):177-196.
[4]Blei D M,Ng A Y,Jordan M I.Latent dirichlet allocation[J].Journal of Machine Learning Research,2003(3):993-1022.
[5]路荣,项亮,刘明荣,等.基于隐主题分析和文本聚类的微博客新闻话题发现研究[C]//第六届全国信息检索学术会议论文集,2010.
[6]Zhao Wayne Xin,Jing Jiang,Weng Jianshu,et al.Comparing twitter and traditional media using topic models[C]//Proceedings of 33rd European Conference on Information Retrieval(ECIR’11).Berlin,Heidelberg:Springer-Verlag,2011:338-349.
[7]张晨逸,孙建伶,丁逸群.基于MB-LDA模型的微博主题挖掘[J].计算机研究与发展,2011,48(10):1795-1802.
[8]谢昊,江红.一种面向微博主题挖掘的改进LDA模型[J].华东师范大学学报:自然科学版,2013,11(6):93-100.
[9]马雯雯,魏文晗,邓一贵.基于隐含语义分析的微博话题发现方法[J].计算机工程与应用,2014,50(1):96-99.
[10]中科院高能物理所Bigdata微博爬虫开放平台[EB/OL]. [2014-02-03].http://bigdataopc.ihep.ac.cn.
[11]Bloom B H.Space/time trade-offs in hash coding with allowable errors[J].Communications of the ACM,1970,13(7):422-426.
[12]Griffiths T.Gibbs sampling in the generative model of LatentDirichletAllocation[EB/OL].[2014-02-03].http:// people.cs.umass.edu/~wallach/courses/s11/cmpsci791ss/ readings/griffiths02gibbs.pdf.
[13]Griffiths T L,Steyvers M.Finding scientific topics[J].Proceedings of the National Academy of Sciences of the United States of America,2004,101(Suppl 1):5228-5235.
[14]Chang J,Boyd-Graber J.Reading tea leaves:how humans interpret topic models[M]//Bengio Y,Schuurmans D,Lafferty J,et al.Advances in neural information processing systems.Cambridge,MA:The MIT Press,2009:288-296.
[15]Gruber A,Weiss Y,Rosen-Zvi M.Hidden Topic Markov Models[C]//Proceedings of the Conference on Artificial Intelligence and Statistics,2007.
WANG Wenshuai1,2,DU Ran1,2,CHENG Yaodong1,CHEN Gang1
1.Computing Center,Institute of High Energy Physics,Chinese Academy of Sciences,Beijing 100049,China
2.University of Chinese Academy of Sciences,Beijing 100049,China
With the daily popularity of microblog,Sina Weibo has become one of the important public access to and dissemination of information platform,microblog topic mining has become a current research focuses.This paper proposes a topic mining method on massive Social Network data.This paper analyzes the large-scale microblog data,uses Bloom Filter algorithm to eliminate the duplicate data.In view of the special structure of microblog,filter the text.SNLDA,an improved LDA topic model is proposed in this paper,Gibbs sampling is chosen to deduce the model,which can mine the microblog topics.The experimental results show that the method can effectively excavate the topics from the large-scale microblog data.
microblog;Bloom Filter;Social Network LDA(SNLDA);topic mining
随着微博的日趋流行,新浪微博已成为公众获取和传播信息的重要平台之一,针对微博数据的话题挖掘也成为当前的研究热点。提出一个面向大规模微博数据的话题挖掘方法。首先对大规模微博数据进行分析,基于Bloom Filter算法对数据进行去重处理,针对微博的特有结构,对文本进行预处理,提出改进的LDA主题模型Social Network LDA(SNLDA),采用吉布斯采样法进行模型推导,挖掘出微博话题。实验结果表明,方法能有效地从大规模微博数据中挖掘出话题信息。
微博;Bloom Filter;社会网络主题模型分析(SNLDA);话题挖掘
A
TP393
10.3778/j.issn.1002-8331.1404-0042
WANG Wenshuai,DU Ran,CHENG Yaodong,et al.Topic mining method on massive microblog data.Computer Engineering and Applications,2014,50(22):32-37.
国家自然科学基金(No.11205179,No.11305196);国家高技术研究发展计划(863)(No.2014AA015205)。
王文帅(1982—),男,博士研究生,工程师,研究领域为数据挖掘,数据库技术;杜然,女,博士研究生;程耀东,男,博士,副研究员;陈刚(1961—),男,博士,研究员,博士生导师。E-mail:wangws@ihep.ac.cn
2014-04-03
2014-05-21
1002-8331(2014)22-0032-06
CNKI网络优先出版:2014-06-26,http://www.cnki.net/kcms/doi/10.3778/j.issn.1002-8331.1404-0042.html
