融入MD5的HASH线性获取增量算法研究
2014-08-03杨金民
郭 亮,杨金民
湖南大学 信息科学与工程学院,长沙 410082
融入MD5的HASH线性获取增量算法研究
郭 亮,杨金民
湖南大学 信息科学与工程学院,长沙 410082
1 引言
随着信息化技术进一步的发展和数据量的暴增,现有的增量提取技术无法大幅度地减少数据备份时间,满足人们的备份需求;对于大部分的用户来说,备份速度过慢将会影响正常的业务运营。在某些大规模数据密集型系统中(如:网络安全监控、金融数据分析、电信数据处理等领域),这些问题尤为突出[1-3]。
常用的数据库增量提取方法主要有两种:(1)基于NOT EXISTS 的 SQL 语句[4];(2)基于 Sort-Merge Join(S-MJ)的方法[5-7]。第一种方法所采用的扫描策略需要进行至少M×N次比较,其时间复杂度为O(n2),虽然在数据库中对相关字段建立索引能提高效率,但在数据量较大的情况下,其性能会急剧下降,效率低下。第二类方法中最具代表意义的是SQL语句MINUS[8],求集合的差集,其具体的实现过程是对原始表和备份表所有记录的相关字段进行排序,线性比较两有序集合得出增量记录;第二种方法较第一种方法有很大的改进,尤其在数据量较大的情况下优势更加明显,但其效率受到排序算法性能和排序字段数的影响较大,有待进一步提升。本文提出了一种融入MD5的 HASH线性扫描获取增量的方法(MD5-Hash Join,M-HJ),采用了HASH查找时间复杂度为O(1)的特性,极大地降低了比对次数;同时通过MD5算法变换属性字段,限定比对字段的个数和长度。M-HJ从整体上来说降低了算法的时间复杂度,实现了线性扫描就能够获取增量数据的目的,提高了增量提取的效率。
2 基于MD5和HASH的增量提取法
2.1 问题分析
通过分析增量提取的过程发现,增量提取问题可等价于求解以下问题:
设有集合 A={a1,a2,…,an}、集合 B={b1,b2,…,bm},求A中不在B中的元素的集合。
数据库中常用的求解问题的方法有两种:(1)SQL语句 NOT EXISTS(N-EXI);(2)Sort-Merge Join方法。
图1展现了在具体情况下,NOT EXISTS和S-MJ两种方法的具体实现。其中NOT EXISTS是将A中所有元素依次去B中探测,如果不存在则该元素为增量;而S-MJ方法是先将A和B分别进行排序,随后线性扫描有序集合A和B得到增量数据。
2.2 算法概述
为了减少多属性字段比对的影响,文献[9]提出了一种在源表中增加这样一个字段,该字段不具备任何意义,但能唯一识别一条记录,就好像影子一样,因此也被形象地称为“影子主码”。“影子主码”解决了多字段比对对效率的影响,变相地限定了比对字段的个数和长度,提高了比对效率;另外,该方法独立于任何的系统平台,具有很好的适应性,能很好地解决分布式数据库的同步和备份问题,但“影子主码”破坏了表的空间结构,在某些系统中,破坏源表结构意味着系统崩溃。
MD5即Message-Digest Algorithm 5(信息摘要算法5)[10-12],它能将任意长度的数据变换成一个128 bit的数。对于任何一个数据,无论数据长短,也不管是何种数据类型,都有且只有一个MD5值,当数据本身发生变化,其MD5值也会发生改变,而两个不同数据的MD5值发生碰撞几率非常小。根据MD5算法的这一原理,当需要提取增量时,可动态生成每条记录的MD5值作为“影子主码”,这样既具备了“影子主码”的优势,也不会破坏源表的空间结构。
散列表(Hash table,也叫哈希表)[13-15],它是基于快速存取的角度设计的,也是一种典型的“空间换时间”的算法;同时是一种根据关键码值(Key value)而直接进行访问的数据结构,通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度,一个设计良好的散列表,其查找时间复杂度为O(1)。根据散列表的这一特性,可以将备份表的所有记录通过散列函数生成散列表,让源表中每条记录去散列表中查找,查找不成功的元素则为增量元素。
2.3 算法描述
现阶段的主流数据库都提供了对MD5和HASH算法的支持,以ORACLE数据库为例,M-HJ算法的过程可以分成以下三个阶段:
准备阶段:利用数据库的存储过程封装MD5方法,使其支持多字段的输入;经过MD5运算得到的128 bit的MD5值经过相应转换可得到一个32 Byte的字符串,因此,该存储过程还需实现这一功能。
初始化阶段:构建备份表,该表只含有一个32 Byte的字段,存储已备份记录的MD5值。
提取阶段:当需要提取增量时,利用封装的MD5方法动态生成源表MD5值,同时将备份中的MD5进行散列得到散列表,对每个动态生成的MD5值去散列表中进行探测,获取增量记录。
这里用S代表原始表,B代表备份表,获得的增量记录存进表C中。所有的过程都是在ORACLE数据库中实现的,具体的算法伪代码如下:


融入MD5的HASH线性扫描获取增量的方法,与传统方法相比较,限定了每次比较字符串的个数和长度,同时降低了总的对比次数,提高了增量提取的效率,在数据量大且属性字段较多的情况下,优势更加明显。
3 算法性能分析
3.1 时间复杂度整体分析
可以用下面的公式来计算增量提取所花费的总时间T:
T=T1+T2×k+T3+T4×b+T5×k+T6×(k-m)+T7×m其中,T1为提取原始表结果集时间;T2为原始表结果集动态生成MD5值所需时间;T3为提取备份表结果集时间;T4为备份表结果集生成散列表所需时间;T5为原始表动态生成的MD5值到散列表中进行查找所需时间;T6为每次具体比对MD5所需时间;T7为增量记录插入临时表所需时间;k为原始记录数;b为备份记录数;m为增量记录数。
分析:其中T1、T3主要受所用硬件资源和具体数据库的性能影响,而T7所需时间则取决于数据库所采取的插入策略,所以主要对T2、T4、T5和T6进行分析。
3.2 明细时间分析
(1)进行MD5运算得到MD5值所需时间T2
T2主要受MD5算法性能的制约,现如今的MD5算法在传统算法的基础之上有了很大的改进,效率明显增强,通常对1 GB数据进行MD5运算只需15~20 s。而两个1 GB大小的文件进行比较的开销要远大于进行MD5运算所花时间,因此当需比对的属性字段越多时,这种优势更加明显。
(2)备份表结果集生成散列表所需时间T4
通过散列函数得到散列地址所需的时间非常小,几乎可以忽略不记,因此生成散列表所需时间T4可看成是对备份表结果集的一次扫描。
(3)MD5值在散列表中进行查找所需时间T5
与T4类似,原始表中动态生成的MD5值在散列表进行查找所需时间T5可看成是对原始表结果集的一次扫描。
(4)进行每次字符串比对所需时间T6
进行MD5运算得到的MD5值只是一个32 Byte的字符串,两个32 Byte长度的字符串进行比较所花时间很小,几乎可以忽略不记。
(5)综合性分析
当所需比较的属性字段越多,且其长度远大于32 Byte时,直接比较这样长度的两个字符串所需时间远大于将字符串进行MD5变换后再进行比较所需时间;假设访问一次结果集并进行散列函数运算所需时间为tc,备份表结果集大小为b,原始表结果集大小为k,则访问备份表结果集并生成散列表所需时间为tc×b,原始表中动态生成的MD5值并在散列表中进行查找所需时间为tc×k,那么所需的总时间为tc×(b+k),也就是说,在这样的前提下,算法的时间复杂度为O(n)。
3.3 小结
综合以上的分析可知,通过属性字段的MD5变换限定了对比字段的个数和长度,采用散列表的方式减少了总体比对次数,提高了效率。又因为该算法的时间复杂度为线性的,所以不会出现对比时间因原始数据的增长而呈现非线性增长,并且在对比属性字段较多的情况下会取得更高的效率。
4 性能测试与结果分析
4.1 测试概述及方法介绍
为了验证本文提出的融入MD5的HASH线性扫描获取数据库增量方法的优势,对传统的S-MJ方法和本文提出的M-HJ方法分别进行了测试和分析。具体以某电信运营商业务支撑中心在实际业务需求中需要提取增量数据的表和对应属性字段为例,分别挑选不同数量级数据表进行测试。为了更好的比对结果,暂不考虑增量记录插入数据库所需时间,只比较识别增量记录所需时间。
4.2 测试环境
操作系统:Windows7;硬件:CPU 2.8 GHz,内存4 GB,硬盘250 GB;数据库:Oracle 10g
由于整个测试过程只涉及到数据读取、MD5运算、HASH映射,对操作系统、软件平台以及开发语言的依赖性很小,因此可以认为经过上述测试方法产生的结果具有普遍性。
4.3 测试结果及分析
4.3.1 测试数据
在表1中,给出了记录总量、增量记录数量以及每条记录所包含的字段数,这几项对增量提取的效率影响最大的要素。
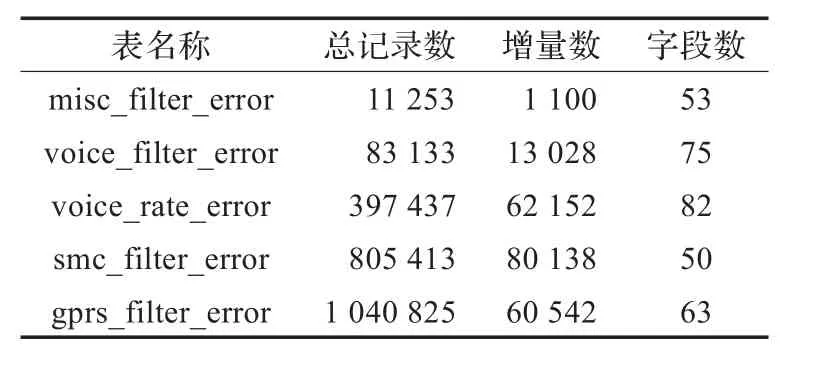
表1 测试表格
4.3.2 HASH线性扫描与排序求差集方法对比
在图2中,给出了在该实验环境下,传统的排序求差集和本文提出的散列表法的对比,从图中可以看出,当数据总量增加时,散列表法的所需时间更少。
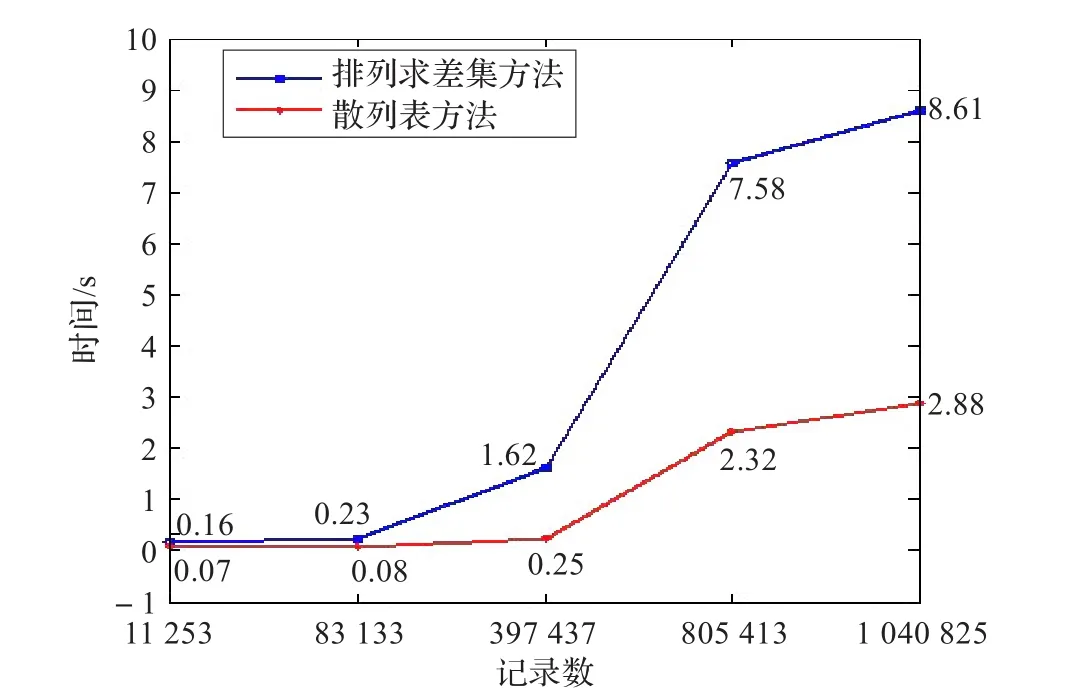
图2 增量提取所选方法的对比
4.3.3 经过MD5变换属性字段的对比
在图3中,给出了在相同实验环境下,字段数量和记录总数,对增量提取效率的影响,从图中可以看出经过MD5转换属性的方法比直接进行全属性字段对比的方法效率更高,随着数据量的增加这种优势会更加突出。
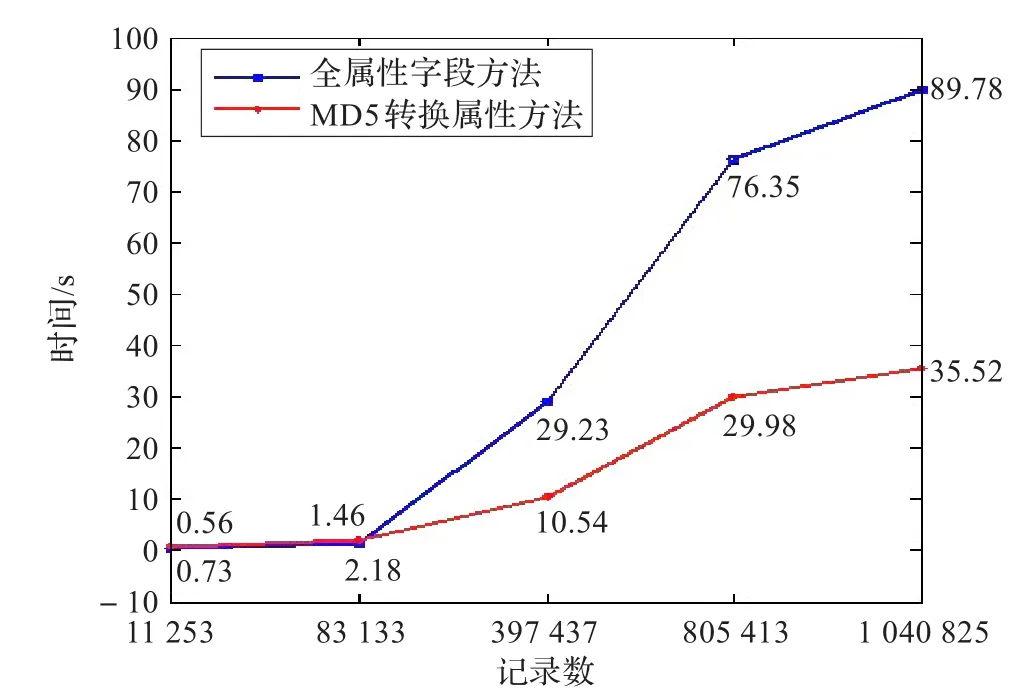
图3 全属性字段与MD5转换字段的对比
4.3.4 综合性能对比
在图4中,给出了相同环境下,采用传统S-MJ法与本文提出的M-HJ法的运行时间对比,从图中可以看到M-HJ法比传统的S-MJ法运行时间要少,尤其随着数据量的增长,在字段较多的情况下,M-HJ方法优势更将加明显。
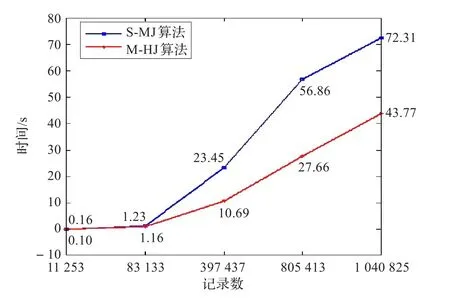
图4 传统S-MJ算法与M-HJ算法的对比
5 结论
本文在传统的增量提取实现方法的基础上,通过属性字段的MD5转换,并结合HASH算法,提出了一种融入MD5的HASH线性扫描获取增量方法。该算法对属性字段的MD5转换限定了对比字段的个数和长度,同时结合散列表的方式,大大降低了记录的比对次数,降低了算法的时间复杂度,提高了增量提取的效率。经过应用测试表明,该算法在增量提取效率上比传统方法有了很大的提高,能够快速识别出增量数据。该算法已在电信运营商业务支撑中心增量数据提取方面得到了应用验证,并取得了较好的结果。由于散列表法是以空间换时间的算法,因此M-HJ法对运行时空间要求较高。
[1]Kimberly K,Cipriano S,Dirk B,et al.Designing for disasters[C]//Proceedings of the 3rd USENIX Conference on File and Storage Technologies,San Francisco,CA,USA,2004:59-62.
[2]Gantz J F,Chute C.The diverse and exploding digital universe:an updated forecast of worldwide information growth through 2011[R].Framingham:IDC,2008:2-16.
[3]Tu P H,Chen Y,Son T C,et al.Incremental information extraction using relationaldatabases[J].Knowledge and Data Engineering,2012,24(1):86-99.
[4]史晶波.在DB2中提取增量数据的一种方法[J].计算机与数字工程,2004,32(6):15-16.
[5]Li Qun,XuHonglin.Researchonthebackupmechanism of Oracle database[C]//Environmental Science and Information Application Technology,2009,2:423-426.
[6]郑祥云,张娟,葛文庚.数据库同步中差异数据捕获方案设计与实现[J].电脑知识与技术,2009,5(7):1544-1545.
[7]Martina-Cezara A,Alfons K,Thomas N.Massively parallel sort-merge joins in main memory multi-core database systems[J].Proceedings of the VLDB Endowment,2012,5(10):1064-1075.
[8]Rogers M.SQL reporting and custom services workshop[C]// ELUNA,2007:5-8.
[9]李懿,罗军.影子主码及其在工作流引擎设计中的应用[J].计算机工程与应用,2006,42(32):158-159.
[10]Ignacio A B,Claudia F U,René C,et al.Design and implementation of a non-pipelined MD5 hardware architecture using a new functionaldescription[J].IEICETransactions on Information and Systems,2008,E91-D(10):2519-2523.
[11]杜昌钰.MD5算法的过程分析及其C#实现[J].通信技术,2008,41(8):71-72.
[12]周林,韩文报,祝卫华,等.MDx差分攻击算法改进及GPGPU 上的有效实现[J].计算机学报,2010,33(7):1177-1181.
[13]Lv Huizhan,Xiao Chenjun,Li Hongye,et al.Hash table in Chinese chess[C]//Control and Decision Conference(CCDC),2012,24:3286-3291.
[14]Xia Weijian,Zhao Heji,Zhao Jiasheng,et al.The XML filtration based on hash table and stream index[C]// Mechatronic Science,Electric Engineering and Computer,2011:1286-1290.
[15]Jimeno M,Christensen K.P2P directory search:signature array hash table[C]//Local Computer Networks,2008,33:506-508.
GUO Liang,YANG Jinmin
College of Information Science and Engineering,Hunan University,Changsha 410082,China
To achieve rapid incremental extraction of database,an algorithm which is blended MD5 in HASH linear scanning to obtain increment is put forward based on analyzing the traditional incremental extraction.Each record in database can be seen as a character string and it can be generated into hash table as duplicate record,which is explored in hash table through traditional record to obtain increment and decrease frequency of comparison.Meanwhile,the fingerprint of each record can be generated with using MD5 algorithm,which reduces the length of character string in every HASH algorithm and comparison and improves efficiency.This algorithm is applicably tested in ORACLE database and the result shows that it is improved on calculative efficiency at a large extent compared with traditional algorithm.
incremental extraction;MD5 algorithm;HASH algorithm;linear scan
为了实现数据库中的快速增量提取,在剖析传统的增量提取方法上,提出了一种融入MD5的HASH线性扫描来获取增量的算法。数据库中的每条记录都可视为一个字符串,利用HASH算法生成备份记录的散列表,通过原始记录去散列表中探测来达到线性扫描就能获取增量的目的,减少了比对次数;同时利用MD5算法生成每条记录的“指纹”,降低了每次HASH运算和比对的字符串长度,提高了效率。对所提出算法在ORACLE数据库上进行了应用测试,结果表明该算法效率较传统方法有很大提高。
增量提取;MD5算法;HASH算法;线性扫描
A
TP311.138
10.3778/j.issn.1002-8331.1301-0132
GUO Liang,YANG Jinmin.Research of incremental extraction based on MD5 and HASH algorithm.Computer Engineering and Applications,2014,50(23):136-139.
国家自然科学基金(No.61272401);“973”子项目(No.2012CB315801)。
郭亮(1987—),男,硕士研究生,研究领域为软件工程、数据库增量提取;杨金民(1967—),男,博士,教授,研究领域为软件工程、容错计算、数据挖掘。E-mail:guoliang0709@163.com
2013-01-14
2013-02-20
1002-8331(2014)23-0136-04
CNKI网络优先出版:2013-04-08,http://www.cnki.net/kcms/detail/11.2127.TP.20130408.1646.010.html
