一种新的基于SVM和主动学习的图像检索方法
2014-08-03彭晏飞尚永刚王德建
彭晏飞,尚永刚,王德建
(1.辽宁工程技术大学电子与信息工程学院,辽宁 葫芦岛 125105;2.渤海装备辽河重工有限公司,辽宁 盘锦 124010)
1 引言
20世纪90年代中期,在文本检索领域中提出的相关反馈技术RF(Relevance Feedback)[1]被引入到了基于内容的图像检索[2]过程中。随着相关反馈的深入研究,许多学者将相关反馈看作模式识别中的有监督学习或分类问题[3],利用成熟的机器学习理论,如神经网络、支持向量机SVM(Support Vector Machine)[4]等,通过对训练样本集的学习,得出用户查询目的与图像特征之间对应的模型,然后根据模型指导新一轮的检索。由于支持向量机在解决小样本、非线性及高维模式识别中表现出的诸多优势,使其得到了广泛的研究和应用。
SVM的引入很大程度上提高了图像检索的检索性能,但如何快速、准确地构造SVM分类器成为了阻碍其发展的主要问题,其中如何选择最优的训练样本成为了其重中之重。主动学习[5,6]算法则为该问题的解决提供了很好的方向,主动学习算法并不是随机地选择训练样本,而是在学习过程中选择最有利于提高分类器性能的未标注样本来训练分类器,该方法能有效地减少评价样本的数量和代价,充分利用最具信息的未标注样本来达到快速学习的目的。近年来在图像检索中已提出了多种基于支持向量机的主动学习方法,但大多都存在一定的局限性,如:文献[7]中提到了一种以样本到分类面距离及训练样本集中样本的余弦距离和为标准的样本主动选择方法。
但是,该方法需要引入平衡因子,而平衡因子的确定在每次实验中都要根据实验要求选择合适的参数,缺乏一般性。文献[8]提出了一种SVM-active主动反馈算法,并认为最接近分类边界的图像最具有信息度(Informative),因此在每个反馈策略中选择最接近SVM分类超平面的样本作为训练样本。但是,此方法的训练样本特征存在冗余,不具有最大信息度。文献[9]提出一种基于K-means聚类的主动反馈策略,该方法提高了反馈图片的多样性,但易受聚类中心和K值的影响,不易达到理想的结果。因此,如何选择既具有最小冗余度,又保持图片多样性的反馈样本作为训练样本成为了研究的首要问题。
针对上述问题,本文提出一种新的基于SVM和主动学习的图像检索方法,通过SVM和新的主动学习方法来构造更好的分类器,包括“V”型删除法和最优选择法。其中“V”型删除法用于快速缩减样本集,最优选择法则是从缩减样本集中选择出既接近分类超平面又具有最小冗余度的最优反馈样本构成训练样本集。在主动学习过程中没有引入任何不确定性变量,从而使得训练出的分类器既准确,又易于实现,可得到更好的检索结果。
2 支持向量机
SVM算法是20世纪90年代中期在统计学习理论基础上发展起来的一种机器学习方法,该方法可以很好地控制学习机器的推广能力,因而在图像检索中可以有效地改善检索结果。在每次训练中对用户标记的正例和反例样本进行学习,建立SVM分类器作为模型,并根据该模型进行检索,如图1所示。
由于在大多数分类问题中,样本集都不是线性可分的,所以本文直接研究样本非线性分类情况。在此情况下,SVM会事先选择一个核函数来将样本的原特征空间映射到一个高维的特征空间,使得样本特征在高维空间中线性可分。
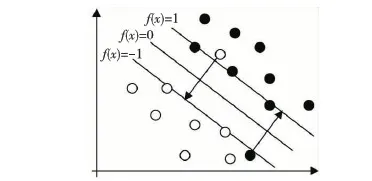
Figure 1 Support vector machine图1 支持向量机
支持向量机算法的描述如下:
记已标注的图像训练样本集为T={(x1,y1),(x2,y2),…,(xl,yl)}∈(Rn×Y)l,其中xi∈Rn表示图像特征,yi∈Y={+1,-1}(+1表示相关,-1表示不相关),其中l表示训练样本集的样本数,则分类超平面的构造即为解决下面的最优化问题:
s.t.yi(w·Φ(xi)+b)-1+ξi≥0,
i=1,2,…,l
(1)
其中,ξi≥0,Φ是将训练数据xi映射到高维空间的映射函数,C是对分类错误的惩罚因子,ξi是松弛项,w是用于决定最优分类面方向的权向量。该最优问题可用如下的对偶形式解决,即:
0≤αi≤C,i=1,2,…,l
(2)
其中,α是Lagrange乘子,核函数K(xi,xj)表示(Φ(xi)·Φ(xj)),K有多种形式,如线性核函数、多项式核函数、径向基核函数、Sigmoid核函数和复合核函数。求解可得最优分类面方程:
(3)

3 本文算法
3.1 预备知识
主动学习是一种人工交互的学习算法,该算法可以通过自动提供未标注样本给训练集来减轻人工负担。其基本思想是选择最具有信息度的样本提供给用户进行标注,即从未标记样本集中选取最优样本集来提高下一轮的检索精度。一般情况下,主动学习方法由两个独立的部分组成:(f,g),其中f代表学习器,g表示查询函数,即从未标记样本集中选取最具有信息度的样本。所以,在主动学习中最重要的就是查询函数g,该函数对主动学习算法的性能起到了主要作用。在各种主动学习算法中,两种最常用的方法是基于不确定样本标注法[10]和基于委员会投票方法[11]来选取要进行标记的样本;在基于不确定样本标注中要选择进行标注的样本是在分类中具有最小确定性的样本,在基于委员会投票方法中,在已标记样本集中训练出分类委员会,然后将其运用到未标记样本集中,并认为在分类中具有最高分类不一致性的样本为最具有信息度的样本。所以,本文中的主要任务就是寻找在每轮的反馈过程中可以获取更好分类效果的样本,这些样本的选择可以使我们以更少的反馈次数得到更好的查询效果。


Figure 2 Sample relationship图2 样本关系
图2中,f(x)=0为分类超平面,f(x)=1为正支撑平面,f(x)=-1为负支撑平面,A、B、C、D为位于分类超平面同一侧的样本,α为样本B、C之间的夹角,β为样本B、D之间的夹角,d(A,B)为样本A、B之间的距离,d(A)为样本A到对应的支撑平面的距离。
首先作以下定义:
定义1样本距离:样本xi、xj之间的距离定义为其欧氏距离,公式如下:
(4)
定义2分类距离:样本到分类超平面距离。若分类超平面方程为f(x),则样本xi的分类距离公式为:
(5)
定义3样本夹角:两样本间连线与分类超平面之间的夹角,其范围为[0,π/2]。样本xi、xj之间的夹角公式为:
(6)
定义4平均角:某一样本与样本集中其它样本的样本夹角的平均值。样本xi的平均角公式为:
(7)
3.2 “V”删除法
在图像检索中往往面临着样本集过大而导致检索时间长、效率低的问题,如何有效缩减样本集成为了提高检索效率的重要研究方向。
传统的样本缩减策略仅仅是删除了距离分类面远的样本,但对于冗余度较高的样本却没有进行有效的处理。文献[12]中提到了一种新的样本缩减策略,但该算法运用C均值聚类算法,从而使得算法复杂度较高。
本文从样本与分类面及样本与样本之间的关系出发,提出一种以样本夹角为基础的“V”型删除法。与传统的样本缩减策略不同的是,该方法不仅可以删除大量距离分类面远的样本,而且可以删除与训练样本近的部分样本,从而得到更优的缩减样本集,并且算法简单、易行。
为减少运算时间,在运用“V”型删除法之前先对未标记样本集进行预处理。因为在SVM中,对分类面有影响的主要有支持向量,所以首先对样本集做预处理,保留到最优分类面距离小于2/w的样本,这样则可以大大缩短计算时间。
假设当前最优训练样本集为F={f1,f2,…,fl},经过预处理的缩减样本集Ul-1={ul-1,1,ul-1,2,…,ul-1,p}。
则“V”型删除法的具体步骤如下:
步骤1利用公式(5)计算当前训练样本fl与Ul-1中所有样本的分类距离,即d(fl)、d(ul-1,i),i=1,2,…,p。


3.3 最优选择法
在SVM的构造中,训练样本的选取是一个亟待解决的问题。传统的方法是选取距离分类面最近的样本作为训练样本,如文献[6,13],但这种完全基于距离的选择原则并不一定能使选择的样本具有多样性,特别是在样本集中的样本属于多个不同类别的情况下就不再可靠了。
针对以上问题,本文提出一种训练样本的最优选择法。该方法所选择出的训练样本不仅与分类面的距离较近,而且训练样本间具有较低的冗余度,从而保证了训练样本的多样性,得到更优的分类器。
假设当前最优训练样本集为F={f1,f2,…,fl},缩减样本集Ul={ul,1,ul,2,…,ul,k}。
则最优选择法的具体步骤如下:

步骤2从样本集Ul中选取同时满足|d(ul,i)|<|d(fl,1)|和〈ul,i,fl,1〉≥(π-〈fl,1,fj〉min)/2,j=1,2,…,l的样本,加入集合Ul′。Ul′初始为空。其中〈fl,1,fj〉min表示fl,1与F中所有样本的最小样本夹角。
步骤3若Ul′为空集,则fl,1即为第l+1个最优的训练样本;否则,从Ul′中选择到Fl+1和F中所有样本的距离和最大的样本为可能最优的训练样本,记为fl,2,加入Fl+1←fl,2,返回步骤2。
步骤4不断重复以上步骤直到样本集Ul′为空集,此时Fl+1={fl,1,fl,2,…,fl,n},则fl,n即为第l+1个最优的训练样本,记为fl+1,则此时最优训练样本集F={f1,f2,…,fl,fl+1}。
3.4 本文基于SVM和主动学习的检索方法
基于以上思路,提出一种新的基于SVM和主动学习的图像检索方法,具体步骤如下:
输入:查询图像Q,图像数据库DB。
初始化:F=∅,U←DB。
步骤1通过计算Q与未标注样本U之间的距离进行相似性排序,输出一个结果集。若用户满意该结果,则算法结束;否则转到步骤2。
步骤2对结果集样本进行标注(相关、不相关),相关图像加入样本集V+,不相关图像加入样本集V-,训练集为V=V+∪V-。在V上训练SVM分类器,得到分类器h1。利用h1对未标注样本进行分类,得到正、负类样本集U+、U-,U-V=U+∪U-。
步骤3从U+∪V+中选取距离分类面最远的N幅图像为输出结果,若用户满意,则算法结束;否则转到步骤4。
步骤4假设每次需要标注的反馈样本数为K,则从U+中首先选择一个距离分类面最近的样本为第一个最优反馈样本,然后根据“V”型删除法和最优选择法得到前K/2个最优反馈样本,即最优的训练样本集F+。
步骤5同理,从U-中得到前K/2个最优训练样本的样本集F-,则用于用户标注的训练结果集F=F+∪F-;然后将训练结果加入训练样本集V←F,剩余样本集U←U-V,返回步骤2。
4 实验及结果
为证明所提算法的有效性,本文实验与传统的基于SVM和主动学习的图像检索算法在同一图像集上进行对比。实验选用Corel图像库,选取10类图像,包括:雪山、大海、建筑、汽车、花卉、大象、恐龙、食物、飞机、马,每类100幅图像,共计1 000幅图像。
随机从每个类别中选取5幅图像,总共50幅图像用于查询。实验中以平均查准率为评价标准来反映算法的检索性能。设s为查询结果中检索到的所有相关图像数目,u为检索到的不相关图像数目,则查准率可以表示为:
(8)
为验证本文图像检索方法性能,在VS2010平台进行实验,图3和图4是在相同检索条件下经过两次反馈后的图像检索结果,从检索结果中可以看到本文算法不仅具有很好的检索性能,而且获得的检索结果具有更好的序列性。

Figure 3 Retrieval results of traditional method图3 传统方法检索结果

Figure 4 Retrieval results of this paper图4 本文方法检索结果
为更好说明本文算法的可靠性,实验以查准率为对比标准,将传统的基于SVM和主动学习的图像检索方法与本文的方法进行了详细的对比实验,实验对比结果如表1和表2及图5和图6所示。

Table 1 Retrieval performance of traditional SVM active learning method表1 传统SVM主动学习检索性能 %

Table 2 Retrieval performance of this paper method表2 本文算法检索性能 %

Figure 5 Average precision rate of Top20图5 Top20的平均查准率

Figure 6 Average precision rate of Top40图6 Top40的平均查准率
上述表1和表2分别为传统SVM主动学习算法和基于本文算法的图像检索实验所得实验数据,图5和图6则显示了两种方法在Top20和Top40的平均查准率。实验结果表明,在相同检索条件下与传统基于SVM主动学习的图像检索相比,本文算法平均具有8%以上的性能提升。由对比实验结果可知,本文提出的方法的确可以使得训练样本得到更好的选择,获得更好的分类器,从而较大幅度地提高检索性能。
5 结束语
本文提出一种新的基于SVM和主动学习的图像检索方法,通过“V”型删除法与最优选择法的结合使用,使得选择的训练样本不仅具有较大的信息度,而且训练样本之间具有很小的冗余度,从而可以扩大所覆盖的样本空间,得到更好的训练结果。在研究本文算法的同时研究了其它的基于SVM主动学习的图像检索方法,发现本文方法不仅易于实现,而且算法中没有引入其它辅助因子,因而无需讨论阈值或最佳值的选取,使得检索更加准确。最后通过实验验证了本文算法的可靠性和高效性。
[1] Wu Hong, Lu Han-qing, Ma Song-de. A survey of relevance feedback techniques in content-based image retrieval [J]. Chinese Journal of Computers, 2005, 28(12):1969-1979.(in Chinese)
[2] Li Xiang-yang,Zhuang Yue-ting,Pan Yun-he.The technique and systems of content-based image retrieval [J]. Journal of Computer Research and Development, 2001, 38(3):344-352.(in Chinese)
[3] Haykin S. Neural networks and learning machines[M]. 3rd ed. MA:Prentice-Hall, 2008.
[4] Zhang Lei, Lin Fu-zong, Zhang Bo. Support vector machine learning for image retrieval [C]∥Proc of IEEE International Conference on Image Processing, 2001:721-724.
[5] Long Jun, Yin Jian-ping, Zhu En, et al. A survey of active learning [J]. Journal of Computer Research and Development, 2008,45(Suppl):300-304. (in Chinese)
[6] Wu Wei-ning, Guo Mao-zu, Liu Yang. A method of active learning with optimal sampling strategy [C]∥Proc of CSAE’12, 2012:725-729.
[7] Xie Hong-Sheng,Zhang Hong.Active learning method based on support vector machine in content-based image retrieval [J]. Journal of Shandong Normal University(Natural Science), 2007,22(4):46-48.(in Chinese)
[8] Tong S, Chang E. Support vector machine active learning for image retrieval [C]∥Proc of the 9th ACM International Conference on Multimedia, 2001:107-119.
[9] Zhang Yu-fang, Chen Zhuo, Xiong Zhong-yang, et al. Image retrieval method based on SVMs and active learning [J]. Computer Engineering and Applications, 2010, 46(24):193-196.(in Chinese)
[10] Cohn D A, Atlas L, Ladner R E. Improving generalization with active learning[J]. Machine Learning, 1994,15(2):201-221.
[11] Seung H S, Opper M, Sompolinsky H. Query by committee[C]∥Proc of the 5th Annual ACM Conference on Computational Learning Theory, 1992:287-294.
[12] Zhu Fang, Gu Jun-hua, Yang Xin-wei, et al. New reduction strategy of large-scale training sample set for SVM [J]. Journal of Computer Applications, 2009,29(10):2736-2740.(in Chinese)
[13] Feng Guo-he.Research on large scale SVM classification based on boundaryK-nearest [J]. Computer Engineering and Applications, 2009,45(23):15-17.(in Chinese)
附中文参考文献:
[1] 吴洪, 卢汉清, 马颂德. 基于内容图像检索中相关训练技术的回顾[J]. 计算机学报, 2005, 28(12):1969-1979.
[2] 李向阳, 庄越挺, 潘云鹤. 基于内容的图像检索技术与系统 [J]. 计算机研究与发展, 2001, 38(3):344-352.
[5] 龙军,殷建平,祝恩,等. 主动学习研究综述 [J]. 计算机研究与发展,2008,45(Suppl):300-304.
[7] 解洪胜,张虹. 基于支持向量机的图像检索主动学习方法[J]. 山东师范大学学报(自然科学版),2007,22(4):46-48.
[9] 张玉芳, 陈卓, 熊忠阳,等. 一种基于SVM和主动学习的图像检索方法 [J]. 计算机工程与应用,2010, 46(24):193-196.
[12] 朱方,顾军华,杨欣伟,等. 一种新的支持向量机大规模训练样本集缩减策略 [J].计算机应用,2009,29(10):2736-2740.
[13] 奉国和. 边界K邻近大样本支持向量机分类[J].计算机工程与应用,2009,45(23):15-17.
