一种基于可预测偏最小二乘法的故障检测方法
2014-08-02杨煜普屈卫东
王 丹 杨煜普 屈卫东
(上海交通大学电子信息与电气工程学院自动化系,上海 200240)
近年来,随着现代化工及冶金等工业过程日益大规模化和复杂化,工业过程的安全问题越来越受到人们的关注。基于多元统计分析的故障检测与诊断方法也成为近年来故障检测与诊断领域的研究热点,并在工业过程中成功应用[1~3]。偏最小二乘(PLS)技术能够根据正常工况的生产数据,准确捕捉质量变量与过程变量之间的关系,对生产工况进行有效监测,且PLS统计检测技术不依赖于过程机理模型,训练时不需要故障样本,能够弥补其他统计方法(例如PCA)无法考虑过程变量对质量变量影响的不足,因此近年来在化工过程的质量控制及在线检测等方面得到了广泛研究和应用[4~6]。但是PLS方法无法反映过程的动态时序特性,这在一定程度上影响了它的故障检测准确率。可预测元分析[7](Forecastable Component Analysis,ForeCA)作为一种新的统计信号处理方法克服了这个不足。可预测元分析是一种全新的用于多变量时序相关信号的特征提取方法,它能从已有的数据中捕捉到系统的动态特性,并以此来预测系统运行变化的趋势,因此所提取的特征能从本质上描述工业过程。
笔者将可预测元分析方法与偏最小二乘法回归方法相结合并用于故障检测,通过将样本映射到可预测子空间,使用最小二乘回归,进一步提高了模型的预测性能,同时构造CUSUM和SPE统计量对系统进行监控,这样能够较好地检测均值偏差在两倍标准差以下的故障。该方法克服了传统偏最小二乘法无法反映过程时序特性的不足,能够预测系统运行变化的趋势,反映出系统的动态特性,因此能够提升故障检测的准确率。
1 基本算法①
1.1 可预测元分析
可预测元分析的基本思想是假设矩阵X∈Rn×m,其中n为样本个数,m为变量个数,通过线性变换WT∈Rk×n,可得:
S=WTX
(1)
其中W为由可预测元列向量组成的可预测元矩阵,S为得分矩阵,ForeCA需要解决的问题即由观测矩阵X估计S和W。

γy(k)=E(yt-μy)(yt-k-μy)T,k∈R
(2)
其中k为时延。
定义单变量平稳过程的谱密度为对其自协方差函数的傅里叶变换,得:
(3)
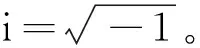
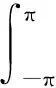
(4)
由文献[7]可知,一个平稳过程的熵越大越难被预测,且白噪声无法被预测,可得:
Hs,a(yt)≤Hs,a(白噪声)
(5)
因此可定义平稳过程的可预测度为:
(6)
对于多变量二阶平稳过程Xt,考虑线性变换yt=wTXt,其中w(w∈Rn)是式(1)中W的列向量,即可预测元,此时yt可以看成是一个单变量的二阶平稳过程。文献[7]给出了ForeCA的最优化问题:
(7)
s.t.wTΣXw=1

对式(7)进行求解,首先使用加权交叠平均谱估计法对随机过程进行谱密度估计[8],再使用EM-Like算法求取可预测元[7]。文献[7]给出了此算法的详细步骤,通过此算法可以得出一组按照可预测度由高到低顺序排列的可预测元,即可得到式(1)中的可预测元矩阵wT。
1.2 偏最小二乘法
给定输入矩阵X∈Rn×N包含n个样本,每个样本N个过程变量,输出矩阵Y∈Rn×M包含n个样本,每个样本M个质量变量。PLS通过隐变量对两个数据块的关系进行建模,它将n×N零均值矩阵X和n×M零均值矩阵Y分解为:
(8)
(9)
式中Ek、Fk——拟合误差矩阵;
P——X的负载矩阵;
Q——Y的负载矩阵;
T——得分矩阵,T=[t1,…,tk];

在PLS模型中,负载向量和得分向量通过最大化解释各自的信息,同时也使X与Y的相关程度最大来求得。最常见的计算PLS模型的算法是Nipals算法,Y的预测回归方程为:
(10)
其中,BPLS是PLS回归系数矩阵,权重矩阵M是由Nipals算法定义的,T=XM。
在复杂的多变量系统中,PLS算法将自变量X和因变量Y看成是具有线性关系的数据矩阵。没有逐个对变量判断其留取与舍弃,而是利用信息分解的思路将显变量系统中的信息重新组合,综合筛选,提取出既能最大程度解释自变量信息,又能最大程度反映自变量与因变量间线性关系的互相正交的综合变量(隐变量)。PLS用独立的隐变量进行建模、预测,使得该方法可以广泛应用于数据不完整、变量间存在多重相关性的场合。
2 基于ForePLS的故障检测模型
2.1 CUSUM统计量
工业过程中存在很多慢漂移的故障,为了检测这种微小的变化,笔者用CUSUM统计量对其进行检测。基于CUSUM统计量的表格累加法为了检测样本均值向上和向下漂移,定义了两个统计量,即:
SH(i)=max[0,xi-(μ0+K)+SH(i-1)],SH(0)=0
(11)
SL(i)=max[0,(μ0-K)-xi+SL(i-1)],SL(0)=0
(12)
(13)
其中μ0是样本实际的均值,xj为第j个样本值,笔者用训练样本均值代替。K为参考值,一般取0.5Δ,Δ为期望检测出的偏差,取值在[0.5σ,2.0σ]内。其控制限为5倍的标准差[9]。
2.2 SPE统计量
首先选取一段正常工况下的观测数据X(X∈Rn×N),其中n为变量个数,N为采样点数,对其运用ForeCA算法,得可预测元矩阵:
WT=[w1,w2,…,wn]T∈RN×N
(14)
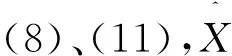
(15)
过程残差可表示为:
(16)
(17)
SPE统计量的控制限用核密度估计确定,具体参见文献[11]。
2.3 基于ForePLS的故障检测步骤
基于ForePLS的故障检测分为两个阶段——离线训练阶段和在线检测阶段。
离线训练阶段。首先采集正常工况下的训练数据X,对其进行预处理后,使用ForeCA算法提取出可预测主元矩阵W,然后在可预测子空间进行PLS回归,再计算训练数据在可预测子空间的CUSUM统计量和SPE统计量,最后计算两个统计量的控制限——H和SPEα。
在线检测阶段。首先根据实时采集的未知状态的数据集,将此可预测模型运用于在线数据,分别计算每个样本数据的CUSUM和SPE统计量,最后比较两个统计量与其对应控制限的大小,通过比较确定系统是否发生故障。如果检验结果在控制限以内,则说明目前系统工作在可预测模型所预测的变化范围之内,即系统工作正常;反之,则说明目前系统的工作状态已经偏离可预测模型所预测的变化范围,判断系统已经出现了故障。
3 TE实验平台故障分析
TE实验平台是Downs和Vogel根据Eastman化学公司的世界工艺流程做了少许修改于1993年提出的[12],其中包含21个预设故障。TE过程由连续搅拌式反应釜、分凝器、气液分离塔、汽提塔、再沸器及离心式压缩机等多个操作单元组成,其流程如图1所示。
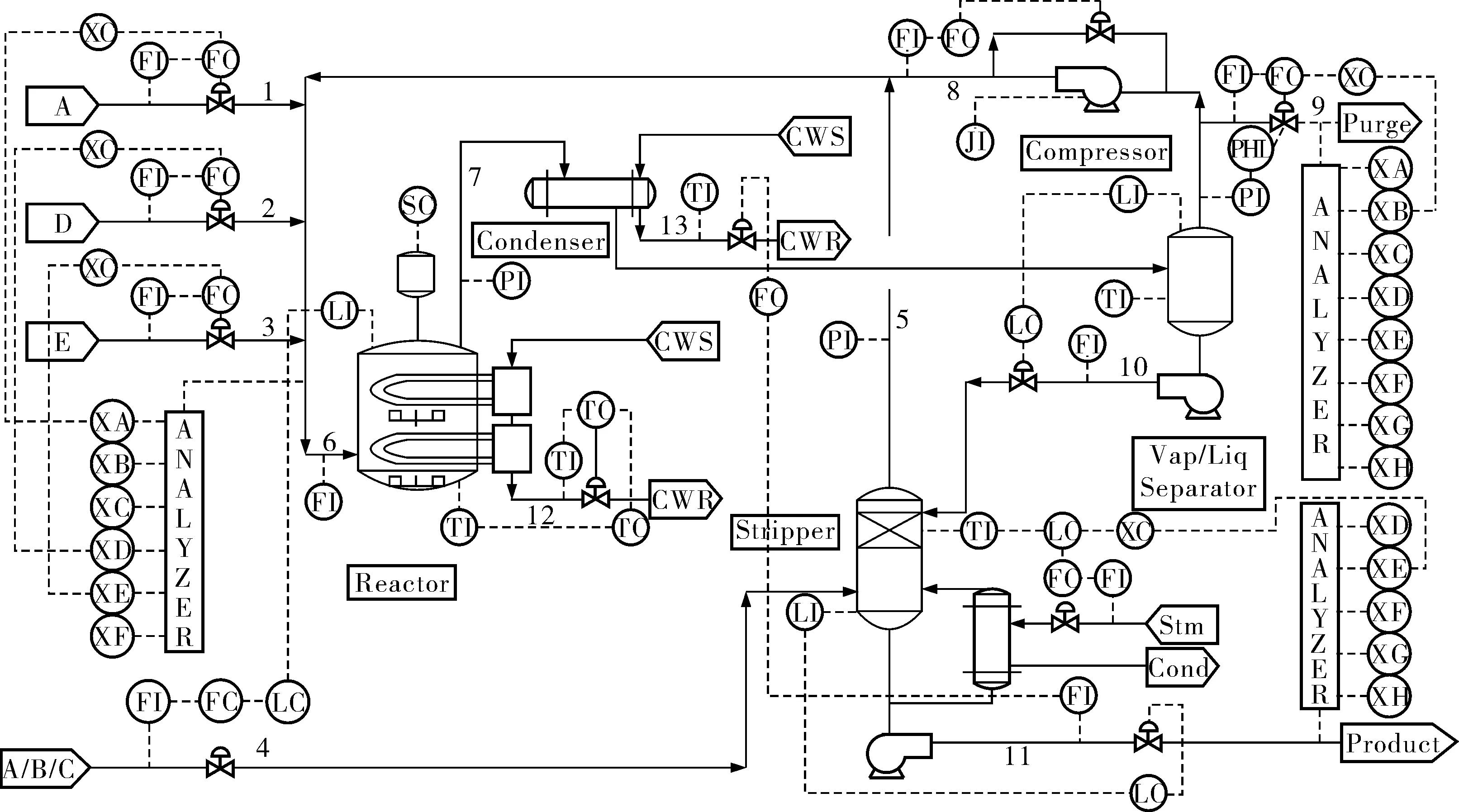
图1 TE流程
TE过程共有A、C、D、E 4种气体进料,G和H两种反应产物,F一种副产品。系统中存在的化学反应如下:

以上各式中,g代表气体,liq代表液体。所有的反应都是不可逆放热反应,反应速度取决于温度和反应物的气相浓度。
TE模型用于训练的样本数据为500个52维向量,用于测试的样本数据为960个52维向量,其中故障从第161个样本点开始引入。笔者选择过程中的G和H(即MEAS35和MEAS36)作为ForePLS模型的质量变量Y;选取22个过程变量MEAS1~22和11个操作变量MV1~11作为X。采用ForePLS模型对TE过程的反应产物G的含量的预测结果如图2所示,可以看出ForePLS有很好的预测能力。
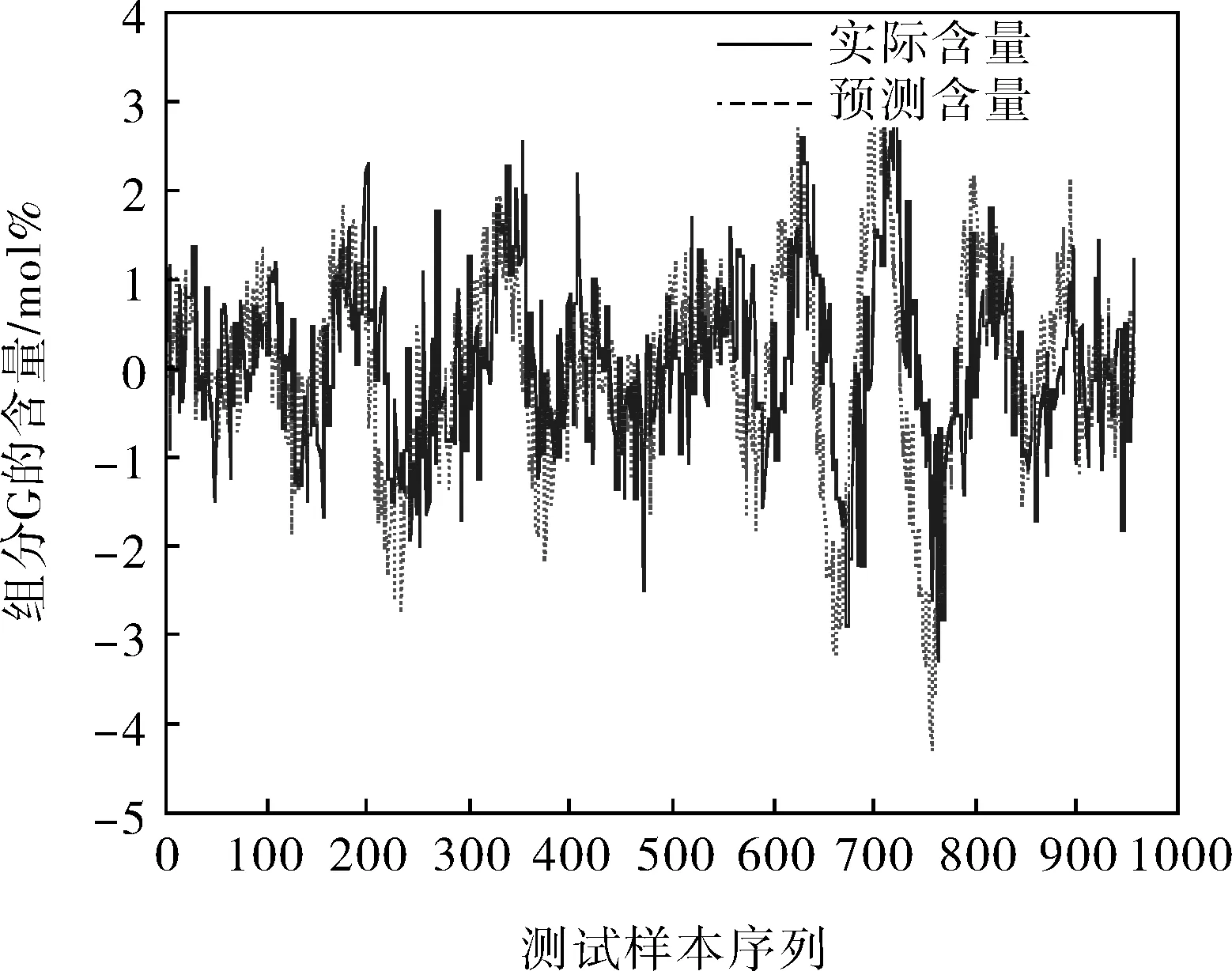
图2 故障10发生时产品中组分G的含量曲线
下面以随机变化故障中典型的故障IDV(10)为例加以分析。故障IDV(10)发生时,供料C的温度产生了随机变化。为了验证ForePLS的有效性,将其与PCA和PLS两种方法进行对比。实验中,ForePLS的隐变量个数为6,PCA的主元个数为15,PLS的隐变量个数为9,期望检测到的均值偏离为0.5倍的标准差。图3显示了PCA、PLS和ForePLS 3种方法对故障IDV(10)的检测效果。可以看出,PCA的T2统计量和SPE统计量的准确率分别为45.6%和53.9%;PLS的两个统计量的检测准确度都较低,分别为18.8%和27.8%;ForePLS的CUSUM和SPE统计量的准确率为96.5%和52.9%。由此说明,笔者所提出的基于ForePLS的故障检测方法检测随机变化的故障准确率比PCA和PLS方法更好。
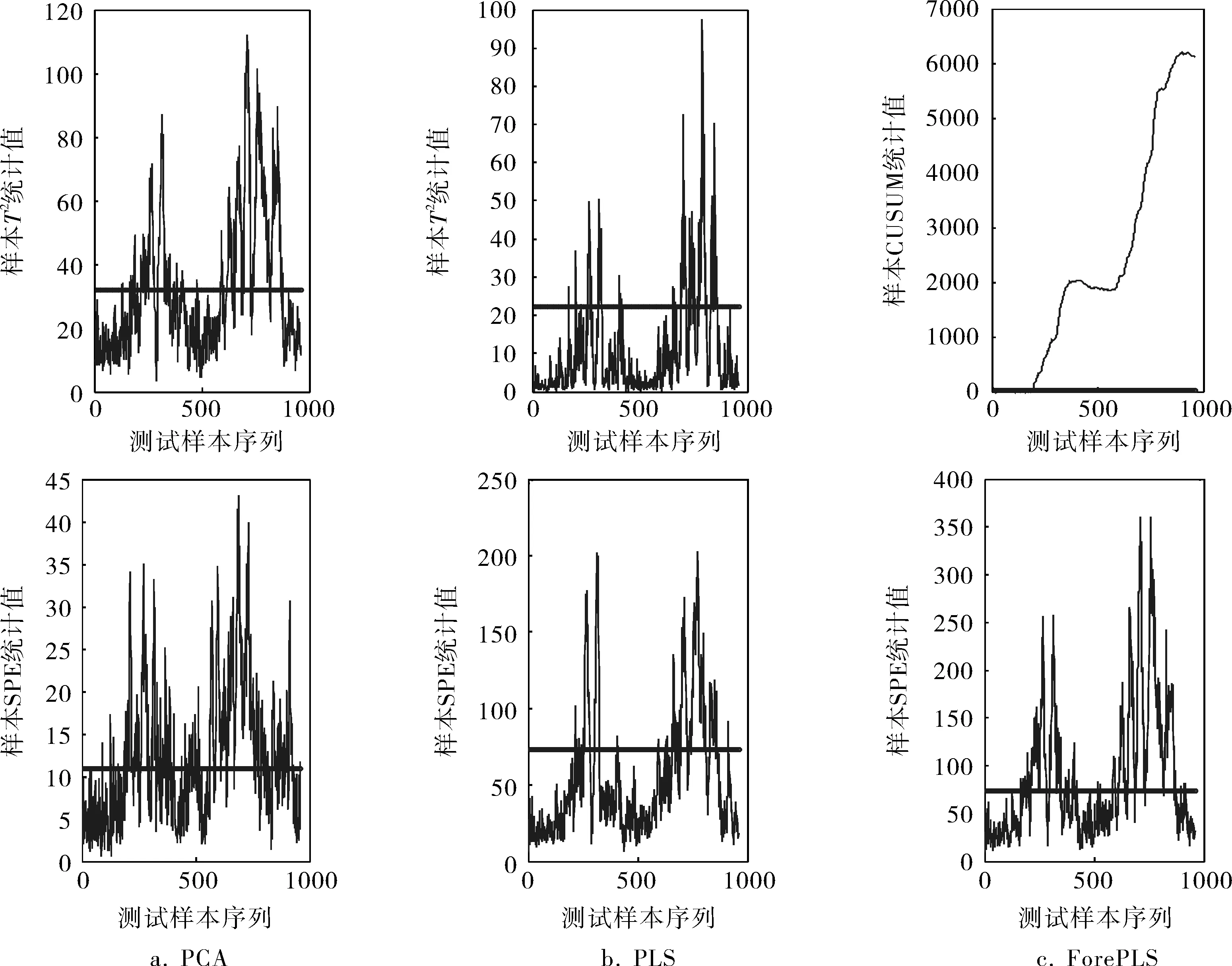
图3 IDV(10)发生时PCA、PLS和ForePLS方法的故障检测性能比较
4 结束语
介绍了一种基于可预测元分析和最小二乘回归法相结合的故障检测方法。该方法克服了传统最小二乘法无法反映过程时序特性的不足,能够有效预测系统运行变化的趋势,反映出系统的动态特性。通过检测可预测空间上的CUSUM统计量和SPE统计量,以达到检测慢漂移等微小故障和随机变化故障的目的。在TE模型上的仿真表明:该方法比传统的PCA、PLS方法检测精度更高,效果更好。
