基于MapReduce的序列规则在推荐系统中的研究
2014-07-25元二菊郭进伟皮建勇
元二菊 ,郭进伟 ,皮建勇
(1.贵州大学 计算机科学与信息学院,贵州 贵阳550025;2.贵州大学 云计算与物联网研究中心,贵州 贵阳550025)
21世纪以来,随着互联网的飞速发展,人类已经进入信息社会的时代。互联网对人们的生活影响越来越大,越来越多的人通过互联网发布和查找信息,网络成为了人们生活中必不可少的一部分,也成为信息制造、发布、处理和加工的主要平台。现如今,互联网已经逐渐参与到人们工作、生活、学习的各个方面,成为人们获取所需信息、进行学习工作和信息交流的主要场所,并对人们的生活和社会的发展产生了巨大影响。
个性化推荐系统是一种以海量数据挖掘为基础的智能平台,这个平台借助于电子商务网站来为顾客提供因人而异的个性化决策支持和信息服务。个性化推荐系统逐渐地被应用于各种商业网站,它因人而异地根据每个用户的喜好主动地为其预测、推荐符合需求的商品,从这一点上弥补了信息系统的不足。随着个性化推荐系统的不断完善,各种算法被深入研究。目前最常用的推荐模型是以协同过滤为基础的。尽管基于协同过滤算法的应用比较成熟,但它有着自身固有的缺点[1],这使得它需要与其他方法结合使用。
本文第1部分介绍了MapReduce编程模型,第2部分描述了一种简易的基于序列模式的推荐系统的框架,第3部分介绍该框架在MapReduce模型下的实现,最后在总结部分提出了该框架的不足及需要改进的地方。
1 MapReduce编程模型
2004年,谷歌发表论文向全世界介绍了GFS[2]和Map-Reduce[3]等模型,为大规模并行数据的计算和分析提供了重要的参考。MapReduce编程模型通过显式的网络拓扑结构尽力保留网络带宽,并尽量在计算节点上存储数据,以实现数据的本地快速访问,从而带来了良好的整体性能。
MapReduce的设计灵感来自于Lisp等函数式编程语言中的map和reduce原语,相应的 map和reduce函数由用户负责编写,它们通常遵循如下常规格式:
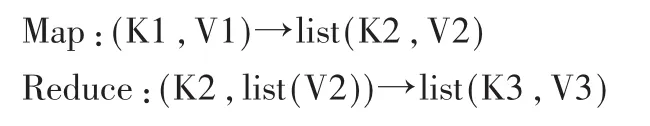
具体的MapReduce操作流程如图1所示。

图1 MapReduce模型执行流程
对图1中的流程可以描述如下:
(1)用户程序利用MapReduce相关接口先把输入文件划分为若干份,每一份的大小根据其分布式文件系统的块的大小进行设定,然后使用fork在系统中创建主控进程(master)和工作进程(worker)。
(2)主控进程负责调度,为空闲worker分配作业(Map作业或者Reduce作业)。主控进程根据输入文件的划分分配相应的Map作业,同时,主控进程还将分配若干个Reduce作业。
(3)被分配了Map作业的 worker,开始读取对应分片的输入数据,Map作业数量由输入文件的划分决定,与split一一对应;Map作业从输入数据中抽取出键值对,每一个键值对都作为参数传递给map函数,map函数产生的中间键值对被缓存在内存中。
(4)缓存的中间键值对会定期写入本地磁盘,而且被分为R个区,R的大小由用户定义,将来每个区会对应一个Reduce作业;这些中间键值对的位置会通报给master,master负责将信息转发给Reduce worker。
(5)主控节点通知分配了Reduce作业的 worker它负责的分区在什么位置,当Reduce worker把所有负责的中间键值对都读过来后,先对它们进行排序,使得相同键的键值对聚集在一起。因为不同的键可能会映射到同一个分区也就是同一个Reduce作业,所以排序是必须的。
(6)Reduce worker遍历排序后的中间键值对,对于每个唯一的键,都将键与关联的值传递给reduce函数,reduce函数产生的输出会添加到这个分区的输出文件中。
(7)当所有的Map和Reduce作业都完成了,master将会唤醒用户程序,用户程序对MapReduce平台的调用由此返回。
MapReduce是一个简便的编程模型,编程人员只需要实现其中的Map函数和Reduce函数即可。
2 框架描述
序列模式挖掘[4]是指找出所有满足用户指定的最小支持读的序列,每个这样的序列成为一个频繁序列,或者一个序列模式。本文描述的算法基于序列模式挖掘,但是不考虑最小支持度,并且经过一次循环即可挖掘出模式,所以不存在产生候选项集。
通常个性化推荐系统分为3个阶段:数据预处理阶段、模式发现阶段和推荐阶段。其中数据预处理阶段和模式发现阶段都是推荐系统定期执行的(即离线部分),而推荐阶段是实时的(即在线部分),因为系统需要通过用户访问的信息及时生成推荐信息。

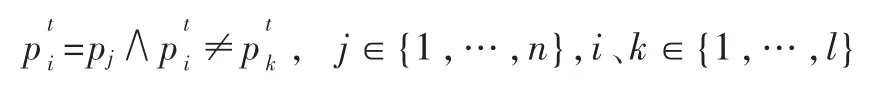
在用户事务t中,的访问时间一定晚于的访问时间(i>j),因为用户不可能同一时间访问不同的两个页面。
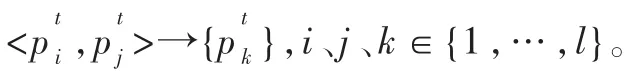

图2 页面间隔为1时的模式生成
在推荐阶段,需要对用户浏览过的页面实时地进行分析,并预测用户要点击的页面,动态地为用户推荐可能要浏览的页面,因此在本阶段引入活动窗口。如果根据用户最新浏览的两个网页进行推荐,则窗口大小为2。为便于理解,暂时讨论活动窗口为3的情况。例如用户u的活动窗口为〈A,B,C〉,假设用户u下一个页面点击了页面 D,则活动窗口改为〈B,C,D〉,在此基础上用户u下一个页面点击了页面 D,则活动窗口改为〈B,D,C〉。如图3所示。系统根据用户的活动窗口,在已经挖掘到的模式中进行查询,如果查询到结果页面,并且不止一个结果页面,则可以根据模式比值进行相应处理,可以将比值最高的作为推荐页面返回给用户,也可以将比值排名前几的作为推荐页面返回给用户。
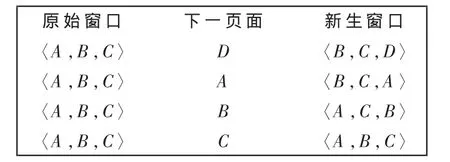
图3 活动窗口变化规律
3 MapReduce算法设计
在MapReduce算法设计[5]中,定义活动窗口的大小为2,并且默认数据经过预处理并保存在文本文件中,文本文件的一行为一个用户的事务,一个单词表示为一个项,项与项之间用空格隔开。
3.1 Map阶段
Map阶段输入数据的键值对,Key为文本的行标,在本文中没有实际意义,Value为文本中的一行数据。Map阶段的伪代码如下:

3.2 Reduce阶段
在Reduce阶段,Reduce工作节点从远程Map工作节点读取中间结果。在此阶段中,统计出模式出现的频率,并得出与事务总数的比值,最后输出结果键值对。

本文提出了一种简易的基于序列模式的推荐模型,并结合MapReduce,实现了在大数据条件下进行模式挖掘的系统,弥补了常见的个性化推荐系统缺少时序的缺点,可以作为辅助的个性化推荐系统的应用。但本文缺少实验数据,没有进行实现分析,从而略显遗憾。并且存在以下问题需要在以后的工作中继续研究:
(1)个性化推荐的研究是基于用户行为的研究,尤其是用户Web浏览行为[6],用户对不同类别的Web浏览习惯存在较大的差别。本文在用户事务和活动窗口中均没有考虑重复页面的情况,并且活动窗口固定大小,因此在后续工作中应加入特定条件下用户行为的研究。
(2)在事务中的项较多的情况下,可以考虑对项进行分类的策略,但是不同类别的项之间也可能存在关联,在活动窗口中也可引入类别的概念,可以考虑同类别项之间的前后顺序,而不像本文只单纯地考虑浏览页面的顺序,这也将在后续工作中进行研究。
[1]SARWAR B,KARYPIS G,KONSTAN J,et al.Item-based collaborative filtering recommendation algorithms[C].In Proceedings of the Tenth International.World Wide Web Conference on World Wide Web,2001.
[2]GHEMAWAT S,GOBIOFF H,LEUNG S-T.The Google file system[C].Procedings of 19th ACM Symposium on Operating System Principles,2003:29-43.
[3]DEAN J,GHEMAWAT S.MapReduce:simplified data processing on large clusters[J].Communications of the ADM-50th Anniversary lssue:1958-2008,2008,51(1):107-113.
[4]AGRAWAL R,SRIKANT R.Mining sequential patterns[C].
In Proc.of the Intl.conf.on Data Engineering,1995:3-15.
[5]WHITE T.Hadoop:the definitive guide[M].Yahoo Press,2010.
[6]MOBASHER B,DAI H,LUO T,et al.Effective personalization based on association rule discovery from web usage data[C].Proceedings of the 3rd International Workshop on Web Information and Data Management,2001:9-15.
