一种基于划分的周期性话题挖掘方法研究
2014-07-25邓定胜
邓定胜
一种基于划分的周期性话题挖掘方法研究
邓定胜
周期性话题挖掘是目前数据挖掘领域的研究热点之一,针对当前绝大部分研究只限于时间序列数据库、无法直接应用于文本数据的不足,提出了一种基于划分的周期性话题挖掘方法(PTMP),首先,将话题划分为周期性话题、背景话题和突发性话题,然后,将每个周期性话题的时标分布建模为混合高斯分布,为了缓解背景噪声问题,通过均匀分布生成背景话题的时标,用高斯分布来生成突发话题的时标,然后通过将该混合模型根据时标文本数据进行调整,从而发现周期性话题及其时间分布。最后,收集了包括研讨会、DBLP和Flickr在内的多个代表性数据集,验证方法的有效性。
周期性话题;数据挖掘;混合高斯分布;噪声;时标
0 引言
随着Web技术的发展,许多文本数据带有时间信息,比如新闻带有发布日期,Flickr照片带有拍照日期(http://www.flickr.com),Twitter(http://twitter.com)上发布的tweet带有上传时间。这些文本数据蕴含了许多有用信息。发现周期性话题并描述它们的时间模式,是个非常有趣的课题。由于周期性分析的重要性,人们针对时间序列数据库进行了周期性检测研究[1,2]。一些研究为了检测周期性模式,在分析单个标记或单次查询的时间分布时使用的策略非常类似[3]。然而,当前绝大部分研究只限于时间序列数据库,无法直接应用于文本数据。首先,一个词组并不足以描述一个话题,只有更多的词组才能全面概括一个话题。其次,只对单个词组进行分析并不足以发现周期性话题。例如,“音乐”、“节日”、“芝加哥”等词组如果单独考虑,不会展现出周期性模式,但如果综合考虑则可能存在周期性话题。第三,由于语言的多样性,存在许多同义词和多义词,这让周期性话题检测更加困难。
本文提出PTMP方法来处理以上问题。本文方法不是根据单个词组或模式出现的周期性展开分析,而是利用了词组的周期性及共生性,进而检测出以词组分布为载体的周期性话题。本文贡献总结如下:(1)首次引入潜在周期性话题分析问题。(2)提出PTMP模型,通过利用词组的周期属性及共性结构来检测周期性话题。(3)基于多个代表性数据集进行全面的实验,证明了本文算法的有效性。
1 相关工作
相继有众多学者提出了一系列方法用于解决周期性话题挖掘问题。如Mei等人[4]将时线分割为多个储体,并提出概率算法对网络博客的子话题主题和时空主题模式同时建模。Wang等人[5]从同等处理过后的文本流中挖掘相关的突发话题模式。Blei等[6]针对话题多项式分布的自然参数使用了状态空间模型,设计了一种动态话题模型,以模拟文件流的时间进化情况。Iwata等人[7]提出了一种在线话题模型,可依次分析文档集合话题的时间进化情况,该模型假设根据上一时间的多尺度词汇分布生成了具体话题的当前词汇分布。Lahiri等人[8]提出了如何在动态社交网络中检测周期性或近似周期性子图这一新的数据挖掘问题。Murata等人[9]根据搜索意图数量及其时间特性来对检索分类,然后对每个搜索意图的比例进行离散傅立叶变换,以检测出周期性变化。然而,这些研究只分析了单个词汇的分布。本文则采用更为系统的方式,对潜在周期性话题分析进行建模,每个话题用词汇分布表示。然后,从话题而非单个词汇角度分析周期性模式,并对周期性突发情况及其对应话题实现了同步检测,而不是分步进行。
2 问题建模
本节将对潜在周期性话题分析问题进行定义。本文所用标记法如表1所示:
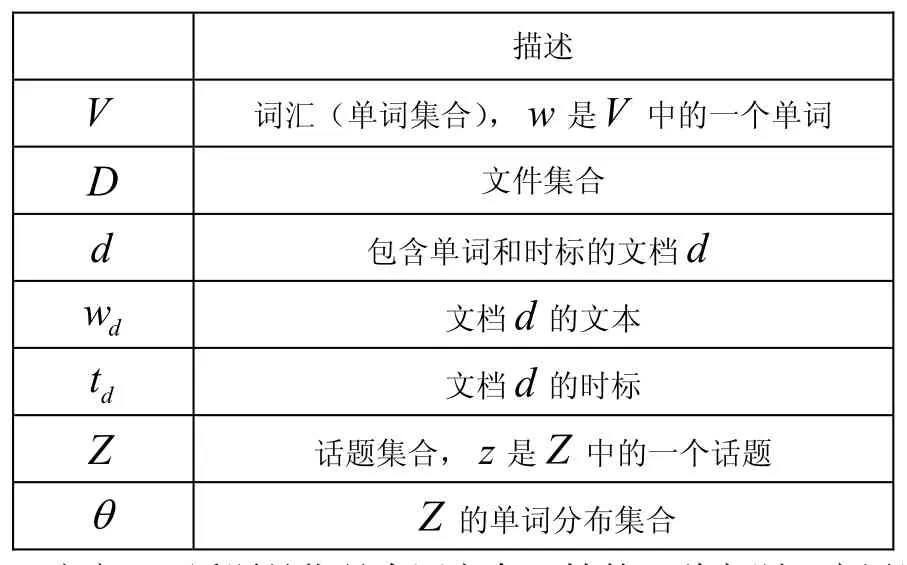
表1 本文采用的标记法
定义1:话题是指具有语义条理性的一种主题,它通过词组的多项式分布表现出来。一般地,每个话题z可表示为如下词组分布:
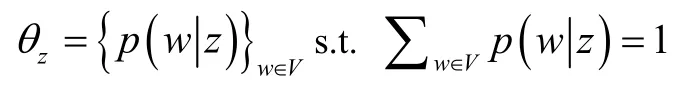
定义2:周期性话题 是指定期重复的一种话题。给定话题z且时间t时的条件概率遵守周期性间隔为T的周期性模式。换句话说,每个话题的时标分布每隔时间T展现一次。周期性间隔T可由用户根据自身需要确定,可以是1周、1月、1年,等等。
定义3:时标文档 是指带有时标的文本文档。它可以是带有发布时期的新闻,带有发布时期的Twitter网上的鸟叫声,也可以是带有上传日期的Flickr网上的照片,此时照片上的标记可以看成是文本,照片的拍摄时间可以看成是照片的时标。
有了时标文件和周期性话题定义后,本文可以定义潜在周期性话题分析如下:
定义4:给定一组时标文档D,周期性间隔T,话题数量K,我们希望发现每隔时间T便重复一次的K个周期性话题,即其中Z为话题集合,时间分布
3 潜在周期性话题分析
本节给出PTMP模型。首先,介绍本文模型的总体思路。然后,详细介绍本文周期性话题生成过程。最后,解释如何估计参数。
3.1 总体思路
我们将每个周期性话题的时标分布建模为混合高斯分布,其中两个连续部分的间隔为T。除了周期性话题外,文档集合可能包括背景词汇。为了缓解背景噪声问题,我们在模型中对背景话题进行了建模。尤其地,通过均匀分布生成背景话题的时标。除了周期性话题和背景话题外,我们使用突发话题来模拟短时间而非经常性的突发行为模式。用高斯分布来生成突发话题的时标。因此,文档集合建模为背景话题、突发话题、周期性话题的混合。通过将该混合模型根据时标文本数据进行调整,我们可以发现周期性话题及其时间分布。
3.2 PTMP方法
(1)从多项式dφ中采样一个话题z。(a)如果z是背景话题,则从均匀分布中采样时间t,其中tstart和是文档集合的开始和截止时间。(b)如果z是突发话题,从采样t。(c)如果z是周期性话题,从均匀分布中采集文档d的周期k,从采集时间t,其中T是周期性间隔。
(2)从多项式zθ采集一个词汇w。若有数据集合,其中wd是文档d的词汇集合,td是文档d的时标,时的集合对数似然概率为公式(1)、(2):
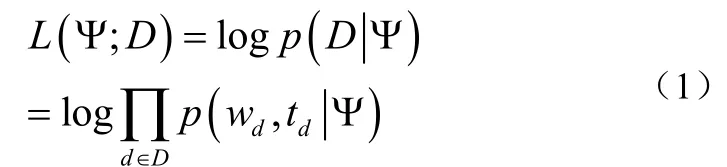
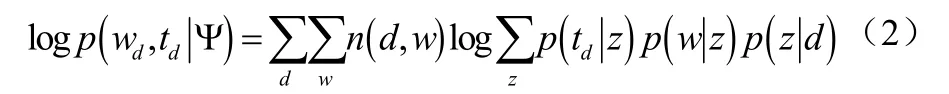
其中,n( d, w)是文档d中词汇w的数量。
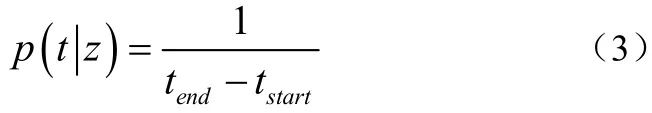
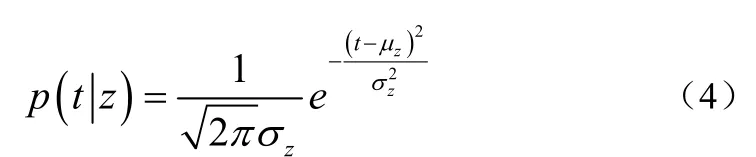
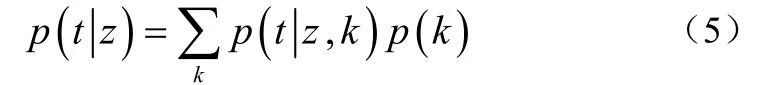
3.3 参数估计
为了估计等式1中的参数Ψ,我们使用最大期望估计(EM)算法[6]来解决问题,循环计算似然局部最大值。本文引入隐藏参数概率表示文档d词汇w属于话题z的概率。在步骤E时,它计算完整似然期望值,其中是在第t次迭代时w的估计值。在步骤M时,它可以获得使完整似然期望最大化的估计值
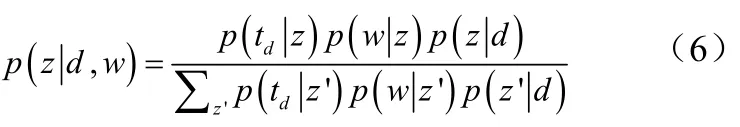
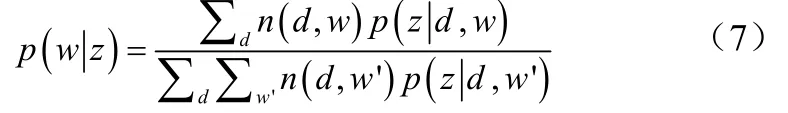
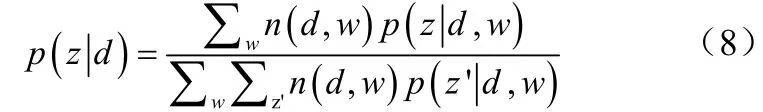
如果z是突发话题,zμ和zσ做如下更新为公式(9)、(10):
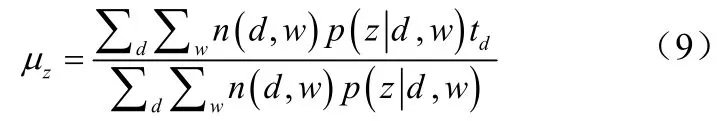
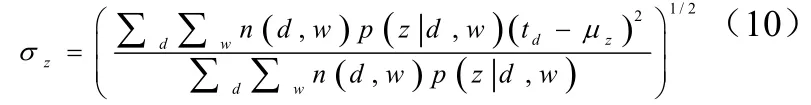
如果话题z是周期性话题,我们将时间线分为长度为T的多个间隔,并假设每个文档只与对应的间隔有关。换句话说,如果文档d未在第k个间隔,则式5中的设为0。周期性话题z的zμ和zσ做如下更新为公式(11)、(12):
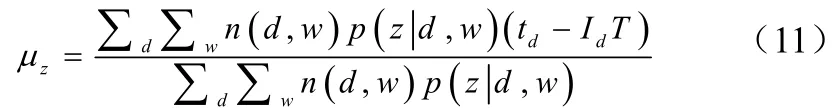
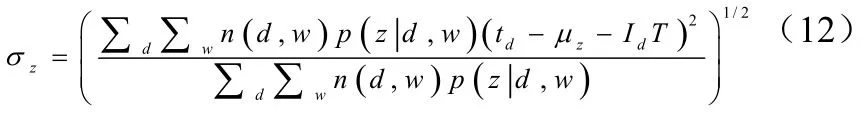
其中,Id是文档d的对应间隔。
4 实验
4.1 数据集
本文基于多个数据集来评估所提方法:
1)研讨会数据。我们收集了伊利诺斯州大学(http://cs.illinois.edu/)计算机专业6个研究小组一个学期内的每周研讨会声明。6个研究小组的研究内容包括AIIS(人工智能和信息系统),DAIS(数据库和信息系统),图像,HCI,理论和UPCRC(通用并行计算研究中心)。研讨会时间作为文档时标。为了确定每周话题,本文把周期间隔设为1周。该研讨会数据集共有61个文件和901个词汇。
2)数字目录工程DBLP数据。它是基于计算机科学的目录项目。我们收集了2010到2013年不同会议的论文题目。会议包括WWW, SIGMOD, SIGIR, KDD,VLDB和NIPS。根据项目安排确定文档的时标。为了发现年度话题,本文设置周期性间隔T为1年。该DBLP数据集有4070个文档和2132个词汇。
3) Flickr。Flickr是一个在线照片共享网站。从Flickr API(http://www.flickr.com/services/api/)选择照片。照片标记作为文档文本,照片拍摄时间作为文档时标。根据实际情况,本文选择了2009到2013年间多个音乐会的照片,例如SXSW (South by Southwest), Coachella, Bonna-roo,Lollapalooza和ACL (Austin City Limits)等。我为了发现年度话题,设置周期间隔为1年。该数据集共有84244个文档和7524个词汇。
4.2 定量评估
(1)PTMP话题检测:结合数据集构建情况,我们分别设置研讨会、DBLP和Flickr的周期性话题数据为6、6、5。如表2所示:
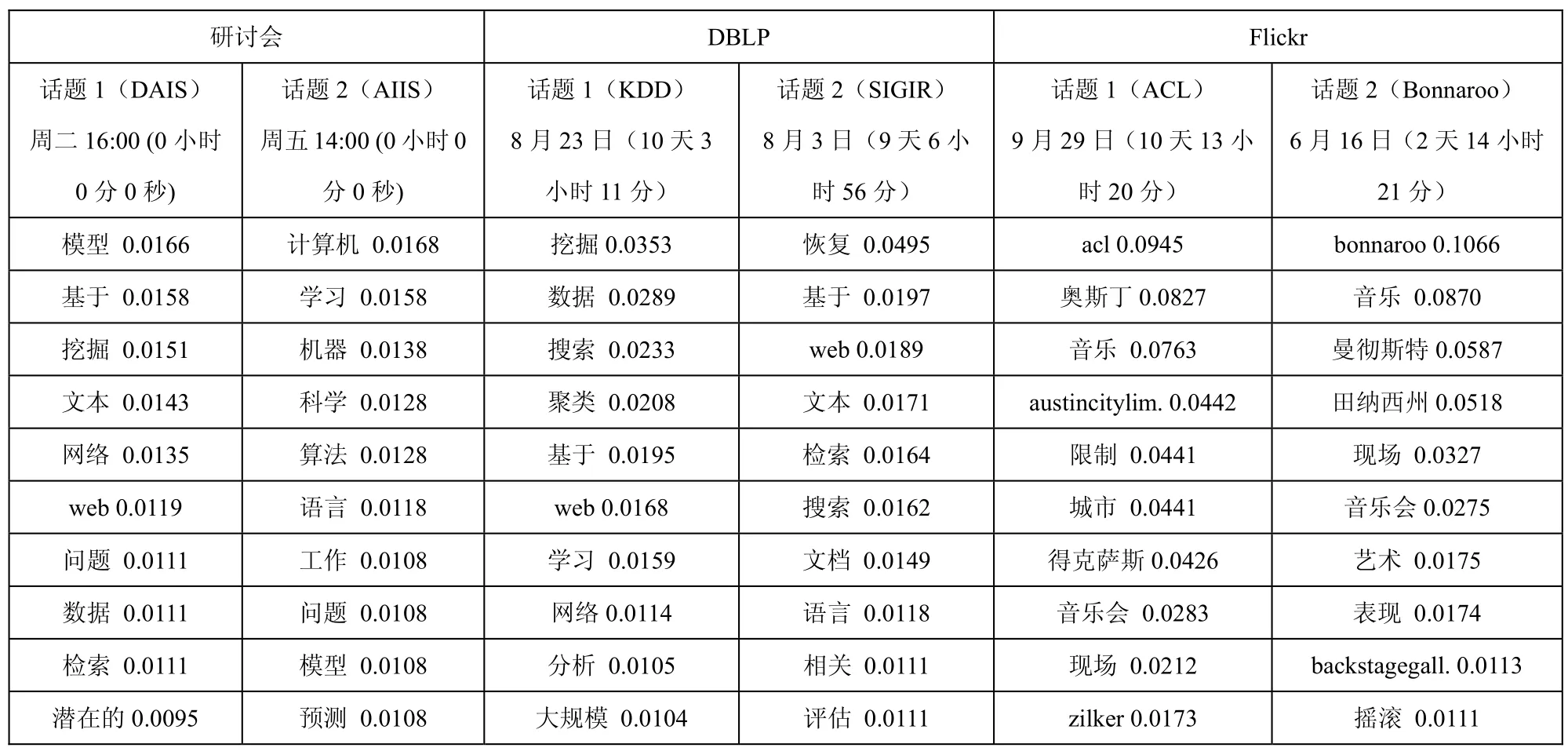
表2 基于PTMP的部分周期性话题检测。日期和括号中的持续时间是对应周期性话题时标的均值和标准差。
PTMP在不同数据集检测出来的部分话题。对研讨会数据集,PTMP可以有效检测不同研究小组的话题及其对应时间。例如,第一个话题是DAIS,每周二下午4点,主流词汇为数据、文本和挖掘。第二个话题是AIIS,每周5下午两点,主要内容是机器学习和算法。对DBLP数据集,PTMP可以检测出6个周期性话题,也就是6个年度会议。例如,第一个话题是8月的KDD,议题是数据挖掘。第二个话题是SIGIR,主要议题是数据检索、网络、搜索、相关性和评估。对Flickr数据集,PTMP可以有效检测出音乐节及其持续时间。
(2)PTMP VS周期性检测。为了证明把相关词汇放在一起检测比各个词汇单独分析更为合理,我们对PTMP和周期性检测算法做一对比。与单个词汇表示相比,PTMP使用多个词汇描述话题,如表3所示:
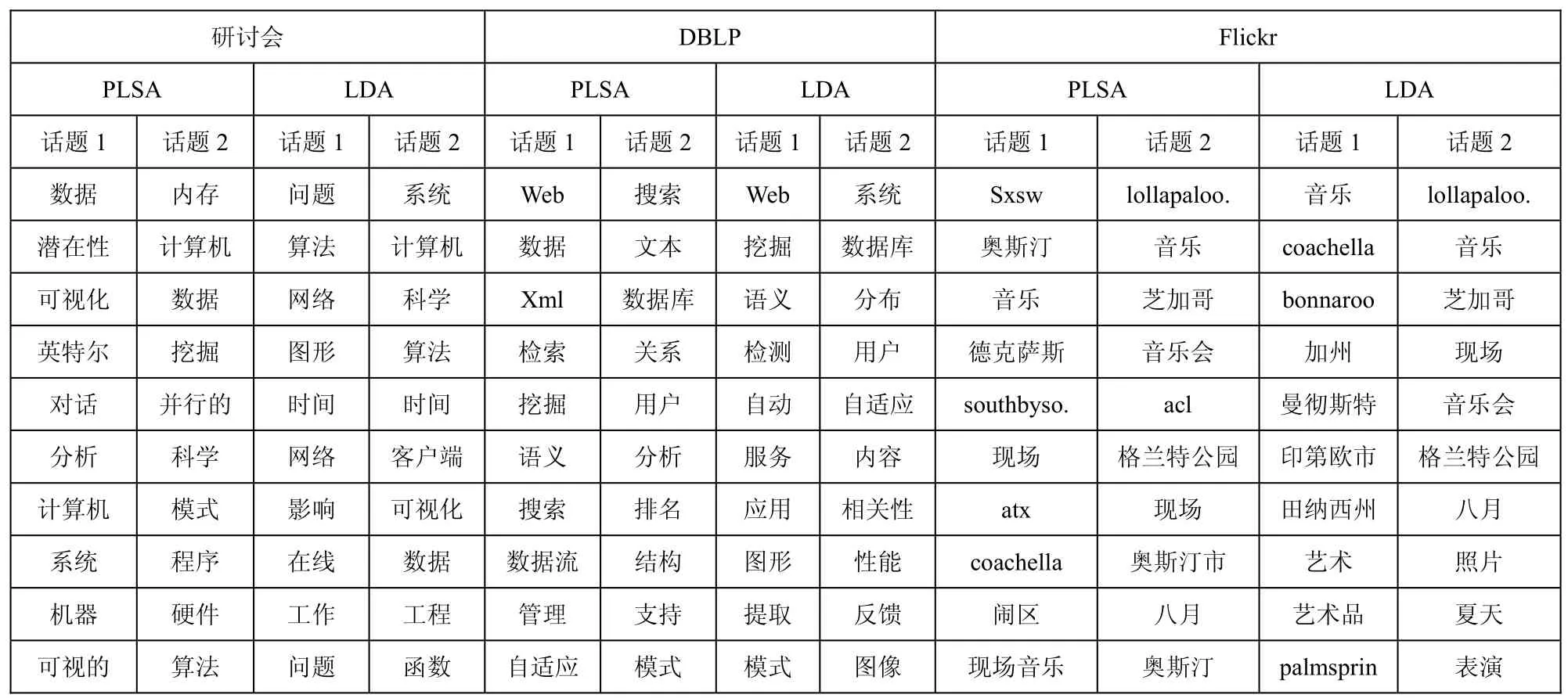
表3 不同数据集使用PTMP和LDA时被检测出来的部分话题
例如,对DBLP数据集,PTMP发现话题VLDB时的词汇分布为data 0.0530, xml 0.0208, query 0.0196, queries 0.0176,efficient 0.0151, mining 0.0142, database 0.0136, streams 0.0112, databases 0.0111。我们可以看出,单个词汇并不足以表示这样一个话题,只有多个词汇才能更好表示。PTMP不仅可以更全面的描述话题,还可以当组成词汇单独考虑不具有周期性模式时检测出周期性话题。对PTMP,我们可以根据和文件时标,绘出检测话题的时间分布,其中可以根据贝叶斯理论由获得。如图1所示:
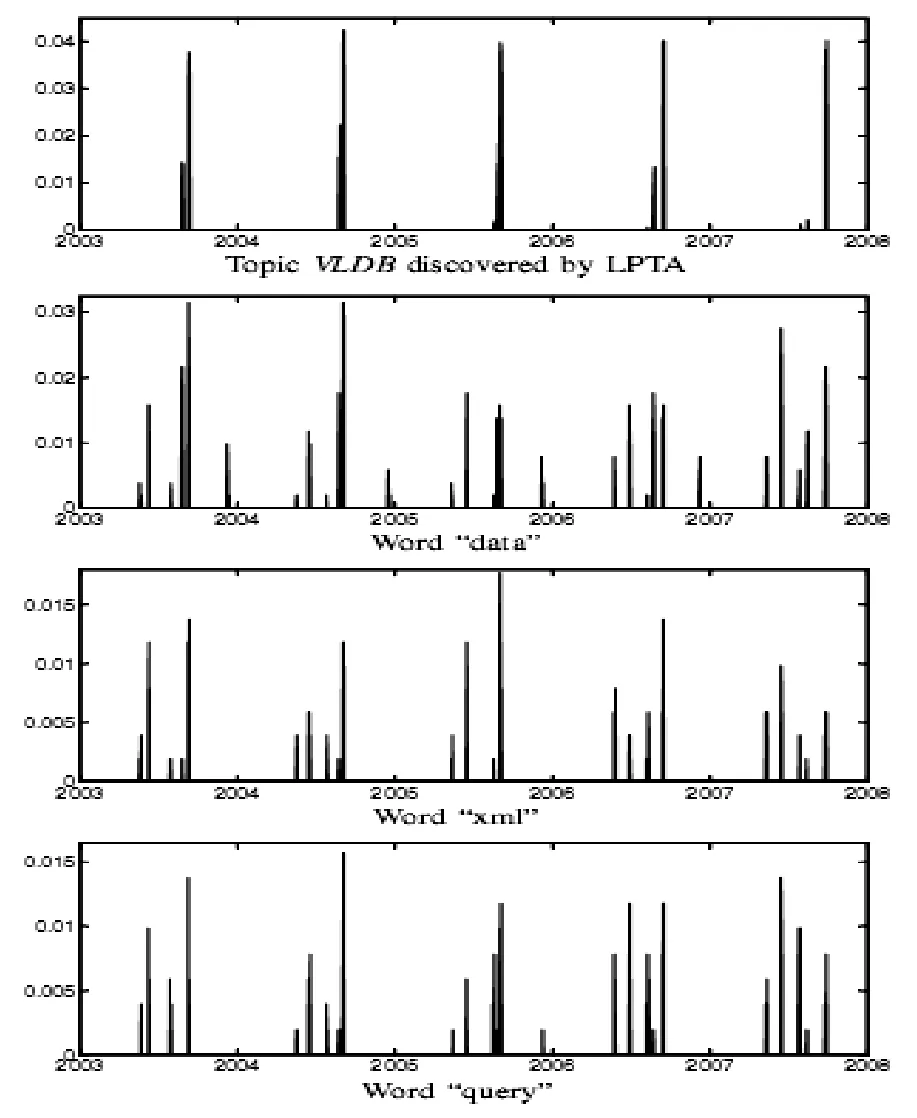
图1 基于PTMP检测的话题VLDB的时间分布及话题词汇的时间分布
我们可以绘出DBLP数据集VLDB话题的时间分布及话题最流行词汇data、xml、query的时间分布。我们可以看出,话题VLDB的周期性模式非常清晰,而词汇data、xml、query没有周期性出现。这表明,即使周期性话题的组成词汇本身没有周期性,PTMP也可以有效检测出这些周期性话题。
(3)PTMP VS 话题模式。为了研究传统话题模型能否检测出有意义话题,我们对话题建模算法结果进行比较,包括PLSA、LDA和PTMP。对PLSA和LDA,我们设置研讨会、DBLP和Flickr数据集的话题数量分别为5、5、6。基于PLSA和LDA的部分话题如表4所示:
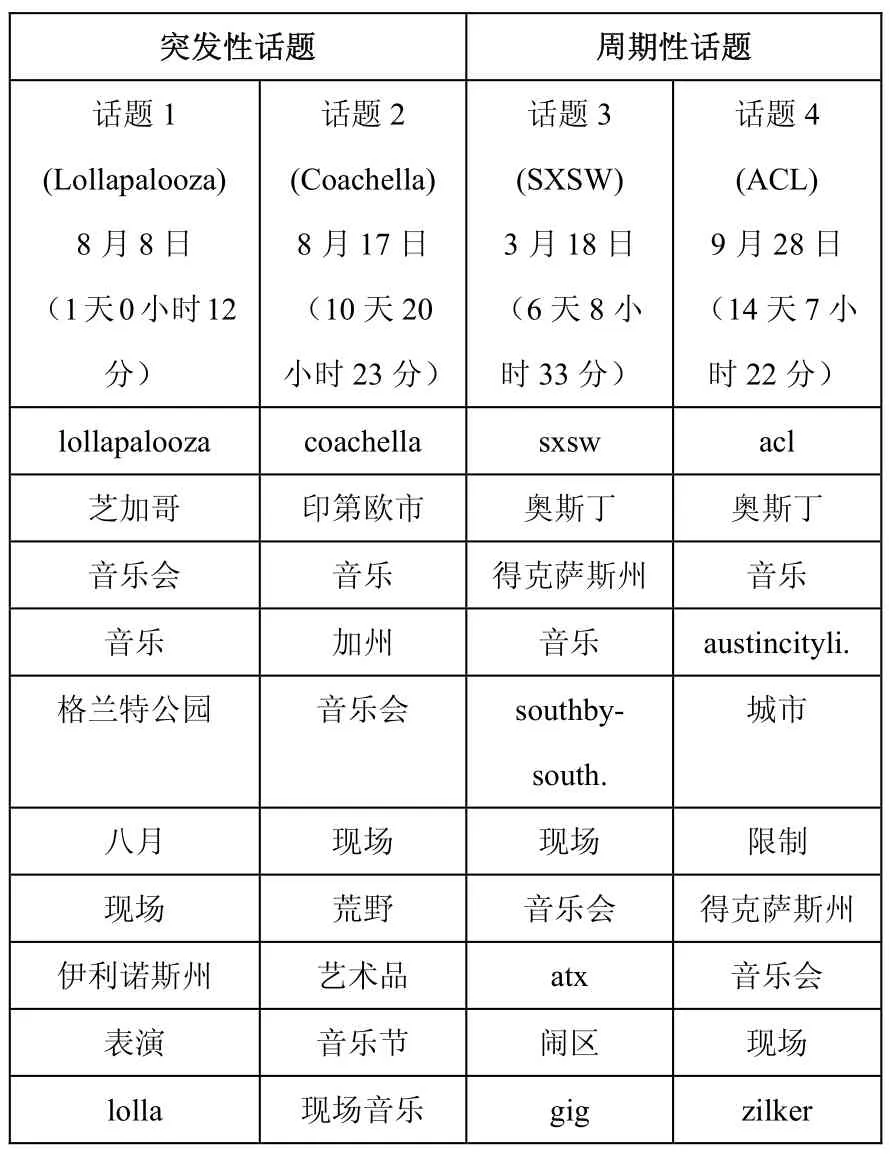
表4 使用PTMP时周期性及突发性数据集的话题检测。
由于计算机领域词汇的相关度非常高,PLSA和LDA无法检测出研讨会数据集不同研究领域的话题。对DBLP数据集,所有的话题非常类似,导致PLSA和LDA无法检测出有意义的话题群组。对Flickr数据集,PLSA混合了几个音乐节。例如,话题1包括southbysouthwest和coachella,话题2包括lollapalooza和austincitylimits。我们发现,LDA在该数据集上的表现要优于PLSA。即使话题1混合了coachella和bonnaroo,LDA也可以检测出不同的节日。与表2中的PTMP相比,我们可以发现,PTMP检测出来的有意义话题的质量更高。
(5)周期性话题 VS 突发性话题。为了验证PTMP方法对周期性话题和突发性话题的平衡性能,本文对Flickr数据集的以下情况进行研究。我们没有将与音乐节有关的所有照片混在一起,而是只保存了2006-2010年间的SXSW和ACL及2009年的Coachella和Lollapalooza音乐节的照片。于是,我们模拟了带有2个周期性话题和2个突发性话题的数据集情况。对PTMP,我们将周期性话题和突发性话题数据均设为2,并在表4中给出了被检测出来的话题名称。从表5中可以看出,每年出现时间比较类似的词汇,比如sxsw和acl,属于两种对应的周期性话题(即话题1和话题2),而只在某段时间才会出现的词汇,比如lollapalooza、chicago、grantpark、illinois、coachella、indio、california,属于两种对应的突发性话题(即话题3和话题4)。PTMP可以区分该数据集的突发性话题和周期性话题。周期性话题SXSW和ACL的平均日期为每年的3月18日和9月28日,突发性话题Lollapalooza和Coachella的平均日期为2009年的8月8日和4月17日。
(6)小结。从以上定量分析可以看出,与针对单个词汇的周期性检测相比,PTMP不仅可以更全面的描述话题,还可以当周期性话题的构成词汇单独分析不具有周期性模式时,检测出周期性话题。与PLSA和LDA话题建模算法相比,PTMP可以检测出更具语义的周期性话题。此外,PTMP还可以有效检测出每个周期性话题的平均日期和标准差。我们从DBLP的SIGMOD vs. VLDB及SIGMOD vs. CVPR数据集可以看出,如果没有综合文本和时间信息,则难以检测出有意义的话题;同时可以看出,PTMP在二者间实现了很好的平衡。对于周期性话题和突发性话题间的折衷,我们从Flickr网站周期性话题VS突发性话题示例中可以看出,具有周期性或突发性模式的词汇将隶属于对应的周期性或突发性话题。
5 总结
本文引入了带有时标的文档的潜在周期性话题分析问题。提出了PTMP潜在周期性话题分析模型,既利用了词汇周期性,又利用了词汇共生性。在测试本文算法时,收集了研讨会、DBLP和Flickr等几个代表性数据集。评估结果表明,本文PTMP模型综合了话题聚类和周期性模式信息,可以有效检测出潜在周期性话题。周期性分析是网络挖掘和社交媒体挖掘的重要课题。下步工作中,我们将重点研究如何对本文结论进行拓展,以应对不断增加的网络文档数量和日趋复杂的社交媒体结构。
[1] Vlachos M, Yu P, Castelli V. On periodicity detection and structural periodic similarity[C]. SIAM International Conference on Data Mining. 2005: 449-460
[2] Bathoorn R, Welten M, Richardson M, et al. Frequent episode mining to support pattern analysis in developmental biology[M]. Pattern Recognition in Bioinformatics. Springer Berlin Heidelberg, 2010: 253-263
[3] Chen L, Roy A. Event detection from flickr data through wavelet-based spatial analysis[C]. Proceedings of the 18th ACM conference on Information and knowledge management. ACM, 2009: 523-532
[4] Mei Q, Liu C, Su H, et al. A probabilistic approach to spatiotemporal theme pattern mining on weblogs[C]. Proceedings of the 15th international conference on World Wide Web. ACM, 2006: 533-542
[5] Wang X, Zhai C X, Hu X, et al. Mining correlated bursty topic patterns from coordinated text streams[C]. Proceedings of the 13th ACM SIGKDD international conference on Knowledge discovery and data mining. ACM, 2007: 784-793
[6] Blei D M. Probabilistic topic models [J]. Communications of the ACM, 2012, 55(4): 77-84
[7] Iwata T, Yamada T, Sakurai Y, et al. Online multiscale dynamic topic models[C]. Proceedings of the 16th ACM SIGKDD international conference on Knowledge discovery and data mining. ACM, 2010: 663-672
[8] Lahiri M, Berger-Wolf T Y. Periodic subgraph mining in dynamic networks [J]. Knowledge and information systems, 2010, 24(3): 467-497
[9] Murata M, Toda H, Matsuura Y, et al. detecting periodic changes in search intentions in a search engine[C]. Proceedings of the 19th ACM international conference on Information and knowledge management. ACM, 2010: 1525-1528
Research on A Periodic Topic Ming Method Based on Partition
Deng Dingsheng
(Computer Science Department, Sichuan University Nationalities, Kangding 626001, China)
Periodic topic mining is a hot problem of current research in the data mining region. Aiming at the disadvantages of most existing studies which are limited to time series database and cannot be applied on text data directly, this paper proposes a periodic topic mining method based on partition, firstly, topics can be classified into three types: periodic topics, background topics, and bursty topics, we model the distribution of time-stamps for each periodic topic as a mixture of Gaussian distributions, in order to alleviate the problem of background noises, the time-stamps of the background topics are generated by a uniform distribution, the time-stamps of the bursty topics are generated from a Gaussian distribution, and then By fitting such a mixture model to time-stamped text data, we can discover periodic topics along with their time distributions. To show the effectiveness of our model, we collect several representative datasets including Seminar, DBLP and Flickr.
Periodic Topic; Data Ming; Mixture of Gaussian Distributions; Noise; Time-Stamps
TP391
A
2014.06.05)
邓定胜(1978-),男,四川广安人,四川民族学院计算机科学系,硕士,讲师。研究方向:软件体系结构,算法分析与程序设计,康定,626001
1007-757X(2014)08-0021-06
