利用旋转森林变换的异构多分类器集成算法
2014-07-25毛莎莎焦李成
毛莎莎,熊 霖,焦李成,张 爽,陈 博
(西安电子科技大学智能感知与图像理解教育部重点实验室,陕西西安 710071)
利用旋转森林变换的异构多分类器集成算法
毛莎莎,熊 霖,焦李成,张 爽,陈 博
(西安电子科技大学智能感知与图像理解教育部重点实验室,陕西西安 710071)
为了增强集成系统中各分类器之间的差异性,提出了一种使用旋转森林策略集成两种不同模型分类器的方法,即异构多分类器集成学习算法.首先采用旋转森林对原始样本集进行变换划分,获得新的样本集;然后通过特定比例选择分类精度高的支撑矢量机或分类速度较快的核匹配追踪作为基本的集成个体分类器,并对新样本集进行分类,获得其预测标记;最后结合两种模型下的预测标记.该算法通过结合两种不同分类器模型,实现了精度和速度互补,将二者混合集成后改善了集成系统泛化误差,相比单个模型集成提高了系统分类性能.对UCI数据集和遥感图像数据集的仿真实验结果表明,文中算法相比单一分类器集成缩短了运行时间,同时提高了系统的分类准确率.
集成分类器;旋转森林;支撑矢量机;核匹配追踪
近年来,分类器集成[1-3]已成为机器学习领域研究的主流和热点.分类器集成是指将多个分类器进行结合以此来提高单个分类器的分类性能的学习方法,它是集成学习在有监督分类中的典型应用.1990年,Hansen和Salamon[4]首先提出了神经网络集成,并且证明集成多个网络能增强单个弱神经网络的泛化能力.随后,支撑矢量机集成[6]被提出,表明集成学习不仅能改善单个弱分类器性能,也能提高强分类器性能.目前,许多分类器集成方法[2,5,14,18]已经被提出,同时也被应用到图像分类[7]、医学图像处理[8]等领域.
在一个分类器集成系统中,一个分类器相当于集成学习中的一个个体,因此,它也被称为一个集成个体.根据已有集成方法,表明集成分类器能有效提高分类性能.然而,在实际应用中大部分的研究者均采用多个同质的分类器进行集成,如所有个体分类器都是神经网络、决策树等.研究表明,一个有效的集成系统不仅应该包含一组精度较高的分类器,同时分类器的错误分类也应该分布在输入空间的不同部分[9-10].换句话说,一个理想的集成系统应该包含一组精确的且尽可能不同的分类器.1999年Opitz[11]给出集成学习的广义定义,即只要是使用多个分类器来解决问题就是集成学习,这表明集成系统不局限于单一模型分类器.1997年Margineantu和Dietterich[12]提出‘Kappa-error’图来展现集成性能,以Bagging和Boosting为例表明集成个体差异性和个体误差的关系:分类器间的差异性影响集成系统性能,差异性越大则集成分类器性能越好,同时差异性的增加却以分类器自身的误差增大为代价.
支撑矢量机(Support Vector Machine,SVM)[9]是最先采用核技术的算法,它在解决小样本问题,特别是高维小样本非线性问题中有许多独有的优势,因此,被广泛地应用于分类和回归问题,并取得了巨大的成功.核匹配追踪(Kernel Matching Pursuit,KMP)[10]是近年来新提出的一种模式识别方法,受启发于支撑矢量机,但却比支撑矢量机具有更为稀疏的解.虽然支撑矢量机和核匹配追踪是两种比较好且应用广泛的分类器,但是仍然存在分类精度依赖参数选择、支撑矢量机计算复杂度高,以及核匹配追踪在训练样本规模较大时存在推广能力差等问题.基于以上原因,文中提出了一种基于旋转森林变换[2]的异构分类器集成的方法,不同类型的分类器可以提供关于被处理数据互补的信息,从而降低单一模型的近似误差,提高集成精度.同时,通过集成两种不同模型分类器增强差异性,以此避免在单一模型集成中通过降低个体性能来满足个体差异性需求的弊端.
1 异构多分类器集成
1.1 旋转森林变换
由于集成学习的分类器构建要求包含一组精度较高的分类器,而且这些分类器的差异要尽可能地大.按照集成系统的构造方法来划分,集成系统[13]可以分为:基于不同训练数据集的构造方式,如Bagging算法[14];基于不同特征集的构造方式,如随机子空间算法等;基于同一训练数据集不同重抽样技术的构造方式等.旋转森林策略[2]主要是对集成分类器的原始样本特征进行处理,通过一定的特征提取变换获得集成所需的新样本,并且在保证分类准确性的前提下,增加集成分类器个体间的差异性.其主要思想如下:
给定初始样本集S(N×D),其中N和D分别是样本个数和样本特征数.首先,将样本的特征随机划分为K个特征子集(无重复抽取),每个特征子集的特征数为M(M=DK),基于特征子集获得K个样本子集{Si}(i=1,…,K),若特征数不能整除,则将剩余特征加入第K组特征.然后,采用主成分分析变换方法对样本子集Si进行特征转换,获得M个特征向量,并选择M′个非零特征值对应的特征向量组成一个特征向量矩阵ai=[ai1,…,aiM′],将获得的K个特征向量矩阵合并获得矩阵R,其中ai位于R的第i个M行和M列位置.最后,找出R中特征向量对应在初始样本中的特征及特征初始位置(维数),将每个特征向量按照对应特征初始位置重新排列,得到新的特征向量矩阵R*,最后由R*产生新样本Snew=S·R*.
旋转森林策略是针对集成分类器间的差异性和集成分类器的准确性两个方面提出的.研究表明,当使用经典集成策略时,集成分类器个数一般选择15到25个才能取得较好的分类性能,同时也意味着其比使用单个分类器分类消耗更多的时间,而旋转森林策略能够使得分类器个数降在10个以下时仍能取得好的分类结果,且改善Bagging算法的波动性.因此,文中采用旋转森林策略构造每个集成分类器的训练样本,通过集成个体数目减少有效缩短集成运行时间,同时保证集成分类正确率.
1.2 混合异构多分类器集成
根据吴建鑫[5]等对集成系统泛化误差的分析,在集成泛化误差E、各个体泛化误差均值¯E和个体平均总体相关度¯A之间存在关系E=¯E-¯A,因而要增强集成系统的泛化能力,就应使各个体分类器之间尽可能不相关,同时保证个体分类器自身误差小.文献[15]给出集成系统的错误率与单个分类器的相关性,两者的关系表示为

其中,ρ表示分类器误差之间的相关性,EOptimalBayes表示在所有条件概率已知情况下使用贝叶斯规则得到的错误识别率.当ρ=0时,集成系统的误差随着分类器数目的增加按比例减小;当ρ=1时,集成系统的误差等于单个分类器的误差.因此,式(1)表明当个体差异性越大且个体误差越小时集成误差越小.
目前,大部分的分类器集成建立在同一种分类器模型上,对此研究较为成熟,并且也证明其能获得好的分类性能.然而,根据理论分析得出,如果个体分类器之间的误差相关性ρ(0<ρ≤1)越小,则集成系统的误差越小,但同时如果增大分类器的误差¯E,对集成系统性能提高则会产生负作用.因此,采用单一模型进行集成已经不能满足更高集成性能的要求.为了获得更小的集成误差E,文中提出了一种异构多分类器集成的方法,即将支撑矢量机和核匹配追踪两种不同的核学习器同时集成,选用旋转森林策略获得个体分类器的训练样本子集.其目的在于增强分类器间的差异性,同时克服分类器误差增大对集成性能的影响.首先,由于两种不同模型的分类器自身的分类机理不同,因此,产生的误差分布将会有差异,且集成分类器的误差E由支撑矢量机和核匹配追踪共同获得,即
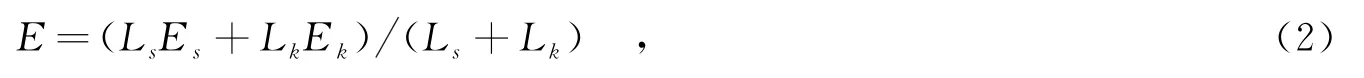
其中,Es和Ek分别表示个体支撑矢量机和核匹配追踪的分类误差,Ls和Lk分别表示个体支撑矢量机和核匹配追踪分类器的个数.依据文献[16]中总结的10种衡量差异性标准,文中选用重合失败多样性(Coincident Failure Diversity,CFD)标准,多样性的值越大则差异性越大.由于文中提出异构分类器集成方法,因此,分类器间的差异性不再依靠单一分类器模型获得,而是由两者共同决定,则对于随机抽取的一个样本,其分类误差应该由不同模型的最大误差产生,即

其中,psi和pki分别为两个分类器对随机抽取样本的误分概率,p0为ps0和pk0的最大值.根据式(3),表明异构分类器集成可获得较单一模型集成更高的多样性值,即增强差异性.此外,支撑矢量机和核匹配追踪分类器集成能相互弥补自身不足,比如,当训练样本个数较多时,支撑矢量机执行的时间长,甚至会出现内存溢出无法计算的情况,而核匹配追踪在处理大样本个数的分类中取得较支撑矢量机更好的效果.此外,核匹配追踪算法比支撑矢量机算法运行速度快,因此,将二者结合既可处理样本数量较大的数据,同时也可缩短分类时间.文中算法具体步骤如下:
step 1 输入初始样本X,样本包括D个特征,集成分类器个数Ls和Lk,L=Ls+Lk;
step 2 对X的D个特征进行等划分,获得K个具有不同特征的样本子集,Xk表示第k个样本子集,每个子集具有M个特征,M=DK;
step 3 对K个样本子集进行如下处理:
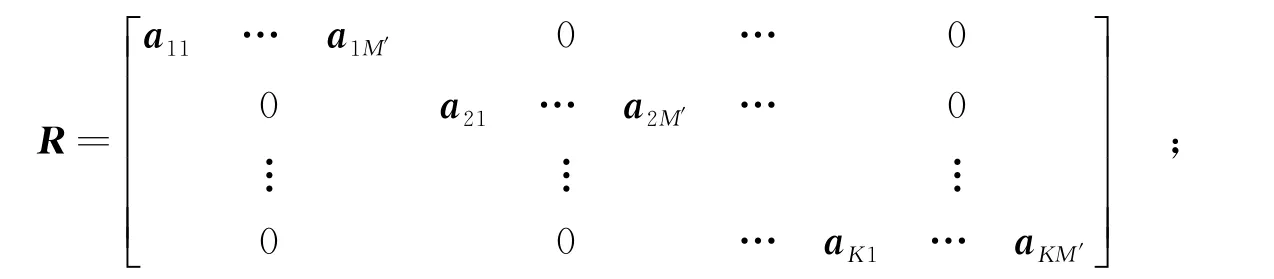
step 4 对R重新排列得R*,获得新样本Xnew,Xnew=XR*;
step 5 Xnew作为分类器的样本,选择分类器(支撑矢量机或核匹配追踪)训练获得一个集成子分类器Cls或者Clk(l=1,…,L).返回step 2,循环L次,获得集成分类器组Ω={C1,…,CL};
step 6 分别使用L个分类器对测试样本集进行分类,获得预测函数{fl}和预测标记{hl};
step 7 对预测函数和预测标记进行投票处理,获得集成分类器最终预测标记Henc.
文中方法在最终集成分类器时,采用了投票准则将其结合.然而,在大部分的分类器集成中,最终的集成结果是通过对预测标记h进行投票表决产生的,但也因此出现一个问题:如果集成分类器的个数为偶数,则投票获得的集成分类器最终预测标记中会出现零值,也就是无法获得标记.为了解决此问题,文中将判决函数f作为投票对象,并通过下式获得一个样本x的最优判决函数[17]fbest(x)和最优预测标记hbest(x):

2 实验结果与分析
本节将通过两个实验来验证文中方法的有效性,分别对UCI数据和6类飞机图像进行分类性能测试.实验中使用计算机的配置为Intel(R)Xeon(TM),CPU6300(3.60 GHz),内存2.75 GB,MATLAB7.0.其中,支撑矢量机和核匹配追踪分类器均采用径向基作为核函数:
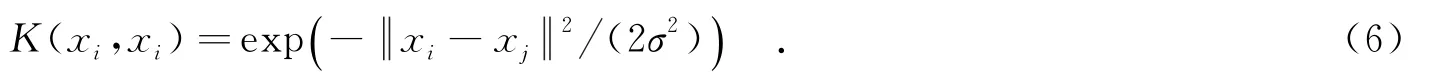
在实验中,集成分类器的个数设为6,支撑矢量机和核匹配追踪分类器按一比一的比例进行集成.另外,对于每个数据集,支撑矢量机和核匹配追踪分类器的参数分别通过十倍交叉验证获得.对于多类数据分类,文中采用一对一策略进行处理.
2.1 UCI数据集分类
实验选择了10个常用UCI数据集进行测试,实验结果如表1所示.在表1中,数据集后括号中分别表示数据集的样本数和特征维数(样本数×特征维数),并且时间和分类准确率均为50次集成的平均值.实验中旋转森林策略采用75%的采样率,并且样本特征划分根据每个数据集的特征数确定,划分子集数在2~6之间.
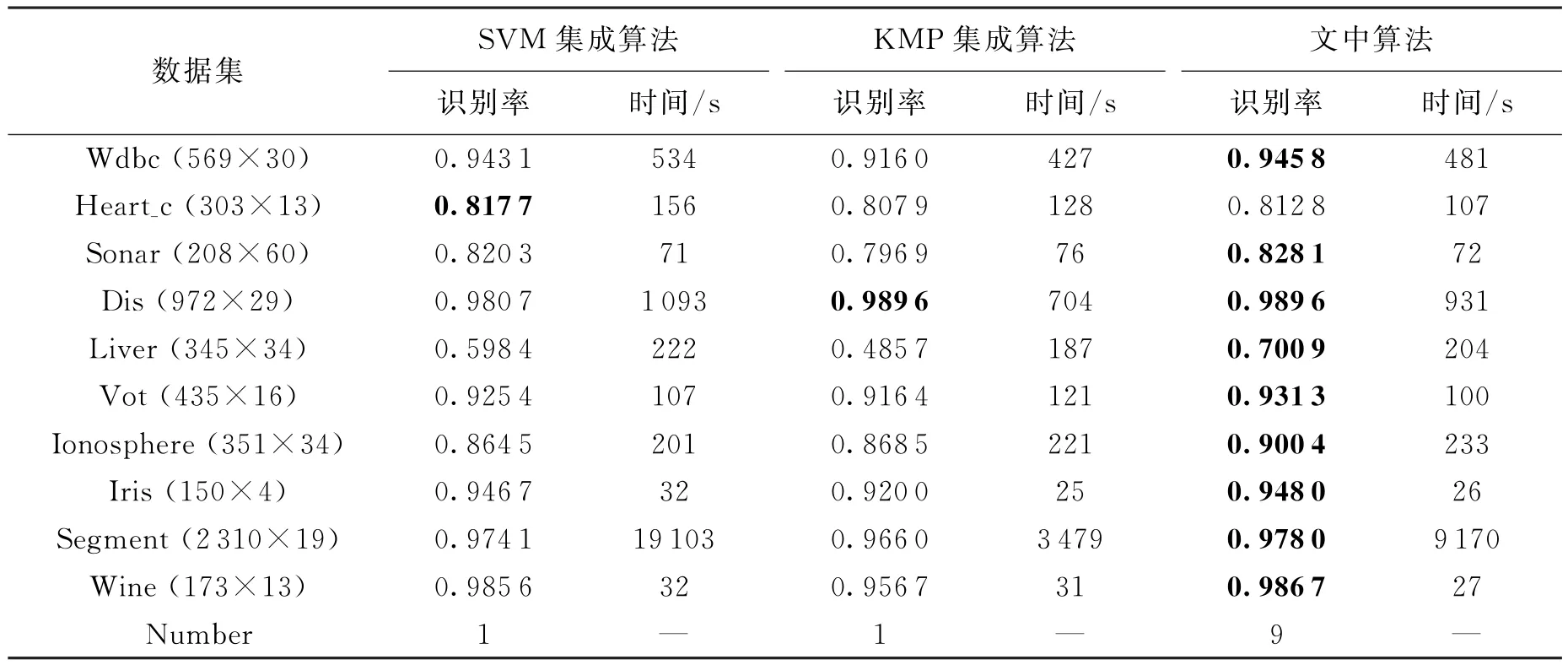
表1 UCI数据集3种方法分类结果比较
从表1可以看出,10个数据集中有9个数据在文中算法下获得了更高的识别率,而支撑矢量机集成(SVM集成)算法只有1个胜出,核匹配追踪集成(KMP集成)算法只有1个与文中算法同时胜出(但KMP集成算法的运行时间缩短).仿真实验结果验证了集成不同模型的分类器能够改善集成个体间的差异性和分类器自身误差,进而提高集成系统分类性能.同时,文中算法所需的分类时间基本上介于支撑矢量机集成算法和核匹配追踪集成算法之间,尤其对于数据样本稍大的数据,在精度略有提高的基础上,文中算法比支撑矢量机集成算法快很多.由此可以证明异构支撑矢量机和核匹配追踪分类器集成比单个分类器集成具有更好的分类性能,可以在分类准确率高和分类速度方面有较好的折中.
2.2 飞机图像的识别
该实验选用了613幅6类飞机图像,其大小为128×128,6类飞机部分示例图如图1所示.实验中分别采用不同种类特征提取方法获得飞机特征,如采用小波分解、Contourlet分解和Brushlet分解提取了相应的能量和方差特征.对于能量特征,文中采用L1范数能量测度:

其中,M×N为子带大小,coef(i,j)为该子带中第i行和第j列的系数值.对于方差特征,计算公式为
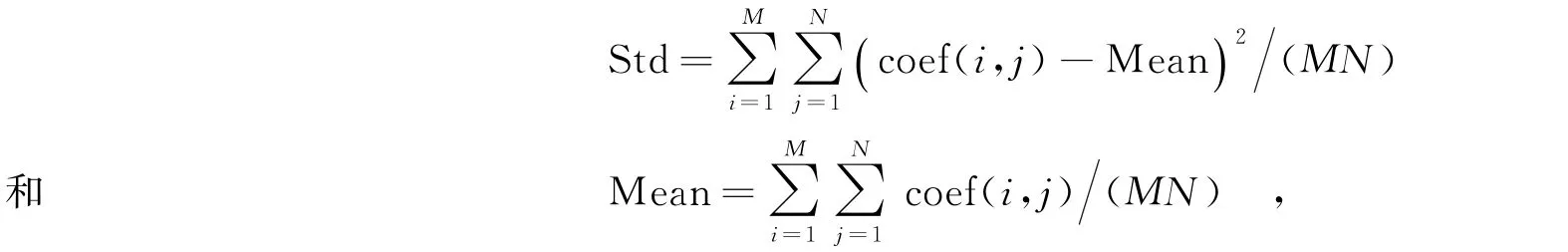
其中,Mean为该子带系数的均值.

图1 6类飞机图像
在文中算法中,特征子集的划分决定生成的新样本,从而影响集成分类器之间的差异性,因此,为了更好说明异构分类器集成的推广性能,实验中分别将飞机图像的每种特征进行多个子集划分,实验结果如表2所示.其中,准确率和时间均为50次集成的平均值,并且每个特征后面括号里表示原始特征维数,后面一列中数字表示划分子集个数.从表2结果中明显看出,文中算法较单个同质分类器集成能获得更好的分类性能,并且结合两个分类器性能和时间的优势.此外,根据表2最后1行(Number)中列出13次实验中具有最好分类性能的次数,可知文中算法获胜10次,而支撑矢量集成和核匹配追踪集成仅获胜2次和1次,这也暗示文中算法能够获得更高的分类精度,并且文中方法获得好的分类性能并不取决于某种特定特征,而是对于大部分的特征都能取得好的分类性能,换言之,其较单个分类器集成具有更强的泛化能力.
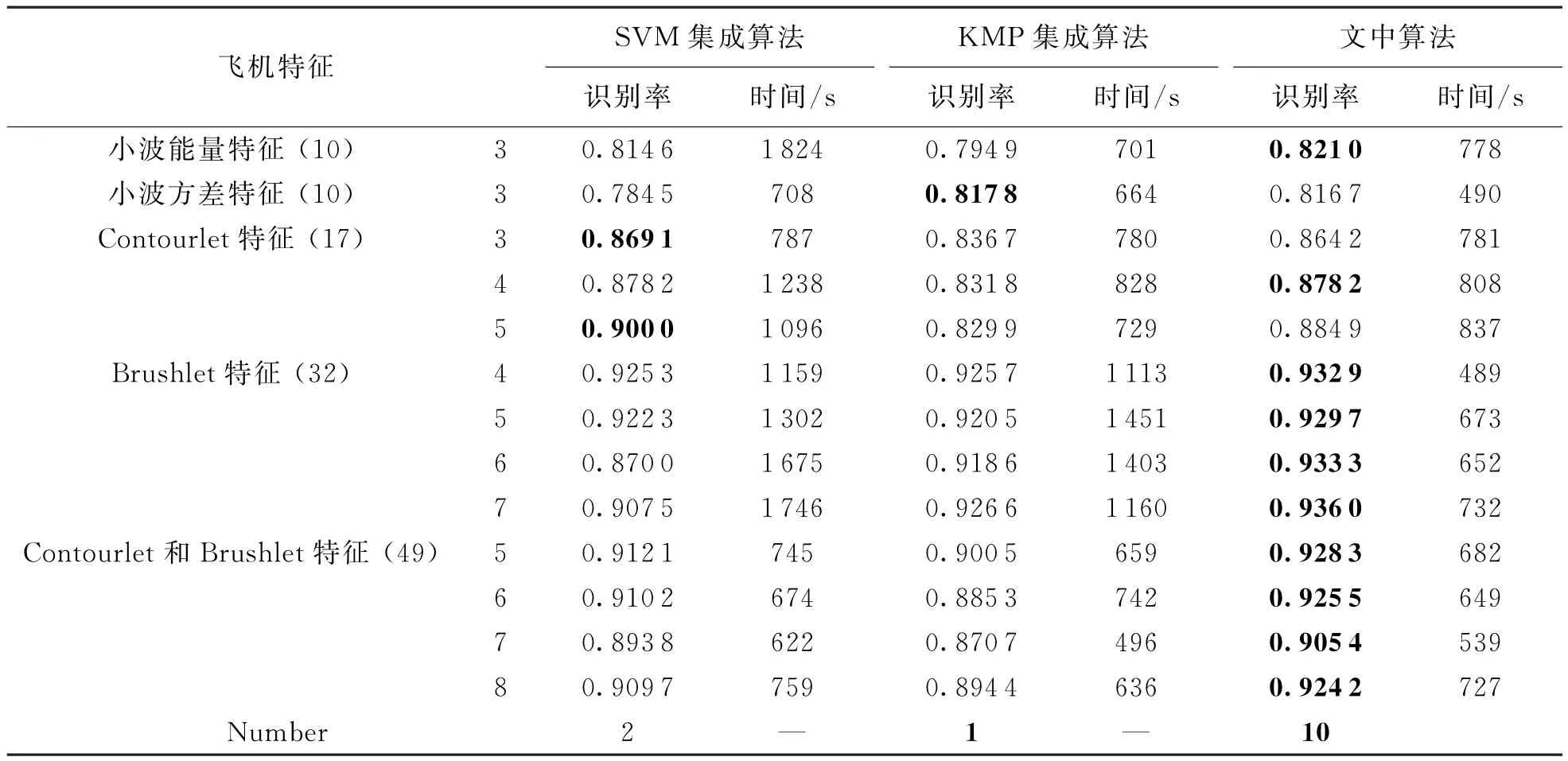
表2 6类飞机图像3种方法分类结果比较
3 结束语
笔者提出了一种将不同模型分类器集成的方法,即支撑矢量机和核匹配追踪分类器集成,并且使用旋转森林变换策略获得个体分类器训练样本子集.该方法主要从集成分类器模型自身误差和分类器间差异性两个因素出发,通过结合不同模型的分类器来增加差异性,同时可以互相弥补分类器模型自身不足,以此改善集成性能.使用旋转森林策略减少集成分类器的个数,改善了个体分类准确度和个体间差异性两个因素相互限制的缺陷.UCI数据集和图像数据实验结果表明,文中算法较单一模型分类器集成能够获得更好的分类性能,在减少运行时间的同时,能够提高或保持好的分类准确率.
[1]Kuncheva L I.Combining Pattern Classifiers:Methods and Algorithms[M].New Jersey:John Wiley&Sons,2004.
[2]Rodriguez J J,Kuncheva L I,Alonso C J.Rotation Forest:A New Classifier Ensemble Method[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2006,28(10):1619-1630.
[3]Zhang L,Zhou W D.Sparse Ensemble Using Weighted Combination Methods based on Linear Programming[J]. Pattern Recognition,2011,44(1):97-106.
[4]Hansen L K,Salamon P.Neural Network Ensembles[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,1990,12(10):993-1001.
[5]吴建鑫,周志华,沈学华,等.一种选择性神经网络集成构造方法[J].计算机研究与发展,2000,37(9):1039-1044.
Wu Jianxin,Zhou Zhihua,Shen Xuehua,et al.A Selective Constructing Approach for Neural Network Ensemble[J]. Journal of Computer Research and Development,2000,37(9):1039-1044.
[6]李青,焦李成.利用集成支撑矢量机提高分类性能[J].西安电子科技大学学报,2007,34(1):68-70.
Li Qing,Jiao Licheng.Improvement Classification Performance by The Support Vector Machine Ensemble[J].Journal of Xidian University,2007,34(1):68-70.
[7]Alham N K,Li M Z,Liu Y,et al.A Distributed SVM Ensemble for Image Classification and Annotation[C]//9th International Conference on Fuzzy Systems and Knowledge Discovery.Piscataway:IEEE,2012:1581-1584.
[8]Ghorai S,Mukherjee A,Sengupta S,et al.Cancer Classification from Gene Expression Data by NPPC Ensemble[J]. IEEE/ACM Transactions on Computational Biology and Bioinformatics,2011,8(3):659-671.
[9]Vapnik V.The Nature of Statistical Learning Theory[M].Berlin:Springer-Verlag,1999.
[10]Vincent P,Bengio Y.Kernel Matching Pursuit[J].Machine Learning,2002,48(1-3):165-187.
[11]Opitz D W.Feature Selection for Ensemble[C]//Proceedings of the National Conference on Artificial Intelligence.New York:ACM,1999:379-384.
[12]Margineantu D D,Dietterich T G.Pruning Adaptive Boosting[C]//Proceedings of the 14th International Conference on Machine Learning.New York:ACM,1997:211-218.
[13]焦李成,公茂果,王爽,等.自然计算、机器学习与图像理解前沿[M].西安:西安电子科技大学出版社,2008.
[14]Breiman L.Bagging Predictors[J].Machine learning,1996,24(2):123-140.
[15]Tumer K,Ghosh J.Ensembles of Radial Basis Function Networks for Spectroscopic Detection of Cervical Precancer[J]. IEEE Transactions on Biomedical Engineering,1998,45(8):953-961.
[16]Kuncheva L I,Whitaker C J.Measures of Diversity in Classifier Ensembles and Their Relationship with the Ensemble Accuracy[J].Machine Learning,2003,51(2):181-207.
[17]Valentini G,Muselli M,Ruffino F.Bagged Ensembles of Support Vector Machines for Gene Expression Data Analysis [C]//Proceedings of the International Joint Conference on Neural Networks.Piscataway:IEEE,2003:1844-1849.
[18]Yuan Hanning,Fang Meng,Zhu Xingquan.Hierarchical Sampling for Multi-Instance Ensemble Learning[J].IEEE Transactions on Knowledge and Data Engineering,2013,25(12):2900-2905.
(编辑:李恩科)
Isomerous multiple classifier ensemble via transformation of the rotating forest
MAO Shasha,XIONG Lin,JIAO Licheng,ZHANG Shuang,CHEN Bo
(Ministry of Education Key Lab.of Intelligent Perception and Image Understanding, Xidian Univ.,Xi’an 710071,China)
In order to boost the diversity among individual classifiers of an ensemble,a new ensemble method is proposed that combines two different classifier models via a transformation of rotation forest, named by isomerous multiple classifier ensemble.Firstly,the original samples are transformed and divided by the rotating forest to obtain new samples.Then support vector machine with the high accuracy of classification or kernel matching pursuit with the speedy classification is selected as a basic classifier model based on a special proportion,the selected classifier is used to classify the new samples,and the predictive labels are obtained.Finally,the predictive labels given by two different models are combined to obtain the final predictive labels of an ensemble.Particularly,the proposed method achieves the complementarity of accuracy and speed by combining two different classifier models,and it is important that isomerous classifier ensemble improve the generalization error of an ensemble and increases the classification performance.According to the experimental results of classification for UCI datasets and remote sensing image datasets,it is illustrated that the proposed method shortens obviously the running time and improves the accuracy of classification,compared with an ensemble based on the single classifier model.
classifier ensemble;rotation forest;support vector machine;kernel matching pursuit
TP181
A
1001-2400(2014)05-0048-06
2013-07-08< class="emphasis_bold">网络出版时间:
时间:2014-01-12
国家重点基础研究发展计划资助项目(2013CB329402);国家自然科学基金资助项目(61003198,60702062);高等学校学科创新引智计划(111计划)资助项目(B07048)
毛莎莎(1985-),女,西安电子科技大学博士研究生,E-mail:skymss@126.com.
http://www.cnki.net/kcms/doi/10.3969/j.issn.1001-2400.2014.05.009.html
10.3969/j.issn.1001-2400.2014.05.009
