基于结构方程模型的顾客细分
2014-07-13于伟杰
于伟杰
(天津大学 管理与经济学部,天津 300072)
基于结构方程模型的顾客细分
于伟杰
(天津大学 管理与经济学部,天津 300072)
文章介绍了基于结构方程模型的REBUS-PLS分类方法,该方法是结构方程模型中专用于分类的比较新的方法。作者用此方法对S银行顾客分类,结果显示这种顾客细分方法行之有效。
顾客细分;结构方程模型;REBUS-PLS;满意度
传统顾客分类一般是直接根据人口统计信息等先验信息分类或用聚类方法对顾客分类。先验式分类把具有相同人口统计信息的顾客归为一类,其一大缺点是人口统计信息很难捕捉到顾客“异质性”的根源(Hahn 2002)[1],实际上顾客分类目的是将有相似心理特征、行为特点的归为一类,人口统计信息只是顾客外在特征的描述,不足以反映顾客的内在特点,即Hahn所说“异质性”。聚类方法是根据样本之间的距离分类,因此也存在上述问题,另外聚类算法需要假设变量之间相互独立(Jedidi et al.1997)[2],但是调查数据很难满足这一点。先验式分类和聚类式分类的诸多不足促使研究者寻找一种根据顾客内部特征的分类方法,结构方程模型恰好能描述顾客的内部特征,因此便成为学者们首先考虑的对象。
用结构方程模型探究顾客内部特征时,一般默认为总体是同质的,建立一个总结构模型就以概括总体的特性。然而现实总体可能是由几个不同质的次级总体(类)混合而成,每个次级总体所包含顾客的行为相似,但是次级总体之间有明显的差异。建立一个总体模型会把次级总体之间的差异中和,总体模型表现出的“共同规律”只能使管理者了解总体的大致轮廓,对具体决策而言并无多大帮助。如果能把现实中存在的“类”找到,总结出各类所具有的特征,管理者根据不同类的特征采取针对性的策略,那意义无疑是巨大的。
1 基于结构方程的顾客细分
结构方程模型有两大类估计方法:基于协方差的最大似然估计和基于主成分的偏最小二乘估计。前一种方法在求解过程中严格依赖协方差矩阵,并假设测量变量呈正态分布,而测量变量的频数常常为非正态分布。基于偏最小二乘(PLS)的结构方程模型不要求分布,有效解决了变量非正态问题[3],再者基于PLS的结构方程模型能有效应对小样本问题,使得此方法越来越流行,特别是在顾客满意度领域,著名的美国顾客满意度指数(ACSI)正是采用了PLS算法。
协方差的结构模型是比较传统的方法,学者首先对基于这种方法的顾客分类进行了一系列研究,但始终无法有效解决分布问题,因而近几年基于偏最小二乘结构方程模型(PLS-PM)的分类成为学者们研究的焦点。Hahn(2002)提出了有限混合偏最小二乘法(FIMIX-PLS)[1],将协方差结构方程模型中的有限混合分类方法扩展到PLS结构方程模型的分类中,开启了基于PLS结构方程模型框架下顾客分类研究的先河。有限混合模型把总体当成是两个或以上次级总体(类)的混合,而每个次级总体都服从一个特殊的分布。Hahn认为顾客之间的差异源于内部特征以及特征之间关系的不同,所以他把潜变量作为研究基础,假设内生潜变量服从有限混合多元正态分布,计算每个样本属于不同类别的概率。Ringle[4](2006)等人对FIMIX-PLS方法进行了改进,但仍没有克服FIMIX-PLS的主要不足:假设内生潜变量呈正态分布;认为所有类别的测量模型是一致的;分类数量事先不知道,需要借助AIC、BIC等规则加以确定。
与FIMIX-PLS的概率分类思想不同,一些学者沿用聚类方法中“距离”的概念。 Squillacciotti(2005)把偏最小二乘分类回归方法(typological regression)引入到结构方程中,提出了PLS-TPM,这是一种预测导向的、不假设分布的、基于响应的分类技术[5]。PLS-TPM分类的基本过程是,对初始分类分别建立结构方程模型,根据每个样本到各类模型“距离”远近重新分配样本,一直重复建模和分配过程直到各类的构成不再变化。
PLS-TPM与FIMIX-PLS相比有3个优点:对变量不要求分布;考虑到各类测量模型的差异而不是仅关注结构模型;各个类模型确定过程是一个不断迭代优化的过程。PLS-TPM的不足之处:目前只用于“反应式”测量模型中;尽管分类结果通常可以实现,但是迭代过程收敛性并没有得到证明[6]。Trinchera(2007)对PLS-TPM中的“距离”加以改进,提出了基于响应的分类算法REBUS-PLS[6],此方法具有PLS-TPM所有优点,并进一步提高了分类的效果。
2 REBUS-PLS分类方法
Trinchera等人认为,如果总体中存在不同的类,那么同一类中的样本就应该具有相似的行为特征,即适用同一个结构方程模型。若样本都能被正确的分类,那对各个类分别建立结构方程模型要比把顾客错误分类或者对所有顾客建模效果好得多。REBUS -PLS分类所用的“距离”是基于结构方程模型整体拟合优度GOF建立的,显然以拟合效果为分类依据的此分类方法所得到的各类模型的表现,如GOF要比总体模型好很多[6]。
2.1 距离的概念
REBUS-PLS是基于PLS结构方程模型完成对顾客的分类。与聚类方法不同,REBUS -PLS中的“距离”是样本与模型之间的距离,其分类过程可以这样概括,如果一个样本对某个类模型的拟合效果比其他类模型都好,就断定此样本到这个类模型的距离近,样本就可以归到这一类。
结构方程整体拟合优度GOF(Goodness of fit)是测量模型和结构模型的拟合效果指标的几何平均,是对结构方程模型整体表现效果的评价,具体表达式如下:

2.2 距离的定义
基于GOF的思想,Trinchera等人提出的衡量样本到类模型“距离”的指标CM(closeness measure),公式如下:

i表示第i个样本,g表示第g类,最大为G。
Pj:第j个潜变量的显变量个数,J:潜变量总数。
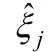

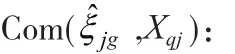
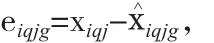

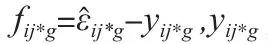
N:样本量,mg是维数,因为测量模型都是反应式所以默认为1。
CM式的左半部分表示在第g类模型的构建下,第i个样本的测量残差与所有样本测量残差均值的比值,值越小说明将第i个样本归入第g类的理由越充分。右半部分表示在在第g类模型的构建下,第i个样本的结构残差与所有样本结构残差均值的比值,值越小说明将第i个样本归入第g类的理由越充分。综合两部分,CM值越小说明归入某一类的可能性越大,样本最终分类是选择其自身在所有可能分类中CM值最小的那一类。
2.3 REBUS-PLS算法步骤
REBUS-PLS算法是一个不断迭代优化的过程,需要设置精度和最大迭代次数。在开源的R软件中可以找到实现的程序包。
1)根据已构建好的概念模型估计总体PLS结构方程模型。
2)计算所有样本的测量残差(communality residuals)和结构残差(structural residuals),对所得残差进行分层聚类,确定各样本的初始分类和总体的类数G。
3)对G组样本分别建立类模型。
4)计算每个样本到各个类模型的CM值,将样本分配到CM值最小的那一类中。
5)计算样本的分类变化情况,若变化率小于设定精度或者达到最大迭代次数则计算停止,否则返回3。
“距离”CM的定义保证了分类模型的效果,与PLSTPM一样,REBUS-PLS方法只适用于测量模型是反应式的情况,收敛性也没有得到证明,Trinchera等人发现此方法在现实应用中一般是收敛的。
3 某银行顾客细分
为了了解顾客满意度,2008年国外S银行设计问卷并调查取得了1300个银行顾客的数据。问卷采用了11级李克特量表。根据欧洲顾客满意度模型(ECSI),作者将问卷所有问项划分为品牌形象、顾客期望、感知质量、感知价值、顾客满意、顾客忠诚六个子量表,具体对应关系如表1所示。
3.1 指标的信效度检验
分别对6个子量表的结构效度和信度进行检验,结果如表1。

表1 问项与潜变量对应关系Tab.1 Description of the manifest variables for each of the latent constructs
6个子量表中,Cronbach’α值都远超过0.7的标准,说明各个子量表的内部一致性非常好。各问项的因子载荷除了“产品和服务的可靠性”一项为0.703外,其余均大于0.71。综上所述6个测量模型(子量表)的信度和效度均达到了预期的效果。
3.2 S银行顾客满意度结构方程构建
作者构造的S银行顾客满意度模型与ECSI基本一致,但没有顾客抱怨这一潜变量。采用R软件中的PLSM程序包进行偏最小二乘路径分析,潜变量之间的关系及路径系数见图1。

图1 S银行顾客满意度模型Fig. 1 Customer satisfaction model of the S bank
5个内生潜变量的拟合优度(R2)在0.43到0.67之间,说明每一个潜变量都可以很好的被其他潜变量所解释,结构模型的构建较为合理。6个潜变量的平均方差提取量(AVE)在0.61到0.84之间超过了0.5,说明测量模型的构建合理。对结构方程模型中的载荷系数和路径系数进行bootstrap非参检验,在5%的显著性水平下,所有系数都通过了检验,说明结构方程模型整体是非常稳健的。在此结构方程模型基础上对顾客分类,其结果是可信的。
3.3 顾客分类
对所有样本进行分层聚类,从聚类效果看,分成3类更合理,所以按分层聚类的结果首先把顾客分成3类,然后用REBUS-PLS方法优化分类,迭代23次后分类变化率为0.1%,分类完成。总结构模型与分类模型的路径系数等结果如表2。

表2 总体与分类模型路径系数Tab.2 Path coeff i cients of the path models for global and local model
对比3类顾客结构方程模型的路径系数,可以发现每一类顾客都有各自的特点。就第一类顾客而言,品牌形象对顾客满意的影响是所有分类之中最高的,达到了0.281,但是此类顾客的感知质量对顾客满意的影响是所有类中最低的为0.083。由此可以推断,第一类顾客非常注重企业的品牌形象,而不太在意企业提供产品和服务的质量。第二类顾客的感知价值和感知质量对顾客满意的影响都是所有类中最高,分别为0.508、0.392,而品牌形象对顾客满意是3类中最低的,可以推断此类顾客非常重视银行为他们提供的产品和服务的质量,而不太在意银行的形象。第三类顾客的品牌形象对顾客忠诚影响程度是3类中最高的,为0.337。
分类模型的GOF值平均为0.648,高于原总模型的0.630,说明按此方法对顾客分类,能够找到内部特征相似的顾客群体,GOF值证实了这一点。
通过对比各类顾客的结构方程路径系数,可以发现3类顾客有各自的内部特征,除内部特征外,了解各类顾客的外部特征对新顾客的分类也具有十分重要的意义。作者利用年龄、性别、受教育程度等人口统计特征与类别做分析,并没有发现十分有价值的规律。
3类顾客没有各自的人口统计特征,作者又转而探究问卷的问项与分类的关系。体现顾客忠诚的“选择别的银行可能性”问项与类别的频数统计结果如表3,其中问项从“0一定会”到“10一定不会”分别体现了顾客的忠诚程度。
分析表3可以看出,第三类顾客在这一问项中有73.7%的人选择了7到10,说明第三类人因为该银行良好的品牌形象成为忠实的顾客。第一、二类人大多分布在5到8分之间,这两类人的忠诚程度还有待提高。由于第二类顾客很重视产品或服务的质量,因此银行在面对第二类顾客时,需要在感知质量和感知价值做出比一般顾客更多的努力,这并非是顾客歧视,而是有针对性的采取措施留住顾客。另外第一、三类人都非常重视品牌形象,因此该银行有必要为打造自己良好的品牌形象付出更多的努力。

表3 三类顾客忠诚度统计表Tab.3 Loyal table for three segmentations
4 结束语
文中介绍了基于结构方程模型分类的新方法-REBUSPLS,并用此方法对S银行顾客分类,结果显示这种顾客细分方法能够找到有相似内部特征的顾客群体,通过对比结构方程模型,可以找到各类顾客各自的特点,这样针对不同类的顾客就可以找到相应的应对措施,以最大程度降低成本提高决策的有效性。另外,此方法的不足之处是收敛性需要在实践中得到检验。
[1]Hahn C,Johnson M, Herrmann A,Huber F.Capturing customer heterogeneity using a finite mixture PLS approach [J].Schmalenbach Business Review 2002,54(3):243-269.
[2]Jedidi K,Jagpal SH,De Sarbo WS. Finite-mixture structural equation models for response-based segmentation and unobserved heterogeneity[J].Marketing Science(1986-1998)1997,16(1):39-60.
[3]林盛,刘金兰,韩文秀.基于PLS结构方程的顾客满意度评价方法[J].系统工程学报,2005,20(6):653-656.
LIN Sheng,LIU Jin-lan,HAN Wen-xiu.Method on customer satisfaction assessment based on the partial least square for structual equation[J].Journal of Systems Engineering,2005,20(6):653-656.
[4]Ringle C M,Wende S,Will A.Finite mixture partial least squares analysis:Methodology and numerical examples[C]//In Esposito Vinzi V (Eds.),Handbook of partial least squares:Concepts,methods and applications in marketing and related fieldsforthcoming,Berlin et al: Springer,2007.
[5]Squillacciotti S.Prediction oriented classification in PLS Path Modelling[C]//In:Proceedings of the PLS’05 International Symposium,2005:499-506.Aluja T, Esposito Vinzi V(Eds.),SPAD Test &Go.
[6]Squillacciotti S,Trinchera L,and Esposito Vinzi V.PLS Typological Path Modeling:a model-based approach to classification[C]//In:Electronic Proceedings of the Workshop on Knowledge Extraction and Modeling (KNEMO),Esposito Vinzi V,Lauro C, Braverman A(Eds),2006.
[7]Trinchera L,Squillacciotti S,Esposito Vinzi V and Tenenhaus M.PLS path modeling in presence of a group structure: REBUSPLS,a new response-based approach[C]//In:Proceedings of the PLS’07 International Symposium,2007:79-82.Martens H,Naes T(Eds),Matforsk, As,Norway.
Customer segmentation based on the REBUS-PLS method
YU Wei-jie
(College of Management and Economics,Tianjin University,Tiangin300072, China)
This paper introduce REBUS_PLS to the customer segmentation.REBUS_PLS is a totally new method based on the Structural Equation Modeling to find out the differences between people.It shows excellent effects when using this method to solve the customer segmentation problem in S bank.
customer; segmentation; REBUS-PLS; satisfaction
TN-9
A
1674-6236(2014)07-0008-04
2013-09-03稿件编号201309017
国家自然科学基金资助项目(70672027)
于伟杰(1988—),男,山东青岛人,硕士。研究方向:顾客细分。
