有向制造网格节点多重链接权重计算方法
2014-07-11蔡皖东
张 璐, 蔡皖东, 彭 冬
(1. 西安市烟草专卖局 信息中心,陕西 西安 710061;2. 西北工业大学 计算机学院,陕西 西安 710072)
随着制造网格及Web技术的发展,协同制造领域出现了一些新的网络应用,如利用Web技术将专网中的制造节点的交互进一步扩展到基于互联网的交互.将制造节点的工作状态信息通过互联网络进行交互,使远程的制造节点实时交互信息及协同工作,显现出越来越大的价值和影响力[1-3].
信息物理融合系统(Cyber-Physical Systems,CPS)是一个综合计算、网络和物理环境的多维复杂系统,通过3C(Computation、Communication、Control)技术的有机融合与深度协作,实现大型工程系统的实时感知、动态控制和信息服务.基于广域网的制造网格也是一种信息物理融合系统,网格中参与计算的不同制造节点可将自身的工作状态信息在互联网中进行发布,并可实时地更新自身的状态信息.同时,也可以调用其他制造节点的工作状态信息以实现制造设备之间的高效协同控制.在制造网格中,状态信息的交互传播过程中,状态汇聚代理发挥了重要的作用.局部状态在状态汇聚代理的影响下演化为网络制造状态.状态汇聚代理是指制造网格在协同制造过程中经常为其他节点提供信息并施加影响的“重要节点”,它们在制造网格的网络制造状态形成过程中起着重要的作用,由它们将制造网格协同制造过程中的协同信息扩散给受众节点,形成信息传递的两级传播[1].随着制造网格协同程度的不断深入,人们对制造网格中状态汇聚代理的研究也在不断地深入.
统计数据显示,制造网格的现实应用中大部分用户节点不经常参与信息的制造与传播,它们做出的控制决策往往参考状态汇聚代理发布的信息.有效地识别广域网中制造网格的状态汇聚代理,通过状态汇聚代理发布引导性信息来影响所在网络中用户节点的控制决策而非直接使用控制指令控制它们,可以有效地触发整个网络的协同性,对于推动信息传播、提高广域网中节点的控制效能具有重要的现实意义.对于状态汇聚代理识别问题,国内外学者都进行了大量的研究,提出了多种状态汇聚代理的识别算法,主要思路是根据网络拓扑特性,将网络抽象成一种图(无向图或有向图),通过分析节点之间的结构关系,计算每个节点的权值.节点的权值越大,成为状态汇聚代理的可能性就越大.由于有向制造网格是一种新兴的制造网格,具有与传统制造网格不同的网络拓扑特性.在有向制造网格中,网格节点构成一种有向图,在分析节点之间结构关系时,除了出度(Out-Degree)和入度(In-Degree)外,还需要考虑其他因素,以提高计算精确度.
笔者重点研究广域网中面向有向制造网格的状态汇聚代理识别问题,提出一种基于多重链接的有向制造网格节点权重计算方法,能够有效地识别有向制造网格中的状态汇聚代理.
1 相关工作
国内外学者提出了多种制造网格状态汇聚代理的识别算法,主要通过分析制造网格拓扑特性来计算网格节点权值,或者根据信息内容来判断其用户的重要性,进而识别状态汇聚代理.文献[4]提出了一种基于状态信息内容分析的有向制造网格重要用户分析方法,通过分析大量的有向制造网格的状态信息内容来判断其用户的重要性,但需要耗费大量的时间用于内容清理和分析,效率较低.文献[5]提出一种状态汇聚代理识别方法,通过对有向制造网格中网格节点的对比来判断用户的重要性,并通过这些用户对整个网络所做的贡献来计算用户权值.该文采用了余弦定理计算不同制造节点状态信息的相似性,复杂性较高,开销大.文献[6]提出了一种基于有向制造网格中节点交互信息的计算识别状态汇聚代理的方法,根据制造网格中节点的用户关系、节点及其用户的分布以及在信息交互的过程中各种用户群体所起到的作用进行权重计算.该算法主要基于制造主题进行分析,召回率不高.文献[7]研究了如何对节点影响力进行定量分析,通过因子图建模,提出了3种学习算法,但文中用到的LDA和因子图降低了其效率.文献[8]根据有向制造网格节点之间的交互信息和拓扑信息,利用线性回归模型预测节点之间的影响力大小,结果表明交互信息起主导作用,拓扑信息作用较小.该方法仅利用了一种领域制造网格的数据,结论是否适合于其他领域的制造网格还待进一步验证.
2 基于多重链接的有向制造网格节点权重计算方法
为了克服现有制造网格节点权重计算方法准确率及召回率低、时间复杂度高的不足,笔者提出了一种基于多重链接的有向制造网格节点权重计算方法.该方法首先将有向制造网格抽象成一种有向网络图G= (R,N),每个制造节点构成网络中的节点,制造节点之间的关系构成节点之间的边.由于每个制造节点所拥有的关联节点(关联程度)不同,因此各个制造节点具有不同的权值.节点权值越大,说明该节点的影响力越大,成为状态汇聚节点的可能性也就越大.在计算节点权重时,考虑到节点拥有的关联节点数量以及节点链接关系和交互关系等多方面因素,提高了计算效率以及准确率.
该方法的基本原理如下.
定义1 有向制造网格的有向图G表示为G= (R,M),其中,R表示节点关系集合,M表示节点集合.
定义2 有效关联节点集合E(v)如下式所示:
E(v)={m|m∈Rrelevant(v)∩Rresponse(v)>ζ} ,
(1)
式中,ζ是非负常数阈值,表示节点v的关联节点m对节点v反馈的程度门限,超过该阈值且属于节点v的关联节点才能看做有效关联节点.
定义3 由链接关系所产生的节点权值WNWL(vi)的计算式为
(2)
式中,WNWL(vi)表示节点vi链接关系产生的节点权值,Rrelevant(vi) 为节点vi的所有关联节点的集合,RRnum(vj) 为节点vj的关联节点数目,σ是介于0和1之间的阻尼系数,N为网络图中的总节点数.
定义4 由节点交互关系所产生的节点权值WNWI(vi)的计算式为
(3)
式中,WNWI(vi)表示节点vi的节点权值,SSIS(vi) 为节点vi的状态信息集合,S表示所有具有交互情况的状态集,|S|是集合S的元素数,Rs(vj) 是节点vj针对状态信息tj的响应次数,Rμ(vj) 为响应平均值,RResp包括用户转发、回复、评论和收藏状态的信息.
定义5 节点综合权值WNWGe(vi)的计算式为
WNWGe(vi)=(1-ε) (WNWL(vi)+ε)WNWI(vi) ,
(4)
式中,参数ε(ε∈[0, 1])主要决定链接关系和节点交互关系两个因子在节点权值计算中所处的地位.当ε较小时,节点权值主要由链接关系决定,特别当ε=0 时,则完全由链接关系计算权值.
综上所述,该方法的具体算法描述如下:
(1) 利用网络垂直搜索工具,从互联网中采集制造网格的状态信息数据,提取其中的节点、连接等网络拓扑信息存入数据库待处理;
(2) 构建有向网络图G=(R,N);
(3) 利用式(1)计算有效关联节点集合E(v);
(4) 利用式(2)计算由链接关系所产生的节点权值WNWL(vi);
(5) 利用式(3)计算由节点交互关系所产生的节点权值WNWI(vi);
(6) 利用式(4)计算节点综合权值WNWGe(vi);
(7) 计算网络图中所有节点的综合权值,并按综合权值由大到小排序,选取综合权值较大的n个节点作为状态汇聚代理的候选对象.
新方法从计算效率和精确度两个方面改进了现有方法.首先,通过定义有效关联节点集合,将没有或拥有少量关联节点的节点排除掉,它们成为状态汇聚代理的可能性极小,因为状态汇聚代理或高权值节点必然拥有大量的关联节点,这样就可大幅度减小网络图规模,有利于提高计算效率.其次,在计算节点权值时,不仅考虑了由关联节点产生的链接关系,还考虑了状态信息的发布、转发、回复以及收藏等所产生的节点交互关系,因此提高了计算精确度.
3 实验结果及分析
由于状态汇聚代理的识别被量化成网络中节点权值序列,故在这个序列中排名靠前的可认为是网络中的状态汇聚代理.目前还没有用于衡量状态汇聚代理识别效果的标准,学术界主要采用算法比较方式来确认状态汇聚代理的识别效果.
下面对基于多重链接算法和基于网络拓扑特性算法进行3种统计学方法比较,即T-Test检验、Kendall tau Rank检验和Spearman Rank检验.
(1) 数据集.从烟草工业制造集成化信息系统及商业物流销售集成化信息系统中抽取原始的数据,生成烟草制造网格所需的原始数据集,为本课题研究的验证过程提供所需的数据支持.
(2) 网络分析工具.采用自行研制的网络分析工具对所采集的数据集进行分析,该工具实现了多重链接、基于网络拓扑特性、Topic-based、PageRank、HITS、TwitterRank、InfluenceRank等多种算法,可以对这些算法的性能进行对比实验分析.该工具运行在一台PC机上, CPU为Intel 酷睿i5 3350P,主频为 3.1 GHz,内存为 4 GB.
(3) T-Test检验.T-Test检验也称student-t检验,主要用于检验样本空间较小 (n<30)、总体标准差σ未知的正态分布数据.
首先使用多重链接算法和基于网络拓扑特性算法分别对 10 000 个制造网格节点进行状态汇聚代理识别,得到前100位节点权值排名靠前的制造节点,然后对这100个节点使用T-Test检验,得到这些节点的P分布.图1和图2分别给出了多重链接算法和基于网络拓扑特性算法的T-Test检验的P分布.图中直线标识了P=0.05 (即5%)的分割线,可以看出,节点的P值主要集中在该直线以下,即通过T-Test检验发现,两种算法计算的节点领袖权值具有较高的可信度,能够代表网络中的状态汇聚代理.

图1 多重链接算法的T-Test检验图2 基于网络拓扑特性算法的T-Test检验
(4) Kendall-tau检验.在统计学中,肯德尔相关系数(Kendall-tau)是用来测量两个随机变量相关性的统计值,用希腊字母τ表示其值.肯德尔检验是一个无参数假设检验,它使用计算得到的相关系数去检验两个随机变量的统计依赖性.τ的取值范围在 -1 到1之间.当τ=1 时,表示两个随机变量拥有一致的等级相关性;当τ=-1 时,表示两个随机变量拥有完全相反的等级相关性;当τ=0 时,表示两个随机变量是相互独立的.τ的计算公式为
τ=(ne-nd)/((n0-n1)(n0-n2))1/2.



根据计算结果,多重链接算法和基于网络拓扑特性算法之间的τ值为0.910 7,说明这两种算法具有很高的一致性.
(5) Spearman Rank检验.在统计学中,斯皮尔曼等级相关系数(Spearman Rank)用来估计两个变量X、Y之间的相关性,其中变量间的相关性可以使用单调函数来描述,并用希腊字母ρ表示其值.如果两个变量取值的两个集合中均不存在相同的两个元素,那么,当其中一个变量可以表示为另一个变量的单调函数 (即两个变量的变化趋势相同)时,两个变量之间的ρ值范围在 -1 到1之间.
假设两个随机变量分别为X、Y(也可以看做是两个集合),它们的元素个数均为N,两个随机变量取的第i(1≤i≤N) 个值分别用Xi、Yi表示.对X、Y进行排序(同时为升序或降序),得到两个元素排行集合x、y,其中元素xi、yi分别为Xi在X中的排行以及Yi在Y中的排行.将集合x、y中的元素对应相减,得到一个排行差分集合d,其中,di=xi-yi,1≤i≤N.随机变量X、Y之间的ρ值可以由x、y或者d计算得到,其计算式为
表1给出了7种算法之间的斯皮尔曼等级相关系数值.从表1可以看出,多重链接算法和基于网络拓扑特性算法具有较高的斯皮尔曼等级相关系数值,序列一致性较高,说明多重链接算法和基于网络拓扑特性算法在状态汇聚代理识别上表现出较好的能力.
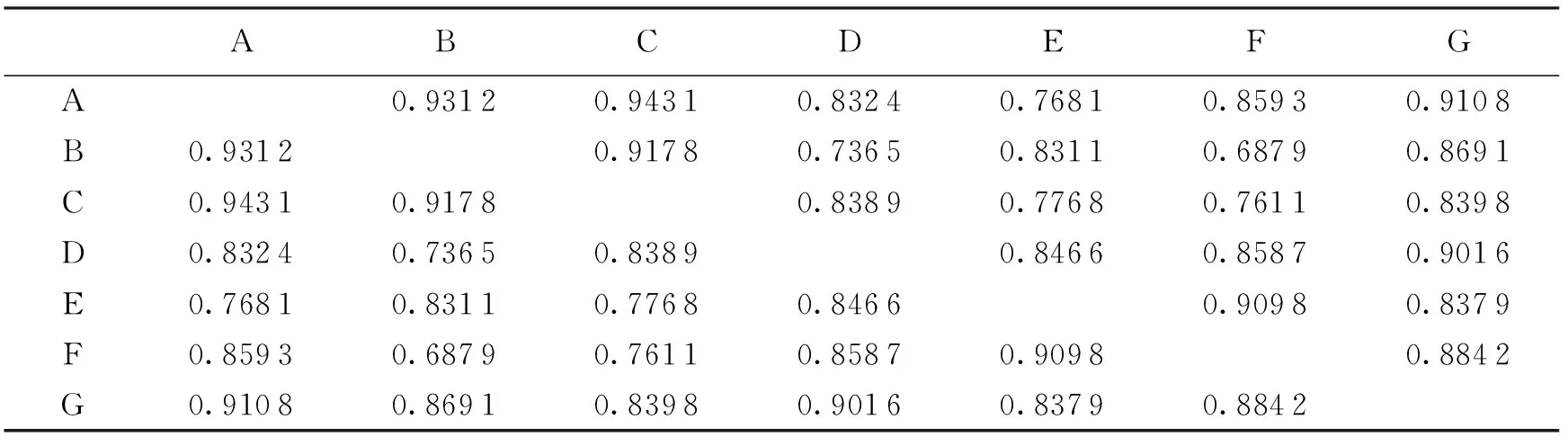
表1 各算法的斯皮尔曼等级相关系数值表
注:A表示Topological;B表示Topic;C表示多重链接;D表示PageRank;E表示HITS;F表示TwitterRank;G表示InfluenceRank.
(6) 准确率与召回率.使用准确率和召回率(查全率)来评价状态汇聚代理识别算法的性能,其中准确率和召回率分别使用P和R表示:
P=A/(A+B) ,R=A/(A+C) ,
式中,A表示找到的真实状态汇聚代理数目;B表示找到的非真实状态汇聚代理数目;C表示未识别到的真实状态汇聚代理数目.
由于在状态汇聚代理识别中还没有标准来衡量是否发现了全部的状态汇聚代理,因此在计算准确率和召回率时,通常采用基于经验的状态汇聚代理来获得真实状态汇聚代理的数目.
表2是以处理10 000个制造节点为基准测试的.从表2中可以看出,单纯分析网络节点(如入度、出度等链接关系分析算法)可以降低节点分析时间,但准确率和召回率不高.考虑节点内容(如ThreadRank、InfluenceRank及TwitterRank等算法)后能够提高节点分析的召回率和准确率,但是会大大降低系统效率.
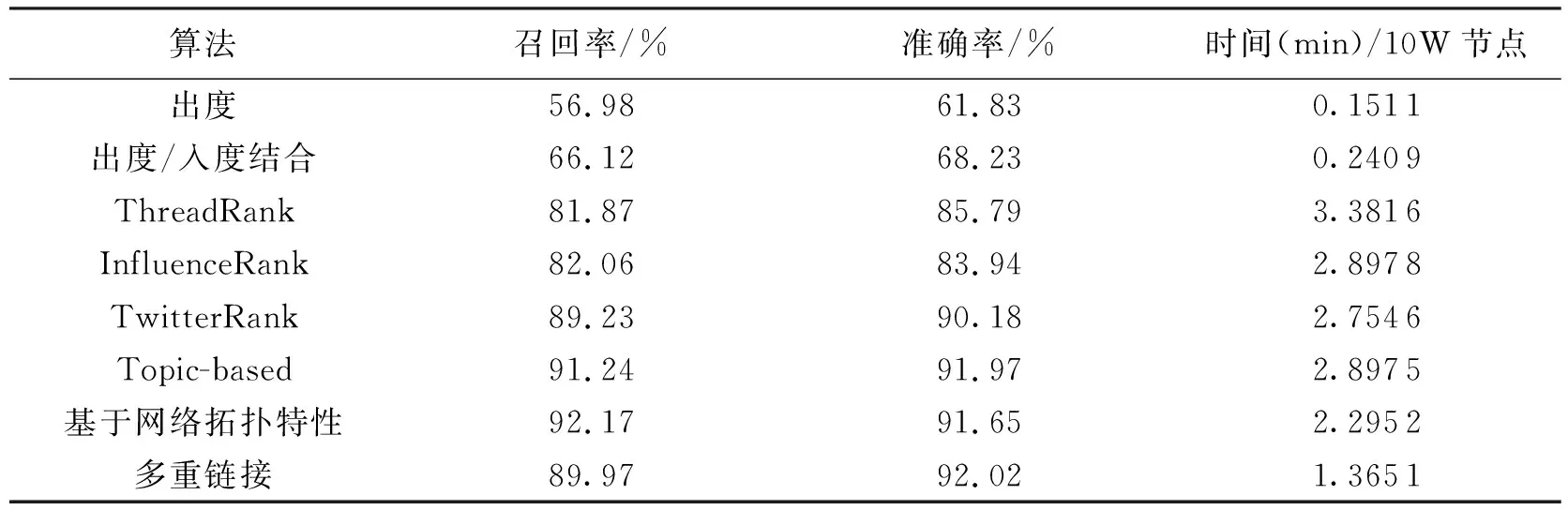
表2 各种算法的召回率、准确率及平均节点处理时间对照
注: 时间测试是在包含1万个制造节点的仿真数据环境下得到的结果.
笔者采用制造网格拓扑结构中链接关系与节点交互相结合的计算方法,降低了网络节点规模,从而提高了计算速度,同时显著提高了准确率和召回率.
从图3和图4可以得出,在测试数据集上,多重链接、基于网络拓扑特性及Topic-based等算法都具有较好的准确率和召回率,与TwitterRank算法基本相当,比常见的出度和出度/入度结合算法更好.在测试数据集上,出度和出度/入度结合算法的召回率和准确率都比较低.
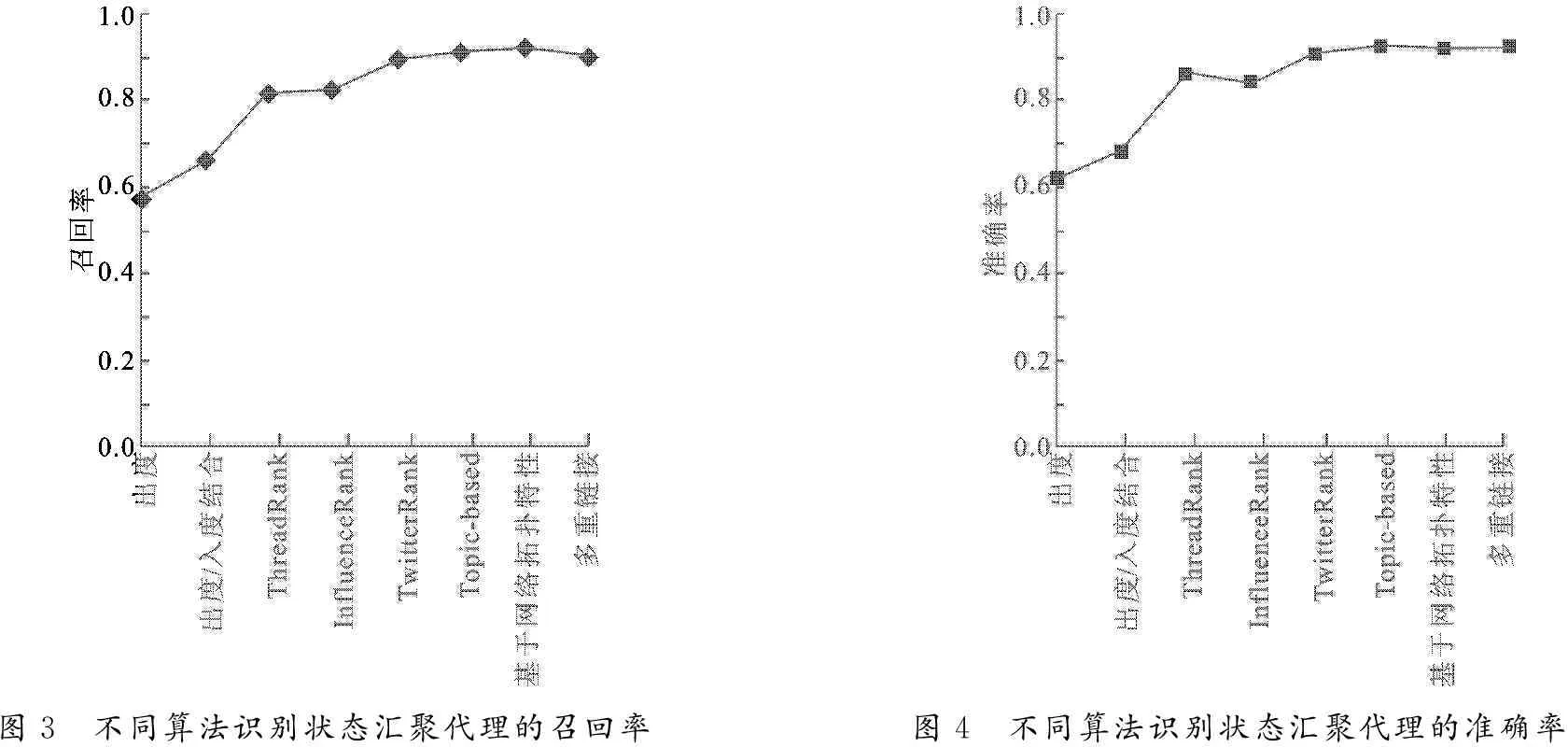
图3 不同算法识别状态汇聚代理的召回率图4 不同算法识别状态汇聚代理的准确率
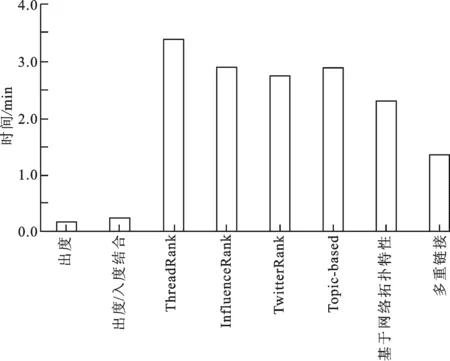
图5 不同算法在计算时间上的比较
从图5可以看出,出度和出度/入度结合两种算法的计算时间要比其他算法优异.因为在计算过程中,这两种算法没有考虑其他的附加条件,所以算法比较简单,但召回率和准确率都比较低.而其他状态汇聚代理识别算法由于考虑了更多的修正因素,因此时间复杂度稍高.相比之下,多重链接算法具有折中的时间复杂度.
4 总 结
采用T-Test、Kendall-tau和斯皮尔曼等级相关系数这3种统计学检验标准,对不同的状态汇聚代理识别算法进行了对比实验.实验结果表明,多重链接算法具有较高的状态汇聚代理识别能力,与基于网络拓扑特性、Topic-based等算法具有一致性.
从算法的准确率和召回率以及计算时间的实验结果可以看出,多重链接算法不仅在准确率和召回率上表现良好,并且比基于网络拓扑特性、Topic-based等算法的时间复杂度要低,这对于处理海量网络数据来说是至关重要的.因此,从状态汇聚节点识别能力、准确率和召回率以及计算时间等综合指标来看,多重链接算法更具优势.
[1] Wang Z Z, Qu T, Chen Q X, et.al. Resource Model and Service Match Algorithm for Mould Manufacturing Grid[J]. International Journal of Computer Integrated Manufacturing, 2012, 25(11): 1011-1028.
[2] Tao F, Zhang L, Lu K, et al. Research on Manufacturing Grid Resource Service Optimal-selection and Composition Framework[J]. Enterprise Information Systems, 2012, 6(2): 237-264.
[3] 孙鹏岗, 权义宁, 刘俊萍. L-模糊集信任机制的网格计算任务调度方法[J]. 西安电子科技大学学报, 2008, 35(1): 110-115.
Sun Penggang, Quan Yining, Liu Junping. Task Scheduling Based on Trust Mechanism of the L-fuzzy Set in Grid Computing[J]. Journal of Xidian University, 2008, 35(1): 110-115.
[4] Brink R V, Rusinowska A, Steffen F. Measuring Power and Satisfaction in Societies with Opinion Leaders: an Axiomatization[J]. Social Choice and Welfare, 2013, 41(3): 671-683.
[5] Nakajima S, Tatemura J. Discovering Import-ant Bloggers Based on Analyzing Blog Threads[C]//The 14th International World Wide Web Conference. Piscataway: IEEE, 2005: 2397879.
[6] Song X, Chi Y, Hino K. Identifying Opinion Leaders in the Blogosphere[C]//Conference on Information and Knowledge Management. New York: ACM, 2011: 971-974.
[7] Weng J, Lim E P, Jiang J. Twitterrank: Finding Topic-sensitive Influential Twitterers[C]//Proceedings of the 3rd ACM International Conference on Web Search and Data Mining. New York: ACM, 2010: 261-270.
[8] Tang J, Sun J, Wang C, et al. Social Influence Analysis in Large-scale Networks[C]//Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM, 2009: 807-816.
