基于IKAnalyzer和Lucene的地理编码中文搜索引擎的研究与实现
2014-06-24柴洁
柴洁
(重庆市勘测院航测遥感所,重庆 400020)
基于IKAnalyzer和Lucene的地理编码中文搜索引擎的研究与实现
柴洁∗
(重庆市勘测院航测遥感所,重庆 400020)
为实现带有地址信息的属性数据的空间化,依据数据采集相关规范和标准,通过建立地址模型中地理实体的一一对应关系组建空间参照数据库,地理编码索引建立以及搜索都基于多元分词算法,因此研究采用IKAnalyzer中文分词术实现词库的建立,基于Lucene开源框架开发出一套地理编码系统,进而实现了地理编码标准地址入库、地址匹配搜索引擎正向、逆向、分级搜索、模糊查询。
地理编码;IKAnalyzer;Lucene;分级搜索;模糊查询
1 引 言
目前,各行业领域的大部分业务信息都与地理空间位置有着密切联系,而对这些数据的空间位置特征描述都是以中文语言文字的属性记录形式存在,未包含能够确定其具体空间位置的坐标信息。在地理信息系统的展示及应用过程中,系统无法直接通过这些文字描述将其定位到实际的空间位置。因此,迫切需要通过某种手段,实现对带有地址信息的属性数据空间化[1~3]。
互联网已经逐渐成为人们生活不可或缺的一部分,每天产生海量的信息中隐含着难以估量的地理信息,如何才能将其挖掘出来,值得我们思考与实践。要整合大量历史不规范的地名地址数据,不仅是技术层面的问题,还有部门之间的沟通协调、共享机制的问题。因此为有效利用地址编码数据[4~6],应建立有效的、良性循环的地址编码数据更新机制,建立地址编码数据共享交换机制,保障数据的应用、更新与数据现势性。
地理编码是基于位置的应用服务系统的核心技术之一,负责将大量的地址信息通过地址匹配服务与空间地理信息相关联。通过建立相应的地址编码,实现对地址匹配[7~8],使得这些信息快速、准确的转换为空间地理数据,从而实现空间与非空间信息的资源整合。地理编码技术是实现大量管理信息(MIS数据)基于地理信息系统(GIS)空间定位和可视化分析应用的桥梁[9-11]。
本文采用了IKAnalyzer中文分词技术和Lucene开源框架开发一套地理编码系统,实现了地理编码标准地址入库、地址匹配搜索引擎正向、逆向、分级搜索、模糊查询等功能。
2 地理编码标准地址库
2.1 可伸缩地址模型
国家标准《数字城市地理信息公共平台地名/地址编码规则》(GB/T23705-2009)中规定了不同粒度范围地名/地址的描述规则,可以看做是一种在层次上可伸缩的地名/地址模型,如表1所示。

可伸缩地址模型中地址要素采用的地址级别 表1
可伸缩地址模型规则:
(1)存在门(楼)牌号时,使用“道路名(小区名)+门(楼)牌号”表述地址;
(2)存在标志物时,使用“行政区划+标志物名”表述地址;
(3)第二种表述的标志物多于一个时,对行政区划的粒度进行延伸,直至唯一确定此地址。
2.2 空间参照数据库
空间参照数据库是数据采集的规范和标准,也是地理编码技术的核心基础。空间参照数据库组成地址模型中所包含的地理实体种类一一对应;按库表结构依次录入(批量导入)全市所有区县、街道、道路、小区、标志物、门(楼)牌的名称(简称、别名)和地理坐标即可构建一个城市的空间参照数据库。地理编码标准空间参照数据表结构如表2所示。
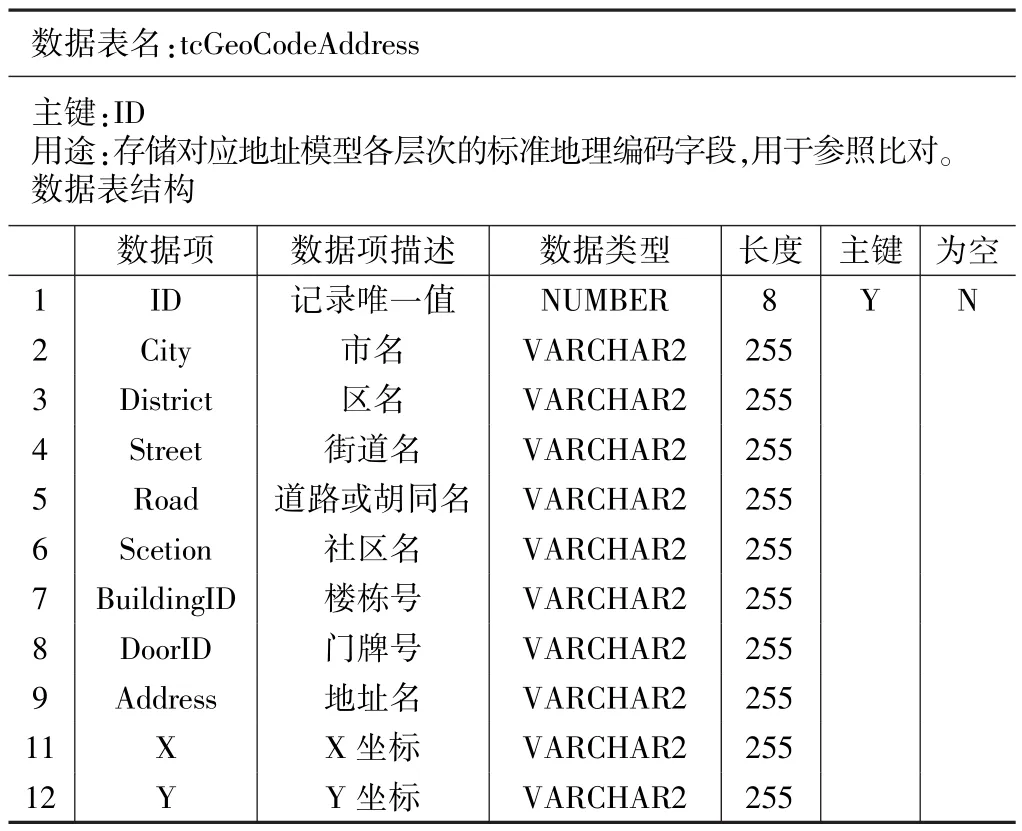
地理编码标准空间参照数据表 表2
3 IKAnalyzer分词算法与词库建立
IKAnalyzer是一个开源的、基于Java语言开发的中文分词工具包,分词器结构如图1所示:

图1 IKAnalyzer分词器结构图
本设计分词算法流程建立如图2所示:
地理编码索引建立以及搜索都基于多元分词算法,分词效果的好坏取决于分词字典的完备性。针对分词字典需要具备以下特性:
(1)选取通用汉语词条作为系统分词词典,尽可能多的容纳日常用词;
(2)增加停词词典,过滤敏感词汇,用户可以根据需要过滤掉包含特定词汇的记录,避免被搜索引擎搜索到;
(3)用户自定义词典,可提供增、删、改功能,用户根据实际需要修改自定义词典。

图2 分词算法流程图
采用IKAnalyzer分词词典作为系统词典,包含数十万日常用词,能够满足用户常用的分词搜索。分词示例:
北京市东城区建国门街道苏州社区北京站前街1号北京市邮政公司==
北京市北京东城区东城城区建国门建国国门街道苏州社区北京站北京站前街1号北京市北京邮政公司
4 Lucene索引建立
Lucene是一个开放源代码的全文检索引擎工具包,Lucene版本:3.0.2,全文检索分两个部分:索引创建(Indexing)和搜索索引(Search)。
索引过程包括:①有一系列被索引文件(此处所指即数据库数据);②被索引文件经过语法分析和语言处理形成一系列词(Term);③经过索引创建形成词典和反向索引表;④通过索引存储将索引写入硬盘。
搜索过程包括:①用户输入查询语句;②对查询语句经过语法分析和语言分析得到一系列词(Term);③通过语法分析得到一个查询树;④通过索引存储将索引读入到内存;⑤利用查询树搜索索引,从而得到每个词(Term)的文档链表,对文档链表进行交差,并得到结果文档;⑥将搜索到的结果文档对查询的相关性进行排序;⑦返回查询结果给用户。
本设计索引和搜索的流程图如图3所示:

图3 索引和搜索的流程图
4.1 索引创建(Indexing)
索引过程创建如下:
(1)创建一个IndexWriter用来写索引文件,它有几个参数,INDEX_DIR就是索引文件所存放的位置, Analyzer便是用来对文档进行词法分析和语言处理的。
(2)创建一个Document代表要索引的文档。
(3)将不同的Field加入到文档中。不同类型的信息用不同的Field来表示,在本研究中,一共有两类信息进行了索引,一个是文件路径,一个是文件内容。其中FileReader的SRC_FILE就表示要索引的源文件。
(4)IndexWriter调用函数addDocument将索引写到索引文件夹中。
本设计和开发中文分词器将标准地址进行拆分,完善中文分词词库,通过语言处理组件将词源进行标准化处理,使用索引组件将标准化之后的词条创建字典表,并生成文档倒排链表,索引文件存入硬盘。本设计索引过程创建如下:
(1)分词:使用IKAnalyzer中文分词组建将查询语句进行拆分,除去“停词”。IKAnalyzer中文分词组建自带强大的中文分词词库,同时还可以拓展应用词库,将地理编码应用城市的专有地址地名录入应用词库,进行定制性的分词处理;
(2)标准化:语言处理组件将词源进行标准化处理,将“北京市”处理成“北京”,去掉通用的“街”、“巷”、“路”等词汇;
(3)索引:使用索引组件将标准化之后的词条创建字典表,并合成同义词,生成文档倒排链表。索引文件列表如图4所示:
4.2 搜索索引(Search)
搜索过程创建如下:
(1)IndexReader将磁盘上的索引信息读入到内存,INDEX_DIR就是索引文件存放的位置。
(2)创建IndexSearcher准备进行搜索。

图4 索引文件列表图
(3)创建Analyer用来对查询语句进行词法分析和语言处理。
(4)创建QueryParser用来对查询语句进行语法分析。
(5)QueryParser调用parser进行语法分析,形成查询语法树,放到Query中。
(6)IndexSearcher调用search对查询语法树Query进行搜索,得到结果TopScoreDocCollector。
本设计索引和搜索的建立过程如下:
(1)用户输入查询语句;
(2)对查询语句进行词法分析,语法处理及语言处理:生成语法树;
(3)搜索索引,得到符合语法树的记录:对分词之后的各词元,找出其对应的文档链表,对多个链表进行逻辑操作,得到终链表;
(4)根据最终链表,查询语句的相关性,对结果进行排序:采用空间向量模型算法(VSM),计算次元权重,根据相关性对结果进行排序,得到类似Baidu、Google搜索排序效果。
5 地址匹配
地理编码引擎将地址编码中地址字符串输入到地理坐标值输出分为两个过程:字符串拆分、数据库匹配。系统通过字符串拆分将地址字符串分解成若干个地址要素和得出相应的地址公式,通过数据库匹配找出与地址串相对应的地理坐标值,如图5所示:

图5 地理编码-地址匹配的实现过程
地理编码搜索引擎工作流程图如图6所示:

图6 搜索引擎工作流图
在地理编码搜索引擎的支撑下,可以提供根据地址串生成位置(包括坐标信息和位置图)、根据位置查询地址串、获得地址串的标准地址等功能,具体过程如图7所示:
图7 搜索过程图
6 地址搜索引擎
本设计采用Lucene+IKAnalyzer开源框架搭建地址匹配搜索引擎,地理编码-地址搜索引擎功能结构图如图8所示:

图8 地理编码搜索引擎功能结构
6.1 关键字搜索引擎
(1)模糊查询
根据用户输入的关键词检索索引词条,将匹配结果按相似度排序之后返回并高亮显示关键字,如图9所示:

图9 模糊查询-关键字搜索匹配结果图
(2)分级查询
可以依据模糊查询的结果进行分层精细查询,也可以按照用户需求分区域分类型进行定制查询,查询结果按匹配相似度排序返回,搜索效果如图10所示:
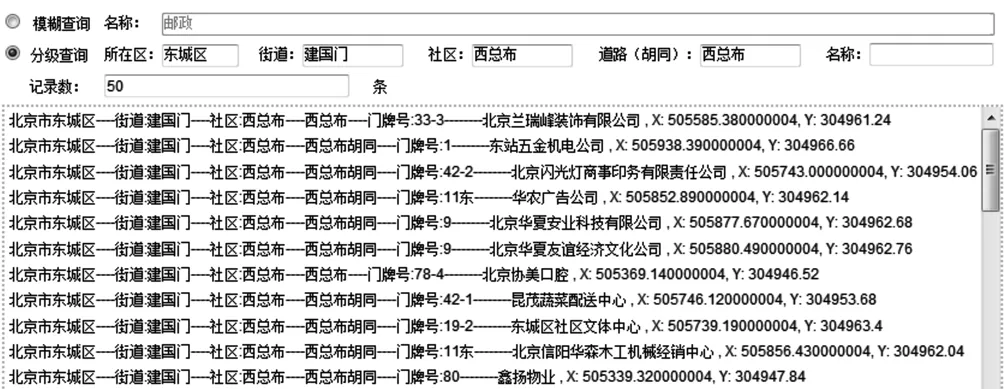
图10 分级查询-分区域分类型查询匹配结果图
6.2 拼音搜索引擎
搜索引擎增加拼音搜索功能,主要包括以下几种方式:
(1)拼音简拼
拼音简拼搜索如图11所示:

图11 拼音简拼搜索效果图
(2)拼音全拼
拼音全拼搜索如图12所示:

图12 拼音全拼搜索效果图
(3)拼音汉字混合
拼音汉字搜索如图13所示:

图13 拼音汉字搜索效果图
6.3 正向、逆向、分级搜索引擎
地址搜索引擎分别提供通过地址描述搜索空间位置,通过空间坐标搜索地址描述以及通过分级过滤搜索记录的功能。
(1)正向搜索
“正查”:类似Google和Baidu,实现对自然语言地址信息的语义分析、词法分析,自动和标准地址库匹配,提供精确的或接近的地理坐标(X,Y);根据用户输入的关键词检索索引词条,将匹配结果按相似度排序之后返回并高亮显示关键字,搜索如图14所示:

图14 正向搜索效果图
(2)分级搜索
通过区、街道、社区、道路联合关键字进行分级过滤搜索。通过空间位置获得地址描述;可以依据模糊查询的结果进行分层精细查询,也可以按照用户需求分区域分类型进行定制查询,查询结果按匹配相似度排序返回,如图14所示:

图14 分级搜索效果图
(3)空间逆向搜索
“逆查”:通过空间位置获得地址描述。在城市范围内,根据任意位置坐标(X,Y),快速解析出合理的地址描述文字,能够生成查询位置点和返回POI点的相对关系,支持多个记录的返回,返回的方式要求以最近的方式而不是以查询顺序的方式,返回包括POI点相对位置关系的描述;根据用户输入的坐标串,搜索在制定范围之内的所有地址,搜索如图15所示:

图15 空间逆向搜索效果图
7 结 语
本文采用了IKAnalyzer中文分词技术和Lucene开源框架开发一套地理编码服务系统,实现了地理编码标准地址入库流程、地址匹配搜索引擎正向、逆向、模糊查询、分级搜索。本文所阐述的地理编码引擎,在互联网地理信息挖掘方面做出有益的尝试和积极的探索。目前,搜索引擎原型应用系统尚待完善,在今后的学习工作当中,进一步完善本文所论述的地理信息编码引擎及原型系统,下一步研究还需要优化软件体系结构与数据库设计,提高匹配效率,对中文分词算法和语义分析算法进一步完善,提高地名地址的识别效率。
[1] 蒋景瞳.我国地理信息标准化政策研究[J].测绘科学,2008,33(1).
[2] 张磊,张代远.中文分词算法解析[J].电脑知识与技术, 2009,5(1):192~193.
[3] 李琦,罗志清等.基于不规则网格的城市管理网格体系与地理编码[J].武汉大学学报·信息科学版,2005,30 (5):408~410.
[4] 高昭良.城市地理空间字典——地理编码[J].城市勘测,2008,2(2):20~22.
[5] 张鹤,孔令彦.城市地址编码发展历史及现状分析[J].测绘通报,2008(007):58~60.
[6] 薛明,肖学年.关于地理编码几个问题的思考[J].北京测绘,2007(2):54~56.
[7] 洪莹.城市地名地址匹配方法研究及实验[D].辽宁:辽宁工程技术大学硕士论文,2009.
[8] Morad M.British Standard 7666 as a Framework for Geocoding Land and Property Information the UK[Z].Compute, Environ·and Urban Systems,2002,26:483~492.
[9] LANGRAN G.Time in Geographic Information Systems [M].Taylor&Francis Ltd,Lond,UK,1992.
[10] LANGRAN G,CHRISMAN N R.A Framework for Temporal Geographic Information[J].Cartographica,1988,25 (3).
[11] Oracle Corp.Oracle Spatial Users'Guide and Reference Release 9.0.2[Z].2002.
Research and Implementation of Chinese Search Engine in Geocoding Based on IKAnalyzer and Lucene
Chai Jie
(Chongqing Survey Institute,Remote Sensing department,Chongqing 400020,China)
To realize the spatialization of attribute data with address information,based on relevant norms and standards of data collecting,this study formed a spatial reference database by establishing the one-to-one correspondence and relationship of geographical entities in the address model.Geocoding indexing and searching based on multiple segmentation algorithm.The establishment of thesaurus adopted the chinese word segmentation technology of IKAnalyze.A geocoding service system is based on the open source framework of Lucene,realizing the Warehousing processes of geocoding standard address,forward searching,backward searching,classification searching,and fuzzy query in address-matching searching engine.
Geocoding;IKAnalyzer;Lucene;classification search;fuzzy query
1672-8262(2014)06-45-06
P208.1
B
2014—03—23
柴洁(1988—),女,工程师,主要从事地理信息系统开发及应用技术工作。
