分布估计算法与爬山法的混合优化算法
2014-06-19闫晓梅王丽芳严莉娜
闫晓梅,王丽芳,严莉娜
(太原科技大学电子信息工程学院,太原 030024)
分布估计算法源于遗传算法,用估计算子和采样算子代替了遗传算法中的交叉算子和变异算子,避免了遗传算法中存在的构造块被破坏的问题[1]。分布估计算法的概念是在1996年正式提出的[2],但该算法最早的代表性研究成果是1994年提出的PBIL算法[3]。由于分布估计算法从宏观上控制算法的进化方向,而且分布估计算法具有良好的理论基础,因此引起了国内外学者的广泛关注,成为智能计算领域的研究热点之一[4]。学者们针对分布估计算法提出了不同的改进策略[5]和具有不同估计采样算子的算法[6],并在诸多领域进行了应用方面的研究[7-8]。
Copula分布估计算法是将Copula理论用于分布估计算法的估计和采样之中,将多变量的联合分布函数分解成一个Copula函数和多个单变量的分布函数,并由此构造出不同的估计算子和采样算子[9]。经验Copula分布估计算法是根据群体的分布情况构造经验函数,建立了相应的采样算子。经验Copula分布估计算法是一种全局优化算法,对于标准测试问题的优化,它能够很快搜索到全局最优解的附近,但是后期的搜索就很慢。从文献[10]的实验结果中也可以很清楚地看到这一点。在算法搜索后期,虽然每代都有进化,但是进化的速度非常慢,每一代的改变也非常小。这些情况说明经验Copula分布估计算法的全局搜索能力强,而局部求精的能力弱。因此在经验Copula分布估计算法中可以引入局部求精能力强,收敛速度快的局部搜索算法。
1 经验Copula分布估计算法与爬山法的混合优化算法
爬山法是一种局部搜索算法,如果从适当的起始位置开始,那么用爬山法可以很快搜索到局部的极值点。在经验Copula分布估计算法进化的过程中,可以加入局部搜索算法,以增强算法的局部求精能力。在经验Copula分布估计算法中,每个新个体的产生都是根据上一代优势群体的分布模型产生的,产生规则单一,致使新一代群体个性差异较小。增加群体中的个性差异,同时又不能过于背离群体的分布模型,是改进算法的一个思路。当经验Copula分布估计算法进化一代后,随机选择若干个体进行局部搜索,将搜索得到的新个体作为新一代群体中的一部分参与进化。这样在算法中增加了个体的差异性,同时对群体的进化方向不会有很大的影响。
算法的具体步骤如下:
(1)初始化群体。在m维搜索空间中随机产生N个个体,组成初始群体。确定选择率s和变异率t.
(2)评价适应值。根据相应的评价标准对群体中的每个个体评价,得到每个个体的适应值。
(3)如果达到算法终止条件,例如达到规定的进化代数或相邻若干代群体的最优适应值没有变化,则算法停止,群体中的最优个体即为优化的结果。否则执行步骤(4).
(4)精英保留。以最小化问题为例,将群体中适应值最小的个体保留至下一代。
(5)选择优势群体。采用截断选择或比例选择等选择算子,从当前群体中选出s*N个适应值较小的个体组成优势群体。
(6)爬山法搜索。从当前群体或优势群体中随机选择t*N个个体为起始点进行爬山法搜索,得到t*N个新个体,将这些新个体作为新一代群体中的一部分。
(7)估计概率模型。根据选择出的优势群体,利用文献[10]中的算法1构造经验Copula函数,并估计各维的边缘分布函数。
(8)采样得到新个体。根据经验Copula函数采样得到一组(0,1)区间内的随机数,然后根据边缘分布函数采样得到(1-t)N-1个新个体。
(9)由以上的N个个体组成新一代群体,继续执行步骤(2).
2 初始种群均匀化策略
在群体智能优化算法中,初始种群要尽可能均匀地且互不相关地分散在搜索空间中。在以往实验时往往直接利用随机函数产生初始种群。图1显示了在二维搜索空间中随机产生的群体,从中可见许多相邻的网格中都没有个体存在。这样对算法的优化结果会有一定的影响。因此需要设计一种均匀初始种群的产生策略。
该策略的基本思想就是将搜索空间中的每一维平均分成若干长度相等的区间,这样整个搜索空间就分成了若干小区域。例如图2中的二维搜索空间,用虚线将搜索空间分成了10×10的小区域,然后在每个小区域中随机产生一个个体,从而组成在搜索空间中均匀分布的且互不相关的群体。如果按维数在每个小区域中依次产生个体,那么算法嵌套的层数会很深。因此需设计一种易行的产生策略。
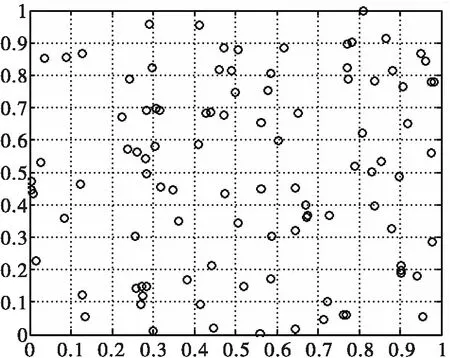
图1 随机初始化种群Fig.1 The randomized population

图2 均匀初始化种群Fig.2 The evenly-randomized population
为叙述方便,设搜索空间中每维的长度相等。以二维搜索空间为例,对二维搜索空间的每一维二等分,则将其划分成了四个子空间,设每个子空间的边长为h.如图3所示,对每个子空间编号,分别是00,01,10,11,这四个编号恰好是两位的二进制编码,其产生方法可以采用基二算法或反射Gray码算法即可获得[11]。这样在编号为00的子空间中随机产生一个点(p,q),那么(p,q)+(0,1)h就得到了01子空间中的一个点。其余子空间也相同。也就是说,在编号为00的子空间中随机产生四个点,分别加上(0,0),(0,h),(h,0)和(h,h)就得到了上面论述中需要的四个随机点,它们均匀地且互不相关地分散在搜索空间中。
对于M维搜索空间,若每一维二等分,则将其划分成2M个子空间,对这些子空间编号,则形成M位二进制编码。如三维搜索空间的每维二等分子空间编号为000,001,010,011,100,101,110,111.同样,在编号为(00…0)的子空间中随机产生2M个M维数,分别加上子空间编号(k1,k2,…,kM)h(其中,ki=0或1,2,…,M)就得到了相应子空间中的随机点。
上述方法只是将每维空间二等分。若要将每维空间四等分,则可使用两层嵌套。不妨记每个子空间的边长仍为h.例如先产生编号为00空间的一个随机点(p,q),那么(p,q)+(0,1)h+(1,1)2h就是编号为23的子空间中的点,如图4所示。即编号为00空间的一个随机点,先加上(0,0)h,(0,1)h,(1,0)h,或(1,1)h,再加上(0,0)2h,(0,1)2h,(1,0)2h,或(1,1)2h便可得任一子空间中的点。

图3 二等分图
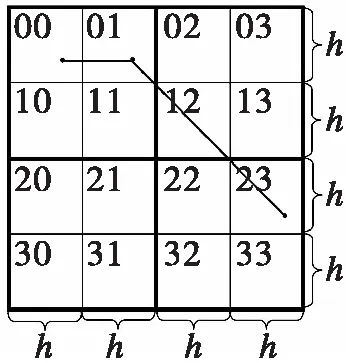
图4 四等分图
对于M维搜索空间,若每一维四等分,则将其划分成4M个子空间,不妨将每个子空间的边长仍记为h.在编号为(00…0)的子空间中随机产生4M个M维数,分别加上子空间编号(k1,k2,…,kM)h+(l1,l2,…,lM)2h(其中,ki=0或1,li=0或1,i=1,2,…,M)就得到了相应子空间中的随机点。
推而广之,对于M维搜索空间,若每一维2n等分,则将其划分成(2n)M个子空间,不妨将每个子空间的边长仍记为h.则要在每个子空间中产生一个点需要s层嵌套。在编号为(00…0)的子空间中随机产生(2n)M个M维数,分别加上 (k11,k12,…,k1M)h+(k21,k22,…,k2M)2h+…+(kn1,kn2,…,knM)(2n)h(其中,kij=0或1,i=1,2,…n,j=1,2,…,M)就得到了每个子空间中的随机点。
以M维搜索空间,每一维四等分为例,该均匀初始化策略的算法步骤如下:
(1)按文献[11]中的基二算法或反射Gray码生成算法,产生2M个M位二进制编码,保存在M×2M的二维数组A中,则每一列为一个二进制编码。
(2)k=1;
for(i=1…2M)
for(j=1…2M)
pop(k)=A(i)h+A(j)2h+rand()
k=k+1;
end
end
在该算法中同样设每维搜索范围为[a,b],则h=(b-a)/4,算法中rand()表示一个由a~a+h之间随机数组成的M维列向量,pop中保存的就是均匀初始化得到的2M×2M=4M个个体。
3 仿真实验
为测试算法性能,并与基本的经验Copula分布估计算法进行比较,对下面三个最小化标准测试函数进行测试。


与文献[10]相同,问题维数D=10,三个问题的群体规模分别是2000、2000和750.算法最大的适应值评价次数是300 000次,并使用截断选择算子进行优势群体的选择。算法选择率为0.5,变异率为0.05.采样时使用的方差有下面三种策略。
A.方差为固定值。
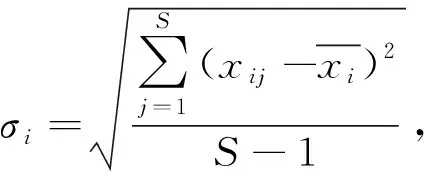
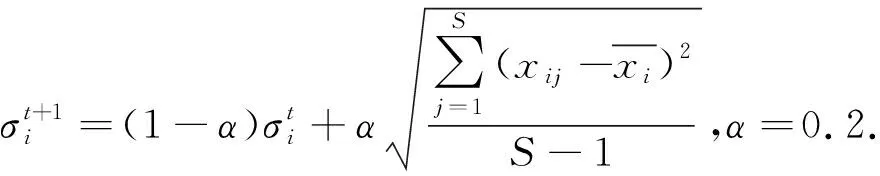
实验结果如表1-表3所示。其中文献[10]中的算法用cEDAPG表示,随机产生初始种群的经验Copula分布估计算法与爬山法的混合优化算法用cEDA-Hill表示,采用初始种群均匀化策略的经验Copula分布估计算法与爬山法的混合优化算法用cEDA-Hill2表示。

表1 三种算法优化f1的结果比较Tab.1 The comparison of three algorithms on optimizing f1

表2 三种算法优化f2的结果比较Tab.2 The comparison of three algorithms on optimizing f2
从实验结果可以看出,爬山法和均匀初始化策略在算法中都起到了一定的作用。特别是对于测试函数f1,当选择率为0.2,方差更新策略为C时,cEDA-Hill和cEDA-Hill2比cEDAPG在优化结果上有明显的改进。仿真结果表明经验Copula分布估计算法与爬山法的混合优化算法以及均匀初始化策略都有一定的有效性。
4 结论
Copula分布估计算法是将Copula理论与分布估计算法相结合得到的一类新型优化算法。经验Copula分布估计算法和爬山法的混合优化算法利用了经验Copula分布估计算法对群体搜索方向的宏观控制能力和爬山法在搜索空间中的局部搜索能力,使得算法在解决优化问题时有了一定的改进。均匀初始化策略使得初始种群能够均匀且互不相关地分散在搜索空间中,能够更全面真实地反映优化问题的特点,从而为算法进化提供良好的开端。但本文中提出的均匀初始化策略只限于对搜索空间中的每维进行多次二等份分割,即分成2n等份。一般的任意等份的且简单易行的均匀初始化策略还有待进一步的研究。

表3 三种算法优化f3的结果比较Tab.3 The comparison of three algorithms on optimizing f3
参考文献:
[1] LARRANAGA J L P.Estimation of distribution algorithms,a new tool for evolutionary computation[M].Kluwer Academic Publishers,2002.
[2] MUHLENBEIN H,PAASS G.From recombination of genes to the estimation of distributions I.Binary Parameters[C]∥Proc.PPSN IV,Berlin,1996:178-187.
[3] BALUJA S.Population-based incremental learning:a method for integrating genetic search based function optimization and competitive learning[R].Technical Rep.CMU-CS-94-163,Pittsburgh,PA:Carnegie Mellon University,1994.
[4] 王圣尧,王凌,方晨,等.分布估计算法研究进展[J].控制与决策,2012,27(7):961-966.
[5] 程玉虎,王雪松,郝名林.一种多样性保持的分布估计算法[J].电子学报,2010,38(3):591-597.
[6] 张放,鲁华翔.利用条件概率和Gibbs抽样技术为分布估计算法构造通用概率模型[J].控制理论与应用,2013,28(3):307-315.
[7] 刘洁,王丽芳.copula EDA-BP混合优化算法预测股票价格[J].太原科技大学学报,2014,35(3):194-197.
[8] ABDOLLAHZADEH A,REYNOLDS A,CHRISTIE M.CORNE D.Estimation of distribution algorithms applied to history matching[J].SPE Journal,2013,18(3):508-517.
[9] 王丽芳.Copula分布估计算法[M].北京:机械工业出版社,2012.
[10] 王丽芳,曾建潮,洪毅.利用Copula函数估计概率模型并采样的分布估计算法[J].控制与决策:2011,26(9):1333-1337,1342.
[11] RICHARD A BRUALDI.组合数学[M].冯舜玺,等,译.北京:机械工业出版社,2001.
