基于实例相似度的概念语义挖掘方法
2014-06-07徐博艺
游 妍,徐博艺,谢 诚
(1.上海交通大学安泰经济与管理学院,上海200030;2.上海交通大学软件学院,上海200240)
基于实例相似度的概念语义挖掘方法
游 妍1,徐博艺1,谢 诚2
(1.上海交通大学安泰经济与管理学院,上海200030;2.上海交通大学软件学院,上海200240)
本体在知识表达、共享、重用以及语义查询中具有重要作用,但在本体融合过程中存在概念层融合难的问题。为此,提出一种挖掘本体概念语义的方法。该方法从实例数据出发,以实例相似度矩阵为基础,在实例层和概念层交替进行概念语义挖掘,将挖掘结果通过属性语义反馈到实例层,并对其进行修正和补充。利用OAEI2012提供的测试本体进行实验,结果显示查全率与查准率均得到提高,证明了该方法的可行性和有效性。
实例相似度;实例匹配;概念语义;属性语义;本体融合;语义网
1 概述
语义网的兴起引起了人们对于本体的兴趣。本体在数据集成领域有重要的意义,促进了知识的表达、共享和重用,同时也促进了从语法到语义这一查询模式的转变。本体由实例数据和概念数据组成,概念是抽象的描述性的,实例是现实世界客观存在的。发现在现实世界中表示同一事物的对象的过程为实例匹配[1],建立不同本体概念之间的联系的过程为本体融合,是机制匹配的一种形式[2]。
目前,本体融合的方法主要有4种[3]:(1)基于通用本体,例如,OAEI2012的WikiMatch系统应用关联规则,将源本体和目标本体都关联到维基百科[4];(2)基于术语和自然语言处理技术;(3)基于结构相似度,文献[5]将结构分为内部结构(如属性、属性类型)和外部关系结构,一般与其他方法结合应用;(4)基于实例匹配,文献[6]提出一种基于已经存在的实例连接,度量约束类的实例集重叠程度,来挖掘值约束类的语义关系,进一步找到本体中的概念覆盖的方法。但通用本体无法解决领域术语与概念的匹配问题;基于自然语言处理技术的方法依赖于本体中概念的命名,与概念的实际含义无关;结构相似度的相关方法对本体结构的完善度要求较高,且前三类方法的实质是对本体中的描述性信息进行二次加工,脱离了数据的事实基础。而基于实例的方法,不考虑本体原有的结构,充分地利用实例集,从本体生成角度进行融合,只适用于已经拥有大量实例数据而概念相对较少的本体。因此,本文选取基于实例匹配的方法,融合有实例的本体。
实例匹配的方法主要有:(1)基于图的入度和出度的实例匹配方法[7];(2)基于OWL语义,如owl: sameas语义、函数性/逆函数性、基数等的实例匹配方法[8];(3)基于属性的实例匹配方法,SLINT系统通过有分辨力的属性-值对匹配实例[9]。此外,在文献[10]提出的Simrank算法中,如果2个对象连接的对象相似,则认为这两个对象也相似。文献[11]算法也是SimRank的一种拓展。基于图的方法只考虑了图中边的数量,而忽略了边的含义;OWL语义直接有效,但只存在于OWL本体中,且这几种语义占本体所有语义的比例较小;基于属性的方法一般比较公共属性的重叠度,能很好地利用属性集,但关键属性的识别是一个难点。
本文结合SimRank算法与属性语义进行实例层的匹配,计算不同数据源之间实例的相似度,利用相似的实例发现其所属概念的语义关系,达到本体融合的效果。
2 基于实例相似度的概念语义挖掘
2.1 概念语义挖掘过程
基于实例相似度挖掘概念语义的过程如图1所示。
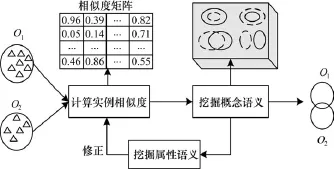
图1 基于实例相似度的概念语义挖掘过程
图1 中包含3个主要的模块:
(1)实例相似度计算模块:初次输入为包含实例的源本体和目标本体,输出为m×n的实例相似度矩阵。收到属性语义挖掘模块的反馈后,输入为属性的相关度,输出为调整的实例相似度矩阵。
(2)概念语义挖掘模块:输入为实例相似度矩阵,输出为源本体概念和目标本体概念之间可能存在的语义,如same_as,subclass_of,disjoint等,以及语义成立的可信度。
(3)属性语义挖掘模块:输入为概念语义及可信度,输出为属性语义,即属性相关度。
2.2 实例相似度
实例相似度计算的输入是分别来自源本体和目标本体的实例集,输出为实例对的相似度矩阵。对于任意的实例,通过属性连接到属性值,这样的描述在RDF中称为一个三元组<s,p,o>,<s,p,o>∈U×U×U∪L,其中,U为URI集合;L为文本集合。实例的完整描述由多个三元组构成,2个实例的描述相似则意味着实例相似,因此,在比较实例时,比较它们的属性值是一个合理的方法。
属性值可以是文本(L)或URI(U),若属性值为URI,称这个URI代表的实例为原实例的邻居实例。基于SimRank的思想[8],不仅邻居实例可以描述原实例,邻居的邻居实例也能对原实例的描述做出贡献,本文给出实例相似度计算公式,如式(1)所示。
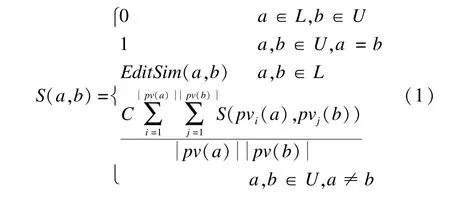
其中,C为0~1之间的衰减常数;pi为实例的第i个属性;pvi为pi对应的属性值;a或b可能没有任何属性和属性值,即pv(a)或pv(b)可能为空集,此时S(a,b)=0。
2.3 概念语义关系挖掘
实例相似度矩阵为源本体和目标本体在实例层建立了映射,要将这种映射转移到概念层才能实现在异构机制下的本体互操作。
从实例层映射中发现概念语义的过程如图2所示。其中,C1,C2分别来自源本体O1和目标本体O2;I1,I2分别为C1,C2的实例集;在O2中与I1的实例连接的实例集称为I1在O2中的映射集Map(I1)。根据映射集与目标实例集的重叠情况来度量概念语义。
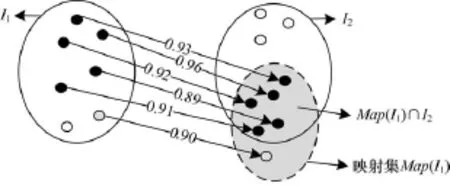
图2 从实例映射中发现概念语义的过程
定义参数p,q为度量指标,p,q的计算公式如下:

若p=1,则C1⊆C2;若q=1,则C2⊆C1。
实例之间的映射通过相似值产生,相似值是小于1大于阈值的数,并不能断定连接的实例指的是同一事物,因此,在这些映射基础上挖掘的概念语义也不是完全可信的。给出概念语义可信度的定义为:I1中实例与Map(I1)∩I2中实例的所有映射对应的相似值的平均值,如下式所示:

表1为p,q取不同的值时,C1,C2的语义对应关系,在实际计算中,将取值适当放宽,大于0.9则可以等同于1,小于0.1等同于0。

表1 概念语义与p,q值的对应关系
2.4 属性语义比对
若2个属性的定义域(Domain)和值域(Range)相似,则这2个属性很可能是相似的,且相似度与其定义域和值域语义相似的可信度相关,如图3所示。用rel(p1,p2)表示属性p1,p2的相关度,即属性语义的相似度:

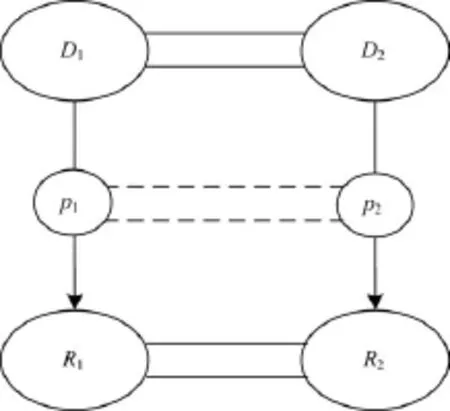
图3 从概念语义挖掘属性语义的过程

将式(1)在a,b∈U,a≠b时的情况修正为:

3 实验与结果分析
3.1 数据来源
本文选取OAEI2012提供的Benchmark测试库中的书目本体(http://oaei.ontologymatching.org/ 2012/benchmarks/index.html)进行实验。将本体101作为源本体,本体202作为目标本体。本体101是完整的参考本体,而本体202则是将本体101中的概念、实例名字和备注等用乱码替代而得到的。2个本体均包含55个实例和36个概念,其中,包含实例的概念有10个,由1 332条三元组组成。
3.2 实验结果
根据2.2节中的算法,本文比较对象型属性值和文本属性值的相似度来衡量2个实例的相似度,通过迭代计算最终得到一个相似度矩阵,如图4所示。相似值在0~1之间,值越高,代表对应的2个实例越相似。本文设置阈值为0.85,实例之间相似值大于0.85,则认为有效相似,小于0.85则认为没有意义。

图4 实例相似度矩阵中的部分数据
基于该相似度矩阵,利用2.3节中的算法查找概念语义关系,结果如表2所示。
找到概念语义关系后,能反推出本体属性之间存在的一些关系,找出相似的属性对。如(journal, sxqsnbvsq,0.89),(event,zadzjadns,0.88),(articles, YuEma,0.89),(title,dznbaln,0.89)等,括号中的数值代表属性相似的程度。返回实例相似度矩阵中,对这些属性所对应的实例相似值进行修正。由表3可见,修正后的相似度加强了源概念和目标概念之间的联系,重复概念语义挖掘的过程,可以得出源概念Inbook与目标概念 vccfsq语义相等,源概念Inproceeding与目标概念deqdxcsqcsq语义相等。由属性修正后补充新增的概念语义如表4所示。

表2 概念语义关系部分挖掘结果

表3 实例相似值修正前后的对比

表4 属性修正后新增的概念语义
3.3 实验结果评估
对实验结果用查全率(P)和查准率(R)评估。查全率是查询结果中正确的关系数与发现的关系数的比值;查准率是查询结果中正确的关系数与实际存在的关系数。用F1值来平衡查全率与查准率:

在测试本体101和本体202中,每个本体有36个概念,其中只有10个概念包含实例数据,其余26个概念均未包含实例,即实例集是空集。但由于本文方法是以实例数据为基础的,本体中不包含实例的概念是干扰性的数据,不在本文方法评估的范围内。因此在表5中,将评估结果分为2行,分别是以包含实例的概念为基数的结果和以所有概念(包含实例与未包含实例的)为基数的结果。
在实验中,利用属性语义对相似度矩阵进行了一次反馈修正,就达到了3项指标均为1的效果,因此,表5中对每项指标也分成了2栏记录,修正前的数值为挖掘流程进行了初次实例相似度计算和概念语义挖掘后的结果,修正后的数值则是在修正前的基础上,进行了属性语义挖掘、修正相似度矩阵、补充概念语义后的结果。针对本体202的概念语义挖掘实验结果评估如表5所示,从中可见,当将本体中的所有概念作为基数时,修正前 3项指标均为8/36=0.22,修正后3项指标为10/36=0.28。当将本体中有实例的概念作为基数时,修正前各项指标均为8/10=0.8,修正后找全了所有的概念语义,各项指标为1。

表5 概念语义挖掘实验结果评估
由实验结果可以看出,属性对于概念语义的修正作用较为显著,本文方法对于以实例数据为基础的本体来说是可行有效的。
3.4 与相关方法的比较
以实例为基础的本体融合方法,已有类似研究工作:Zhishi是一个实例匹配系统,利用标签进行pre-match,然后进行复杂的语义挖掘[12];ObjectCoref是一个利用属性-值对迭代自训练的实例匹配系统,挖掘频繁属性组合来调整训练过程[13];SBUEI是一个在实例层和机制层交替匹配的本体融合系统,将实例5步以内的邻居实例组成该实例的关联网,计算关联网的相似度来匹配实例,并认为相似网中的实例所属概念也相似[14]。
本文从融合机制、实例匹配依据、适用场合、数据集大小4个维度将本文方法与Zhishi,ObjectCoref和SBUEI方法进行比较,如表6所示。

表6 本文方法与Zhishi,ObjectCoref,SBUEI方法的比较
在融合机制上,本文方法与SBUEI方法较为相似,均在实例层与概念层交替,但本文实例层接受概念层的反馈,且考虑属性语义的修正作用。在实例匹配时,本文方法综合了文本、邻居实例、属性对实例的描述,适用于一般的含实例的本体。
4 结束语
本体由于其在数据集成、查询优化等领域的重要意义成为当前研究的热点,而本体融合是本体互操作性实现的一个难点。本文提出的方法是一种基于实例的概念语义挖掘方法,在客观数据中挖掘本体概念层的联系,最大限度地提取了实例数据中的信息,完成了本体机制匹配,可实现知识共享和本体互操作。该方法将属性值对的相似度传递到实例对上,通过迭代计算得到稳定的实例相似度矩阵,建立本体实例层的关联,而概念语义则是这种关联在机制层的表现,进一步挖掘属性的语义,修正实例相似度矩阵,优化概念语义挖掘的结果。
本文方法在OAEI2012的测试数据集上有较好的查询效果,但其基础是实例数据,并不适用于没有实例数据或实例数据较少的本体,这也是以所有概念为基数时指标不高的原因。此外,由于在实例相似度计算部分时间复杂度和空间消耗较高,本文方法对于大规模的本体适应性不强。下一步工作是研究如何将本文方法应用到大规模的本体中。
[1] Halpin H,Hayes P J,McCusker J P,et al.When owl: Sameas Isn’t the Same:An Analysis of Identity in Linked Data[C]//Proc.of ISWC’10.Berlin,Germany: Springer-Verlag,2010:305-320.
[2] Rahm E,Bernstein P A.A Survey of Approaches to Automatic Schema Matching[J].The VLDB Journal, 2001,10(4):334-350.
[3] 孙海霞,钱 庆,成 颖.基于本体的语义相似度计算方法研究综述[J].现代图书情报技术,2010,26(1): 51-56.
[4] Hertling S,Paulheim H.WikiMatch——Using Wikipedia for Ontology Matching[C]//Proc.of 2012 International Workshop on Ontology Matching.Boston,USA:[s.n.], 2012:37-38.
[5] Euzenat J,Euzenat J,Shvaiko P.Ontology Matching [M].Berlin,Germany:Springer-Verlag,2007.
[6] Parundekar R,Knoblock C A,Ambite J L.Discovering Concept Coverings in Ontologies of Linked Data Sources [C]//Proc.of ISWC’12.Berlin,Germany:Springer-Verlag,2012.
[7] Rowe M.Interlinking Distributed Social Graphs[C]// Proc.of LDOW’09.Heidelberg,Germany:Springer-Verlag,2009:461-475.
[8] Hogan A,Polleres A,Umbrich J,et al.Some Entities are More Equal than Others:Statistical Methods to Consolidate Linked Data[C]//Proc.of the 4th International Workshop on New Forms of Reasoning for the Semantic Web:Scalable and Dynamic.Heraklion, Greece:[s.n.],2010:44-58.
[9] Nguyen K,Ichise R,Le B.SLINT:A Schemaindependent Linked Data Interlinking System[C]// Proc.of 2012 International Workshop on Ontology Matching.Boston,USA:[s.n.],2012:1-12.
[10] Jeh G,Widom J.SimRank:A Measure of Structuralcontext Similarity[C]//Proc.of the 8th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.Edmonton,Canada:ACM Press,2002: 538-543.
[11] 宋亚楠,仲 茜,钟 远.基于多属性的本体实例匹配算法[J].计算机工程,2011,37(13):63-65.
[12] Niu Xin,Rong Shu,Zhang Yunlong,et al.Zhishi.Links Results for OAEI 2011[C]//Proc.of 2011 International Workshop onOntologyMatching.Bonn,Germany: [s.n.],2011:220-227.
[13] Hu Wei,Chen Jianfeng,Qu Yuzhong.A Self-training ApproachforResolvingObjectConferenceonthe Semantic Web[C]//Proc.of the 20th International Conference on World Wide Web.[S.l.]:ACM Press, 2011:87-96.
[14] Taheri A,Shamsfard M.SBUEI:Results for OAEI 2012 [C]//Proc.of 2012 International Workshop on Ontology Matching.Boston,USA:[s.n.],2012:189-196.
编辑 金胡考
Concept Semantic Mining Method Based on Instance Similarity
YOU Yan1,XU Bo-yi1,XIE Cheng2
(1.Antai College of Economic and Management,Shanghai Jiaotong University,Shanghai 200030,China;
2.School of Software,Shanghai Jiaotong University,Shanghai 200240,China)
Ontology plays an important role in knowledge expression,sharing,reuse and semantic query,but in the process of ontology integration,it is difficult to fuse the concept layer.Aiming at this paper,this paper proposes a method to find concept semantic for ontology.Based on the instance similarity metric extract from instance data,it alternates between instance level and schema level to get concept semantic,mines the property semantic,and then turns instance level to amend similarity metric and complement concept semantic on schema level.This paper tests this method with test ontologies provided by OAEI2012,and the result shows that the precise and recall ratio are increased,which proves the feasibility and effectiveness of the method
instance similarity;instance matching;concept semantic;property semantic;ontology fusion;semantic Web
1000-3428(2014)10-0219-05
A
TP18
10.3969/j.issn.1000-3428.2014.10.041
国家自然科学基金资助项目“诊疗本体自动构建方法与过程驱动的本体进化机制研究”(71171132);上海市自然科学基金资助项目“面向自演化软件服务的本体生成及进化研究”(13ZR1419800)。
游 妍(1991-),女,硕士研究生,主研方向:本体论,数据集成;徐博艺,副教授;谢 诚,博士研究生。
2013-11-11
2013-12-10E-mail:yancyyou@sjtu.edu.cn
中文引用格式:游 妍,徐博艺,谢 诚.基于实例相似度的概念语义挖掘方法[J].计算机工程,2014,40(10):219-223.
英文引用格式:You Yan,Xu Boyi,Xie Cheng.Concept Semantic Mining Method Based on Instance Similarity[J]. Computer Engineering,2014,40(10):219-223.
