基于统计分析的指令高速缓存优化技术
2014-06-07王钰博严晓浪
陈 辰,黄 凯,王钰博,严晓浪
(浙江大学超大规模集成电路设计研究所,杭州310027)
基于统计分析的指令高速缓存优化技术
陈 辰,黄 凯,王钰博,严晓浪
(浙江大学超大规模集成电路设计研究所,杭州310027)
针对现有高速缓存技术计算方法复杂、适用性差的问题,提出基于统计分析的指令高速缓存优化技术。采用GUN覆盖率分析工具和性能分析工具对代码进行静态分析,降低优化过程中的计算复杂度。在软件代码方面,通过优化的缓存块着色算法、地址段静态锁定、代码段选择性不缓存等技术,提高指令高速缓存的读取效率。给出缓存锁定选择排序公式,用于判断代码段是否锁定或不缓存,有效增加指令高速缓存的利用效率。实验结果表明,该优化技术能使程序执行时间平均减少8%,缓存命中率平均提高23%。
高速缓存;优化的缓存块着色算法;过程排序;缓存锁定;选择性不缓存;缓存锁定选择排序
中文引用格式:陈 辰,黄 凯,王钰博,等.基于统计分析的指令高速缓存优化技术[J].计算机工程,2014, 40(10):76-80,85.
英文引用格式:Chen Chen,Huang Kai,Wang Yubo,et al.Instruction High-speed Cache Optimization Techniques Based on Statistic Analysis[J].Computer Engineering,2014,40(10):76-80,85.
1 概述
随着集成电路制造工艺的进步,处理器性能快速增长。根据摩尔定律[1],处理器速度每18个月就增加一倍,而存储器性能的增长速度却远远落后。位于存储器和处理器之间的高速缓存可以有效缓解这个问题。处理器在运行中需要不断地从外部获取指令,因此,指令缓存读取命中率对处理器性能有着重大影响[2]。在嵌入式系统中,由于缓存容量较小,影响尤为显著,因此如何提高指令高速缓存的命中率,减少缓存缺失是提高系统整体性能的关键环节。
文献[3]采用拆分循环过程,避免程序循环体大小大于缓存容量,并且采取了适当压缩代码的方法进行缓存优化,这种方法能提高程序局部性及缓存命中率。文献[4]提出动态DDP排序算法,在代码段设置一个用来放置被调用的过程新代码区域,按照调用的先后次序将过程放置在新代码区域中。该方法虽然取得较好效果,但需要额外的代码储存空间。文献[5]提出一种最小化最坏执行时间的指令缓存锁定算法,通过对任务最坏执行时间的分析,选择部分函数在编译时锁定到缓存中。文献[6]提出了PH算法,该算法中的过程排序方法使用“最近最优”原则,将频繁互相调用的代码放置在临近位置,即每次选择过程调用图中调用频率最高的2个节点,将它们合并成新的节点,重复处理,直到所有过程都处理完毕。PH算法中的过程排序方法可以减少产生缓存冲突的可能性,但是没有将缓存大小、程序大小、缓存块大小考虑在内,不具备通用灵活性。缓存块着色算法[7]考虑了缓存大小、缓存块大小等架构特点,但依旧没有考虑过程的大小,在子函数大小接近或大于缓存大小时,优化效果不佳。
针对现有方法的不足,本文提出基于统计分析方法的指令高速缓存优化技术,主要创新点如下: (1)采用GUN覆盖率分析工具(gcov)[8]和GNU性能分析工具(gprof)[9]在本地平台中对程序进行静态分析,分析步骤简便、运行速度快、信息获取直观;(2)针对低性能CPU的缓存容量较小、子函数大小接近或大于缓存容量的情况,对缓存块着色算法进行优化,提出了优化的缓存块着色算法,提高了代码局部性,减少了缓存冲突缺失;(3)提出2种采用gcov信息的指令高速缓存软件优化技术,即缓存锁定和选择性不缓存技术,并提出用于计算选择锁定或不可缓存代码段的缓存锁定选择排序(Cache Locking Selection Sorting,CLSS)公式。
2 指令高速缓存优化技术
2.1 针对小容量缓存优化的过程排序
过程排序技术是指通过编译器、连接器或者其他编译工具,根据一定规则来改变代码排列次序,以提高指令高速缓存命中率的技术[10]。它通过改变代码原始排序,将频繁互相调用的代码段放置到相邻或互不冲突的地址段上,降低了他们之间发生缓存映射冲突的概率,以减少指令高速缓存的冲突缺失、提高程序局部性。
gprof工具可以产生程序运行时的统计信息,包括相函数互调用次数等。根据缓存块着色算法,使用gprof信息,构造子函数调用图对代码进行排序,如图1所示,每个节点代表一个子函数,之间的连线权值代表函数相互调用次数。
如图2所示,将整个指令存储器划分为以缓存大小为单位的区间,假设缓存大小等于4个缓存块的大小。不同区间的同种颜色的缓存块中的数据会发生缓存冲突。
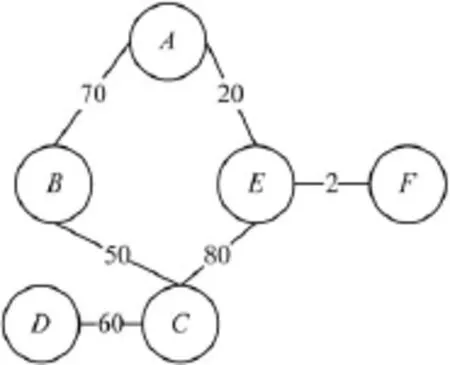
图1 原始的子函数调用过程

图2 缓存块着色算法步骤
根据反汇编Obj文件,计算出程序大小,假设子函数A,B,F的大小各占用1个缓存块,C,D各占用2个缓存块,E占用4个缓存块。
首先选取权值最大的一条边CE,但由于E的大小与缓存大小相近,不论如何放置都会和其他子函数产生冲突,因此E最后进行放置。先选取除CE外权值最大的边AB,将AB放置到图2步骤1所示位置。紧接着,选取BC。此处要保证B和C不发生冲突,所以,放置C时需要考虑B在缓存中的位置,选择与B不同的缓存块存放位置进行放置。随后,选取CD,D也需要和C处于不同的缓存块位置。之后,将调用频率最小的F插空放入序列中。最后,放入超过缓存大小的子函数E。
从图2可以看出,由于子函数E体积大于缓存容量,因此不论如何放置,均会与其他子函数产生缓存冲突。
缓存块着色算法适用于缓存大小较大、子函数均小于缓存容量的情况,但在多数低成本低性能CPU设计中,缓存容量较小,就会出现子函数大于缓存容量的情况。针对这一情况,提出了优化的缓存块着色算法,该算法将较大的子函数进行拆分。同样采用之前的程序,将较大的子函数E拆分为EA和EB,各占用2个缓存块,新的子函数调用图如图3所示。经过拆分子函数E后,可使子函数E一同进入过程排序和放置的过程,放置过程如图4所示。
对比图2和图4可以看出,图2中子函数E与C发生了缓存冲突,而它们的调用次数高达80次。在图4中,A和EA发生了缓存冲突,它们的互相调用次数仅有20次,显然效果好于优化前。采用优化的过程排序方法,能进一步细化子函数存储位置,相比原算法更加减少了缓存冲突。
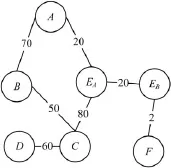
图3 优化后的函数调用过程

图4 优化后的缓存块着色算法步骤
2.2 基于gcov信息的地址段静态锁定
在程序执行过程中,可能会出现程序或某个循环的大小大于缓存的情况,这时缓存中的数据将会频繁地进行替换,当某些频繁访问的数据和其他较少访问的数据发生冲突时,若把频繁访问的数据替换出缓存将会导致更多的缺失,容量缺失成为主要制约因素,影响了程序执行性能。
为此,本文采用静态缓存锁定来干预缓存替换策略,减少不必要的缓存替换。缓存锁定机制是将某些数据锁定在缓存中,当发生缓存冲突时,被锁定的数据不会被替换,在解除锁定之前,对这些数据的访问将总是命中。
为合理选择需要锁定的地址段,以达到最大化的优化效果,提出一种通过gcov获取反馈信息来选择需要进行缓存锁定的子函数的技术。
gcov是一种代码覆盖率测试程序,可以获取程序执行的一些统计信息,主要包括:代码执行次数,分支执行次数,子函数调用返回次数,程序代码覆盖率和程序分支覆盖率。
由于地址段静态锁定的目的是为了减少容量缺失,因此需要从容量不足而造成缓存替换的情况来分析那些子函数需要进行锁定。最简单的方法就是寻找执行次数最多的子函数,对其进行锁定。但是,会出现有些子函数执行次数虽不多,但其中包含大量循环的情况,必须加以考虑,对循环执行次数多的子函数也进行锁定。因此,提出缓存锁定选择排序(Cache Locking Selection Sorting,CLSS)公式,对判断子函数是否需要锁定进行量化排序。
记某个子函数中第N个循环分支LN的执行次数为KN次,该子函数运行次数为J次,循环分支代码覆盖率为CN,子函数代码覆盖率为CALL,将这些数据带入反汇编生成的Obj文件中,即可计算出汇编代码的覆盖率CN′、CALL′,和经过编译器编译后,该子函数的汇编代码所占空间大小SALL,此循环分支的汇编代码大小SN,则此子函数执行指令总大小λ为:

设该子函数执行指令总大小与指令大小的比值为:

式(1)、式(2)主要通过子函数执行次数、循环分支执行次数、在仿真平台中编译后的代码大小及代码覆盖率来计算该子函数指令对缓存替换的影响,CLSS值越大,则说明在程序执行过程中,该子函数指令循环次数越多,执行次数越多,该代码局部性越好,需要将这些指令执行系数大的子函数进行锁定操作。根据式(1)、式(2)中的各个参数,可以计算出程序中每个子函数的CLSS值,由此可以选择CLSS值最大的子函数进行缓存锁定。
2.3 基于gcov信息的代码段选择性不缓存
与采用地址段静态锁定技术的原因一样,采用代码段选择性不缓存的原因也是为了降低由于缓存容量不足而造成的容量缺失。在指令存储器中划出一部分区域,使得储存在该区域的代码均不通过高速缓存,由CPU直接进行读取,如图5所示,通过将部分使用频率较低的代码段置于存储器的不可缓存区域,从而减少缓存不必要的替换。

图5 代码选择性不缓存的判断
根据CLSS计算对每个子函数进行排序后,选出CLSS值最小的几个子函数,即运行次数少、循环少、替换次数少的子函数,编译时在linker文件中将其放入Flash的不可缓存区域中,从而使其不进入Flash缓存进行替换。
采用此技术在提升缓存命中率上优点显著,由于总体进入缓存的代码量减少,因此缓存容量缺失及许多不必要的缓存替换大大减少,多次运行的指令高速缓存效率大幅提高,缓存命中率较大提升。
3 技术实现
采用优化的缓存块着色算法进行过程排序的流程如图6所示,获得GCC编译并反汇编后的Obj文件,就可以计算每个子函数的指令大小,对于子函数大小大于缓存容量大小的1/2的函数,对它们进行拆分,拆分成若干个较小的子函数。当所有的子函数都小于缓存容量大小的1/2后,通过gprof工具获取函数调用信息,绘制函数调用图,并用优化的缓存块着色算法进行排序和放置。最后在link文件中根据算法结果调整函数放置位置和顺序。
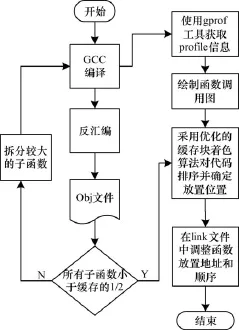
图6 采用优化缓存块着色算法的过程排序流程
采用缓存锁定或选择性不缓存技术进行过程排序的流程如图7所示,GCC编译后,通过gcov分析和反汇编文件中获取计算CLSS所需要的循环分支执行次数、子函数运行次数、汇编代码的覆盖率、经子函数的汇编代码所占空间大小、此循环分支的汇编代码大小等信息。计算CLSS后,即可选择CLSS值最大的子函数进行缓存锁定,或将CLSS值最小的子函数放置到不缓存区域中。若采用缓存锁定,则配置寄存器,将需要锁定的地址进行锁定操作。

图7 采用缓存锁定或选择性不缓存的过程排序流程
若同时使用上述3种优化技术,则需要同时进行gcov和gprof分析。如图8所示,首先进行过程排序技术中的函数拆分步骤,所有子函数大小都符合要求后,进行CLSS的计算,然后将不需要缓存的子函数剔除,剩余需要缓存的子函数进行优化的缓存块着色算法排序,最后在link文件中调整放置地址和顺序,并配置寄存器,将需要锁定的地址进行锁定操作。

图8 采用3种优化技术的过程排序流程
4 仿真结果分析
本文所采用的实验平台基于杭州中天微系统公司的CK803低成本、低功耗32位嵌入式处理器[11],采用高速缓存来加速指令Flash的访问,CPU缓存容量为512 Byte,块大小为8 Byte。指令存储器Flash选用GSMC GRA_FLS2P5M28DA[12],大小320 KB,读取位宽为32 bit。本文采用循环运行的Dhrystone、MD5加密算法、SHA1加密算法和Base64算法作为测试基准程序。
如图9、图10所示,不同优化技术对不同程序的效果不同,例如采用优化的缓存着色算法技术时, SHA1加密算法的效果最好,原因是SHA1程序中, SHA1Final与SHA1Update 2个子函数相互调用次数达到57次,而其他各子函相互调用次数均较少,如表1所示,这2个子函数的相关性远高于其他子函数,因此,这2个子函数的排序将影响程序运行效率。相比PH算法和原始的着色算法,由于本文系统采用的缓存容量较小,因此本文提出的优化的缓存块着色算法有较大的优势,在缓存命中率和程序执行速度上均有提高。而原始的缓存块着色算法相比PH算法,由于考虑了缓存块大小等相关因素,比PH算法也有所提高。
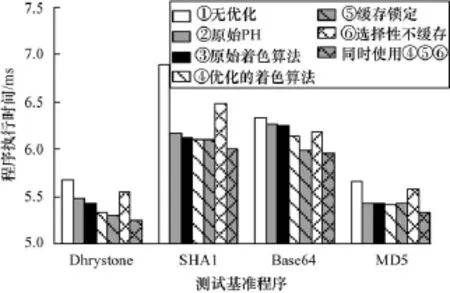
图9 程序优化前后运行时间对比

图10 程序优化前后缓存命中率对比
采用缓存锁定优化技术时,Dhrystone的效果最好,该技术针对子函数中循环大小接近或大于缓存大小的大循环时效果最好,能有效减少大循环中不断的缓存替换。在本文提出的这3种技术中,此技术对程序性能提升优化效果最好。

表1 SHA1 gprof分析结果
选择性不缓存法在提高运行效率方面效果不如前2种技术好,但在提高缓存命中率方面效果比较明显。如表2所示,在MD5程序采用此技术优化后,缓存读请求次数减少了47%,但命中数提高了16%,命中率提高了40%,主要原因是在MD5程序中,MD5 Transform子函数中的代码全都只执行一次,且无循环,此子函数代码量很大,CLSS值为1,将其存入不缓存区域后,减少了大量不必要的缓存替换。
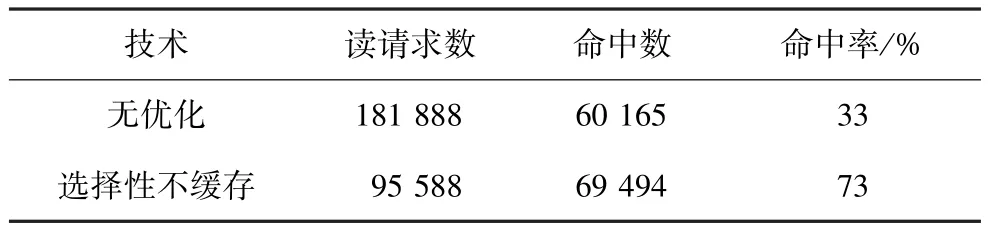
表2 MD5采用选择性不缓存时的缓存命中率对比
5 结束语
本文提出了多种指令高速缓存的优化技术,包括优化的缓存块着色算法、地址段静态锁定、代码段选择性不缓存等技术,从软件代码方面显著提高了指令高速缓存读取效率。本文还给出缓存锁定选择排序(CLSS)公式,用于选择代码段锁定或不缓存,并在CK803原型平台中加以实现。实验结果证明,采用上述优化技术可降低程序初次分析时的复杂程度,减少了优化所需的时间,并且能有效地提高指令高速缓存命中率,改善程序执行性能。每个测试基准程序在选择了优化效果最佳的一种优化方案后,可根据程序运行结果计算出:运行时间平均能减少8%,缓存命中率平均能提高23%。后续研究将针对基本块进行优化,将本文的优化技术应用到细粒度的软件优化中。
[1] Moore G E.Cramming More Components onto Integrated Circuits[J].Electronics,1965,38(8):114-117.
[2] Hennessy J L,Patterson D A.Computer Architecture:A QuantitativeApproach[M].Amsterdam,Holland: Elsevier,2012.
[3] 宋立锋,戴青云.H.264实时编码的指令Cache优化[J].电子学报,2008,36(8):1615-1619.
[4] Scales D J.EfficientDynamic Procedure Placement [Z].1998.
[5] 曾 辉.最小化最坏执行时间的指令缓存锁定算法[J].武汉大学学报:理学版,2010,56(6):697-703.
[6] Pettis K,Hansen R C,Davidson J W.Profile Guided Code Positioning[J].ACM SIGPLAN Notices,2004,39 (4):398-411.
[7] Hashemi A H,Kaeli D R,Calder B.Efficient Procedure Mapping Using CacheLineColoring[J].ACM SIGPLAN Notices,1997,32(5):171-182.
[8] Han Yiming.Application Performance Evaluation on Different Compiler Optimizations[J].Advances in Computer Science and Its Applications,2013,2(3):410-415.
[9] Mishra A,Garg K,Asati A R,et al.Hardware Software Co-design Using Profiling and Clustering[C]// Proceedings of 2012 International Conference on Communication,Information&Computing Technology.[S.l.]: IEEE Press,2012:1-4.
[10] 张定飞,赵克佳,黄 春.指令Cache优化中代码重排技术研究[J].计算机工程与应用,2006,42(7):28-30.
[11] 潘 赟.CK-CPU嵌入式系统开发教程[M].北京:科学出版社,2011.
[12] GSMC Embedded Flash IP Datasheet(ESF2-130E 320Kx8 E-Flash IP(FLS2P5M28DA))[EB/OL].(2012-05-03). http://sso.gracesemi.com/domino/servlet/GetCVSFile.
编辑 陆燕菲
Instruction High-speed Cache Optimization Techniques Based on Statistic Analysis
CHEN Chen,HUANG Kai,WANG Yu-bo,YAN Xiao-lang
(Institute of VLSI Design,Zhejiang University,Hangzhou 310027,China)
Aiming at the problem that existing cache technology has computational complexity and poor applicability, instruction cache optimization techniques based on statistic analysis by using GNU coverage analysis tool and performance analysis tools are proposed.It uses optimization techniques,including optimized cache line coloring algorithm,static use of cache locking and code selectively non-caching,can significantly improve the efficiency of instruction cache reading. Also a Cache Locking Selection Sorting(CLSS)is proposed to evaluate the code segment which can be locked or noncached.Simulations show that these techniques make the program running time reduced by 8%,and make the cache hit rate increased by 23%.
high-speed cache;optimized cache block coloring algorithm;process sorting;cache locking;selective no cache;Cache Locking Selection Sorting(CLSS)
1000-3428(2014)10-0076-05
A
TP301
10.3969/j.issn.1000-3428.2014.10.015
陈 辰(1988-),男,硕士研究生,主研方向:数字集成电路设计,缓存优化;黄 凯,副教授、博士;王钰博,硕士研究生;严晓浪,教授。
2013-11-25
2013-12-19E-mail:373144881@qq.com
