使用随机森林算法实现优质股票的选择
2014-06-05曹正凤谢邦昌
曹正凤,纪 宏.,谢邦昌
(1.首都经济贸易大学 统计学院,北京 100070;2.台湾辅仁大学 统计资讯学系,台湾 新北 24205)
使用随机森林算法实现优质股票的选择
曹正凤1,纪 宏1.,谢邦昌2
(1.首都经济贸易大学 统计学院,北京 100070;2.台湾辅仁大学 统计资讯学系,台湾 新北 24205)
文章通过比较分析价值策略和成长策略,提出了以价值成长投资策略(GARP)理念为基础的选股模型指标体系,选用了2012年1月至2013年2月间360多支股票的4406个样本数据,通过等频算法对数据进行离散化预处理后,使用随机森林算法实现了较高正确率的股票分类,投资者可以据此判断是否继续持有股票。通过分析优选后的股票在行业平均收益、最值方面的实际表现,验证了该量化选股模型性能优异。
随机森林;股票选择;股票投资;价值成长投资策略
一、问题的提出
选择优质股票是股票投资中的关键环节,是进行投资组合的重要前提。所谓优质股票是指那些成长性优异、投资回报丰厚以及抗风险能力良好的股票,这些股票的价格在市场中表现为:在熊市中,其下跌幅度低于行业平均水平;在牛市时,其上涨超过行业平均水平。所有的投资者和机构都希望投资于优质股票。然而,由于股票价格受多种因素的影响,表现出“没有规律”的随机游动特性,选择优质股票成为可望而不可及的事情。
从技术上看,股票的选取可以归结影响股票价格的多因素分析问题,其中每一个因素可以看作一个维度的指标,这样股票的价格就由多个维度的指标体系决定,从众多的股票中选取优质的股票,就归结为大量信息的统计分析,其本质是一个多维空间的分类问题。
该分类问题涉及两个方面,一是影响股票价格的维度选择,即指标体系的构建;另一个是分类算法的选择,即选择模型分类算法的确定。本文拟以价值成长投资策略(GARP)为基础,提出一种新型的综合性的选股模型指标体系,使用随机森林算法,构建量化选股模型,解决股票投资中选择优质股票的实际问题。
二、选股模型指标体系的构建
确定选股模型的指标体系,首先需要解决股票投资领域一个争论不止的问题——使用什么样的投资策略,因为投资策略使用决定了指标体系构建。
(一)两种相互对立的投资策略
1.传统的价值型投资策略。该策略倡导一种理性的投资思路和选股标准——价值投资,其思想是通过对股票基本面的分析,寻找具有更好价值因子且交易价格低于内在价值的公司,以期获得超过市场平均收益额。价值因子包括市盈率、市净率和市销率。该投资策略的代表理论有Graham的价值投资理论和Williams的投资价值理论。
2.积极的成长型投资策略。该策略倾向投资于销售收入与盈余率等成长因子高于市场平均水平、处于快速发展阶段的上市公司股票,通过其高速成长带来未来股价上涨而从中获利。成长因子指净利润增长率、ROE增长率和ROA增长率等。其代表理论有艾尔文·费雪(Irying Fisher)的资本价值理论。
(二)价值成长投资策略(GARP)[1-2]
就在人们为选择价值型还是成长型投资策略争论不休时,“股神”沃伦·巴菲特将格雷厄姆和费雪的价值投资理论彻底融合。该策略是上述两个理论的综合,其思想是挑选出从一定程度上价值被低估,同时又具有比较好的持续增长能力的潜力股。其特点是能够充分利用两者的优势,弥补单一价值投资和成长投资的不足。在股票市场发生价值与成长的风格轮动时,GARP策略可以兼顾到两个方面,所以预期可以获得比较稳定的收益。
(三)以价值成长投资策略为指导的选股模型指标体系的构建
1.影响因子构建
本模型影响因子的构建,主要参照国信证券工程师焦健等人提出的六因子量化选股模型,同时根据价值成长投资策略的思想,适当加入其他因子进行组合,使指标体系中同时包含价值因子和成长因子。
国信证券工程师焦健等人提出的六因子量化选股模型,由市净率、市盈率、ROA、前一月股票收益率、EPS一致预期变化率和EPS一致预期六个指标构建。前两个指标都是价值因子,是衡量市场及股票是否合理的常用指标,在本模型中给予保留。后四个指标体现了成长因子的概念,由于前一月股票收益率稳定性较差,予以剔除,保留ROA、EPS一致预期变化率和EPS一致预期三个指标。
这样模型共有五个指标,在一般的选股模型中都有这五个指标,或者是其线性组合。当然为了使模型的稳定性更好,加上以下四个指标:
一是净资产收益率(ROE),又称股东权益报酬率,是报告期净利润与报告期末净资产的比值。它是判断上市公司盈利能力的一项重要指标,一直受到证券市场参与各方的极大关注。如果公司净资产收益率呈上升趋势,那么肯定是企业的盈利模式发生变化,主要有以下几大因素:产品毛利上升,产品结构向高毛利发展,资产周转率上升,财务杠杆加大,而这些因素都是不能持久了,所以说净资产收益率是一个可持续高速成长企业很好的指标,这正是巴式风格最理想的投资指标。
二是存货周转率,它是衡量和评价企业购入存货、投入生产、销售收回等各环节管理状况的综合性指标。它是销货成本被平均存货所除而得到的比率,或叫存货的周转次数,用时间表示的存货周转率就是存货周转天数。存货周转率反映了企业销售效率和存货使用效率。在正常情况下,如果企业经营顺利,存货周转率越高,说明企业存货周转得越快,企业的销售能力越强,营运资金占用在存货上的金额也会越少,这也是挑选成长型股票必须具备的一个指标。
三是资产负债率,它是企业负债总额占企业资产总额的百分比。这个指标反映了在企业的全部资产中由债权人提供的资产所占比重的大小,反映了债权人向企业提供信贷资金的风险程度。由于此指标是企业偿债能力的体现,在不同的经济形势下,此比率需进行相应的调整,是企业经营策略的一种反映,体现企业管理层的财务管理能力,是企业价值因子的一个重要指标。
四是流通市值,它是公司的股票在证券市场里的交易价格乘以总股本的结果,反映了市场在某个时期对公司的看法,是公司价值的一种市场体现。一般来说流通市值是围绕公司价值上下波动的。当然这种波动是随机的,不对称的,往往受到群众的心理的影响,容易出现极端化的倾向。流通市场指标是价值投资的核心,如果市场过低低估股票市值,则该股票就是值得投资的股票。
根据以上分析,本文构建的模型指标体系如下:

表1 模型的指标体系
以上九个指标既反映了企业的营运能力、盈利能力、成长能力和市场预期,又反映了成长因子和价值因子的内容,使模型充分体现了价值成长投资策略(GARP)。
2.响应因子构建
根据价值成长投资策略的长期性特点,兼顾模型稳定性,将响应因子构建为股票前12个月的月平均涨跌幅均值的函数。其计算步骤分为三步:
首先,计算每只股票前12个月的月平均涨跌幅,使用几何平均法构建,公式如下:
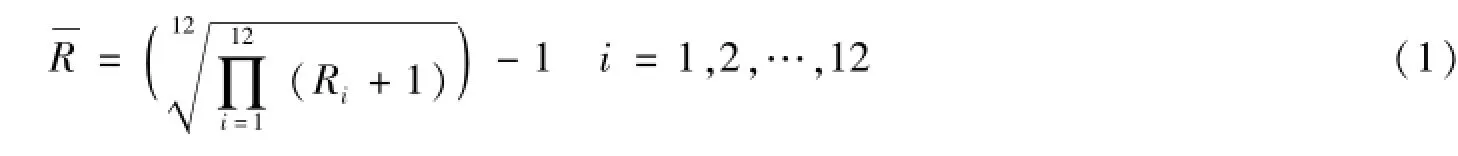
其中,Ri为该股票前第i-1个月的月涨跌幅
其次,将该行业全体股票的加权平均,计算行业前12个月的月平均涨跌幅,公式如下:

最后,将每只股票的,与全体样本平均值的比较,构建响应因子,公式如下:
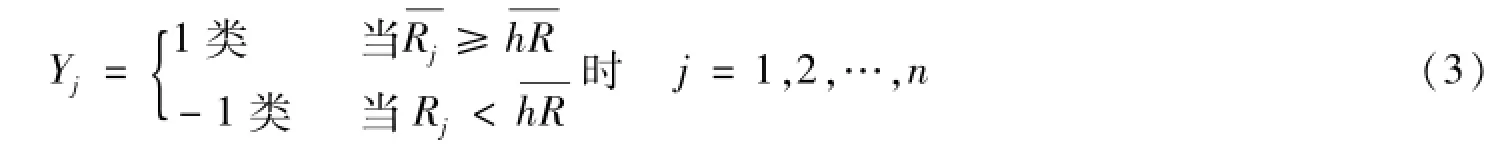
其中,为第j支股票的前12个月的平均月涨跌幅;为该行业的前12个月的月平均涨跌幅。
三、选股模型分类算法的选择
(一)已有文献选择的分类算法综述
选股问题,其本质是分类问题,因此人们在选择数量化工具进行股票选择时,纷纷选择数据挖掘工具中的分类算法进行股票选择。
1.决策树算法。在埃里奇、凯特、奇克(Eric H&Keith L&Chee K,2000)[3]的论文中,提出了EPSPrice、Price-MOM等指标构建了决策树模型,对美国科技股1993~1999年的数据进行分析,得出比较好的收益。使用他们提出的决策树方法并参考其指标,对中国国内科技股板块从2012~2013年的数据进行检验,结果表明模型在效果并不显著,原因是模型中这些指标主要为美国投资经理的经验选择,在中国市场上应用还需要一个本土化过程。
国信证券工程师焦健等(2010)[3]提在对埃里奇、凯特、奇克(Eric H&Keith L&Chee K,2000)等人提出了EPS-Price、Price-MOM等六项指标进行定义调整,提出了基于市销率、市现率,ROA变化率等适合中国股票市场的六项指标,并在此指标的基础上,使用CART决策树算法,对科技板块152只股票数据进行训练和测试,通过五分法转换和剪枝操作,得出模型预测效果显著,多头明显跑赢行业平均利润率。由于决策树算法在处理噪音数据效果较差,且容易过拟合等特点,使得模型的应用行业有一定的局限性,只能用于小盘股。
赵永进等(2005)[4]从股票分析的基本面和技术面着手,把判定树分类ID3算法应用到股票财务数据的分析上,选取有代表性的财务指标,并对样本数据进行测试,开创数据挖掘分类算法在量化选股模型在中国股票市场的先河,投资者利用测试结果可以对上市公司的经营情况和获利能力进行分析。但该文章仅仅是提供了一种分析手段,投资者不能通过模型得到诸如可否继续持有股票等指导性意见,没有达到量化选股的最终要求。
2.神经网络。张建军等(2010)[5]采用科威特第纳尔指数,通过建立一个三层(输入层、隐含层和输出层)结构的BP神经网络,对股市整体走势进行预测,成功地利用数据挖掘中神经网络技术对中国股票行情波动趋势进行研究,预测未来股市的行情走势及其波动情况,但其模型对个股的走势预测效果欠佳。
3.支持向量机。李云飞(2008)[6]在其论文中,提出基于支持向量机的股票选择模型,模型采用最小二乘法,核函数选用径向基核函数。在模型训练完成后,使用交叉验证的实证方法,实证结果支持了支持向量机模型的分类精度和泛化能力均优于传统神经网络的理论推断,但由于支持向量机算法在多分类选择时,性能显著低于随机森林算法[7],因此模型还具有提升的空间。
(二)随机森林算法介绍
随机森林(RF)[7-9]是一种组合分类器,能用于股票的分类筛选,其本质是一个树型分类器{h(x,βk),k=1,2,…}的集合。其中基分类器h(x,βk)是用CART算法构建的没有剪枝的分类决策树;x是输入向量;βk是独立同分布的随机向量,决定了单棵树(基分类器)的生长过程;输出结果采用简单多数投票法确定。基本原理如下:
1.训练集的随机选取。算法采用bootstrap抽样技术从原始训练集中抽取N个训练子集,每个训练子集的大小约为原始训练集的三分之二,每次抽样均为随机且放回抽样。
2.森林的随机构建。算法为每一个训练子集分别建立一棵决策树,生成N棵决策树从而形成“森林”,每棵决策子树任其生长,不需要剪枝处理。在每棵子树的生长过程中,并不是将全部M个属性参与节点分裂,而是随机抽取指定F(F≤M)个属性,以这F个属性上最好的分裂方式对节点进行分裂,从而达到节点分裂的随机性。
3.节点分裂。节点分裂是算法的核心步骤,每棵树的分支的生成,都是按照节点不纯度(Gini系数)最小的原则(或其他评价原则)从M个属性中选出一个属性进行分支的生长。
Gini系数指标的计算过程如下:
①计算样要的Gini系数

其中,Pi代表类别Cj在样本集S中出现的概率。
②计算每个划分的Gini系数
如果S被分隔成两个子集S1与S2,则此次划分的Gini系数为
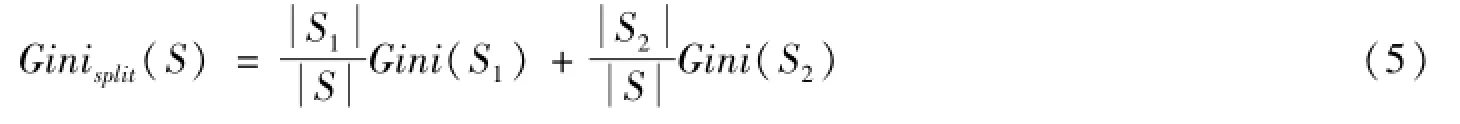
其中,|S|是样本集S的样本个数,|S1|、|S2|分别为两个子集S1与S2中样本个数。
在节点分裂时,将每个属性的所有划分按照他们Gini系数来进行排序,节点分裂时,选择Gini系数最小的属性作为分裂属性,并按照其划分实现数据的分类。
4.取多数投票得出分类结果。算法最终的输出结果采取大多数投票法实现。根据随机构建的N棵决策子树将对某测试样本进行分类,将每棵子树的结果汇总,所得票数最多的分类结果,将作为算法最终的输出结果。
(三)使用随机森林算法的优势
从上述算法介绍可以看出,随机森林算法因其训练集随机和属性随机两个随机性特点,使得算法具有很好的容错性和鲁棒性,这和当前股票市场异常情况和干扰项比较多的情况相适应;和支持向量机相比,在进行多分类选择时,随机森林算法性能显著占优[7];另外,随机森林算法具有很高的预测准确率,且不容易出现过拟合[5]。基于此三点,本文选择随机森林算法作为选股模型的量化工具,相信该算法应用到股票投资时会有不错的表现。将随机森林算法应用到此领域在国内文献中见之甚少,也属于该领域的创新。
四、实证分析
(一)样本的选择
样本选取区间为2012年1月至2013年2月,财务和股票数据来自Wind资讯,EPS数据来自朝阳永续信息技术有限公司,样本个数共计4406个,月度样本选取时,剔除了ST股和数据缺失的股票,每期股票样本范围在363支股票左右,因每个月的股票数据缺失情况不一,因此每个月的样本数据会稍有不同。
在363支股票中,有202支股票属于计算机、通信和其他电子设备制造业,另161支股票属于批发和零售业,该行业分类为2012年证监会新制定的行业分类。从实时性和可比性来说,选择2012年为起点较宜,且行业分类也更为合适。
选择这363支股票进行分析,是基于以下三点考虑:
1.进行选股时,所选股票均为同一行业,这样可以剔除行业差异,在指标选择时,可以不考虑行业因素;
2.通过两个行业的对比,有利于分析算法的普适性值;
3.所选行业的股票均超过100支,股票数量较大,有利于统计观察。其他制造业分类中,股票数量较少,不利于统计观察。
(二)指标数据的财报匹配
模型中有些指标的数据来源于上市公司的财务报告,上市公司财报公布时间如下表:

表2 上市公司财报公布时间
在进行指标计算时,月度样本数据应用的财报数据如下表:
(三)数据预处理
在上述的9个变量中,仅流通市值(MV)不是比值,因此对其进行标准化,公式为:
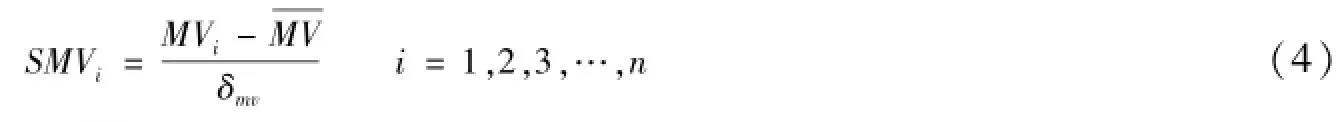
其中,MVi第i支股票的流通市值为样本股票流通市值的均值,δmv为样本股票流通市值的标准差。
由于9个变量的均为连续性变量,但随机森林算法处理变量时,需要对变量进行级别的划分,即连续变量离散化,因此需要对9个变量进行离散化处理。离散化处理方法有等宽算法、等频算法、聚类等方法。本文使用等频算法进行离散化处理,等频算法是将连续性变量的值域化分为K个小分区,K是指定的区间数目,每个变量的值用对应分区编号替代。算法的最终目标是使位于每个区间上的样本数目相等,即频数相等。
分析时发现,随着K值的变化,随机森林算法的泛化误差和准确度均发生变化,且随着K值的增大,算法性能有提升的趋势,但到一定程度后,便会下降。采用逐个K值测试、重复200多次随机实验的办法,根据数据结果发现K值为23时,算法性能最佳。因此本模型选择K值为23,对9个变量的值进行离散化处理。
(四)当月实际表现分析
在使用K值为23的数据离散化处理后,分行业对算法进行训练和预测。
1.模型在两个行业中分类正确率分析
分别使用计算机、通信和其他电子设备制造业的股票2012年1月至2013年1月2335个训练样本,和批发和零售业的股票,2012年1月至2013年1月的训练样本1708个,对随机森林进行训练,使用训练得到的随机森林分别对两个行业2013年2月股票进行分类,分类准确率如下表所示:

表4 2013年2月两行业分类正确率对比表
从上表可以看出,模型在两个行业中分类正确率均在75%以上,说明模型具有一定的普适性,当然对于行业中股票个数较少的股票,模型的正确率需要进一步的研究。从两个行业来看,分类正确率有一些差异,相差2.43个百分点,这个差异笔者认为和样本本身相关,具体原因需要进一步探讨。
2.模型分类股票在当月的实际表现分析。
以计算机、通信和其他电子设备制造业为例,2013年2月份样本股票涨跌幅如下表所示:
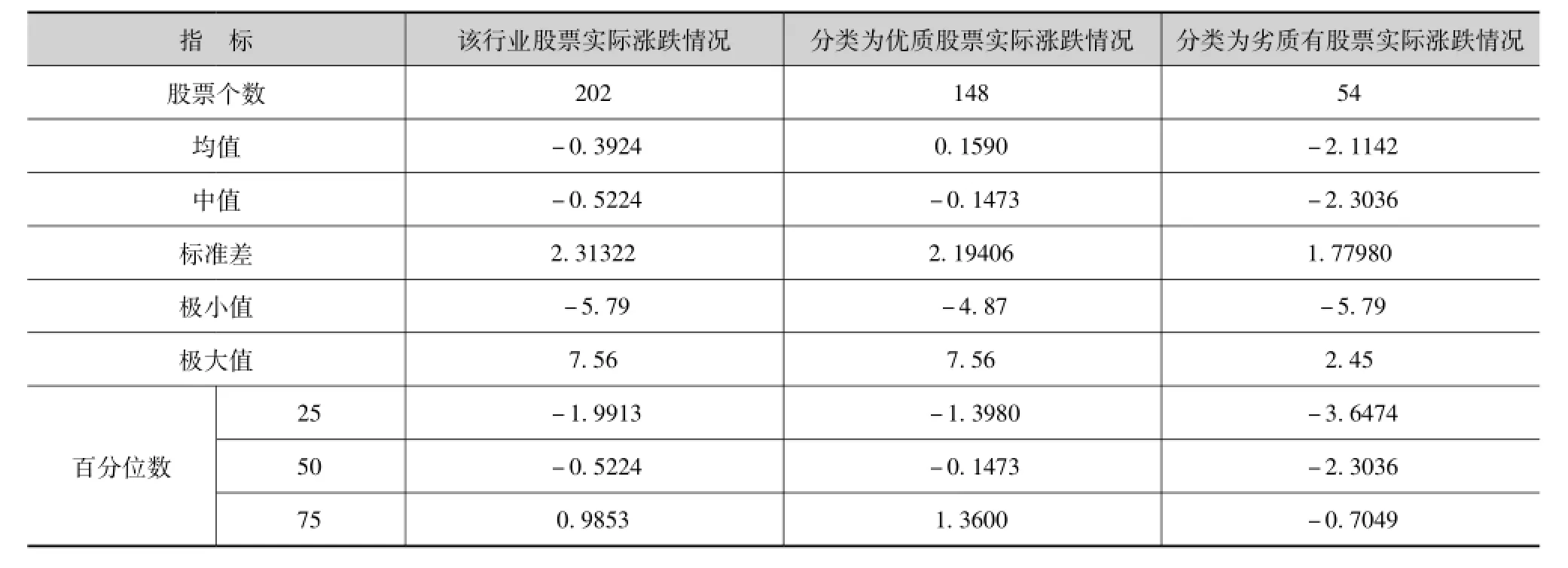
表5 2013年2月模型分类股票实际涨跌情况表
由上表可知,2013年2月计算机、通信和其他电子设备制造业行业当月平均涨跌幅为-0.3924%,整个行业下跌,分类为优质的148支股票中,当月平均涨跌幅为0.1590%,跑赢行业平均水平0.6%,且最大值也在该类股票中,最小值不在该类股票中,说明该选股模型在中国股票市场上有较好的表现。
五、结语
选择合适的数据挖掘算法进行分类选股,是量化投资的一个重要内容,使用随机森林算法进行股票选择是股票投资领域的有益探索。通过本文的研究,使随机森林算法得到更好的推广,使机构和投资人获得了一个较好的投资分析工具。当然本文在选股时,局限于某个行业,这主要是考虑到行业因素是股票选择时另一个很重要的前提条件,模型中加入行业因素和对小行业股票的分类选择是后续研究的重要内容。
[1]陈光兴,张一明.浅谈价值成长投资策略在中国股市的适用性[J].经营管理者,2010,(24):8-8.
[2]严高剑,胡浩,马坚,等.GARP投资策略——成长与价值并重[R].中信证券研究所,2008.
[3]焦健,赵学昂,葛新元.CART决策树的行业选股方法[R].深圳:国信证券经济研究所,2010.
[4]赵永进.基于数据挖掘的股票分析与预测研究[D].河南:郑州大学,2005.
[5]张建军.基于数据挖掘的股票数据分析[D].山东:中国石油大学(华东),2010.
[6]李云飞.基于人工智能方法的股票价值投资研究[D].黑龙江:哈尔滨工业大学,2008.
[7]黄衍,查伟雄.随机森林与支持向量机分类性能比较[J].北京:软件,2012,33(6):107-110.
[8]方匡南,吴见彬,朱建平,等.随机森林方法研究综述[J].统计与信息论坛,2011,3(26):32-38.
[9]Breiman L.Random Forests[J].Machine Learning,2001,45(1):5-32.
Realization of High Quality Stock Options by the Random Forest Algorithm
CAO Zheng-feng1,JIHong1,XIE Bang-chang2
(1.School of Statistics,Capital University of Economics and Business,Beijing 100070,China;2.Taiwan Furen University Consulting Department,New Taipei City 24205,Taiwan)
By comparing the analytical value strategies and growth strategies,the paper proposed the indicator system of the stock selectionmodel based on the Growth ata Reasonable Price(GARP)and selected four thousand four hundred and six samples’data ofmore than 360 stocks from January 2012 to February 2013.After the discretized preconditioning for the data through the algorithm of equivalent frequency,the paper achieved a higher accuracy of stock classification by the random forest algorithm.Investors can judge whether to continue to hold the stock.The paper validated the performance of the stock selection model by analyzing the actual performance values in the average income,the minimum and maximum values in the industry.
random forest;stock options;equity investments;value growth investment strategy
F224.9
A
1008-2700(2014)02-0021-07
(责任编辑:高立红)
2013-12-12
国家自然科学基金面上项目《基于预测建模的宏观经济时间序列结构变化研究》(项目编号71071022)
曹正凤(1979- ),男,首都经济贸易大学统计学院实验师,博士研究生,研究方向为统计理论研究;纪宏(1954- ),男,首都经济贸易大学统计学院教授,博士生导师,研究方向为统计学基础理论、宏观经济系统分析;谢邦昌(1962- ),男,台湾辅仁大学商学研究所,台湾辅仁大学教授,博士生导师,中国人民大学统计学系Data Mining中心客座教授,上海财经大学统计学系客座教授,商学研究所所长。
