面向通用计算GPU集群的任务自动分配系统
2014-06-02胡新明盛冲冲李佳佳吴百锋
胡新明,盛冲冲,李佳佳,吴百锋
面向通用计算GPU集群的任务自动分配系统
胡新明,盛冲冲,李佳佳,吴百锋
(复旦大学计算机科学技术学院,上海 201023)
当前GPU集群的主流编程模型是MPI与CUDA的松散耦合,采用这种编程模型进行编程,存在编程复杂度大、程序的可移植性差、执行效率低等问题。为此,提出一种面向通用计算GPU集群的任务自动分配系统StreamMAP。对编译器进行改造,以编译制导的方式提供集群任务的计算资源需求,通过运行时系统动态地发现、建立并维护系统资源拓扑,设计一种较为契合GPU集群应用特征的任务分配策略。实验结果表明,StreamMAP系统能降低集群应用程序的编程复杂度,使之较为高效地利用GPU集群的计算资源,且程序的可移植性和可扩展性也得到了保证。
GPU集群;异构;编程模型;任务分配;可移植性;可扩展性
1 概述
采用具有大规模并行计算能力的GPU作为异构加速设备的GPU集群在科学计算领域得到了广泛的研究和应用。文献[1]采用GPU集群作为底层运行平台来加速流计算应用。文献[2]将分子生物学中蛋白质分子场的计算程序并行化,使之能够在GPU集群上加速执行。此外,GPU集群在仿真学[3]和分子动力学[4]等领域也有大量应用实现。研究结果表明,对于具有数据密集型计算的应用,相比较于传统的计算平台,GPU集群能够提供充分的计算能力,并带来可观的性能加速比。
GPU的加入使得GPU集群呈现节点内部资源的异构化,单个节点内部不仅可以包含单核CPU、多核CPU,甚至GPU计算资源,而且包含了单GPU或者多GPU。GPU作为面向大规模数据并行计算的计算资源使得GPU集群的并行计算能力呈现多层次化。GPU集群不仅能够支持常规粒度的单程序多数据(Single Program Multiple Date, SPMD)和多程序多数据(Multiple Program Multiple Date, MPMD)计算能力,而且可以支持更细粒度的面向大规模数据的SPMD和单指令多数据(Single Instruction Multiple Data, SIMD)计算能力。GPU集群这种异构计算资源和多层次并行计算能力给并行程序设计带来了巨大的困难。
为了更好地对GPU集群这种异构计算平台[5]进行编程,学术界在编程模型方面进行了大量的研究。文献[6]和文献[7]对基于SMP体系结构的并行编程模型MPI+openMP进行了初步的探索。文献[8]对现有的消息传递系统进行了扩充,以使其能够更好地适应GPU加入集群带来的通信要求。当前主流的GPU集群编程模型是MPI+CUDA[9],这种编程模给程序员提供了一种使用异构计算资源和发挥GPU集群多层次并行的能力,但是它不能充分地契合GPU集群系统体系结构,并将由此带来编程复杂度大、程序可移植性差、执行效率低等问题。为此,本文设计并实现了面向节点异构GPU集群的任务自动分配系统StreamMAP,StreamMAP系统包含语言扩展(编译器前端)和运行时系统2个部分,以在自动且高效地将集群任务映射到计算节点的同时,降低编程复杂度并提高程序的可移植性。
2 GPU集群体系结构
在科学计算领域,GPU已经成为主流加速部件,各种不同规模的GPU集群应运而生。例如NCSA部署的2套基于Tesla s1070系列的GPU集群Lincoln[10]和AC[11]。 Lincoln有192个节点,每个节点包含2个四核CPU。每 2个节点共享1个Tesla s1070 GPU,节点之间通过SDR INFINIBAND总线进行互连。AC包含32个节点,每个节点包含2个双核CPU和1个Tesla s1070系列GPU。上述GPU集群至部署以来已经成功地完成了大量的科学计算工作,其性能、稳定性、可靠性都得到了良好的证实。
上述GPU集群计算资源不仅包含CPU还包含GPU,这样集群系统本身就是系统层面异构的。但因为每个节点的资源配置完全一致,所以集群系统在节点层面仍然是同构的。然而出于很多原因,在现实系统中的很多GPU集群都是节点异构的。
典型的GPU集群系统体系结构如图1所示。在节点异构GPU系统中,每个节点可以有一个或多个GPU,也可以没有GPU。随着CPU和GPU的发展以及集群节点扩展,新的高性能CPU和GPU加入到GPU集群中,集群的异构程度进一步加强。可以预见,在未来,节点异构GPU集群将成为高性能计算领域的主流系统。
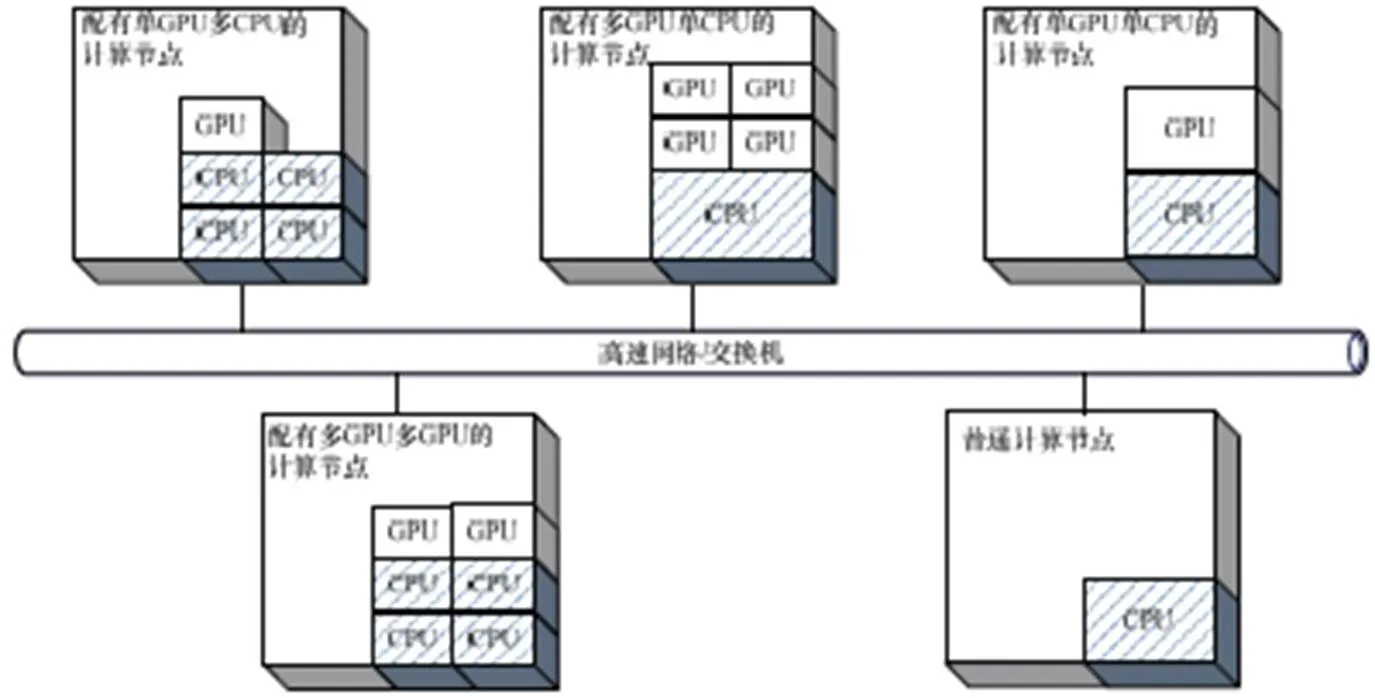
图1 GPU集群体系结构
3 MPI+CUDA编程模型
消息传递接口MPI[12]是一种标准化可移植的消息传递系统,主要用于基于分布式内存的并行计算机或集群系统。MPI是为了编写消息传递程序而开发的广泛使用的标准。通过编写配置文件可以自定义地将逻辑进程分配到具体的物理执行节点去运行。
计算统一设备架构CUDA是NVIDIA公司研发的一种针对面向通用计算GPU的并行计算架构。通过对C语言进行的扩展和限制,CUDA为GPU异构计算环境提供了一种抽象的编程模型。在这种编程模型中,GPU和CPU分别被称为device和host。CUDA程序包括2个部分,一部分在CUDA设备上执行,称之为内核(kernel),另一部分在CPU上运行,称之为主机进程(host process),两者通过GPU全局内存共享和交换数据。
当前HPC领域GPU集群的主流编程模型是MPI与CUDA的松散耦合,构成一个可行的GPU集群系统并行编程模型MPI+CUDA。
图2为MPI+CUDA编程模型系统框图,MPI主要负责进程的显示划分和进程间的通信,CUDA负责GPU面向数据级并行程序的设计和实现。
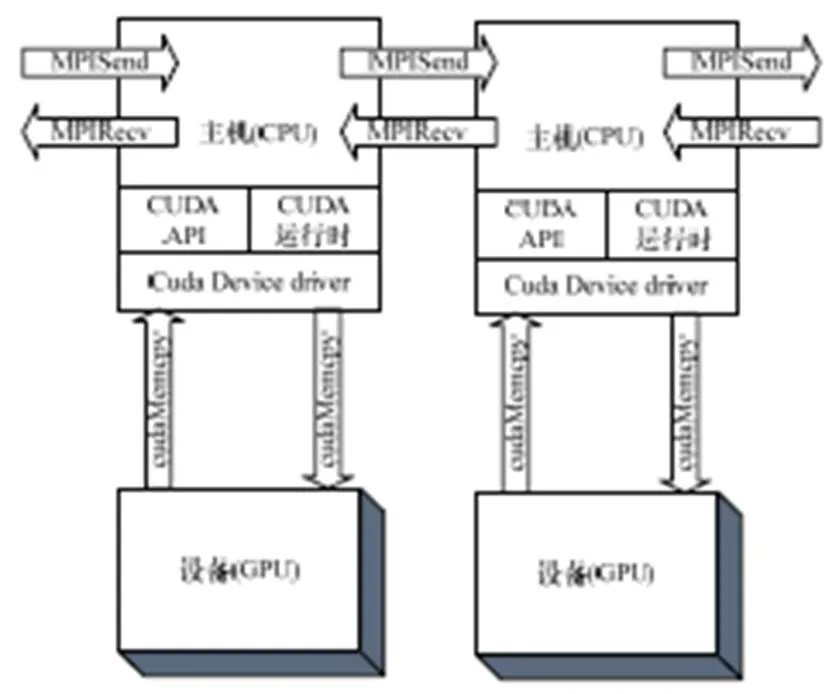
图2 MPI+CUDA编程模型
4 系统设计与实现
4.1 系统模型
采用MPI编程模型之所以会有编程难度大、可移植性差、程序执行低效等缺点,是因为尽管每个任务都有可能是一个CUDA并行程序,需要在GPU上执行,但MPI系统以一种平坦的视角对待每一个进程,即无论是纯CPU任务还是CPU-GPU任务,MPI系统并不关心每个任务的细节信息和其对于资源的需求。同样在MPI集群系统,系统中的每个节点对于MPI系统来说也是透明的,MPI并不关心这个节点的资源状况。无论是集群任务对于资源的需求还是每个节点的资源情况,对于MPI运行时系统都是透明的,即无法进行自动高效的任务分配。
通过提供编译制导指令和运行时系统,StreamMAP系统很好地解决了MPI系统的这2个盲点。StreamMAP系统模型如图3所示。
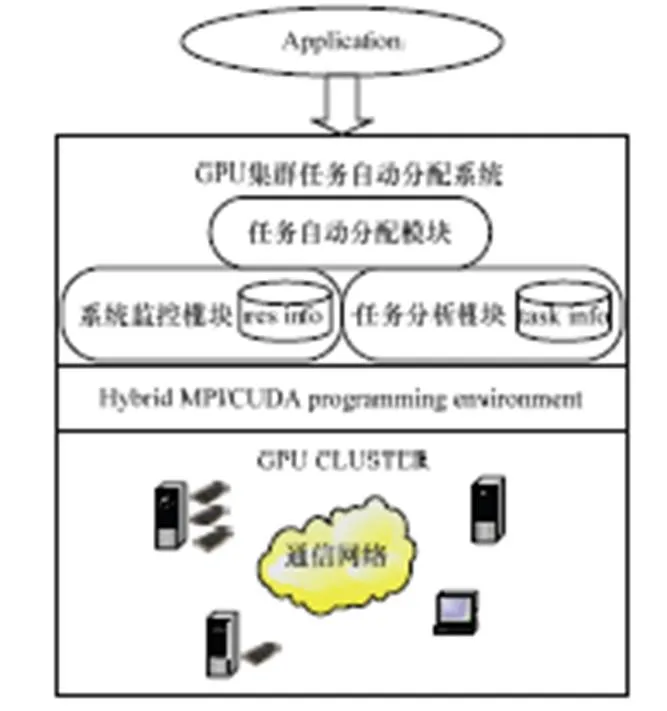
图3 StreamMAP系统模型
StreamMAP对于传统的并行编程模型进行了2个层面的扩展:
(1)通过对C语言编译器进行扩展,向应用程序员提供编译制导指令。通过编译制导的方式,程序员可以在程序中显示地表达任务的计算资源需求。StreamMAP系统提供一个编译器前端对编译制导指令进行解析。使用编译制导的好处在于,即使在原始编译器环境下,程序仍然可以正确地编译执行。
(2)StreamMAP运行时系统完成系统资源的自动发现,建立并维护系统资源数据库,并根据集群任务的资源需求,进行有效的任务分配,最终通过生成MPI执行配置文件,完成集群任务到计算节点的映射。
4.2 设计目标
StreamMAP的目的是为各种不同的GPU集群体系结构提供一个通用的、高效的编程环境。系统的设计与实现主要考虑了如下方面:
(1)可编程性:应用程序员只需要设计逻辑上任务划 分和进程间通信的关系,而任务的具体运行位置则由StreamMAP系统自动完成。这样应用程序员无需了解底层的体系结构细节,就实现了逻辑设计与物理运行的分离。这种系统结构层面的抽象简化了程序员编程的难度。
(2)可移植性:StreamMAP系统自动完成集群系统资源的发现与分配,应用程序员无需了解底层节点资源状况。当集群节点资源拓扑结构发生变化时,应用程序无需做任何修改即可在新的环境中正确、高效地运行。
(3)高效性:StreamMAP系统采用有效的任务分配策略,使得对于计算资源需求不同的逻辑进程能够高效地映射到异构的物理节点上,保证了集群系统计算能力得到最大程度的利用。
(4)可扩展性:集群平台环境对于程序员来说是透明的,系统资源的发现和任务的分配都由StreamMAP系统自动完成,这使得其在应用程序是高度可扩展的。
4.3 系统实现
如图3的系统模型所示,StreamMAP包含任务分析模块、系统监控模块和任务自动分配模块3个部分。
(1)编译制导是一种通过对编译器进行改造,提供对某些自定义编译指令的支持以实现某种自定义条件编译的技术。在正式编译开始之前,编译指令指示编译器完成某项工作(通常是预处理工作)。编译指令的解析需要编译器的支持,但如果采用原始的编译器进行编译,将会忽略编译伪指令,也可以完成编译工作。openMP、openACC[13]等并行编程技术都采用编译制导的方式对传统的串行程序语言进行了相应的扩展,使之能够支持并行程序的设计与实现。StreamMAP任务分析模块通过提供编译器前端解析程序员提供的编译制导信息,分析并存储所有集群任务的计算资源需求状况。StreamMAP系统编译制导指令格式为:#pragma streamap directive [clause[[,]clause]…] new-line。当前实现的资源指令语法格式为:#pragma streamap resource [tasknum:res[[,]tasknum:res]…] new-line。资源指令表达了集群任务对于资源的需求状况,其中,tasknum为任务编号,对应于MPI+CUDA编程模型中的进程编号;res可以是 C/c,表示任务为纯CPU任务(不需要GPU加速设备的支持),也可以是G/g,表示任务中含有大规模并行的cuda kernel程序,需要在GPU设备上运行。为便于使用,任务分析指令的解析支持正则表达式实现。
(2)StreamMAP系统监控模块包含一个控制节点和多个计算节点,控制节点本身也可以是计算节点,并作为进行任务分配的单位。在StreamMAP系统启动和更新期间,控制节点向所有计算节点发送资源发现请求消息,每个计算节点中运行StreamMAP的资源发现模块,通过相关操作系统调用和一系列GPU设备查询例程获取本节点资源信息并反馈给控制节点,由控制节点存储并更新所有集群节点的各种资源信息。StreamMAP运行时系统基于MPI消息传递系统,完成对所有集群节点的轮询,记录并维护所有节点反馈的系统资源信息,包括CPU资源、GPU资源、系统通信拓扑等。
图4为基于StreamMAP系统的逻辑结构和软硬件层次模型。其中,控制节点基于MPI scatter模式向各个计算节点发送资源的发现请求消息,在每个计算节点的内部StreamMAP运行时系统完成CPU、GPU、通信拓扑等系统资源的发现。然后所有的这些资源信息以MPI reduce模式聚集到控制节点,控制节点以此建立并维护系统资源数 据库。
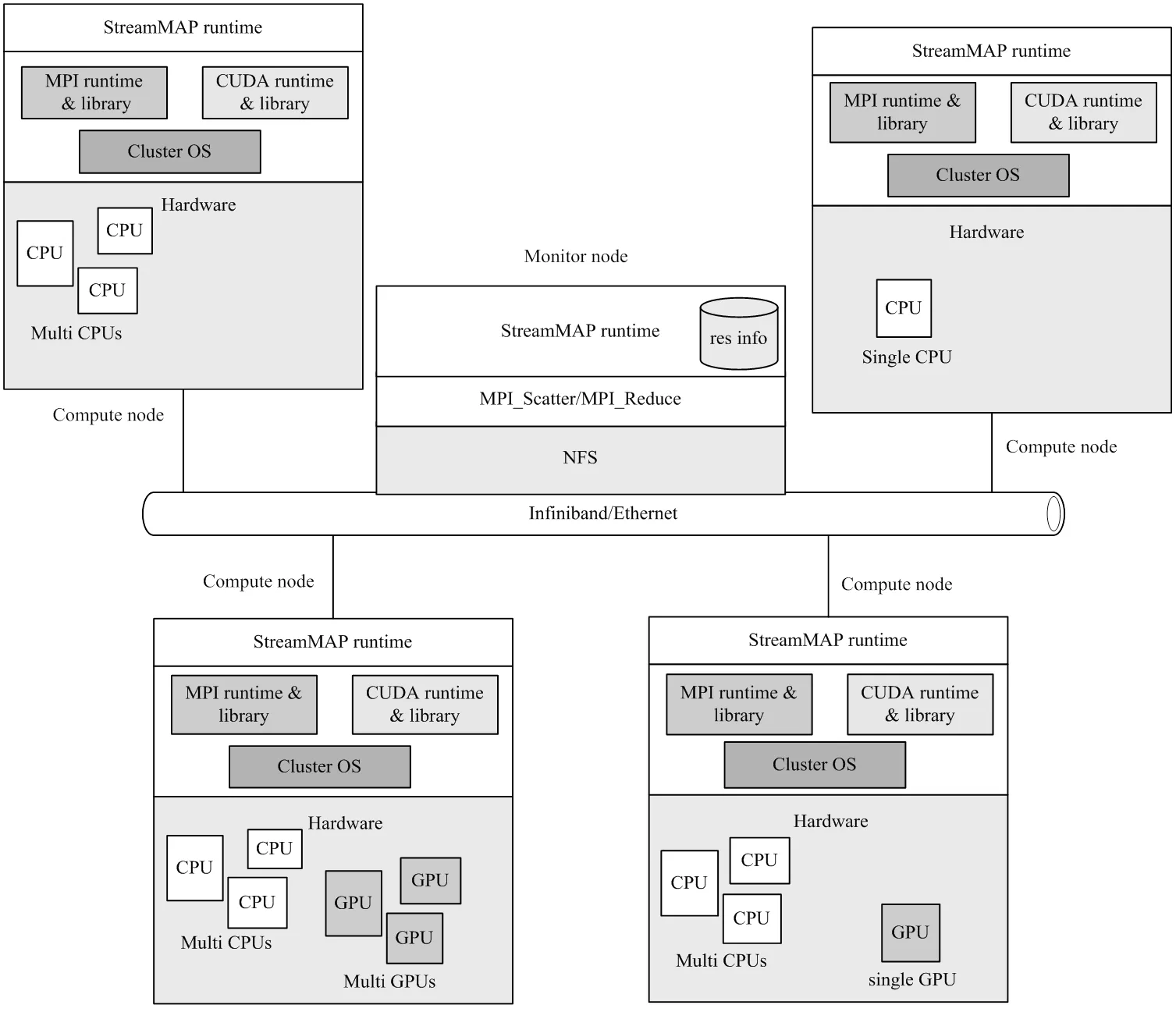
图4 StreamMAP运行时系统
(3)在完成任务资源需求分析和系统资源发现的基础上,StreamMAP运行时系统中的任务分配模块自动地完成集群任务到物理计算节点的映射。现实中大量的集群应用存在广泛的差异性,一种单一的任务划分方式或是任务分配算法很难保证具体的应用能够最高效地在集群环境中运行。为了满足集群任务的资源需求并兼顾系统的负载均衡状况,同时保证系统的通用性,本文采用了较为简单和典型的Round-Robin资源轮询算法,并有差异性地区分GPU和CPU计算资源。即相比较于CPU能支持多任务并发和抢占执行等机制,本文系统将GPU视为不可抢占资源,并因此在任务分配时优先考虑分配CPU-GPU类任务,以满足此类任务的资源需求。即在第1次分配中只考虑CPU-GPU类任务,选择具有GPU加速器的计算节点并考虑这类节点的负载情况,并将任务分配到负载较小的节点。第2次分配时,所有需要在GPU设备上执行的任务已经分配完毕,这时仅需要考虑纯CPU类任务和所有计算节点,具体分配算法和CPU-GPU类任务的分配相同。
5 实验结果与分析
5.1 实验环境
在本文实验中,现实系统是系统和节点层面异构的GPU集群DISPAR,集群平台包括4个节点,系统拓扑结构如图5所示,node0、node1主机为DELL T410服务器,分别包含XEON 5606四核CPU以及内置的1个NVIDIA C2075 GPU。node2、node3是2台DELL T5600工作站,内置双核CPU。考虑到设备成本较大,而且本文实验重点验证StreamMAP系统所实现的任务分析、系统监控和任务自动分配等功能性目标,并不追求极致的计算和通信速度,DISPAR集群系统没有采用相当于万兆以太网的高速互联设备INFINIBAND,而是采用1 000M以太网代替。
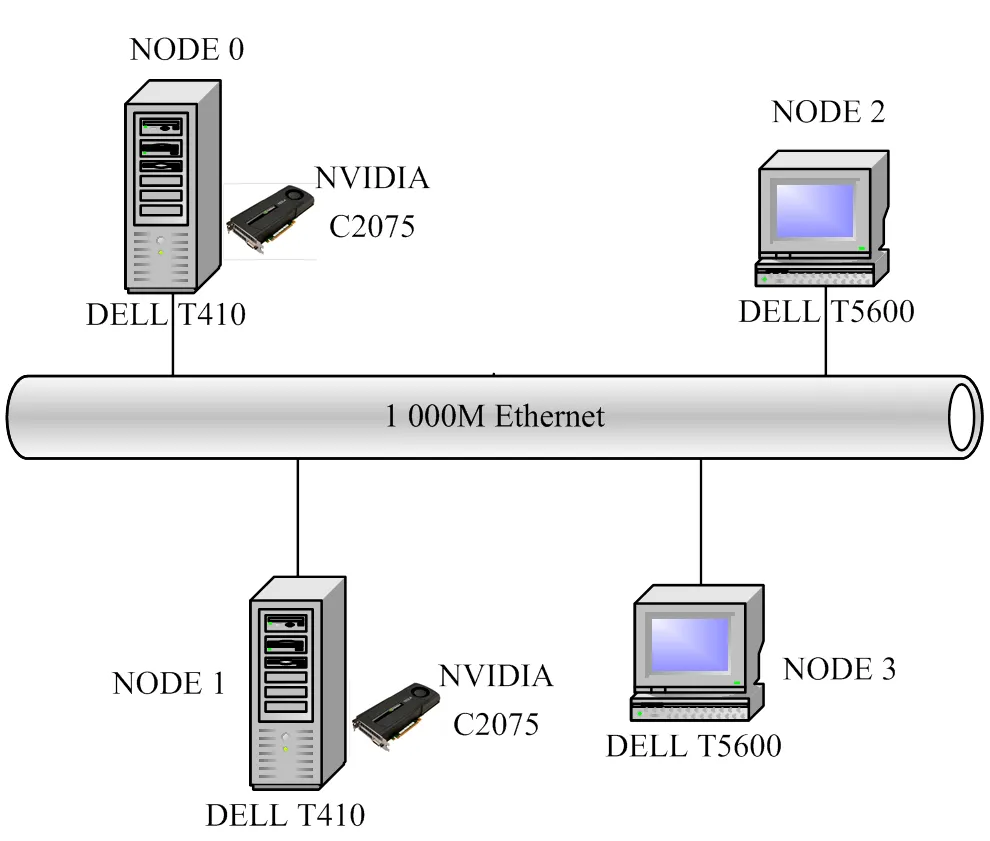
图5 DISPAR集群拓扑结构
所有节点运行64位ubuntu 10.04 LTS操作系统,MPI选择支持多种体系结构的MPICH2开源实现。NVIDIA driver版本是285.05.33,CUDA Toolkt版本为4.1,CUDA SDK版本为4.1,用于开发的GCC的版本是4.4.3。
实验采用的集群应用样例程flowComput共包含12个任务,其中,task0~task7为纯CPU任务;task8~task11为CPU-GPU任务。
5.2 结果分析
图6是通过StreamMAP系统最终生成的flowCompute执行配置文件,配置文件的前2列是待执行集群任务的数目,中间2列表示这些任务执行的具体集群节点,最后 1列这是集群应用的执行程序和数据映像。因为在配置文件格式中,任务的编号默认是按照行的顺序进行递增,所以这实际上是建立了集群任务到计算节点的一个映射。如图6所示,第1列表示将task0分配在node0上执行,第2列表示将task1在分配node1上执行,以此类推。
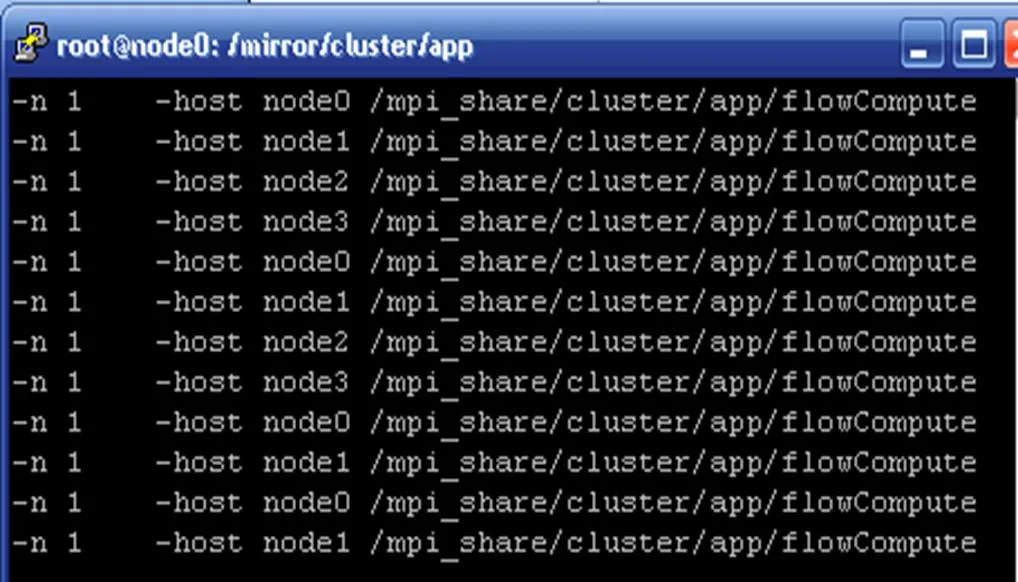
图6 MPI执行配置文件
表1为本文实验中MPI和StreamMAP这2种调度方案的任务分配结果,可见MPI采用了一种简单的随机分配方案,任务按照编号依次地分配到各个节点。其中,MPI运行时调度系统忽略了任务10、任务11对于GPU计算资源的需求,而将这2个具有大规模数据并行的任务分别分配到没有配备GPU加速器的普通计算节点2和节点3。在采用MPI+CUDA,乃至其他包含异构GPU内核程序的主流GPU集群编程模型中,这种分配方案使得集群应用无法在异构GPU集群平台上正确地运行。而采用StreamMAP的分配方案中,4个CPU-GPU类任务task8~task11分别被分配到具有并行计算能力的GPU节点node0和node1,而纯CPU任务task0~task7则被均匀地分配到集群中的各个节点。所有任务的计算资源需求都得到了满足,因此相比之下,streamMAP更能够契合GPU集群的体系结构特征。
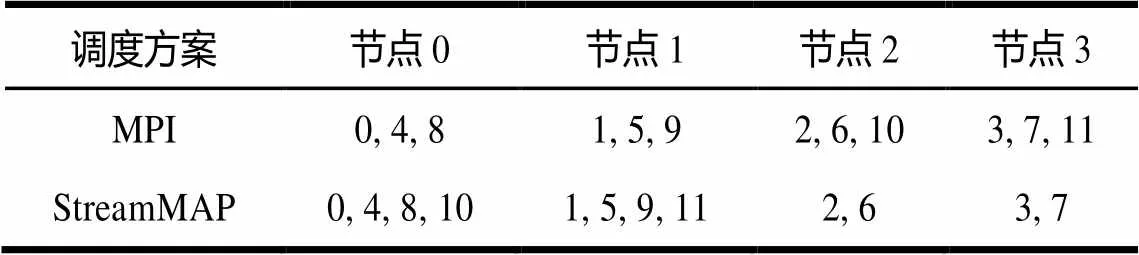
表1 2种方案任务的分配结果
为了能够对MPI运行时调度方案和StreamMAP调度方案进行性能比较,首先需要使得采用MPI运行时系统的集群应用程序能够在GPU集群上正确运行,为此使用openACC跨平台编译制导指令对本文实验中所用到的集群应用进行重写。使用OpenACC编译制导指令的好处在于,如果一个具有大规模数据并行性的CPU-GPU任务没有获得其执行所需要的GPU计算资源,就会通过相应的回滚(fallback)操作在CPU处理器上执行。
表2是上述2种调度方案的运行时间开销。可以看出,在MPI运行时调度方案中,节点2和节点3因为没有配备GPU计算资源,所以其上运行的task10、task11必须通过回滚操作在CPU上运行,这大大地增加了运行时间开销。而采用StreamMAP调度方案的各个节点的负载更加均衡,没有明显的性能瓶颈。在本文实验中,采用StreamMAP调度方案带来了约26x的整体性能提升。
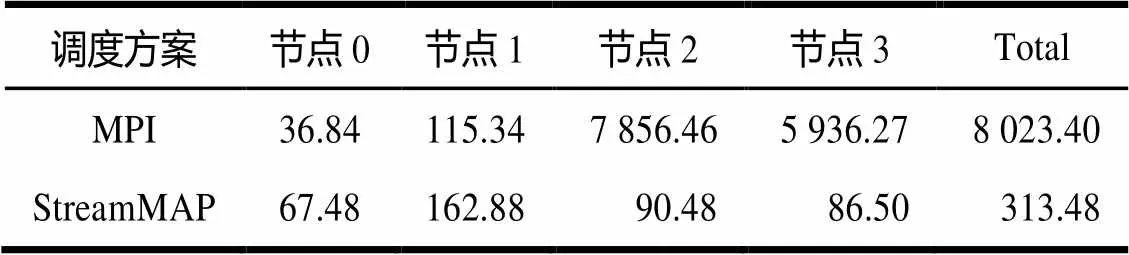
表2 2种方案运行时间开销的对比 s
上述所有工作都是由StremMAP系统自动完成的,程序员无需了解底层GPU集群体系结构的细节,降低了集群程序设计者的编程负担,同时这样的程序也具有广泛的可移植性和可扩展性。
6 结束语
本文设计并实现了StreamMAP系统,从预编译和运行时2个层面对现有的集群编程模型hybrid MPI/CUDA进行了改进,使之能够较好地契合GPU集群体系结构特征。与传统的hybrid MPI/CUDA编程模型相比,StreamMAP系统有效地降低了集群应用程序的编程复杂度,并保证了程序的可移植性和可扩展性。此外,StreamMAP提供了一个系统性的框架,开发者可以在此基础上设计针对于具体集群应用特征的任务划分方式和分配算法,这也是后续工作的重点。
[1] Jacobsen D A, Thibault J C, Senocak I. An MPI-CUDA Implementation for Massively Parallel Incompressible Flow Computations on Multi-GPU Clusters[C]//Proc. of the 48th AIAA Aerospace Sciences Meeting and Exhibit. Orlando, USA: [s. n.], 2010: 1065-1072.
[2] 张 繁, 王章野, 姚 建, 等. 应用GPU集群加速计算蛋白质分子场[J]. 计算机辅助设计与图形学学报, 2010, 22(3): 412-419.
[3] 龙桂华, 赵宇波. 三维交错网格有限差分地震波模拟的GPU集群实现[J]. 地球物理学进展, 2011, 26(6): 1938-1949.
[4] 苏丽丽. 基于CPU-GPU集群的分子动力学并行计算研 究[D]. 大连: 大连理工大学, 2009.
[5] 朱晓敏, 陆配忠. 异构集群系统中安全关键实时应用调度研究[J]. 计算机学报, 2010, 33(12): 2364-2377.
[6] 陈 勇, 陈国良, 李春生, 等. SMP机群混合编程模型研究[J]. 小型微型计算机系统, 2004, 25(10): 1763-1767.
[7] 王惠春, 朱定局, 曹学年, 等. 基于SMP集群的混合并行编程模型研究[J]. 计算机工程, 2009, 35(3): 271-273.
[8] Phillips J C, Stone J E, Schulten K. Adapting a Message- driven Parallel Application to GPU-accelerated Clusters[C]// Proc. of ACM/IEEE Conference on Supercomputing. Piscataway, USA: IEEE Press, 2008: 81-89.
[9] 许彦芹,陈庆奎. 基于SMP集群的MPI+CUDA模型的研究与实现[J]. 计算机工程与设计, 2010, 31(15): 3408-3412.
[10]University of Illinois at Urbana-Champaign. Accelerator Cluster Webpage[EB/OL]. [2013-03-12]. http://iacat.illinois. edu/resources/cluster/.
[11] National Center for Supercomputing Applications. Intel 64 Tesla Linux Cluster Lincoln Webpage[EB/OL]. [2013-03-18]. http://www.ncsa.illinois.edu/UserInfo/Resources/Hardware/Intel64TeslaCluster/.
[12] Message Passing Interface Forum. MPI: A Message-passing Interface Standard[EB/OL]. [2013-02-10]. http://www.mcs.anl. gov/rresearch/projects/mpi/.
[13] OpenACC Forum. OpenACC.1.0.pdf[EB/OL]. [2013-02-20]. http://openacc.org/Downloads.
编辑 任吉慧
Automatic Task Assignment System of General Computing Oriented GPU Cluster
HU Xin-ming, SHENG Chong-chong, LI Jia-jia, WU Bai-feng
(School of Computer Science,Fudan University, Shanghai 201203, China)
MPI+CUDA are the mainstream programming models of current GPU cluster architecture. However, by using such a low level programming model, programmers require detailed knowledge of the underlying architecture, which exerts a heavy burden. Besides, the program is less portability and inefficient. This paper proposes StreamMAP, an automatic task assignment system on GPU clusters. It provides powerful, yet concise language extension suitable to describe the compute resource demands of cluster tasks. It develops a run time system to maintain resource information, and supplies an automatic task assignment for GPU cluster. Experiments show that StreamMAP provides programmability, portability and scalability for GPU cluster application.
GPU cluster; heterogeneous; programming model; task assignment; portability; scalability
1000-3428(2014)03-0103-05
A
N945
胡新明(1989-),男,硕士研究生,主研方向:面向GPU的大规模并行计算;盛冲冲、李佳佳,硕士研究生;吴百锋,教授。
2013-02-27
2013-04-18 E-mail:10210240001@fudan.edu.cn
10.3969/j.issn.1000-3428.2014.03.021
