基于统一计算设备架构的干涉成像光谱快速反演技术研究
2014-06-01高教波孟合民张茗璇
李 宇,高教波,孟合民,张 磊,张茗璇
(西安应用光学研究所,陕西 西安710065)
引言
成像光谱技术由于其不仅具有二维空间信息,还能获取目标的光谱维信息,对目标识别有着极其重要的作用,因此近年来受到了各研究机构的重视,文献[1]研究得出了针对高光谱数据的快速重建技术,CUDA并行架构非常适合于处理高光谱原始数据[1-2],针对成像光谱技术而发展起来的系统分析、设备装置研发、数据处理算法也不断跟进。成像光谱技术已经在很多领域取得了较为成熟的应用,如区域制图、环境监测、农业遥感、公共安全等[3]。
时空调制型干涉光谱成像系统,相对于传统的空间调制型和光栅分光型光谱成像系统具有高通量的优势,适合对微弱光谱辐射信号的探测,在气体检测方面具有一定的优势。针对大部分气体在长波红外波段都有其独特的吸收峰的特征,我们设计并研制了时空调制型长波红外干涉成像光谱系统,用于对气体成分的检测。由于气体检测属于实时性要求较高的应用场合,这就需要从推扫成像到最终的数据解算结果要有很高的处理效率,但是受干涉成像光谱的原理限制,采用传统的CPU串行处理方法完全不能达到性能的要求。为此,利用CUDA平台实现干涉光谱数据并行处理的研究,并取得了一定的成效,实验结果表明,采用GPU作为协处理器实现并行处理,比仅使用CPU作串行计算在计算效率上有了5到20倍的提升。
1 时空混合调制型干涉成像原理
自主研制的时空混合调制型长波红外干涉成像光谱仪基于分体式Sagnac干涉仪,样机工作波段为8μm~12μm。
1.1 系统装置
分体式Sagnac干涉仪采用三角共光路结构,依靠反射镜的非对称布置及分光镜对光线的偏折作用产生横向剪切量,分光干涉原理如图1所示[4]。图中,光学系统由分光干涉仪、长波红外成像物镜及热像仪组成,分光干涉原理如下:
1)远处物点的平行光入射分光干涉仪,分为2束,2束光以一定横向剪切量平行出射;
2)2束光经过成像物镜在焦平面FPA上合束并干涉;
3)干涉光谱成像系统相对目标运动,物点平行光进入干涉系统角度不同,获取不同光程差的干涉信息;
4)干涉条纹经傅里叶逆变换,反演出目标辐射的光谱信息[5]。
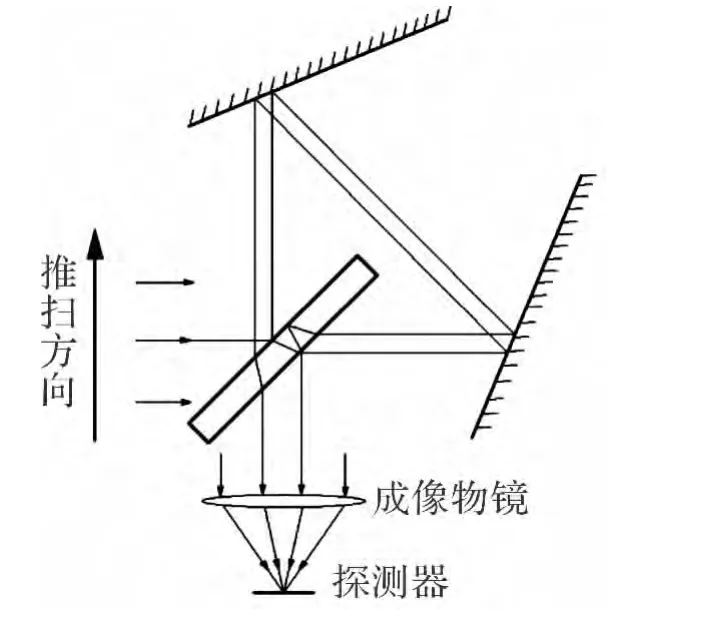
图1 Sagnac干涉光谱成像仪Fig.1 Sagnac interferometer
1.2 干涉图获取模式
时空混合调制型干涉光谱仪获取干涉图的模式与其他干涉光谱仪有所区别,由于Sagnac采用前置光学系统,每次进入视场的是当前区域范围内的所有目标像元,而且每个目标像元在当前帧上只有一个干涉数据点信息,要获取单个目标像元的完整干涉信息,就需要按照一定的规律,从不同的CCD帧中取得该像元的所有干涉信息后组合起来。被测目标像元相对于仪器的入射角不断变化,产生不断变化的光程差,从而形成一系列干涉图像。所以这就要求仪器和被测目标之间必须是相对匀速运动,同时满足采样定理,方可获得被测目标均匀的干涉数据[6]。
2 CUDA架构
图形处理单元(graphic process unit,GPU)由于其众核设计理念,使得它在浮点运算能力上远超过CPU,因此非常适合数据密集型的复杂计算任务。到2009年,GPU浮点运算的执行速度可以达到1×1012次/s(1teraflops),而此时的多核CPU执行速度仅是1×1011次/s,二者在峰值浮点运算的吞吐量方面比率达到了10∶1,而这还仅仅是芯片中执行资源可以支持的原始速度,不一定是应用程序在运行时能够达到的最高速度[7]。
统一计算设备架构(compute unified device architecture,CUDA)的出现,综合了CPU的逻辑控制能力和GPU的数据密集型并行计算能力,并且使用对C语言的简单扩展CUDA C作为编程语言,使得并行程序开发变得相对容易[8]。在本研究中,我们采用CUDA架构实现干涉数据的反演处理来解决处理效率的问题。
2.1 CUDA并行原理
在CUDA中使用的是单指令多线程(SIMT)计算模型,即同一条指令可以处理多个数据对象。这相当于使得用户对程序有着线程级的控制,通过跳转和分支,每个线程可以有独立的、不同的行为,并且在GPU中线程是轻量级的,即其创建、切换和销毁所耗费的时间可以忽略不计。CUDA使用一种分层的编程模型来组织线程:用户根据需要定制一定数量的线程准备投入计算,并可以定制线程和数据的映射关系。
一个支持CUDA的GPU中至少包含一个流多处理器(SM),每个SM包含若干个标量处理器(SP)。在实际运行中,控制器将一个线程组分配给一个SM后,SM中的SP协同工作,并行处理所有的线程。
2.2 算法设计
时空混合调制型光谱成像系统,光谱特征信息以干涉条纹的形式叠加在景物所成的像上。从双边干涉图像到光谱信息的光谱反演过程需要经过以下步骤:
1)提取重排
同一物点以不同光程差干涉成像于各帧图像的不同位置,因此需先将该物点的干涉强度信息从各帧图像中提取出来,按照光程差顺序重新排列。
2)基线校正
由于视场渐晕的影响,图像边缘的干涉条纹强度有所降低,为正确反演光谱,需对干涉条纹进行基线校正处理以修正趋势项及减去直流分量。
3)切趾
理想傅里叶变换的积分上下限是光程差从负无穷大到正无穷大,而实际仪器中的干涉图函数在光程差达到最大值处截止,这使得仪器谱线函数变宽,反演光谱峰值周围出现较强的“旁瓣”,掩盖了波峰旁边的弱光谱信息,造成分辨光谱的困难。这个“旁瓣”出现的物理根源在于最大光程差附近干涉图尖锐的不连续性,消除或抑制这些“旁瓣”的基本方法就是用一渐变权重函数来乘干涉图,即通常所说的“切趾”的方法进行数学滤波,以缓和这种不连续性[9]。对条纹进行切趾处理能有效降低旁瓣,但会使光谱展宽,不同的切趾函数有不同的特性[10]。
4)傅里叶逆变换
以提取重排、基线校正和切趾处理后的干涉条纹作傅里叶逆变换,设定采样频率,确定反演光谱的位置。利用传统的CPU处理模式[11],其计算流程如图2所示。
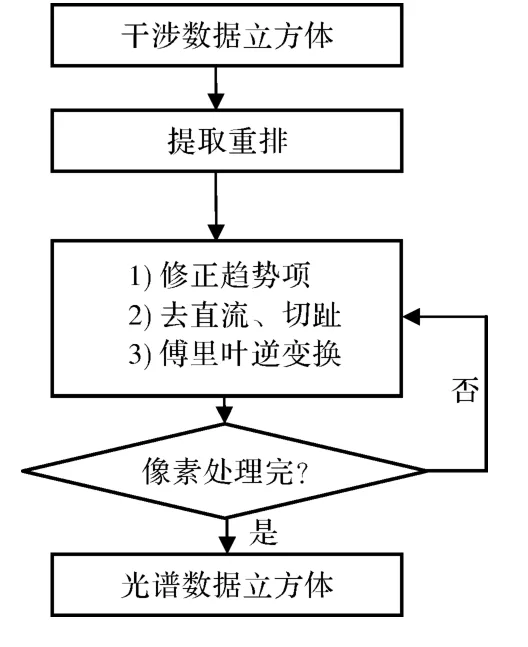
图2 传统CPU处理流程Fig.2 Processing procedure using traditional CPU
而对于每个空间像元来说,其所需要的处理都是上述的相同步骤,因此各像元之间独立、可并行的特点非常适合使用CUDA实现,在本研究中基于CUDA架构的干涉光谱反演并行算法对获取的干涉图进行处理,处理流程如图3所示。
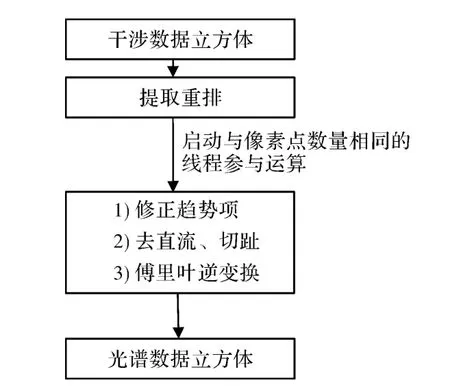
图3 采用CUDA架构的处理流程Fig.3 Procedure using CUDA
3 实验结果及分析
文中采用的实验数据来自于自研干涉成像光谱仪采集的干涉数据,探测器视场大小为640×480像元,采用12bit量化,数据处理采用三角窗切趾和256点傅里叶变换。针对同样的算法分别实现了CPU的串行计算版本和CUDA架构的并行计算版本,并对比两者的计算效率以及计算结果的正确性。
本实验采用的运行环境是:
操作系统:Windows 7旗舰版64位SP1。
处理器:Intel Xeon X5690@3.47GHz六核。
内存:8GB
显卡:Nvidia Quadro 4000,显存大小为4GB,CUDA计算能力为2.0,CUDA驱动版本为5.0。
开发编译环境:Microsoft Visual Studio 2008 SP1+NVIDIA CUDA编译器NVCC。
实验针对黑体经单色仪出射10μm单色光进行推扫,数据处理过程中各步骤的结果见图4~图7。图4所示是对采集到的数据进行重排以后,在黑体表面选取的一个像素点的完整干涉序列,我们将所有像素点干涉序列组成的干涉立方体数据送至显存,由GPU进行并行计算的任务。图5所示是为了校正视场渐晕而导致的边缘能量畸变,将图4中弯曲的谱线拉平。图6是去直流及采用三角窗切趾得到的曲线。图7是CUDA针对图4中选取的干涉序列最终得到的反演结果,我们没有采用CUDA自带的cufft库,而是在核函数中实现了频域两点IFFT算法,计算结果只进行了波长定标,而未作辐射定标。图8是在CUDA中利用OpenGL渲染出的可视化结果,可以看到单色光的空间分布范围很明显。
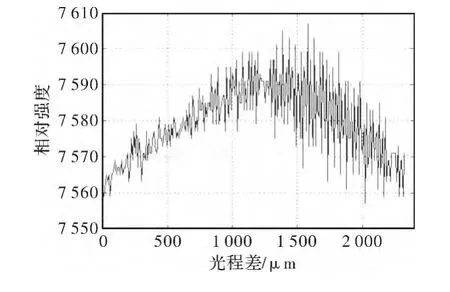
图4 10μm单色光原始采集干涉序列Fig.4 Original data sequence of 10μm homogeneous light
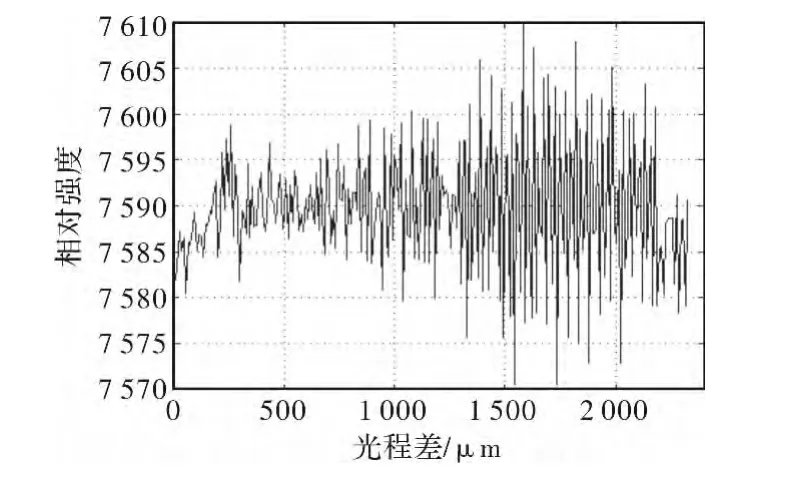
图5 CUDA消除趋势项Fig.5 Eliminating tendency using CUDA
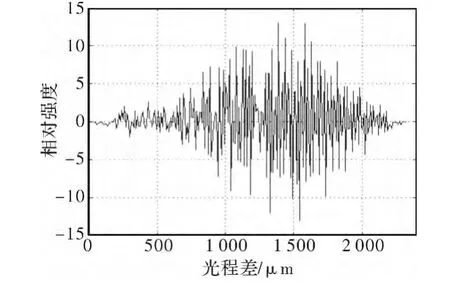
图6 CUDA三角切趾Fig.6 Triangle apodization using CUDA
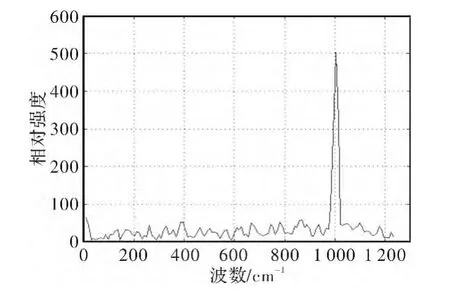
图7 10μm单色光CUDA反演结果Fig.7 Inversion result of 10μm homogeneous light using CUDA

图8 10μm单色光反演结果显示Fig.8 Inversion result visualization of 10μm homogeneous light
表1是采用CUDA和仅采用CPU对相同输入数据和算法流程的计算结果对比(输入数据量:515.625MB(640×480×880×2B)),从表中可以看出,对于同样规模的数据量,采用CUDA计算只需要5.3s,而采用传统的CPU计算则需要33s,说明了CUDA完全能够使用并行计算代替原本的串行计算,提高计算效率。
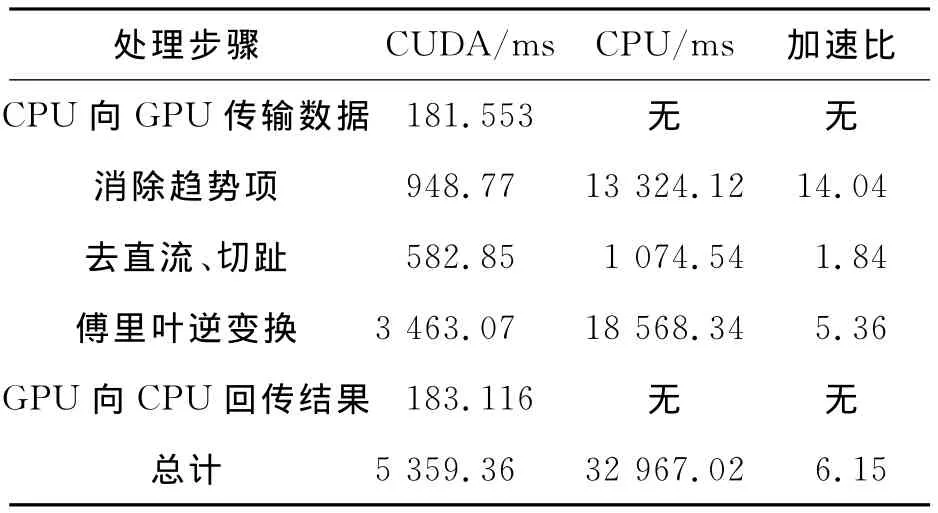
表1 CUDA和CPU计算时间对比Table 1 Calculation time performance contrast between CUDA and CPU
在近期的研究中,改为采用1024点傅里叶逆变换,使用CUDA计算320×480像元大小的光谱立方体仅需要13s,而采用CPU计算时间则达到了接近300s,加速比超过了20倍。表明对于复杂度高的算法来说,CUDA的并行处理模式相对于CPU来说具有很高的效率。
从图9和图10中还可以看出,采用CUDA计算和仅采用CPU计算,分别得到计算结果,其误差基本在±0.005以内,所以采用CUDA进行计算并不会对计算的精度有很大的影响。
通过分析工具Visual Profile的分析结果可以得知,应用程序中仍然存在不足之处,影响了加速比的显著提高,有几方面的原因:一是采用的数据结构不利于显存的合并访问,全局内存存/取和浮点运算次数之比不理想;二是目前采用的并行方式所导致的,在每个线程中还是需要处理一维向量,而同一时刻并行执行的线程数量是有限制的。
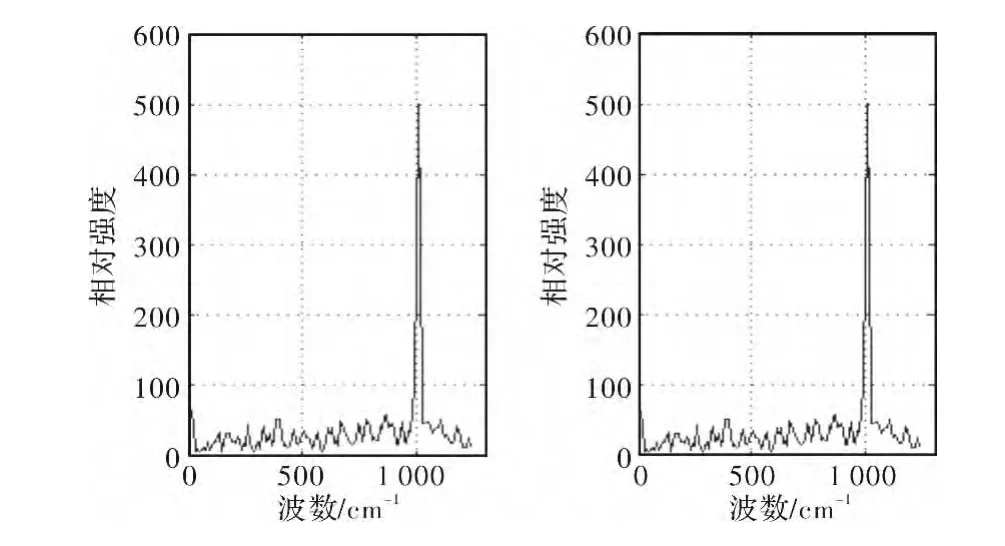
图9 CUDA和CPU反演结果对比Fig.9 Inversion result contrast between CUDA and CPU
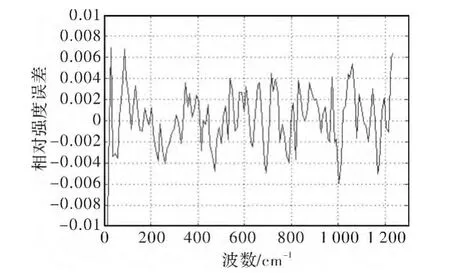
图10 CUDA和CPU反演计算误差Fig.10 Calculating deviation between CUDA and CPU
4 结束语
通过对时空混合调制型成像光谱仪干涉图获取模式的分析,结合CUDA平台,实现了干涉光谱的并行反演算法,并通过实验验证了采用CUDA进行并行计算,将干涉光谱数据的反演过程加速了5到20倍。
[1] 杨智雄,廖宁放,吕航,等.基于CUDA的傅里叶变换成像光谱仪数据重建[J].光学技术,2013,39(2):128-132.YANG Zhi-xiong,LIAO Ning-fang,LÜ Hang,et.al.Fast data reconstruction method of Fourier transform imaging spectrometer based on CUDA[J].Optical Technique,2013,39(2):128-132.(in Chinese with an English abstract)
[2] 王建宇,舒嵘,刘银年,等.成像光谱技术导论[M].北京:科学出版社,2011.WANG Jian-yu,SHU Rong,LIU Yin-nian,et al.Introduction of imaging spectrum tecniques[M].Beijing:Science Press,2011.(in Chinese)
[3] SCHOWENGERDT R A.遥感图像处理模型与方法[M].北京:电子工业出版社,2010.SCHOWENGGERDT R A.Remote sensing:modeling methods for image processing[M].Beijing:Publishing House of Electronics Industry,2010.(in Chinese)
[4] 张茗璇,高教波,孟合民,等.基于傅里叶变 换光谱技术的Zoom-FFT 算法研究 [J].应 用 光 学,2013,34(3):452-456.ZHANG Ming-xuan,GAO Jiao-bo,MENG He-ming,et al.Zoom-FFT based on Fourier transform spectroscopy[J].Journal of Applied Optics,2013,34(3):452-456.(in Chinese with an English abstract)
[5] 孟合民,高教波,肖相国,等.红外高通量干涉成像光谱仪的设计与验证[J].红外与激光工程,2012,41(11):2903-2908.MENG He-min,GAO Jiao-bo,XIAO Xiang-guo,et al.Design and validation of infrared interferential imaging spectrometer with high flux[J].Infrared and Laser Engineering,2012,41(11):2903-2908.(in Chinese with an English abstract)
[6] 严新革,张淳民,赵葆常.时空混合调制型偏振干涉成像光谱仪干涉图获取模式研究[J].物理学报,2010,59(5):3123-3129.YAN Xin-Ge,ZHANG Chun-Min,ZHAO Baochang.Research on the mode of obtaining interferograms based on the temporally and spatially mixd modulated polarization interference imaging spectrometer[J].Acta Physica Sinica,2010,59(5):3123-3129.(in Chinese with an English abstract)
[7] KIRK D B,HU Wen-mei.大规模并行处理器编程实战[M].陈曙辉,熊淑华,译.北京:清华大学出版社,2010.KIRK D B,HU Wen-mei.Programming Massively Parallel Processors[M].translated by CHEN Shuhui,XIONG Shu-hua.Beijing:Tsinghua University Press,2010.(in Chinese)
[8] FARBER R.高性能CUDA应用设计与开发:方法与最佳实践[M].北京:机械工业出版社,2013.FARBER R.CUDA application design and development[M].Beijing:Machinery Industry Press:2013.(in Chinese)
[9] 张淳民.干涉成像光谱技术 [M].北京:科学出版社,2010.ZHANG Chun-min.Interferential imaging spectroscopy [M].Beijing:Science Press,2010.(in Chinese)
[10] 杨露.干涉成像光谱技术中干涉图处理的研究[D].南京:南京理工大学,2007.YANG Lu.Study on interferometry processing of imaging spectroscopy interference[D].Nanjing:Nanjing University of Science and Technology,2007.(in Chinese with an English abstract)
[11] 韩刚.干涉光谱复原算法研究[D].西安:中国科学院西安光学精密机械研究所,2012.HAN Gang.Research on the algorithm of inteferogram spectrum reconstruction[D].Xi'an:Xi'an Institute of Optics and Precision Mechanics,2012.(in Chinese with an English abstract)
