面向图书馆关联数据的语义链接构建研究*
2014-05-31游毅
游 毅
(广州大学图书馆 广东广州 510006)
1 引言
长期以来,馆藏资源以良好的信息质量、较高的组织水平与开放的可获取性而成为公共文化服务体系的重要组成部分。而随着信息爆炸式增长与用户自主意识觉醒,馆藏分散性、异构性、无序性与用户严苛的信息需求形成了尖锐矛盾,图书馆用户希望基于内在需求一站式获取本地馆藏乃至外部网络资源,并以一种关联化和知识化的方式加以组织,从而为关联数据的图书馆应用提供了现实需求。
2006年7月,“万维网之父”Tim Berners-Lee提出了关联数据概念,力图探索Web架构下发布结构化数据并实现语义关联的最佳实践,此后由W3C发起的“开放关联数据运动”更是吸引了各类信息机构乃至个人参与其中。另一方面,目前图书馆元数据无论数据格式还是系统架构均千差万别,同时数据间由于缺乏语义关联而无法充分发挥在馆藏组织与服务中的聚合效应。针对这一问题,关联数据全面支持完整数据类型、面向海量语义关联关系、提供多样数据存取机制等技术特性恰恰弥补了现有馆藏数据的诸多不足,因此有望成为图书馆实现馆藏组织与服务的理想模式。就技术机制而言,关联数据核心在于RDF资源描述框架基础上的语义链接机制,从而深入揭示馆藏中实体或概念之间多样化的语义关联,并实际承担图书馆与外部数据间的融合与共享功能。因此,RDF链接构建机制在馆藏的语义聚合与共享中扮演着重要角色,并由此成为图书馆关联数据应用重点关注的问题。
2 语义链接的构建原则与类型机制
图书馆要实现面向馆藏关联数据的语义链接构建,必须明确链接对象、链接属性、链接类型及构建方式等基础性问题。具体而言,图书馆在语义链接构建中一方面要明确构建基本原则,以便确定合适的链接目标数据集与资源对象并选择恰当的术语词汇作为链接属性,另一方面也要区分语义链接类型并寻找通用高效的构建方式,从而为图书馆关联数据的链接管理奠定方法基础。
2.1 语义链接的构建原则
图书馆应用关联数据的目的之一是利用语义链接将分散异构的馆藏元数据及其描述对象聚合在一起,为此需要确定哪些外部数据集包含馆藏链接目标数据,进而明确具体链接资源对象,此外还要选择恰当的概念术语作为链接属性,而上述内容都需要依据链接构建原则作为指导。
首先,图书馆关联数据的链接构建需要选择数据集作为链接对象来源,而内容权威性、质量稳定性与链接广泛性应成为选择目标数据集的基本原则。具体来讲,由于关联数据中任意资源URI标识都必须保证可解析,即数据对象能够利用HTTP协议解析为相关资源的语义描述信息,因此链接目标数据集的权威性与高质量能够保证馆藏从中获得准确的语义描述,从而促进资源内容的可理解性。此外,由于权威数据集已成为关联数据网络的核心节点,因此与之构建语义链接就等于间接与更多数据集形成关联关系,利用这一扩散效应就能够减轻图书馆直接构建海量语义链接的沉重负担。而从现实角度考虑,目前关联数据网络中的诸多高质量核心数据集都应当成为图书馆关联数据的潜在链接对象来源。
其次,图书馆还需要从已确定的目标数据集中进一步明确具体链接数据对象,从而构建资源之间更为精确和富含语义的链接关系。而这一过程中应重点考虑以下原则:首先是目标数据的质量如何,一般而言链接对象质量越高,就越能够凸显语义链接构建的价值;其次是目标数据能够为图书馆关联数据增加的价值如何,由于图书馆构建语义链接的核心目的在于增强自身关联数据的利用价值,因此链接目标选择也应围绕这一目的展开;再次是目标数据是否具有稳定的维护机制,关联数据动态性导致的更新变化会影响到指向该数据的语义链接的有效性,因此稳定的维护机制能够保证语义链接的持续有效性;最后是目标数据是否已具有丰富链接,丰富的外部语义链接将能够帮助应用程序更好地检索、发现与链接图书馆关联数据并帮助其融入关联数据网络。
图书馆关联数据在确定链接构建的目标数据集与具体数据对象之后,还需要选择概念术语作为链接属性,从而明确表达图书馆与外部数据集之间的语义关联。一般而言,图书馆关联数据在链接属性选择时需要考虑两个原则:一是链接属性应当具有权威性与通用性,从而避免异构属性词汇之间的语义映射过程,同时也便于关联数据应用程序的访问与解析;二是链接属性应当具有稳定可解析的URI,从而使得关联数据应用程序能够对其调用和解析并确保语义链接乃至整个数据网络的整体质量。具体而言,可选择LOD开放关联数据云中广泛使用的词汇集,即使使用生僻名词术语作为链接属性也应当与更为通用的链接属性关联在一起,以便客户端对语义链接的理解与使用。
2.2 语义链接构建的类型机制
实际上,语义链接构建对于任何关联数据发布者而言都是极其困难的任务,原因是一方面在于链接类型的多样化,另一方面则在于构建机制的复杂性。具体而言,语义链接构建既涉及语义框架层面概念术语间的词汇型链接,也包括实体对象层面客观资源间的关系型链接,同时关联数据的内容复杂性也对链接构建质量提出挑战,为此明确语义链接构建的类型机制成为图书馆链接构建首先需要解决的基础性问题。
如前所述,语义链接作为实现关联数据网络构建与资源共享的核心,从目标对象与功能作用上可分为词汇型链接与关系型链接。其中词汇型链接用于关联描述资源内容且存在逻辑关系的概念术语,从而保证数据网络语义层面的一致性。而关联数据中实体间的关系型链接作为数据网络的核心骨架,反映的是客观世界中更为灵活多样且缺乏规律的复杂关联。实际上,当前链接构建复杂化的重要原因便在于语义框架的异构性,即用于资源描述的概念术语在语义层面难以统一,从而影响到关联数据的通用性与可理解性,同时关系型链接的灵活性、主观性与多元化使得关系型链接的构建难度大大增加。
就链接构建机制而言,SPARQL查询与相似度匹配应当成为语义链接构建的核心机制。对于词汇型链接而言,一方面由于概念映射必须实现异构术语词汇的翻译转换,因而需要借助SPARQL查询语言在目标数据集中查询链接词汇对象;另一方面存在关联的术语词汇必然具有某种语义相似性,因此能够通过相似度计算实现词汇型链接构建,同时信息检索与自然语言处理领域的相似度算法也能为此提供方法论支撑。对于关系型链接而言,关联数据中实体间RDF链接构建可通过人工或自动机制来实现,其中人工构建机制可利用SPARQL查询方式确定目标数据集中可供关联的对象URI,而半自动或自动链接构建则是基于资源URI结构相似性或属性相似度来实现。目前来看,关系型链接构建中最重要的仍是基于属性相似度的自动构建机制,即利用算法工具对链接资源对象的特征属性进行相似度判断,从而创建图书馆与外部数据集中实体间的语义链接。
3 图书馆关联数据的链接构建方式
图书馆关联数据力图使用通用体系标准发布与关联各类开放数据集并使之成为满足共享要求的数据资源,而语义链接构建正是其实现开放共享应用的关键。因此图书馆需要在关联数据开放发布基础上构建指向外部数据集的词汇型链接与关系型链接,以便用户及应用程序能够在馆藏与外部资源间自由跳转,并促进图书馆关联数据的自由发现与融合。
3.1 词汇型链接的构建方式
各类关联数据由于选择的语义模型与发布方法存在差异,使得其资源描述中对于概念术语的选择具有不同倾向,进而造成数据集间语义框架的不一致,同时也会对关系型链接构建造成障碍。基于此,馆藏描述词汇与外部通用概念间的语义关联发现就成为图书馆链接构建的首要内容。
3.1.1 基于SPARQL查询的链接构建
SPARQL语言是W3C面向RDF数据查询的候选推荐标准,其典型应用便是通过术语模式查询从目标数据集中寻找符合链接要求的RDF术语变量,以此作为关联数据词汇型链接的关联对象,其针对目标数据集中术语词汇的SPARQL查询语句结构可表达为:

基于上述SPARQL查询模式能够发现基于特定语义结构的关联关系并支持各种属性词汇的深度查询,而在此基础上通过CONSTRUCT陈述结构,图书馆关联数据就能够实现馆藏描述术语与外部通用概念之间的映射关联,即将馆藏术语结构作为外部数据集中SPARQL术语模式查询的约束条件,同时CONSTRUCT语句还支持与其他SPARQL查询条件的混合使用。
综上可见,基于SPARQL查询的链接构建较之词汇间的复杂映射规则编制更为简单直接,同时也能发挥关联数据RDF模型与SPARQL查询优势。例如,图书馆可以利用CONSTRUCT语句实现书目数据集中作者属性bib:author与外部FOAF数据集中人物属性foaf:person之间的语义关联发现,并在书目数据集中产生指向FOAF数据集的映射实例:

3.1.2 基于术语相似度的链接构建
关联数据的术语词汇从本质上可视为通用或领域本体,因此基于本体映射的术语相似度可以成为词汇型链接构建的重要途径。所谓本体映射,是指利用本体间语义级映射与相似度计算来揭示概念间关联关系的过程,从而为图书馆与外部数据集间异构术语词汇的链接构建提供依据。
具体而言,基于本体映射的术语相似度计算能够在词汇语法、概念定义、概念实例与概念结构多个层面实现。基于语法的术语相似度通过计算术语间的编辑距离来判断其是否存在语义关联,其中编辑距离是指术语名称字符串之间实现完全形式转换所需的最小编辑操作数目,具体编辑操作包括字符插入、删除、调换、替换等,同时由于该相似度计算过程实际就是编辑操作的求解最优化问题,因此相应算法包括Diogene算法或本体比较算法等。应当说,基于语法的术语相似度具有最佳的适用性与有效性,但另一方面语义深度的欠缺使得链接准确性难以尽如人意。与之相比,基于概念定义的术语相似度是依据概念的名称、关联关系、约束条件等定义信息,将不同类型定义信息作为独立要素分别计算相似度,进而利用加权平均方法对要素相似度汇总以得到最终的语义相似度。客观来讲,通过比较概念多重属性的语义相似度计算在链接构建中具有更高的准确性,但在缺乏丰富定义信息的情况下其效果往往不尽人意。除上述方法外,基于概念实例的术语相似度是从拥有相同实例的概念可能具有相似性这一假设出发,以概念实例的概率分布为依据来计算相似度,例如可通过机器学习等方式对实例进行自动统计从而获得其联合概率分布,进而利用相应函数确定概念间的语义相似度,其中实例完全相同的概念术语间相似度为1,完全不同则取值为0。由于该方法是基于概念的丰富实例信息来计算相似度,因而能深入语义层次,但同时也表现出对概念实例完备性的过度依赖。最后,基于概念结构的术语相似度计算是基于概念间的语义层次结构,通过其中蕴含的潜在语义信息来揭示词汇间的语义关联。例如术语词汇间在结构上存在的上下位以及整体局部等关联均可定义在以某一核心概念为中心且半径为r的语义辐射范围内,其中语义半径r取值能够反映出概念与核心概念间的语义关联程度。然而,目前单纯依靠概念结构信息的术语相似度仍然缺乏精确性,同时具体算法也有待成熟完善。
综上可见,基于本体映射的术语相似度算法在拥有各自优势的同时也表现出自身局限性,因此在图书馆关联数据的链接构建中需要将各相似度取值分别作为语义关联影响因子,进而通过影响因子的权重汇总来提高链接构建准确性。
3.2 关系型链接的构建机制
图书馆关联数据在语义链接构建中更为核心的还是实体间的关系型链接,这也是馆藏对象与外部资源实现语义聚合最为直接的途径。关系型链接的构建需要借助属性匹配或相似度计算来发现实体关联,而面向RDF数据对象的SPARQL查询与基于信息检索的文本相似度匹配能够为此提供可能途径。
3.2.1 基于SPARQL查询的链接构建
目前关联数据网络中大量数据集均能够提供基于SPARQL端口的数据查询,因此图书馆可以基于此在外部数据集中寻找与馆藏存在语义相似性的资源对象,进而判断和构建二者间的关系型链接。如针对图书馆数据集D与外部数据集D,若要在D与D的实体之间构建关系型链接,首先可以通过如下SPARQL语句针对特定资源文本属性i进行语义查询:
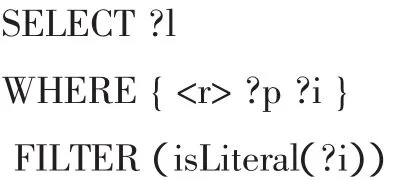
如果能在D与D中分别查询到具有属性i的资源r与r,那么就可以利用RDF链接将二者关联起来,而如果数据集中针对文本属性i的查询结果均不存在,那么就可以认为图书馆与外部数据集面向该属性不存在语义关联。尽管基于SPARQL查询的语义关联发现适用于图书馆与外部数据集间语义链接的初步构建,但由于属性查询实际返回的资源可能不止一个,因而无法为资源相似度判断提供足够的辨识度。为此可在SPARQL查询中增加目标资源类型或URI格式等限制条件。如在图书馆书目数据集与外部数据集DBpedia间寻找语义关联时,可在查询DBpedia中图书资源时对类型属性进行如下限定:

如上所述,实体间的语义链接构建能够利用SPARQL查询中的限制条件来提高关联结果的指向性与辨识度。然而面对图书馆关联数据中的海量链接对象,基于SPARQL查询的链接构建方式虽然能够提供较强可操作性与较小实现难度,但却缺乏足够的执行效率,因此难以满足海量语义链接的构建要求,而基于文本相似度匹配的相关性检索方法恰恰能够通过关联数据背景下的扩展延伸为此提供可能途径。
3.2.2 基于文本相似度匹配的链接构建
实际上,由于关联数据中任意资源都需要提供包括文本属性在内的语义描述,因此如果在语义框架一致性基础上对不同数据集中资源的同类属性进行相似度匹配,就能够判断二者之间是否具有关联并利用语义链接标识其关联关系。
总体而言,无论采用何种文本相似度匹配算法都应满足可延展性与高精确度两项基本要求。可延展性是指相似度算法能够根据文本属性字符串长度进行延展,使之适应任意长度字符串间的精确匹配,如普遍使用的qgrams策略是依据连续字符序列单元长度q将属性字符串切分为若干字符单元,其中q可以依据延展需要自行调整,如字符串r=“dblab”可在q=2的设定下被切分为r={‘d’,‘db’,‘b’,‘bl’,‘l’,‘la’,‘a’,‘ab’,‘b’}多个字符单元,进而通过每个字符单元赋予相似度权重以计算整个字符串的相似度。高精确度是指相似度匹配算法能够准确判断资源属性间是否具有语义关联,这一方面取决于算法自身性能,另一方面也与相似度阈值设置有关。具体而言,用于关系型链接构建的文本相似度匹配算法基本原理均是将图书馆数据集中馆藏属性字符串r作为源数据,将相关数据集中资源属性字符串r作为目标数据,进而计算二者的语义相似度,具体算法包括Edit Similarity算法、基于信息检索的相似度算法、隐马尔科夫模型算法等。
(1)Edit Similarity算法。该算法通过计算字符串间的编辑距离来实现文本属性的相似度匹配,其中馆藏文本属性源字符串r与外部实体属性字符串r之间的编辑距离可表示为 tc(r,r),具体指代借助字符复制、插入、删除、替代等编辑操作将r转换为r所需的最小成本。基于此,属性字符串r与r的编辑相似度可进一步定义为:

由于属性字符串的编辑距离与具体编辑操作有关,因此针对编辑相似度算法也拥有多种编辑距离模型,其中最常见的是Levenshtein编辑距离,即对于复制以外的其他编辑操作均以单位成本1赋值,而复制操作则赋值为零,并据此判断文本属性是否存在语义关联。
(2)基于信息检索的cosine算法。该算法源于信息检索领域的一个基本问题,即在给定查询语句和一组源文件的情况下如何查询最为相关的文件对象,而如果将馆藏与外部资源的属性字符串均视为信息检索算法中的查询文件,将依据q-gram策略切分的字符单元视为文件中的语词,那么就能将文件相关性检索技术用于文本属性相似性匹配中。具体而言,基于tf-idf加权的cosine相似性是基于向量空间模型的相似性测度方法,利用该方法能够将馆藏属性r与目标资源属性r分别转换为单位向量,进而通过测度字符串对应向量之间的矢量角来确定其相似距离,具体cosine相似性函数为:

其中r(t)与r(t)分别为属性字符串r与r中每一个相同字符的标准化tf-idf权重,例如r的标准化tf-idf权重可定义为:
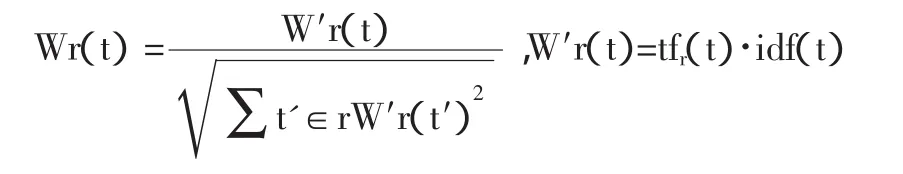
其中tf(t)为字符t在字符串r中的出现频率,而idf(t)则为整个字符串集合R的倒排文档频率。
(3)隐马尔科夫模型。图书馆与外部数据集中资源文本属性相似度匹配还能利用离散隐马尔科夫模型进行建模,该模型能够计算目标对象属性字符串r与馆藏属性字符串r存在相似性的概率函数:

其中a与a是马尔科夫模型中的状态转换概率且a=1-a,P(t|GE)与 P(t|r)分别定义为函数:

利用该算法进行属性相似度匹配的优势在于能够在关系型数据库中使用标准SQL查询语句,因此在目前关联数据集主要由关系型数据库利用D2R方式实现发布的背景下具有很强的可操作性与应用空间。
综上可见,利用文本相似度匹配算法能够实现图书馆与外部关联数据集之间基于属性相似度的语义链接构建。例如在q-grams文本单元切分策略中设定q=2(相关研究表明该取值具有最好的匹配准确度),图书馆可以选择馆藏数据集中题名属性为特征文本属性,并确定适当的相似度算法与目标数据集中同类资源的文本属性进行字符串匹配,最后借助预先设定的阈值θ对其属性相似度进行判断,如果资源间属性相似度超过θ值则构建二者的语义链接。
4 结语
关联数据的语义特性与聚合功能有赖于RDF数据模型下资源间无处不在的语义链接。正是由于数据集间存在包含多种关联属性的RDF链接,才使得多元化创建与分布式管理的关联数据能够聚合成为统一的语义网络。基于此,图书馆关联数据需要面向海量外部数据集构建复杂多样的语义链接,从而更好地融入数据网络之中以提高其可发现性,并促进复杂馆藏实体对象的标识控制与内容表达。同时,通过馆藏实体资源与外部网络资源的深度关联,能够帮助馆藏共享突破传统图书馆物理限制,最终营造出覆盖全球信息资源的广义馆藏空间。
然而必须承认,与面向异构数据类型与用户多元需求的关联数据发布相比,语义链接的构建方法与自动化工具仍然相对匮乏,同时无论基于SPARQL查询抑或相似度匹配的语义链接构建都还无法满足复杂多样的关系型链接构建需求。因此,语义链接高效构建已成为关联数据发展亟待解决的重点问题,同时也应当成为今后图书馆关联数据应用所应着力研究的关键。
[1]EuzenatJ,Shvaiko P.Ontology matching [EB/OL].[2013-11-20].http://homes.cs.washington.edu/hois.pdf.
[2]Scharffe F,Fensel D.Correspondence patterns for ontology alignment[A].Knowledge Engineering:Practice and Patterns[M].Springer Berlin Heidelberg,2008:83-92.
[3]Anhai D,Jayant M,et al.Learning to map between ontologies on the semantic web[A].Proceeding of 11th International WorldWide Web Conference[C].2002.
[4]Rodriguez A.Determining semantic similarity among entity classes from different ontologies [J].Knowledge and Data,2003,37(02):24-31.
[5]Doan A H,Madhavan J,et al.Learning to map between ontologies on the semantic web [A].Proceedings of the 11th international conference on World Wide Web[C].ACM,2002:662-673.
[6]Sekine S,Sudo K,et al.Statistical matching of two ontologies[A].Proceedings of ACL SIGLEX99 Workshop:Standardizing Lexical Resources[C].ACM,1999:134-141.
[7]Arasu A,Ganti V,et al.Efficient exact set-similarity joins[A].Proceedings of the 32nd international conferen ce on Very large data bases[C].VLDB Endowment,2006:918-929.
[8]Bhattacharya I.Collective entity resolution in relational data[J].IEEE Data Engineer,2006,23(2):4-12.
[9]Hausenblas M,Halb W.Interlinking of resources with semantics[A].Poster at the 5th European Semantic Web Conference[C].W3C,2008:234-245.
