一种基于交叉验证思想的半监督分类方法
2014-05-25赵建华
赵建华
(1.西北工业大学计算机学院 陕西西安 710072;2.商洛学院计算机科学系 陕西商洛 726000)
机器学习作为人工智能一个重要研究方向,一直受到计算机科学家的关注。当前,机器学习面临的现实情况是:未标记样本数目众多,易于获得;标记样本数据稀少,难于获得。这种现象使传统的机器学习算法无法得以有效应用,原因在于监督学习需要大量标记样本对分类器进行迭代训练。在这种情况下,半监督学习(Semi-Supervised Learning)和主动学习(Active Learning)应运而生并迅速发展,成为解决上述问题的重要技术[1]。
半监督分类[2-3]利用大量无标记数据扩大分类算法的训练集,主要研究从有监督学习的角度出发,当已标记训练样本不足时,如何自动利用大量未标记样本信息辅助分类器的训练。根据每个样本标记数目的不同,半监督分类可以分为单标记分类和多标记分类。对于单标记分类问题,也就是传统的半监督分类,目前常见的分类方法很多,包括基于EM算法的生成式模型参数估计法[4]、协同训练方法[5-7]、基于支持向量机的半监督分类方法[8-9]、基于流形的半监督分类方法[10]等;对于半监督多标记分类问题,目前出现的方法包括直推式多标记分类[11]和基于正则化的半监督多标记分类[12]等。
泛化误差(Generalization)是统计机器学习模型的重要评价指标,在统计中,泛化误差通常使用交叉验证方法来估计,所以,交叉验证方法广泛地应用到模型选择领域,实现对模型泛化误差的估计和选择[13-14]。有一些研究者或对交叉验证进行改进,或将其应用到分类领域,取得了较好的效果。文献[15]提出一种极限学习机的快速留一交叉验证方法,文献[16]提出了一种改进的交叉验证容噪分类算法,文献[17]将交叉验证容噪分类算法应用到数据流分类领域,都取得了较好的效果。
通过对国内外大量文献的查阅,就作者掌握的文献来看,目前还没有研究者将交叉验证思想应用到半监督分类领域,实现对未标记样本的标记。
本文将交叉验证思想引入到半监督分类领域,提出一种基于交叉验证思想的半监督分类算法(Cross Validation Semi-Supervised Support Vector Machine,CV-S3VM),提高半监督单标记分类器的性能。对所选未标记样本进行伪标记后,形成新的标记集;将新的标记样本集分为多组,使用SVM作为分类器进行交叉验证,计算分类准确率,求出每种伪标记所对应的分类误差率,最后选取能使分类器误差最小的伪标记作为未标记样本的最终标记,挖掘未标记样本信息,扩充未标记样本数量。最后对算法的性能进行分析,并在UCI数据集进行半监督分类实验,验证算法的有效性。
1 基于交叉验证思想的半监督分类方法(CV-S3VM)
1.1 算法思想
该算法的主要思想是通过对未标记样本进行伪标记,将伪标记后的样本加入到标记样本集中,参与训练和测试,选取能使分类器误差较小的标记作为最终的标记,实现对未标记样本进行标记。依次挖掘未标记样本的隐含信息,扩充标记样本的数目。用最终的标记样本训练分类器,减少分类器误差,直接提高学习算法的泛化能力。首先选取一个未标记样本集U,把U中每一个未标记样本都作为候选样本,按照不同的分类类别分别进行不同的伪标记;其次,将标记后的候选样本放入已标记样例中形成新的训练集,将训练集进行分组、交叉验证;接着,分别计算在各种伪标记下分类器训练后误差值,选取误差值小的对应标记作为最终的样本标记值;反复迭代,不断扩充标记集的样本数目,作为最终的训练集。
1.2 算法实现
该算法借鉴交叉验证思想中分组、交叉、验证、求平均值等思想和方法挖掘未标记样本的隐含信息,实现对未标记样本的标记。具体实现算法描述如表1所示。

表1 交叉验证半监督分类算法描述Table 1 The description of sem i-supervised classification algorithm based on cross validation
第1步,合理选取有标记样本集L、未标记样本集U作为初始的分类器训练集。
第2步,从未标记样本集U中选取未标记样本w,分别给w进行伪标记Mi,其中Mi=1,2,…,m-1,m(假设是进行m分类,m≥2)。
第3步,对任意一个标记为Mi的样本w,将其依次填加到有标记样本集L中。
第4步,对于新的有标记样本集L,按照交叉验证的思想将其均匀分为k组。将每个子集数据分别做一次验证集,同时其余的k-1组子集数据作为训练集,得到k个模型。用这k个模型中的训练集训练分类器,使用验证集进行验证,得到最终的分类准确率,计算k个模型分类准确率的平均数,得出相应的误差率。
第5步,选取使得误差率最小的标记Mx,用其实现对样本w的最终标记,并将标记后的w添加到L中,实现对L的扩充。
第6步,通过该方法反复迭代,不断挖掘未标记样本的隐含信息,扩充标记样本集L,直到未标记样本集U为空为止。
第7步,使用扩展后的标记样本集作为最终的训练集,训练形成最终的半监督分类器。
特别地,对于二分类问题,即k=2时,为了能较好地提高标记正确率和分类准确率,采用下面的方式进行处理。当满足公式(1)时,将未标记样本标记为第1类,满足公式(2)时,将未标记样本标记为第2类。

其中,e1和e2分别表示将未标记样本归类为第1类和第2类时对应的误差,η为可调参数,可以通过η调节分类准确率。
1.3 算法分析
该算法将交叉验证思想引入半监督分类领域,通过迭代计算误差,实现了对未标记样本数据的标记。算法可以在某种意义下得到最优的解,可以有效避免选择野点,有效避免过学习和欠学习状态的发生。
算法通过选择能够最大程度缩减分类器误差的样本进行标记,是一种统计学分析方法,具有很强的统计学基础,可以建立基于主动学习的统计学学习模型,即基于模型方差最小化的缩减策略[1,18]。期望误差如式(3)所示,其中D为训练集,x为输入特征,y(x)代表x对应的实际类别,y^(x;D)为预测类别。ET(·)和ED(·)都表示在D上的期望误差,但ED(·)表示通过主动学习,选取误差小的样本进行标记后,将新标记样本扩充到有标记样本集后的训练集D。式(3)可以通过式(4)计算求出,式(4)中的第三项可以通过式(5)计算得出,式(5)可以通过式(6)计算。通过交叉验证半监督学习的目的就是选取期望误差最小的样本进行标记。

其中,ET(·)表示在D上的期望误差。
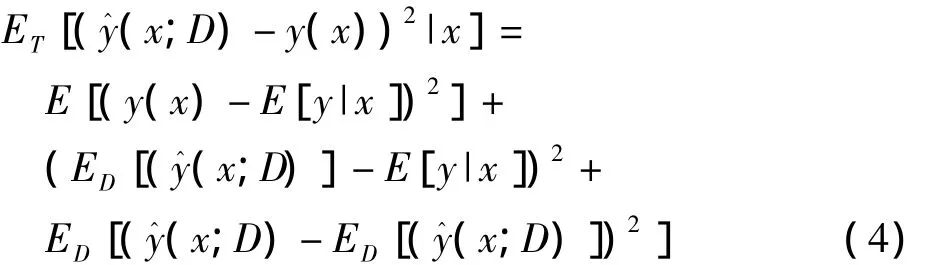
其中,ED(·)表示D更新后在D上的期望误差。

其中,<·>表示增加新的标记样本后,在D上的期望误差值。
同时,算法操作简单,可行性强,较容易实现对未标记样本的标记,同时能较容易实现2分类问题和多分类问题。当m的值为2时,算法可以解决2分类问题,当m>2时,算法很容易地转化为解决多分类问题。该算法时间复杂度为O(n1*n2),其中n1表示选取的未标记样本集中样本数目,n2表示选取的标记样本中样本的数目,一般情况下n1≫n2。
2 实验
实验平台选用 Intel Core2 Duo CPU 2.0 GHz、内存2.0 GB的 PC;安装 Windows XP操作系统和MATLAB 7.8.0(R2009.0a)编程环境;SVM 分类器选用台湾大学林智仁等人开发的模式识别与回归机软件包 libsvm -mat-2.89-3。
实验采用 UCI数据库(http://archive.ics.uci.edu/ml/)中常用的5个数据集,数据集如表2所示。
对于表2所选取的样本,将训练集和测试集的样本数目比例设为1:1。将训练集分为标记样本和未标记样本两种,按照标记样本占训练集样本数目的比例(如式(7)所示)构造三类半监督分类实验数据集。第一类,标记样本占训练集样本的5%;第二类,标记样本占训练集样本的10%;第三类,标记样本占训练集样本的20%。

表2 实验数据集Table 2 Experimental data sets
对于构造的三类半监督分类实验数据集,分别使用普通的SVM方法(即训练集仅仅使用初始的有标记样本集)和CV-S3VM方法(通过交叉验证方法对未标记样本标记,扩充标记样本集)进行分类实验。按照公式(8)和(9)统计实验结果,其中P1表示CV-S3VM方法对训练集中未标记样本进行标记扩充后,对未标记样本进行标记的正确率,P2表示SVM和CV-S3VM对测试集样本进行分类测试的分类正确率。

表3、表4和表5分别表示λ=5%,λ=10%和λ=20%时的实验结果。图1-图5分别表示SVM和CV-S3VM使用5种数据集进行实验的分类正确率P2和标记正确率P1的实验结果对比图。
通过图表可以看出,CV-S3VM使用了交叉验证方法对未标记样本进行了标记和扩充,具有较高的标记率,因此其对测试集样本的分类率明显比SVM要高,尤其在Sonar数据集(图3)中最为明显。同时,我们也可以看到,在标记样本集数目较少时,即λ=5%,相对SVM,CV-S3VM的分类率的优越性得到了充分体现。但随着标记样本集数目不断增加,到达一定程度时,CV-S3VM和SVM的分类率差距越来越小。这是由于此时标记样本数目已经非常充足,半监督学习已经演化成有监督学习。
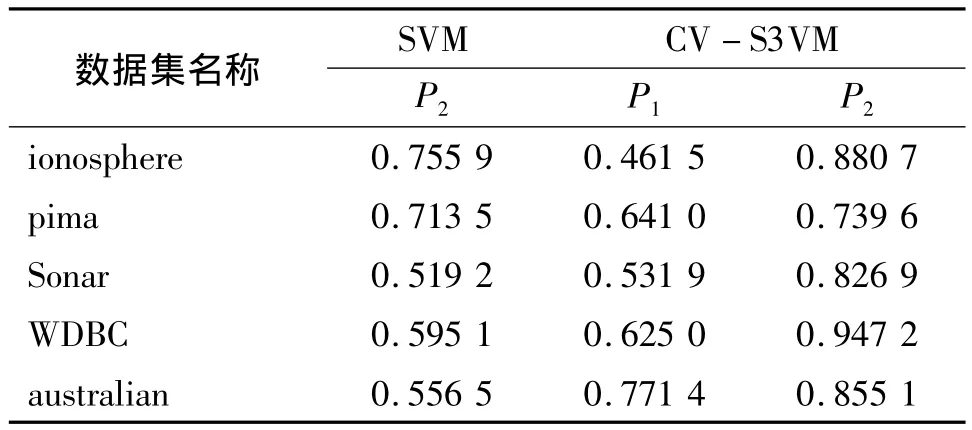
表3 实验结果(λ=5%)Table 3 The experimental result(λ=5%)

表4 实验结果(λ=10%)Table 4 The experimental result(λ=10%)
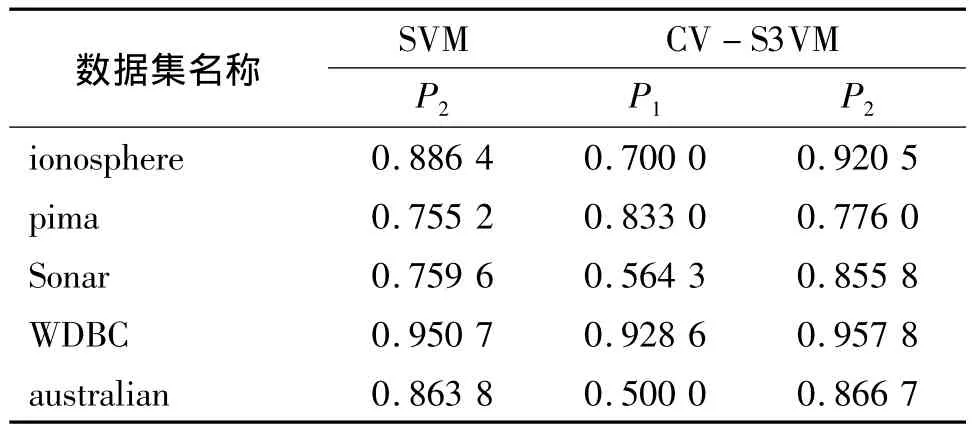
表5 实验结果(λ=20%)Table 5 The experimental result(λ=20%)
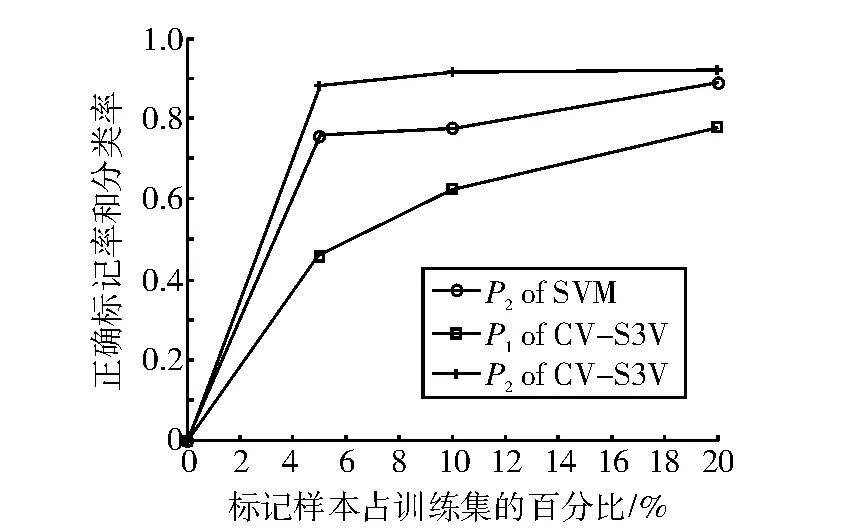
图1 ionosphere样本实验结果对比图Fig.1 The result comparison chart of sample ionosphere
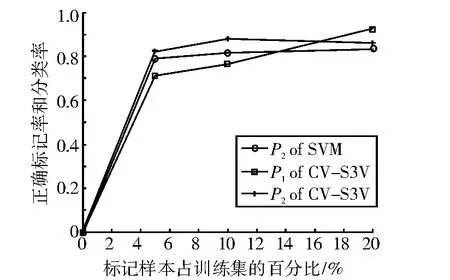
图2 pima样本实验结果对比图Fig.2 The result comparison chart of sample pima
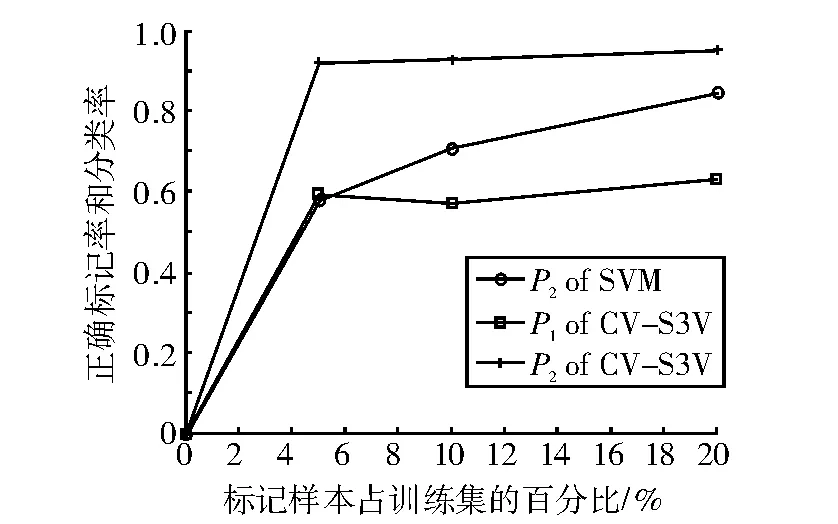
图3 Sonar样本实验结果对比图Fig.3 The result comparison chart of sample Sonar
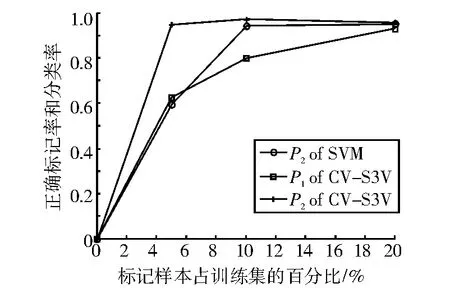
图4 WDBC样本实验结果对比图Fig.4 The result comparison chart of sample WDBC
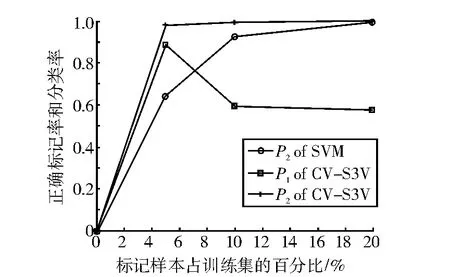
图5 australian样本实验结果对比图Fig.5 The result comparison chart of sample australian
3 结语
本文将交叉验证思想引入到半监督分类领域,提出一种基于交叉验证思想的半监督分类算法(CV-S3VM)。实验结果表明,CV-S3VM操作简单、能较容易实现对未标记样本的标记,性能良好。尤其在标记样本较少的情况下具有明显的优越性。可以将该方法应用到病例分类、网络数据流分类、入侵检测等标记样本稀缺领域。
[1]吴伟宁,刘扬,郭茂祖,等.基于采样策略的主动学习算法研究进展[J].计算机研究与发展,2012,49(6):1162-1173.
[2]ZHU X J.Semi- supervised Learning Literature Survey[R].Madison:University ofWisconsin,2008.
[3]李昆仑,曹铮,曹丽苹,等.半监督聚类的若干新进展[J].模式识别与人工智能,2009,22(5):735 -742.
[4]CH APELLE O,ZIEN A.Semi-supervised Classification by Low Density Separation[C].Proceedings of the 10th InternationalWorkshop on Artificial Intelligence and Statistics,Barbados,2005.57 -64.
[5]ZHOU ZH ,LIM.Tri-training:exploiting unlabeled data using three classifiers[J].IEEE Transactions on Knowledge and Data Engineering,2005,17(11):1529-1542.
[6]Zhang M L,ZHOU Z H.CoTrade:Confident co-training with data editing[J].IEEE Transactions on Systems,Man,and Cybernetics - Part B:Cybernetics,2011,41(6):1612-1626.
[7]赵建华,李伟华.一种协同半监督分类算法Co-S3OM[J].计算机应用研究,2013,30(11):3249 -3252.
[8]WANG Yun-yun,CHEN Song-cai,ZHOU Zhi- hua.New semi-supervised classification method based on modified cluster assumption[J].IEEE Transactions on Neural Networks and Learning Systems,2012,23(5):689-702.
[9]LIY F,KWOK J T,ZHOU Z H.Cost-Sensitive Semi-supervised Support Vector Machine[A].In:Proceedings of the 24th AAAI Conference on Artificial Intelligences(AAAI'10)[C].Atlanta,GE,2010,500 -505.
[10]MENG Jun,WU Li-xia,WANG Xiu-kun.Granulation-based symbolic representation of time series and semi-supervised classification[J].Computers and Mathematics with Applications,2011,62(9):3581 -3590.
[11]KONG Xiang-nan,NG M K,ZHOU Zhi-hua.Transductive multi-label learning via label set propagation[J].IEEE Transactions on Knowledge and Data Engineering(TKDE),2011.25(3):704 -719.
[12]李宇峰,黄圣君,周志华.一种基于正则化的半监督多标记学习方法[J].计算机研究与发展,2012,49(6):1272-1278.
[13]赵存秀,王瑞波,李济洪.交叉验证中类别切分不均衡对分类性能的影响分析[J].太原师范学院学报:自然科学版,2013,12(1):53-57.
[14]杜伟杰,王瑞波,李济洪.基于均衡7×2交叉验证的模型选择方法[J].太原师范学院学报:自然科学版,2013,12(1):27 -31.
[15]刘学艺,李平,郜传厚.极限学习机的快速留一交叉验证算法[J].上海交通大学学报,2011,45(8):1141-1145.
[16]JOHN G H.Robust Decision Trees:Removing Outliers from Databases[A].Proceedings of the First International Conference on Knowledge Discovery and Data Mining[C].Menlo Park,CA:AAAIPress,1995.174 -179.
[17]张健沛,杨显飞,杨 静.交叉验证容噪分类算法有效性分析及其在数据流上的应用[J].电子学报,2011,39(2):378-381.
[18]COHN D,GHAHRAMANI Z,JORDAN MI.Active learning with statistical models[J].Journal of Artificial Intelligence Research,1996,(4):129 -145.
