改进的粒度支持向量机在甲醇合成中的应用
2014-05-25王建国范凯张文兴
王建国 范凯 张文兴
(内蒙古科技大学机械工程学院,内蒙 古包头 014010)
改进的粒度支持向量机在甲醇合成中的应用
王建国 范凯 张文兴
(内蒙古科技大学机械工程学院,内蒙 古包头 014010)
针对甲醇合成过程中的复杂性和非线性等问题,利用共享最近邻(SNN)相似度将训练样本划分成若干个信息粒,然后分别进行支持向量提取,最后将提取出的支持向量融合,建立最终粗甲醇转化率预测模型。试验结果表明,改进的粒度支持向量机(GSVM)可以将“冗余数据”进行删减,获得更“稀疏”的回归模型,精度也高于传统支持向量机的粗甲醇转化率模型,从而能更好地指导甲醇生产。
支持向量机 共享最近邻(SNN) 粒度支持向量机 粗甲醇转化率 粒度计算
0 引言
甲醇作为一种重要的有机化工材料,在有机合成、医药、涂料和国防等工业领域有着广泛的应用。在甲醇生产过程中,合成塔出口粗甲醇的转化率是一个非常关键的指标。在实际生产中,由于在线分析仪价格昂贵且维护复杂,通常使用人工采样分析方法来计算粗甲醇的转化率,因此,建立一个准确有效的粗甲醇转化率预测模型变得尤为重要。
对于甲醇转化率的建模研究,目前国内研究仍然处于起步阶段。文献[1]利用多模型方法代替单模型来建立甲醇转化率预测模型。文献[2]提出一种新的差分进化算法。文献[3]主要利用模糊神经网络方法,并结合一定的优化算法对网络进行优化处理,其效果优于传统的神经网络。然而由于神经网络易陷入局部最优,其训练效果不太稳定,一般需要大量样本。支持向量机具有较强的学习能力与泛化能力,并可以解决小样本、高维数、非线性等问题[4-5],因此更适合建立甲醇转化率模型。但是,由于传统的支持向量机对于复杂冗余的海量数据运算能力较差,导致其泛化能力变弱,影响其最终预测精度。因此,本文采用一种改进的粒度支持向量机建模方法,通过“稀疏化”样本数据来提高模型的预测精度,从而更好地指导生产。
1 支持向量回归机
假设给定训练样本集{(xi,yi),i=1,2,…,l},其中xi∈Rd为第i个学习样本的输入值,d维列向量。对应的目标值为为样本个数。
对于线性情况,支持向量机的函数拟合首先考虑用线性回归函数f(x)=ωx+b拟合,而标准支持向量机一般采用ε-不敏感函数,并引入了松弛变量将最优化问题转化成:
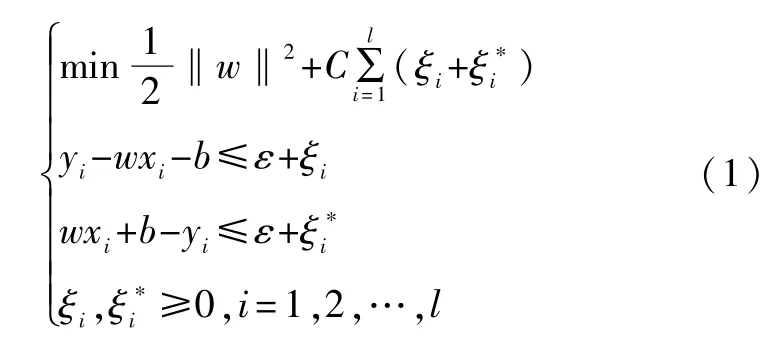
可以看出,式(1)为一个凸二次优化问题,所以引入Lagrange函数求解:
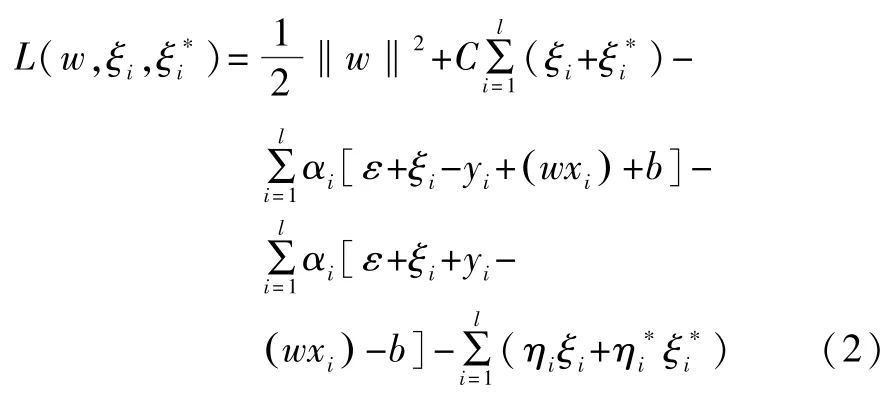
αi、为拉格朗日乘子。分别对w、b、ξ、 ξ*求偏导并令其等于零,得到极值条件,返代入上式,可得到如下的对偶最优化问题。

根据最优化的KKT条件可知,在最优点处拉格朗日乘子与约束的乘积为0,即:

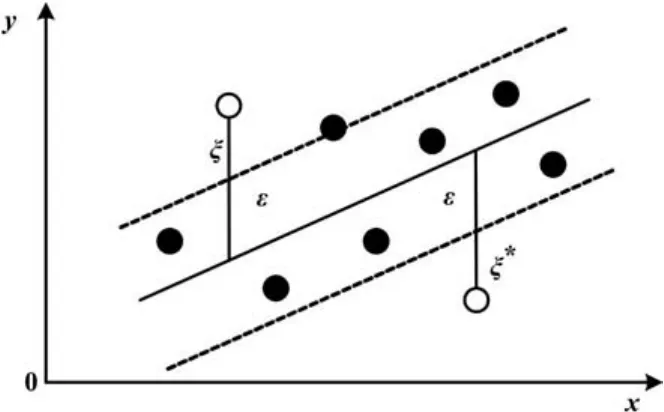
图1 不敏感系数及损失函数Fig.1 The insensitive coefficient and loss function
由式(4)可推导出如下结论。
①同时满足ai=0和的样本点落在ε-带内,即如图1中所示两条虚线之间的点。这些样本点对模型的预测没有贡献,因此不会出现在决策函数中。
从上述结论中可以看出,只有标准支持向量和边界支持向量对决策函数有贡献。也就是说,应尽可能地去除那些对决策函数没有贡献的点,即稀疏性可以简化计算,而且可以提高最终的预测精度。
2 GSVM-SNN算法
2.1 粒度支持向量机
2004年,Yuchun Tang提出了将粒度计算理论和支持向量机相结合的机器学习模型,称为粒度支持向量机(granular support vector machine,GSVM)[6]。它既可以克服传统支持向量机对于大规模数据训练效率低下的问题,同时也可以获得不错的泛化性能。目前GSVM已成为支持向量机的研究热点之一[7-9]。
GSVM将样本空间划分为若干个粒,构建出比传统支持向量机更加优越的间隔宽度,从而提高模型的泛化能力。最优超平面的对比图如图2所示。

图2 最优超平面的对比图Fig.2 Comparison of the optimal hyperplanes
其次,GSVM还可以将一个典型的X-OR线性不可分问题,通过合理的划分机制,将其转化为两个线性可分问题,从而得到多个决策函数。线性不可分问题的解决示意图如图3所示。

图3 线性不可分问题的解决示意图Fig.3 Solution of the linear inseparable issue
支持向量机是针对整体样本集构造最优超平面。而粒度支持向量机的主要思想是通过一定的方法将样本空间划分成为若干个子空间,得到一系列的信息粒;然后在每个信息粒上进行支持向量机的学习;最后通过信息粒上的信息,获得最终的支持向量机决策函数。
2.2 SNN相似度
传统相似度在高维空间中不能准确地反映两点之间的相似问题,而对于密度不同的样本空间,传统的密度聚类方法也无法准确将样本点区分出来。针对以上问题,Jarvis-Patrick提出了一种相似性的间接方法,即共享最近邻(shared nearest neighbor,SNN)相似度。其原理为:如果两个点与相同的点中的大部分相似,即使两点的直接相似度量无法反映两点的相似性,两点依然相似[10]。
定义 xi和xj为样本集{x1,x2…xn}的任意两点,若两点存在于对方的k-最近邻中,则两点相似,且其共享最近邻点的个数为两点的相似度。
两点之间的SNN相似度的计算如图4所示。首先,计算两个黑点的8个最近邻,其中4个灰色点是两个黑点共享的最近邻点,则我们称这两个黑点之间的SNN相似度为4。

图4 两点之间的SNN相似度的计算Fig.4 Calculation of SNN similarity between two points
2.3 GSVM-SNN算法
由图5可知,第1股水氨氮浓度为1 700 mg/L,其氨水最低采出浓度为31 927 mg/L,最高采出浓度为67 875 mg/L,未达到设计值;出水氨氮浓度即塔釜液氨氮浓度在75 mg/L以内,其平均值为69.4 mg/L,满足设计值。第2股水氨氮浓度为3 500 mg/L,其氨水低采出浓度为86 732 mg/L,最高采出浓度为138 830 mg/L,未达到设计值;出水氨氮浓度在45 mg/L以内,其平均值为33.3 mg/L,满足设计值。
SNN相似度在聚类中可以划分为任意形状、变密度的样本集。本文利用SNN相似度这一特性,对样本点进行粒的划分,得到更符合样本点自然分布的信息粒。然后对这些信息粒进行支持向量机(support vector machine,SVM)的训练,尽可能地提取混合粒中的支持向量点。将这些点与“边缘点”融合在一起,建立最终的决策模型。
GSVM-SNN主要算法步骤如下。
(1)设定阈值k。
(2)根据式(5)计算样本点的每一个点的k最近邻,得到整个样本点的k最近邻列表。
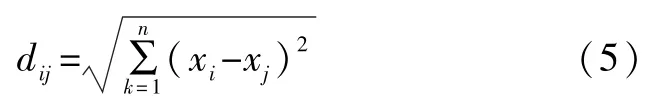
式中:xi、xj为样本的任意两点。
(3)通过k最近邻列表,计算每个点的SNN相似度,得出样本的相似度矩阵。
(4)利用阈值稀疏化SNN相似度矩阵,将大于阈值相似度的点划分成簇;将小于阈值相似度的点归为离群点。
②利用参数ε较小的SVM对其余的粒分别进行支持向量机的训练,并提取支持向量。保证在不丢失关键支持向量的前提下,对冗余样本点进行删减。
(5)融合混合粒与提取出的支持向量,建立最终的决策模型。
(6)输入测试样本,计算预测结果。
3 仿真试验
本文主要研究某厂甲醇项目中的甲醇合成工序。甲醇生产的主要任务是将合成气在一定压力、温度、催化剂的作用下合成粗甲醇[11]。而甲醇转换率受诸多因素的影响,由生产经验总结出,影响因素主要有温度、压力、碳氢比、空速、循环比。因此,本文选取温度、压力、碳氢比、空速以及循环比这5个变量作为预测模型的输入,选取甲醇合成塔出口的单程粗甲醇质量转化率为输出。试验首先利用归一化对数据进行预处理,将所有数据缩放到[0,1]之间,并选取均方误差(mean square error,MSE)作为评价指标。

式中:yi为真实值;为预测值。
为了验证对比结果的有效性,传统的SVM与GSVM-SNN两种方法的核函数都采用高斯核函数,且参数C=1、ε=0.01、q=0.08。
两种方法的MSE误差及对甲醇转化率的数据拟合对比图分别如图5和图6所示。

图5 两种方法的MSE误差对比图Fig.5 Comparison of the MSE errors from different methods
经过预处理后共有249组数据,本文利用10折交叉验证,将数据分为10份,其中8份作为训练样本,剩余2份作为测试样本,与传统支持向量机进行10次对比试验。

图6 两种方法的拟合对比图Fig.6 The fitting comparison of different algorithms
两种方法10次试验分别得到的最终支持向量个数如表1所示。

表1 两种方法的最终支持向量个数Tab.1 The number of final support vectors from two methods
传统支持向量机对样本数据建模与GSVM-SNN模型的10次试验所得到的误差结果对比如表2所示。

表2 两种方法的MSE误差结果Tab.2 The MSE errors results from two methods
从表1可以看出,GSVM-SNN利用SNN相似度在给定阈值k时,对于不同的样本数据,其划分的粒的个数也不尽相同。这是因为基于SNN相似度的划分方法得出的结果更符合数据样本的“自然”分布。然后对每一个信息粒进行SVM的训练,在保证不丢失关键信息的前提下,尽可能地删去“冗余”数据。
从表2以及图5可以看出,经过“瘦身”后的GSVM-SNN的预测误差基本上低于传统支持向量机的预测误差。而从图6可以看出,GSVM-SNN对实际甲醇转化率的数据拟合效果优于传统的支持向量机,说明GSVM-SNN的模型预测精度高于SVM的模型。
4 结束语
本文利用SNN相似度对粒度支持向量机模型进行改进并预测粗甲醇的转化率。结果表明,GSVMSNN模型的预测精度比传统的SVM模型更高,且更适应甲醇合成过程的非线性、复杂性,从而能更好地指导实际生产过程。
[1] 魏可泰.多模型软测量理论研究及其在甲醇生产中的应用[D].青岛:青岛科技大学,2008.
[2] Rahnamayan S,Tizhoosh H R,Salamam M A.Opposition-based differential evoloution[J].IEEE Transactions on Evolutionary Computation,2008,12(1):64-79.
[3] 缪啸华,宋淑群,王建华,等.基于模糊神经网络的甲醇合成塔转化率软测量模型[J].石油化工自动化,2012,48(2):32-35.
[4] Vapnik V.The nature of statistical learning theory[M].New York: Springer-Verlay Press,1995:156.
[5] 张学工.关于统计学习理论与支持向量机[J].自动化学报, 2000,26(1):32-42.
[6] Tang Yuchun,Jin Bo,Sun Yi,et al.Granular support vector machines for medical binary classification problems[C]//Computational Intelligence in Bioinformatics and Computational Biology,2004:73-78.
[7] 张鑫,王文剑.一种基于粒度的支持向量机学习策略[J].计算机科学,2008,35(8a):101-103.
[8] Ding Shifei,Qi Bingjun.Research of granular support vector machine[J]. Artif Intell Rev,2012,38(5):1-7.
[9] Wang Wenjian,Guo Husheng,Jia Yuanfeng,et al.Granular support vector machine based on mixed measure[J].Neuro Computing, 2013,101(5):116-128.
[10] Ertoz L,Steinbach M,Kumar V.A new shared nearest neighbor clustering algorithm and its applications[C]//In Workshop on Clustering High Dimensional Data and Its Applications,Proceedings of Text Mine'01,First SIAM intl.Conference on Data Mining, Chicago,IL,USA,2001.
[11] 王珊.基于改进人工蜂群算法和LSSVM的甲醇合成过程软测量建模方法研究[D].上海:华东理工大学,2012.
Application of the Improved Granular Support Vector Machine in Methanol Synthesis
To counter the problems of complexity and nonlinearity in methanol synthesis process,by using shared nearest neighbor(SNN) similarity,the training samples are divided into several information granules,then support vector extraction is conducted respectively,finally the prediction model of crude methanol conversion rate is built from these extracted support vectors.The experimental results show that the improved granular support vector machine can delete“redundant data”and to get“sparse”regression model,and offer higher accuracy than traditional support vector machine crude methanol conversion rate model,thus the methanol production can be guided better.
Support vector machine(SVM) Shared nearest neighbor(SNN) Granular support vector machine(GSVM) Crude methanol conversion rate Granular computation
TP202
A
国家自然科学基金资助项目(编号:21366017);
内蒙古自然科学基金重大项目(编号:2011ZD08);
内蒙古自治区教育厅高等学校科学研究基金资助项目(编号: NJZY13144);
包头市科技局重大科技发展基金资助项目(编号:2011Z1006)。
修改稿收到日期:2014-02-17。
王建国(1958-),男,2009年毕业于北京科技大学机械电子工程专业,获博士学位,教授;主要从事机电系统智能诊断与复杂工业过程建模、优化及故障诊断的研究。
