基于模糊模式与决策树融合的脚本病毒检测算法
2014-05-22付垒朋
张 涛 张 瀚 付垒朋
基于模糊模式与决策树融合的脚本病毒检测算法
张 涛 张 瀚*付垒朋
(南开大学天津市智能机器人技术重点实验室 天津 300071)
构建决策树进行脚本病毒检测可以全面利用训练样本的信息,在样本特征较为复杂、样本数较大的情况下会产生大量节点,计算时间复杂度高,在剪枝过程中影响分类准确度。为融合模糊模式的信息以提高分类器性能,该文设计了决策树分类基础上的融合算法。该算法将关于模糊模式贴近度的3个特性作为决策树样本信息向量中的属性。使用训练样本集,根据上述属性在划分点上的分裂信息值及信息增益率选择分裂属性,逐步构建决策树。实验结果验证了算法的稳定性与准确度,表明这种融合方法可增加属性的区分度,减少决策树的分支数。
脚本病毒检测;模糊模式;决策树;贴近度
1 引言
脚本病毒[1]作为网络中的流行病毒对信息安全产生巨大威胁,脚本病毒检测技术的研究有着积极的意义。脚本与浏览器的紧密结合,简单的脚本语法使得病毒易于变形与撰写。特征代码法、校验和法等对于变种病毒检测效果不好[2],使得统计与人工智能方法被广泛应用。
脚本病毒与可执行文件病毒等在语言与执行环境上有明显区别,脚本病毒研究有其自身特点。 Choi等人[3]采用N-gram分析脚本代码,结合SVM方法识别未知脚本病毒。Asaf等人[4]使用机器学习理论构建分类器,通过对静态特征的分析检测恶意代码。Robert等人[5]总结了机器学习方法提取恶意代码静态特征的研究进展,模糊理论[6]被应用到病毒检测中,可以识别未知的计算机病毒。文献[7]细致讨论了脚本病毒检测中,模糊模式的具体构造算法与参数选取。模糊模式的使用能提取病毒集的特征相互之间的规则信息,一定程度上能反映脚本语言编写特点,但是仅使用模糊模式检测病毒的效果不太理想。
决策树[8,9]是模式分类中的常用技术,文献[10]使用决策树分析可执行文件病毒的机器码。决策树算法通常[8,9,11]具有较高的准确率,分类效果与训练样本有直接关系。如果训练样本包含噪声数据过多,特征过于复杂,或统计出现波动,使得增加了不必要的分支,会产生决策树的过度适应现象,这样分支的增多会导致资源消耗的增加。
针对决策树算法的不完善及模糊模式在脚本检测中的缺点,本文提出了一种基于模糊模式和决策树相融合的脚本病毒检测算法。决策树使用脚本文件集预处理产生的特征信息训练生成;为了增加属性区分度,减少树节点个数,构建决策树时融合了模糊模式中贴近度的信息;混合使用模糊模式信息与自身特征信息可提高决策树的稳定性,改善决策树的准确性,所得决策树为新的脚本病毒分类器,最后通过实验结果验证检测效果。
2 脚本文件集的来源与预处理
实验对象为VBScript脚本构成的病毒脚本集与正常脚本集,通过VirusTotal, VirusScan标记。其中病毒脚本1277个,来源为VX Heavens[12]网站下载的病毒实例与脚本病毒生成器生成的典型病毒实例,及知名安全网站看雪、剑盟、卡饭、http:// malwareurl.com等。病毒脚本的种类涉及后门程序、自动运行病毒、邮件蠕虫、漏洞攻击代码、P2P蠕虫、局域网蠕虫、WORD宏病毒、EXCEL宏病毒、加密变型病毒等。正常脚本集4041个,由版本1.15.4的Heritrix工具爬取网页获得,接近现实网络中的分布,包括网站的特效脚本代码、word宏、excel宏和http://www.computerperformance.co.uk/ vbscript/网站的示例代码。
脚本病毒的行为主要通过调用如CreateObject, CreateObject的关键的系统函数和如FileSystem Object的对象来实现,Zou等人[13]使用它们来表示病毒行为。文中这两类作为关键词被提取,对病毒脚本集和正常脚本集进行关键词的统计分析[7],按其在病毒集和正常集中出现频率的均方误差大小排序,本文选取均方误差显著较大的关键词。样本信息由矩阵描述,行表示某样本的向量信息,元素为样本的属性取值,即关键词的出现频率。
3 模糊模式与决策树算法融合的检测算法
由文献[7]可知基于模糊模式的脚本病毒检测算法稳定性好,但对病毒文件检测正确率不太理想。基于决策树算法的脚本病毒检测算法分类效果同训练样本有关,全面的样本集会带来较高的准确率;但如果训练样本噪声过多,统计出现波动,都会出现决策树过度适应现象,产生的多余分支会使得分类出现错误。在决策树修剪环节中,决策树过于复杂会增加难度。精确的决策树需要较多的节点,训练建树时间较长,将模糊模式和决策树相融合,模糊模式的使用可增加属性的区分度,减少决策树的分支数,即减小计算时间复杂度,增加检测的稳定性。因此,本文设计了利用模糊贴近度信息的融合算法。
3.1模糊化与贴近度的计算
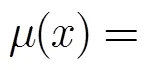
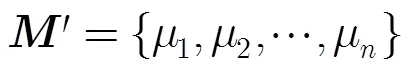
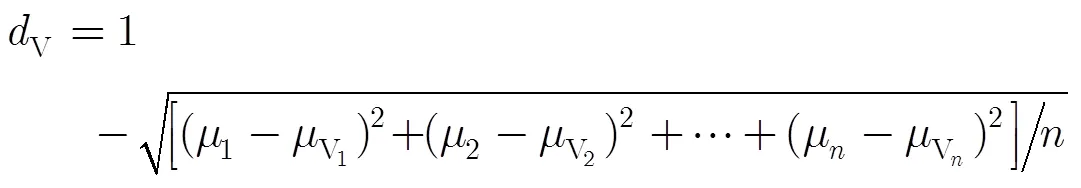
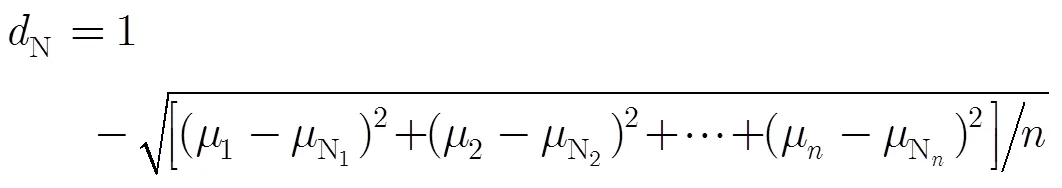
3.2 融合算法
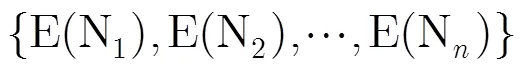

3.2.2决策树构建子算法描述 依据文件预处理后的关键词及其模糊属性信息生成C4.5决策树[8,9,11],并对决策树进行悲观剪枝[15],以控制生成决策树规模,提高准确率,算法主要步骤如下:
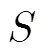
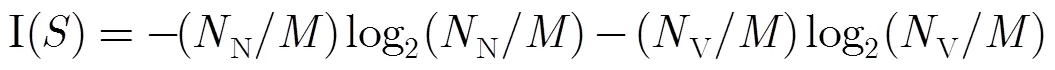
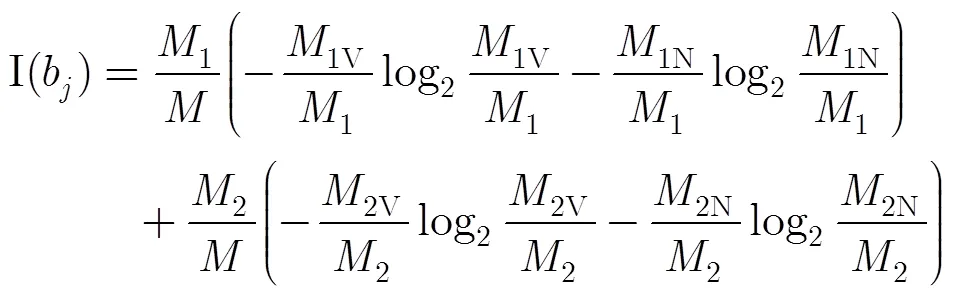
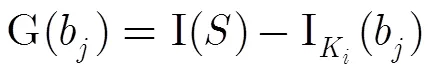
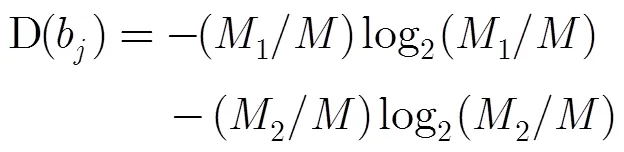
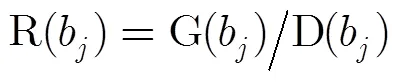
步骤3 对所有属性使用上述方法,选取具有最大信息增益率的属性作为此次分裂的属性,并将集合划分为两个子集;
步骤4 对划分的两个子集使用上述方法递归进行决策树的生长;
步骤5 设置叶节点,停止决策树的生长。以下3种情况设为叶节点:节点数据集的纯度达到98%;节点数据集与整个数据集样本数比值小于1%,即数据集过小;没有用来分割的属性。当该节点集合中病毒比重较大时,将此叶节点的类别设置病毒,反之设置为正常文件。
3.2.3分类算法描述
4 实验结果分析
4.1 融合算法的实验结果
使用10次交叉验证实验方式[16],共5318个样本。每次随机提取1772个实验样本作为测试数据集,其中病毒文件425个,正常文件1347个,其余3546个样本作为训练集。决策树停止生长的条件设置为:最小的叶准确率为98%,最下的叶分支比例为0.001,连续属性的划分数设置为30。

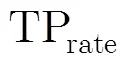
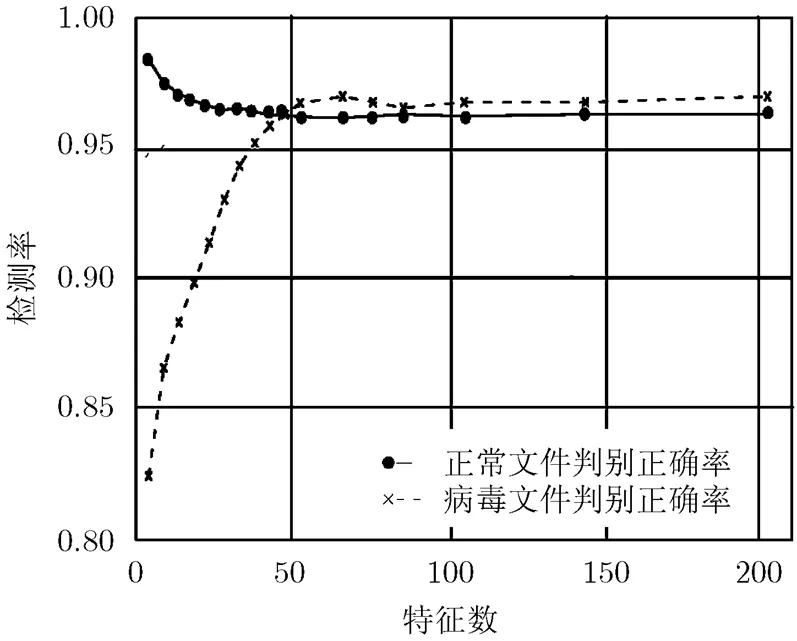
图1 融合算法中关键词数与实验正确率的关系图
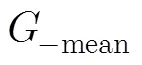

4.23种检测模型的对比分析
4.2.1正常文件的检测率 由表1,表2将融合算法与决策树算法、文献[7]的模糊模式算法比较,正常文件检测率均值依次为0.9638, 0.9584, 0.9875,总体样本差依次为0.0011, 0.0024, 0.0020。模糊模式算法对于正常文件检测效果稍强于其它两个检测模型,因模糊模式算法构造时倾向于判断为正常文件。
表1决策树模式10次交叉实验结果
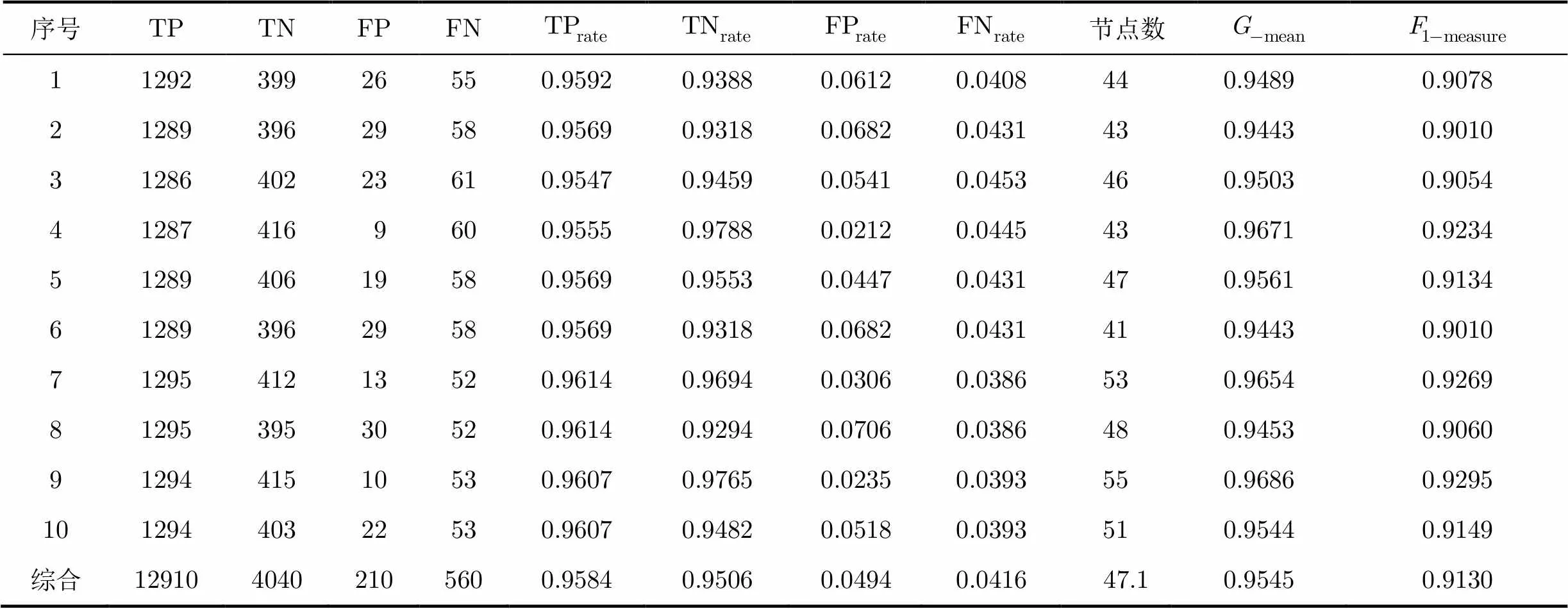
序号TPTNFPFN节点数 1129239926550.95920.93880.06120.0408440.94890.9078 2128939629580.95690.93180.06820.0431430.94430.9010 3128640223610.95470.94590.05410.0453460.95030.9054 41287416 9600.95550.97880.02120.0445430.96710.9234 5128940619580.95690.95530.04470.0431470.95610.9134 6128939629580.95690.93180.06820.0431410.94430.9010 7129541213520.96140.96940.03060.0386530.96540.9269 8129539530520.96140.92940.07060.0386480.94530.9060 9129441510530.96070.97650.02350.0393550.96860.9295 10129440322530.96070.94820.05180.0393510.95440.9149 综合1291040402105600.95840.95060.04940.041647.10.95450.9130
表2融合算法10次交叉实验结果
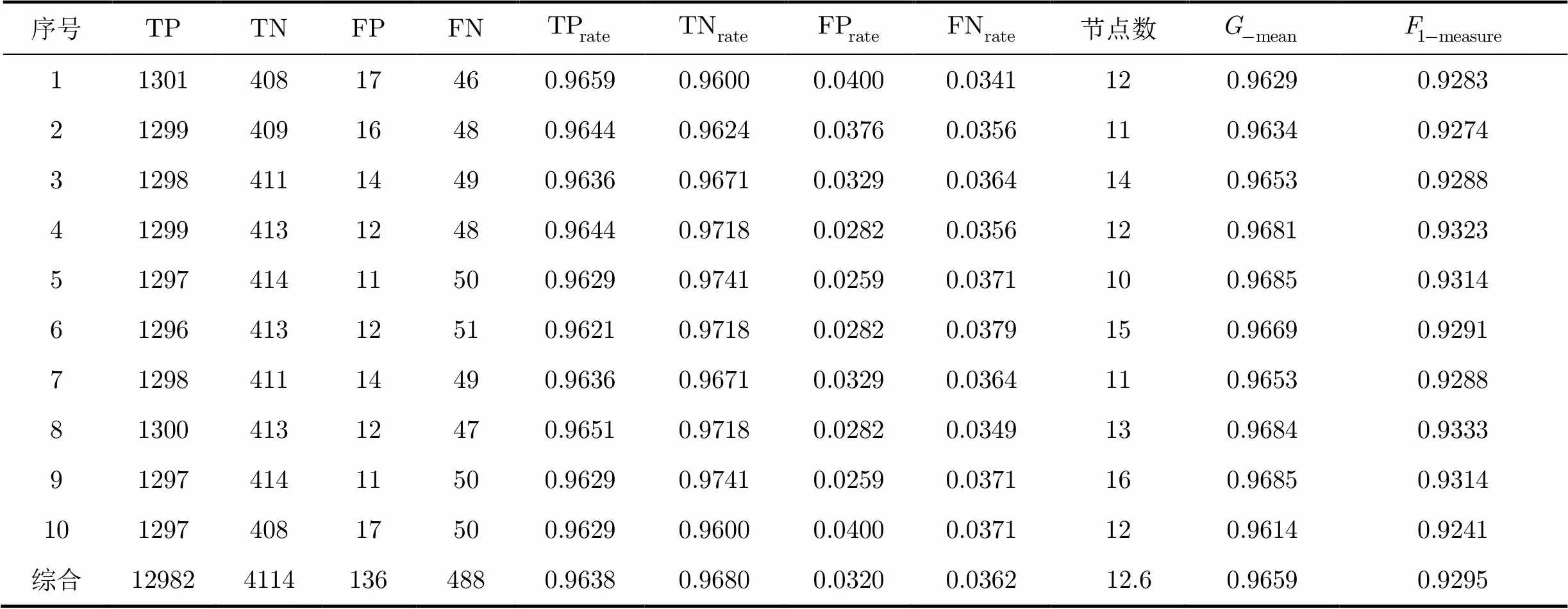
序号TPTNFPFN节点数 1130140817460.96590.96000.04000.0341120.96290.9283 2129940916480.96440.96240.03760.0356110.96340.9274 3129841114490.96360.96710.03290.0364140.96530.9288 4129941312480.96440.97180.02820.0356120.96810.9323 5129741411500.96290.97410.02590.0371100.96850.9314 6129641312510.96210.97180.02820.0379150.96690.9291 7129841114490.96360.96710.03290.0364110.96530.9288 8130041312470.96510.97180.02820.0349130.96840.9333 9129741411500.96290.97410.02590.0371160.96850.9314 10129740817500.96290.96000.04000.0371120.96140.9241 综合1298241141364880.96380.96800.03200.036212.60.96590.9295
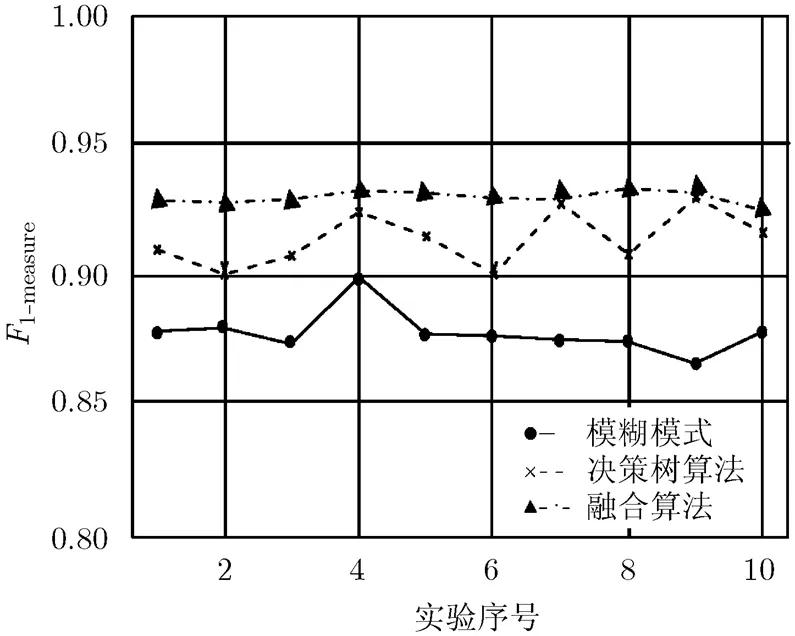
图2 3个模型10次交叉验证值曲线图
4.2.4决策树的节点个数 两种决策树模型生成的结点数见表1,表2,决策树模型节点数在47个左右,节点数总体标准差为4.41。融合算法检测方法需要节点数较少,仅为13个左右,融合模型节点数总体标准差为1.8,生成节点数的稳定性较好,其生成的节点数仅为决策树模型的25%左右。
4.3 融合算法的理论分析
决策树的显著优点是所给分类问题的计算时间复杂度与决策树的节点数成线性增长关系。决策树中某些重要模式由于噪声及数据波动可导致建树过程复杂,而由模糊模式提炼的较为本质的属性具有一定鲁棒性,一定程度上可抗噪声干扰,结合建树算法互为补充,在保证正确率的前提下,既可由模糊模式提高稳定性,也能在两者的融合下大幅度节省节点数。当样本足够多,种类全面时融合算法的优势会更加明显。
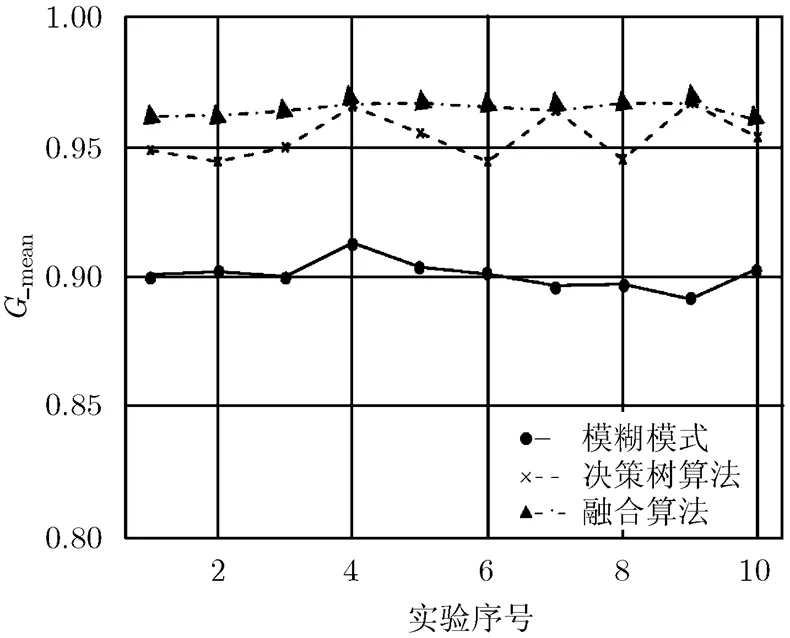
图3 3个模型10次交叉验证值曲线图
5 结束语
本文在决策树检测实验的基础上提出了一种基于模糊模式和决策树算法相融合的脚本病毒检测算法,通过实验结果分析,融合算法在脚本病毒检测中具有很好的检测效果与可行性,总体分类性能与病毒分类性能较模糊模型有明显提高,比单纯的决策树模型也有一定提高。这种模糊模式同决策树融合的具体方法可显著减少节点生成个数,增加了属性的区分度。它克服了模糊模式对病毒类的低检测率,优化了决策树的构建过程,较好地同时利用了模糊信息与自身的特征信息,且性能稳定,生成节点数较少。
本文提出的脚本病毒检测算法针对VBScript,对于其它的脚本病毒的研究需提取有效特征再应用。寻求模糊模式和改进决策树的更有效的融合办法,是将来的工作方向之一。
[1] Willem D G, Dominique D, and Frank P. Better security and privacy for web browsers: a survey of techniques, and a new implementation[C]. 8th International Workshop on Formal Aspects of Security and Trust, Leuven, Belgium, 2011: 21-38.
[2] Kim J Yand Moon B R. New malware detection system using metric-based method and hybrid genetic algorithm[C]. Proceedings of the 14th International Conference on Genetic and Evolutionary Computation Companion, Philadelphia, PA, United States, 2012: 1527-1528.
[3] Choi J H, Choi C, Kim H Y,. Efficient malicious code detection using N-gram analysis and SVM[C]. International Conference on Network-Based Information Systems, Tirana, Albania, 2011: 618-621.
[4] Asaf S, Robert M, Yuval E,. Detection of malicious code by applying machine learning classifiers on static features: a state-of-the-art survey[J]., 2009, 14(1): 16-29.
[5] Robert M and Yuval E. Malicious code detection using active learning[C]. Second ACM SIGKDD International Workshop, PinKDD 2008, Las Vegas, NV, USA, 2008: 74-91.
[6] Zadeh L A. The concept of a linguistic variable and its applications to approximate reasoning[J]., 1975, 8(3): 199-249.
[7] 张涛, 付垒朋, 张瀚, 等. 一种基于模糊模式的脚本病毒检测方法[OL].中国科技论文在线, http://www.paper.edu.cn. 2011.9.
Zhang Tao, Fu Lei-peng, Zhang Han,. Research on method of classification based on fuzzy pattern model in script virus detection[OL]. http://www.paper.edu.cn. 2011.9.
[8] Quinlan J R. C4.5 Programs for Machine Learning[M]. San Mateo, CA, Morgan Kaufmann Publishers, 1993, Chapter 1- Chapter 5.
[9] Thakur D, Markandaiah N, and Raj D S. Re optimization of ID3 and C4.5 decision tree[C]. International Conference on Computer and Communication Technology, Allahabad, India, 2010: 448-450.
[10] Rad B B, Masrom M, Suhaimi I,. Morphed virus family classification based on opcodes statistical feature using decision tree [C]. The International Conference on Informatics Engineering & Information Science, University Technology Malaysia, Kuala Lumpur, Malaysia, 2013: 123-131.
[11] Fan Jie and Wen Pu. Application of C4.5 algorithm in web- based learning assessment system[C]. The Sixth International Conference on Machine Learning and Cybernetics, Hong Kong, China, 2007: 4139-4143.
[12] VX Heavens. Virus collection[OL]. http://vx.netlux.org. 2009.10.
[13] Zou Meng-song, Han Lan-sheng, Liu Qi-wen,. Behavior- based malicious executables detection by multi-class SVM[C]. Proceedings of IEEE Youth Conference on Information, Computing and Telecommunication, Piscataway, NJ, United States, 2009: 331-334.
[14] Nakamura E and Kehtarnavaz N. Optimization of fuzzy membership function parameters[C]. Proceedings of the IEEE International Conference on Systems, Man and Cybernetics, Piscataway, NJ, United States, 1995: 1-6.
[15] Rajeev S and Kyuseok S. A decision tree that integrates building and pruning[C]. Proceedings of 24th International Conference on very Large Database, New York, USA, 1998: 404-415.
[16] Duda R O, Hart P E, and Stork D G. Pattern Classification [M]. 2nd Edition, New York: USA, Wiley, 2001, Chapter 8.
张 涛: 女,1983年生,硕士生,研究方向为信息安全.
张 瀚: 男,1978年生,男,博士,教授,博士生导师,研究方向为计算智能、信息安全、生物信息学.
付垒朋: 男,1983年生,硕士生,研究方向为信息安全.
Script Virus Detection Algorithm Based on Fusion of Fuzzy Pattern and Decision Tree
Zhang Tao Zhang Han Fu Lei-peng
(,,300071,)
The method using the decision tree for script virus detection can make full use of the information of training samples. But complex sample features and large number of samples will produce large number of nodes which result in the high algorithm time complexity and affect the classification accuracy due to the pruning process. In order to improve classification performance, a fusion algorithm using the information of fuzzy pattern is designed based on the decision tree classification algorithm. Three important characteristics of fuzzy pattern about close degree are regarded as the three attributes of sample information vector in the decision tree to build decision tree through training get.The stability and accuracy of the algorithm is verified by experiment. The experiment results show that the proposed algorithm increases discrimination of attributes and reduces the decision tree branch.
Script virus detection; Fuzzy pattern; Decision tree; Close degree
TP309.5; TP181
A
1009-5896(2014)01-0108-06
10.3724/SP.J.1146.2012.01491
2012-11-16收到,2013-08-12改回
国家自然科学基金(61004086)和高等学校博士学科点专项科研基金(200800551024)资助课题
张瀚 zhanghan@nankai.edu.cn
