家庭网络后台流量分析与识别
2014-05-18郭志鑫乔美华
郭志鑫 乔美华
1 山东大学 济南 250100
2 河海大学 南京 210098
引言
随着互联网的迅速普及和发展,家庭网络化已经成为信息社会的一个发展趋势。通过现有的计算机网络技术,家庭内各种家电和电子设备可以通过网络为人们提供各种服务,获取外部信息。逐渐增加的带宽压力使网络运营商必须提高对网络流量的管理控制能力,而业务流量识别技术则是实现下一代网络的可控、可信、可扩展的一个重要因素。先进的流量识别技术不仅可以提高网络管理的能力,从一定程度上预测网络的未知流量,还可广泛应用于网络管理、业务监控、服务质量管理等各个系统,对下一代网络业务管理、服务质量控制等都有重大的现实意义[1-2]。
1 常用应用的流量特征分析
由于流量识别和分类是根据抓包特征的不同进行的,所以抓包特征的合适与否决定了识别的准确度,抓包特征是否容易得到决定了下一步编程识别的难度。我们选用抓包工具Wireshark,该工具使用方便,可用于对网卡上的流量进行分析和统计,从而得到流量特征信息。
根据人们日常生活习惯,本文选取了在电脑端和智能电视端常用的占据带宽较大的几类应用作为抓包分析的对象。选取的应用有:QQ视频聊天、无线传屏和VOD视频点播等。其他一些常用的网络应用如E-mail、QQ文字聊天等由于占据带宽有限,不会对整个网络的性能造成明显影响,不作为本文的研究对象。
本文采用五元组信息(包括源IP地址、目的IP地址、源端口号、目的端口号和协议类型号五个信息)、上行流量包长、下行流量包长、上行流量包数、下行流量包数作为识别特征。这些信息不一定要单独使用,可以进行组合处理得到更适合识别的新的数据形式[3-5]。
下面将分析采用上述几种信息作为识别特征的可行性,最后得到用于编程识别的几种特征。
1)五元组信息的可行性分析。五元组信息是抓包数据中最重要的信息,一个五元组能够唯一地确定一个网络会话。所以,如果在抓包过程中发现某应用始终采用某一固定的IP地址或者端口号,则可以用五元信息作为识别特征,准确地识别该应用。
2)包长信息的可行性分析。包长同样是封包数据中十分重要的信息,但是单独一个或几个包的包长难以体现出某类应用的总体特征,可在编程部分设置一个定时器,统计在一段时间内包长之和,即这段时间内流量的数据量。另外,考虑到数据量的大小受网络条件的影响较大,本文采用的处理方法为:分别统计一段时间内上行流量和下行流量的数据量,然后以下行数据量/上行数据量作为最终的识别特征。该信息还能比较明确地显示出该应用的数据流向。
3)包数信息的可行性分析。为较好地体现不同应用的特征,参考包长信息的处理方式,包数信息的使用也采用同样的处理方式,以下行包数/上行包数作为最终的识别特征。为得到各类应用的特征,本文采取的抓包方式是每天早上、下午和晚上分别对某一应用抓包三次,连续抓包两周,最后将得到的数据统一分析,得到各类应用的特点[6],总结见表1。

表1 各类应用的特征总结
通过分析这些特征,综合考虑识别的准确度和编程的难度,本文采取的识别方法为:在接收到封包并对封包信息进行分析后,首先对封包的远端端口进行判断,如果该端口为16 000或50 021,则可直接识别为QQ视频聊天或无线传屏应用;然后设置定时器,每隔20秒对还未识别的流量上下行数据量进行统计,如果下行数据量/上行数据量大于20,则判定为VOD视频点播。
由于智能应用市场发展十分迅速,每天都会出现新的应用,为了程序的适应性并为未来能够识别更多的应用作准备,本文将识别条件写为正则表达式的形式存放在数据库的表中,在识别时对正则表达式进行一一匹配。这样当需要识别新的应用时,只需根据新应用的特点写成新的正则表达式添加到已有的表中,识别流程不需要进行改动。
2 后台流量统计与识别系统的实现
经过第1章的抓包分析工作,各类应用的流量特征已经基本确定,本章的工作是根据这些特征编程实现流量的统计与识别功能,识别环境为Linux,流量特征和识别结果均通过数据库存放。
2.1 系统框架
本系统的框架如图1所示,分为后台管理系统和Linux下的流量识别两部分,通过数据库进行交互。下面将对后台管理部分和流量识别部分的原理分别进行详细的分析。

图1 系统框架图
2.2 后台管理子系统
后台管理系统的结构如图2所示。下面将详细分析该系统的工作原理。
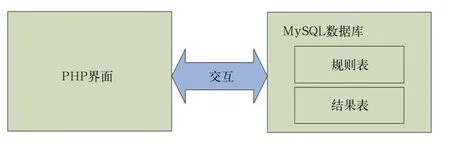
图2 后台管理系统结构图
MySQL是一个关联式数据库管理系统,由于它体积较小、运行速度快、源码开放等优点而被广泛应用于中小网站的开发中[7-8]。本文同样选择MySQL数据库作为工作数据库。
1)规则表。规则表用于存放识别各类应用的正则表达式,它的结构如表2所示。其中order_number为规则表的主键,AppID为各类应用的序号,regular_expression为应用的正则表达式,用于识别路由器上的流量是否符合某一类应用的特征。
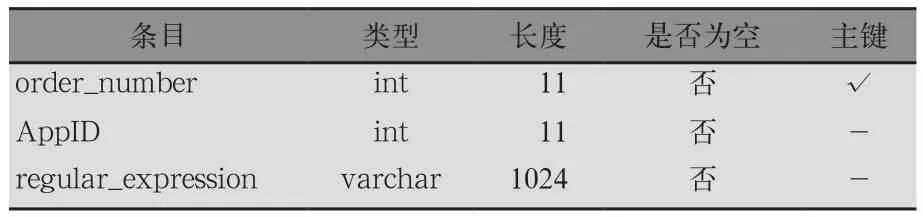
表2 规则表结构
正则表达式是一种逻辑公式,是用已经定义好的一些某些特定字符或字符组合组成的一个“规则字符串”。这个“规则字符串”的作用是用来匹配某个字符串,检查该字符串是否符合这个“规则字符串”的规则[9]。
2)结果表。结果表用于在成功识别某应用后存储其五元组和其他信息,它的作用是在识别开始时首先将未知流量与已经识别过的结果进行匹配,如果匹配成功则直接识别为已有应用类型,避免进行重复识别,降低效率。另外,结果表中的标志符current_run_flag用于标识目前正在进行的应用,并将该信息传递给PHP界面。
结果表的结构如表3所示。其中order_number为结果表的主键,AppID为各类应用的序号,local_ip、remote_ip、local_port、remote_port、protocolID为封包的五元组信息,current_run_flag为标识符,当值为1时表示该应用正在运行,每20秒会对所有记录的标识符进行清零。

表3 结果表结构
2.3 流量识别子系统
流量识别子系统的编程环境为Linux系统,工作流程如图3所示。下面将对系统的运行过程进行详细的分析。
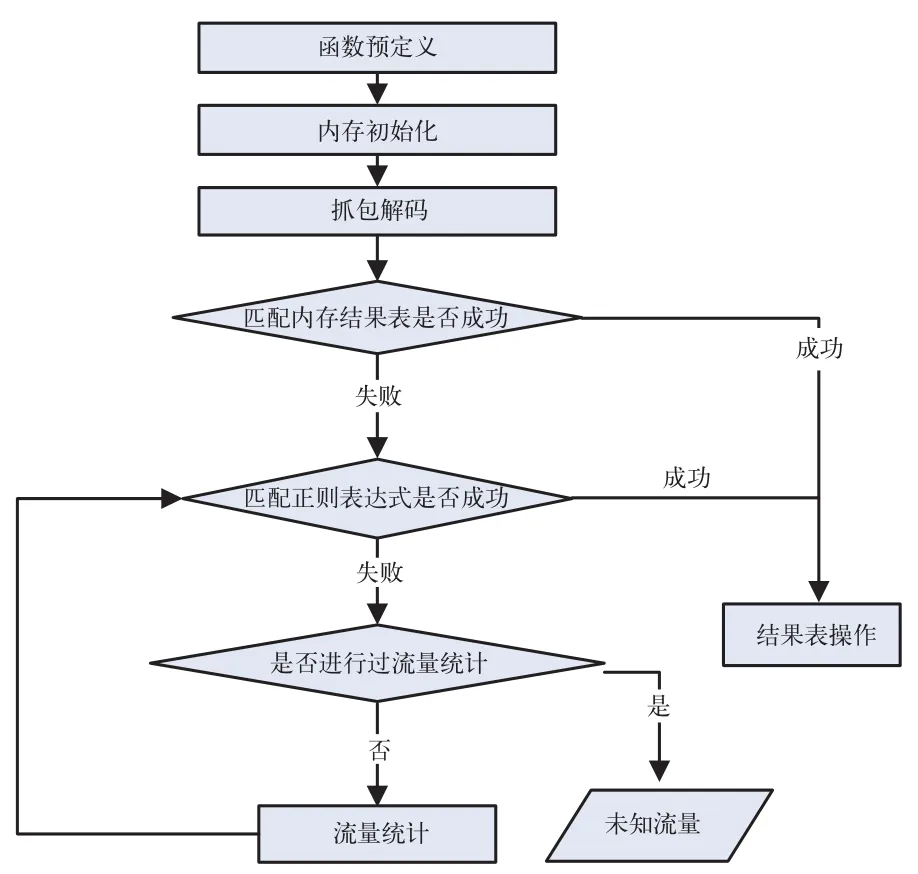
图3 流量识别子系统流程图
在函数预定义的过程中定义了结果表链表头指针和规则表链表头指针两个全局变量,在初始化时使用结果表初始化函数,将数据库中结果表信息存入结果表链表,同时使用规则表初始化函数将规则表信息存入规则表链表。两个链表将用于后面的封包匹配。
抓包解码时主要使用的是入侵检测系统Snort。这是一个用C语言开发的,开放源代码的网络入侵检测防御系统,能够进行实时流量分析和网络数据包记录。用于截取网络流量中的数据包,分析其中的内容并将里面的信息存入流量特征信息结构体中,用于后续的流量识别部分[10]。
下一步进入流量识别的关键步骤,将得到的封包进行识别。
根据图3所示的流量识别流程图,对一个封包进行一次完整的匹配分为以下三步,每次匹配成功后需要对结果表进行相应的操作。
1)匹配结果表信息。将当前流量特征信息结构体的五元组与结果表五元组进行匹配,如果匹配成功,则说明该结果在之前已经被成功识别过,直接将相应结果表消息的Flag位设为1,表示该应用正在进行;如果不成功,继续进行正则表达式的匹配。
2)匹配正则表达式。由于结果表匹配不成功,说明该结果在之前没有被识别过,需要使用正则表达式进行匹配。正则表达式就是从数据库的规则表中取出的逻辑公式,用于检查该结果是否符合某类应用的特征。如果匹配成功,则将该条结果的识别记录增加到结果表中,并同时将Flag位设置为1,表示该应用正在进行。
3)流量统计。对于VOD视频点播的识别需要对一段时间的上下行流量比进行统计计算。在每种五元组的起始流量包到来时记录起始时间,每次来一个相同五元组的流量包时,对其上下行流量分别进行累加,存入流量统计链表。每隔一段时间将统计后的信息输出,用于再次进行正则表达式的匹配。
除了流量统计,定时器的另一个作用是判断应用是否正在进行。每隔一定时间,读取一次系统时间,与结果表链表中某结果的最后一次更新时间相减,如果间隔超过默认设置的时间,则判定为此段时间内没有该应用的新包到来,将标志位Flag设置为0,表示该应用已经停止运行。
3 Socket通信模块
前面已经实现了流量的统计与识别功能。这部分通信模块的设计目的是将该功能移植到网关上,网关部分只负责收包和识别,而后台部分暂时负责数据库的管理和识别结果界面等,随着后续开发的进行,后台将会承担更多的功能,使系统更加智能。这样就需要增加网关和后台系统之间的通信机制。本文采用的通信方式是Socket通信,为TCP方式。
3.1 通信模块框架
1)网关侧处理流程。网关侧处理流程如图4所示。在网关开始识别功能前,首先要向后台发送注册请求,只有在得到后台允许注册的回复后才能正常工作。然后根据从后台收到的规则表和结果表对封包信息进行匹配,如果匹配成功,将结果表更新,并将识别后的结果传到后台。2)后台侧处理流程。后台侧处理流程如图5所示。在每次收到网关侧的包时,首先判断该网关是否已经注册,如果未注册则丢弃该包。每次收到网关侧的识别结果后,将后台的结果表进行刷新。
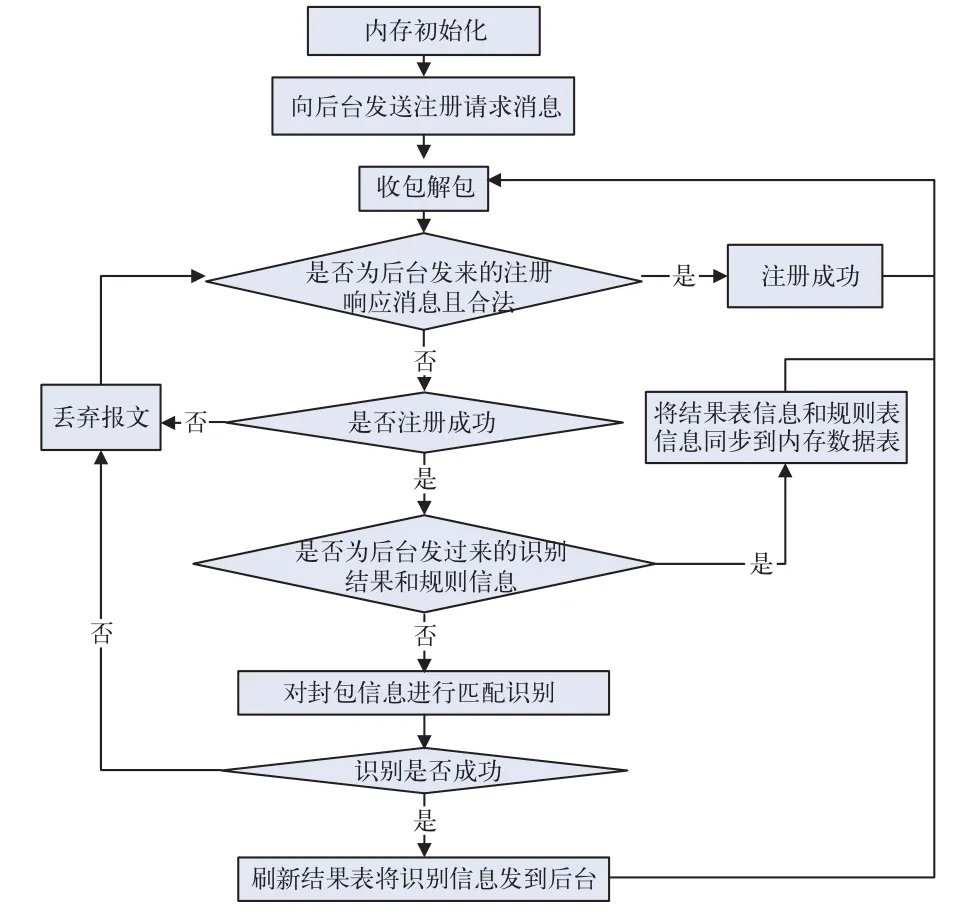
图4 网关侧处理流程图
3.2 通信模块工作原理
Socket又称“套接字”,用于网络进程之间的相互通信,应用程序通过Socket向网络发出请求或接收网络请求。服务器端与客户端通过Socket建立连接后,可以调用IO函数进行读写操作。在阻塞模式下,网关侧或后台侧调用IO函数收发信息都需要等待对方的回应,在此期间系统不能进行其他工作,这样的工作方式不符合通信模块的工作流程且效率很低;因此,通信模块在信息收发时均调用select函数使其工作在非阻塞方式之下,通过函数的返回值判断在缓冲区是否有新的信息,然后根据消息ID进入相应的处理流程。本文通信模块的消息处理流程如图6所示[11-13]。
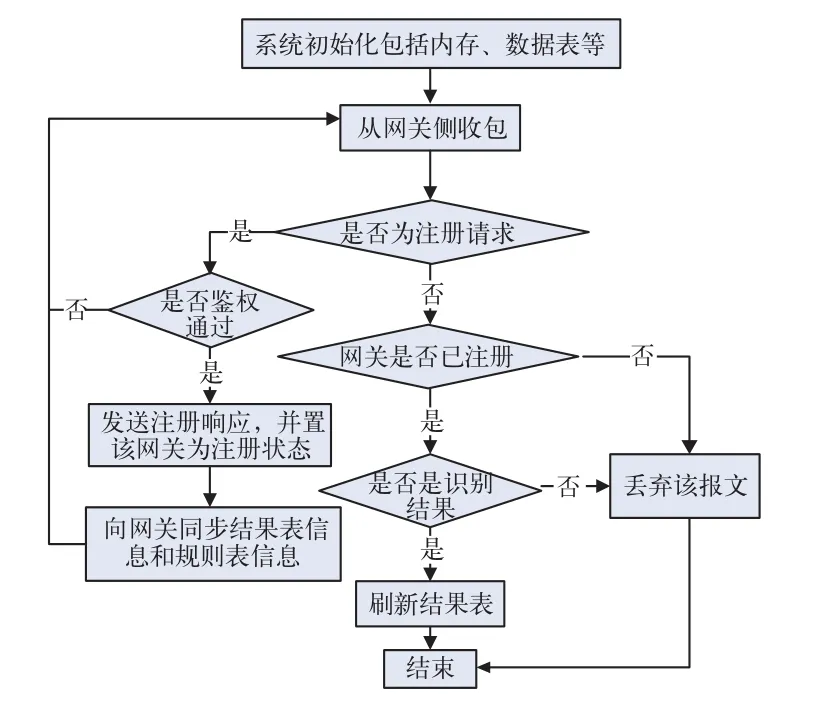
图5 后台侧处理流程图
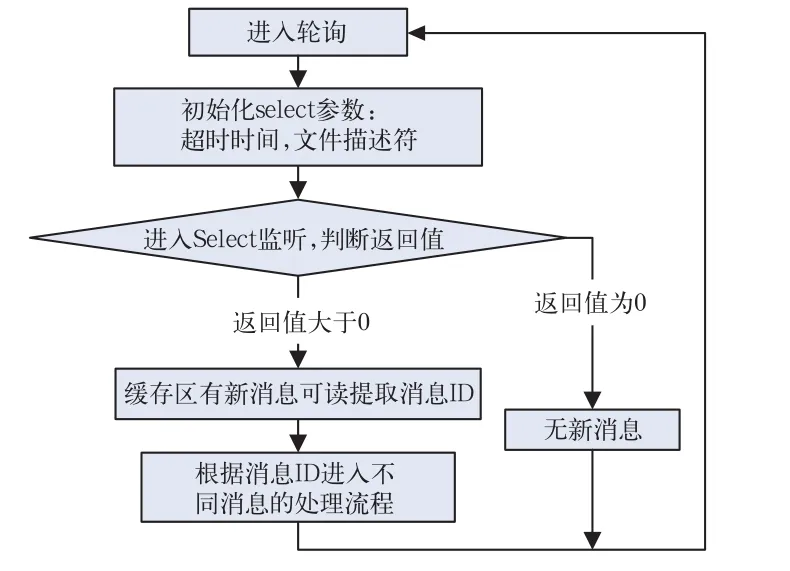
图6 通信模块消息处理流程
4 识别结果
流量识别系统识别成功后,识别结果被写入数据库的结果表。每条结果信息的内容包括:识别结果ID、本地IP地址、远端IP地址,本地端口号、远端端口号、协议类型号。结果信息的内容与2.2节后台管理子系统中描述的结果表结构相对应,此处不再详述。
5 结束语
在对家庭生活中的常用应用进行汇总分类时,本文只选取了其中占据带宽较多的几类应用,其他占据带宽有限的应用不作为本文的研究对象。本文的识别方法能够对家庭成员的网络活动进行较为准确地识别,在此基础上,下一步的计划是QoS管理系统的实现。对各类应用的优先级进行设置,在网络带宽有限的情况下,优先级低的应用不能影响优先级高的应用的运行,采用这样的方式尽量保证家庭成员的重要业务能够顺利进行。
[1]朱川,韩光洁.家庭网关平台与IMS融合技术[M].北京:科学出版社,2012:5-20
[2]薛家勇.嵌入式Linux家庭网关系统研究与实现[D].西北工业大学硕士学位论文,2005:1-4
[3]高彦刚.实用网络流量分析技术[M].北京:电子工业出版社,2009:8-18
[4]郭明亮.高速网络中实时流量识别系统的研究与设计[D].北京邮电大学硕士学位论文,2010:1-6
[5]左建勋.网络流量识别技术研究及其应用[D].重庆大学硕士学位论文,2007:2-8
[6]Chris Sanders.Practical Packet Analysis:Using Wireshark to Solve Real-World Network Problems (2nd Edition)[M].USA:No Starch Press,2009:3-89
[7]潘景昌,刘杰.操作系统实验教程(Linux版)[M].北京:清华大学出版社,2010:59-72
[8]吉尔摩.PHP与MySQL程序设计[M].朱涛江,译.北京:人民邮电出版社,2011:372-410
[9]Jan Goyvaerts.Regular Expressions Cookbook[M].USA:O'Reilly Media,2009:8-103
[10]李凤霞.C语言程序设计教程[M].北京:北京理工大学出版社,2008:246-268
[11]W.Richard Stevens.TCP/IP详解卷1:协议[M].北京:机械工业出版社,2000:313-349
[12]丁国华,胡荣强.Linux的Socket编程及其在嵌入式网关中的应用[J].电子元器件应用,2004,6(10):1-4
[13]W.Richard Stevens.UNIX网络编程(第1卷)[M].北京:清华大学出版社,2010:47-149
