在线评测系统中的源码相似度检测研究与实现
2014-05-02陈荣钦胡永良应建健郭贤海
陈荣钦,胡永良,应建健,郭贤海
(台州学院 计算机应用研究所,浙江 临海 317000)
在线评测(online judge,OJ)系统[1]是为 ACM 国际大学生程序设计竞赛而设计的程序源码评测系统。OJ系统通常用Web浏览器将用户的源码提交至服务器,并在服务器端编译、运行程序,再通过预先给定的测试数据对程序进行检测,然后将结果反馈至客户端,整个过程全部由计算机自动处理,因此在国内外程序设计竞赛中被广泛采用。知名的OJ系统有Timus OJ[2]、ZOJ[3]、POJ[4]、HDOJ[5]等。
OJ系统的自动处理机制使其非常适合于程序设计类课程的实践教学,但高校存在的抄袭现象阻碍了OJ系统在教学中的应用。研究表明,源码抄袭与论文剽窃在高校教学过程中时有发生,并有不断增长的趋势[6-8]。由于 OJ系统的代码提交量往往较大,如HDOJ的年提交量在100万以上,且呈加速增长趋势,手工检测根本无法完成,因此迫切需要有高效的源码自动检测方法。
1 相关工作
源码检测属于文本匹配范畴,文本匹配算法广泛应用于生物技术、信息检索、语言翻译、入侵检测等领域,主要有前缀搜索、后缀搜索、子串搜索等类型。
文本匹配问题可以描述为:给定一个文本串T[1,2,…,n]和一个模式串P[1,2,…,m],其中m≤n,且T[i]和P[j]均属于字母表∑。若存在s,使得T[s+1,s+2,…,s+m]=P[1,2,…,m]成立,则说明模式串P在文本串T中出现,且位移为s,其中0≤s≤n-m。文本匹配的研究已经较为成熟,代表性的算法有Rabin-Karp、KMP、有限自动机、BM 和 Sunday等算法[9]。在实际应用中,Rabin-Karp算法的平均复杂度为O(n+m),通常应用于单个模式串在多个文本串中的匹配问题中。KMP算法和有限自动机的复杂度稍好,达到O(n),BM算法和Sunday算法的平均时间复杂度为O(n),最坏时间复杂度为O(nm),但对于短模式串的匹配问题,Sunday算法执行速度较快。
单纯的文本匹配算法不能直接应用于源代码匹配中,因为抄袭者只需通过文本替换功能修改变量名、函数名等即可使字符串匹配的相似度大大降低,因此还需要针对源码的特点设计更好的算法,常见的方法有属性计数法(attribute counting method)和结构度量法(structure metric method)。
1.1 属性计数法
属性计数法通过提取两段代码中的运算符、操作数、行数、字符数、程序注释等相关属性的数量,并将它们表示为N元组,对N元组进行规范化,并计算它们的欧几里得距离,由此来判断源码的相似度。欧几里得距离计算如公式(1)所示:
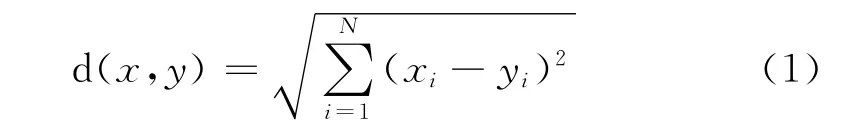
其中x和y分别是N 元属性组,分别表示为(x1,x2,…,xN)和(y1,y2,…,yN),该方法的缺点是如果抄袭者加入一些多余的关键字、变量甚至一些冗余的源码,系统便很难检测[10],而对于不属于抄袭甚至完全不相关的源码,由于属性个数相近的原因可能存在较大的误判概率。
1.2 结构度量法
结构度量法从程序的结构上进行分析,避开了任何冗余代码,主要分2个步骤:(1)首先对源码进行词法或语法分析并产生符号序列,在此过程中将同义词映射为统一的形式,将自定义的标志符转换为标准符号,删除空白符号和注释,将大写字母转化为小写等;(2)采用相关字符串匹配技术两两比较前面产生的符号序列,并求出其相似度[11]。该方法可以有效克服属性计数法带来的问题,因此在实际过程中应用更为广泛,如 Sim[12]、JPlag[13]、YAP3[14]和 MOSS[15]等。
在OJ系统中,由于系统要承担源码正确性实时检测的任务,因此服务器负载很重。而代码相似度检测的负载则更重,因为提交的每个源码都需要与原有的所有源码进行比较,因此单纯的字符串匹配算法不可能满足实时检测的需求。
2 OJ系统中的源码检测过程
OJ系统源码检测过程主要包括给定检测条件、查询源码、预处理、相似度检测、统计检测信息等部分,如图1所示。
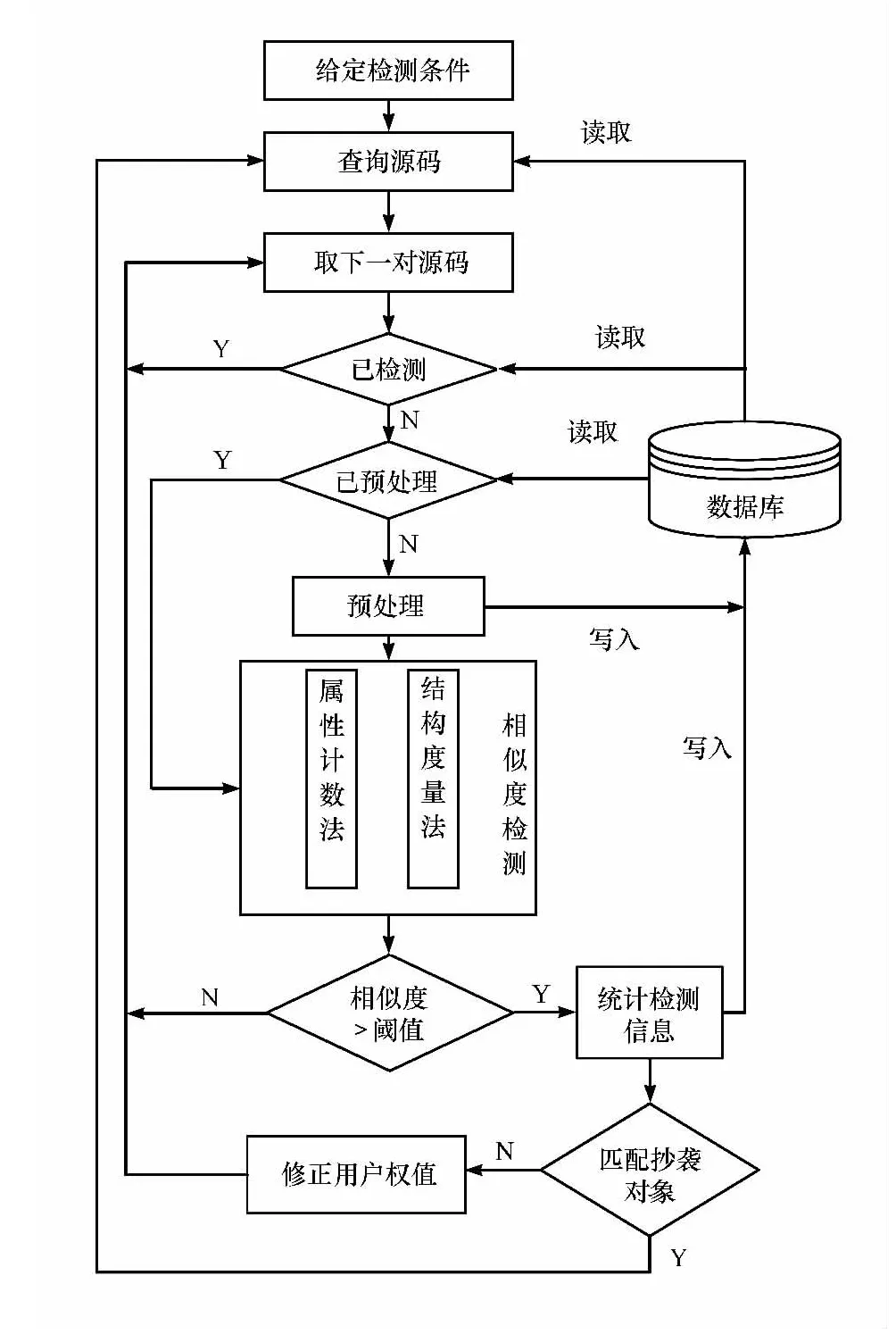
图1 OJ系统中的源码检测流程
2.1 给定检测条件进行源码查询
源码保存在OJ系统的服务器端数据库中,可以随时调取。在调取源码时,可以设定相关的条件,避免不必要的检测,如忽略较短的源码,只在指定的班级中、某次竞赛或考试中调取,只在2个用户之间进行匹配等,也可以设定在服务器负载轻的夜间自动启动对当天的源码进行抄袭检测。
2.2 预处理
预处理阶段针对采用的相似度检测算法,对源码进行适当处理,以便更有效地进行相似度检测。针对属性计数法可以删除源码中的空行、空白字符、注释语句、双引号中的文字等与代码相似度无关的度量,同时记录相关的属性个数,如标志符、常量、数字等;针对结构度量法将源码根据结构进行转化,形成相应的标记流(token stream);预处理得到相关数据根据需要将其直接存入数据库,待下次检测时直接取出,节省了预处理的时间。
2.3 相似度检测
相似度检测部分可以根据需要选择属性计数法或结构度量法。前者效率较高,但容易被学生通过加入冗余代码降低相似度,可以用于检测不经修改便提交到系统中的低级抄袭现象,在教学过程中的初始阶段采用较为有效;结构度量法因为可以对程序的内部结构和控制流进行分析,因此精确度较高,可以在教学的后续阶段使用(一般针对少部分擅长投机取巧的学生)。由于Rabin-Karp支持多模式匹配(multiple pattern match)的特点,因此在结构度量法中采用Rabin-Karp算法进行字符串匹配。属性计数法处理过程为:
(1)只保留源码中数字、字母和可见符号;
(2)滤除注释语句以及双引号内部文字;
(3)对源码进行词语分割,统计出基础属性数目,主要包括:n1(操作符种类)、n2(操作数种类)、N1(操作符总数)和N2(操作数总数);
(4)定义词汇量n=n1+n2,长度N=N1+N2,再根据词汇量和长度定义容量V=N·Log2(n),最后将这些信息组合成一个特征向量H(n,N,V)。通过计算所比较程序对的特征向量之间的距离进行相似度检测,距离越小则相似度越高。结构度量法处理过程为:
①先对源码进行词法或语法分析,将同义词映射为统一的形式,将所有用户自定义标志符转换为特定的符号,删除空白和注释字符,将大写字母转化为小写,最终形成标记(token)串。其中的字符串T=T1T2,散列函数设计如公式(2)所示
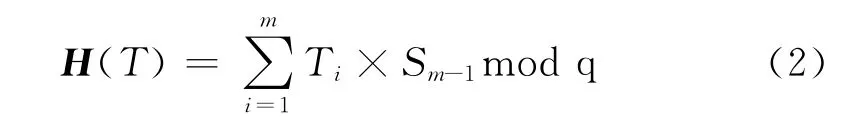
其中Si=di,d为源码字符集合的长度,q为一个较大的素数。
② 采用Rabin-Karp对标记流进行两两比较,在比较过程中,字符串的比较转化为了散列值的比较,该方法使得算法的时间复杂度可以达到O(n),因此提高了比对效率。
2.4 统计检测信息
相似检测的结果如果大于设定的百分比阈值,则认定抄袭。由于在实际教学过程中,抄袭现象往往发生于2个用户之间,并且用户抄袭的源码往往是批量的,因此系统在检测过程中对“用户对(即指抄袭的双方用户)”进行计数,并同时统计双方用户各自的抄袭频率,优先调取频率较高的用户进行检测。若“用户对”的抄袭次数高于设定的阈值,将智能地对该“用户对”进行源码的完全检测,以便于进一步确认该“用户对”是否存在大量抄袭。检测的结果存入数据库,可以作为教师扣除学生积分的依据,从而有效地控制了抄袭现象。
3 结果分析
通过给定相关条件从OJ系统中抽取若干组源码进行比对测试,属性计数法的分析时间远远大于检测时间,因此通过缓存预处理信息的方式可以大大提高源码检测效率,完全可以达到实时处理(平均每秒钟约检测5000组源码),如表1所示。结构度量法的预处理时间与检测时间较为接近,因为两者的处理效率均为O(n),缓存预处理信息也能提高一倍(如表2所示)。
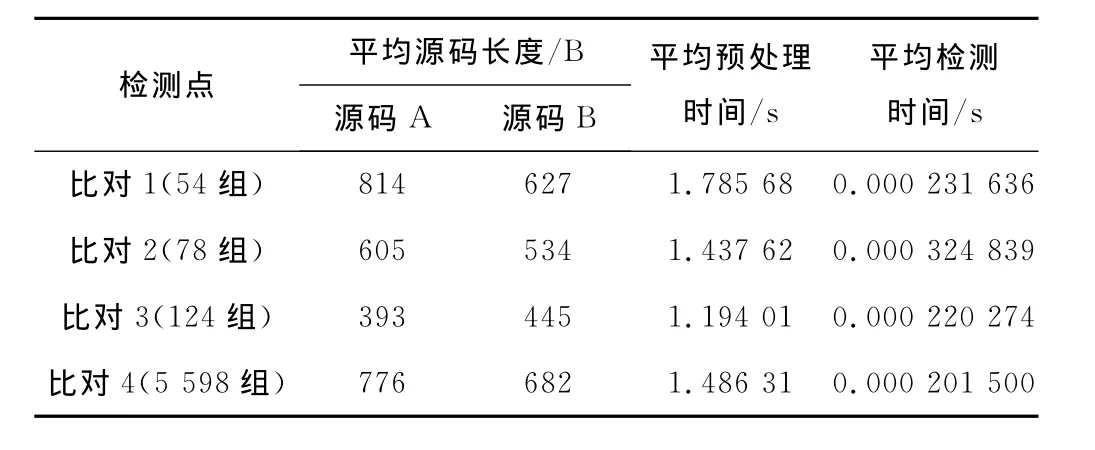
表1 属性计数法性能分析

表2 结构度量法性能分析
4 结论
本文结合OJ系统的特性,采用属性计数法与结构度量法相结合的方式对OJ系统的源码进行了相似度检测,通过缓存方式提高了检测效率。检测过程中通过动态调整用户的权值来修正检测模型,以便于更有效地控制用户抄袭行为。实验表明,该方法能较为有效地检测OJ系统的源码相似度。同时,该检测方法已应用到台州学院在线程序设计综合平台(http://acm.tzc.edu.cn),检测效果良好,有效控制了本校学生的抄袭现象。
(
)
[1]Kurnia A,Lim A,Cheang B.Online Judge[J].Computer & Education,2001(36):299-315.
[2] Timus Online Judge[EB/OL].[2013-07-11].http://acm.timus.ru.
[3]Zhejiang University Online Judge[EB/OL].[2013-07-10].http://acm.zju.edu.cn.
[4]Peking University Online Judge[EB/OL].[2013-07-10].http://poj.org.
[5]Hangzhou Dianzi University Online Judge[EB/OL].[2013-07-10].http://acm.hdu.edu.cn.
[6]Bull J,Collins C,Coughlin E,et al.Technical Review of Plagiarism Detection Software Report[R].CAA,University of Luton,2001.
[7]Culwin F,MacLeod A,Lancaster T.Source code Plagiarism in UK HE Computing Schools,Issues,Attitudes and Tools[R].Technical Report No.SBU-CISM-01-02,South Bank University,2001.
[8]Sheard J,Dick M,Markham S,et al.Cheating and Plagiarism:Perceptions and Practices of First Year IT Students[C]//In Proceedings of the 7th Annual Conference on Innovation and Technology in Computer Science Education,Aarhus,Denmark,ACM Press,2002:183-187.
[9]Singla N,Garg D.String Matching Algorithms and their Applicability in various Applications [J].International Journal of Soft Computing and Engineering(IJSCE),2012:218-222.
[10]Verco K,Wise M.Software for Detecting Suspected Plagiarism:Comparing Structure and Attribute Counting Systems[C]//In Proceedings of Australian Conference on Computer Science Education,Sydney,Australia,1996:81-88.
[11]Arwin C,S.M.M.Tahaghogh.Plagiarism Detection across Programming Languages[C]//ACM International Conference Proceeding Series,Proceedings of the 29th Australasian Computer Science Conference,Hobart,Australia,2006(48):277-286.
[12]Gitchell D,Tran N.Sim:A Utility for Detecting Similarity in Computer Programs[C]//In Proceedings of the Thirtieth SIGCSE Technical Symposium on Computer Science Education,ACM Press,1999:266-270.
[13]Prechelt L,Malpohl G,Philippsen M.Finding plagiarisms among a set of programs with JPlag[J].Journal of Universal Computer Science,2002(8):1016-1038.
[14]Wise M J.Detection of Similarities in Student Programs:YAP’ing May be Preferable to Plague’ing[C]//ACM SIGSCE Bulletin(Proc.of 23rd SIGCSE Technical Symp),1992(24):268-271.
[15]Aiken A.MOSS(Measure of Software Similarity)Plagiarism Detection System[EB/OL].http://www.cs.berkeley.edu/moss/.University of Berkeley,CA.
