基于元音共振峰特征的法庭说话人识别
2014-04-27王华朋李宁许锋蔡能斌
王华朋李 宁许 锋蔡能斌
(1 中国刑警学院 辽宁 沈阳 110035;2 上海市公安局物证鉴定中心 上海 200135)
基于元音共振峰特征的法庭说话人识别
王华朋1李 宁1许 锋1蔡能斌2
(1 中国刑警学院 辽宁 沈阳 110035;2 上海市公安局物证鉴定中心 上海 200135)
在似然比证据评估体系下研究元音的共振峰特征在法庭语音证据强度评估中的应用,提供了似然比计算方法,并在包含42人语音的数据库中对法庭说话人识别系统的性能及可靠性进行了检验。结果表明:使用共振峰特征的法庭说话人识别系统,在只使用一个元音的情况下具有良好的识别率。该方法不仅能正确识别说话人,而且能根据当前语音证据的差异,量化该语音样本作为证据的力度,为法庭提供科学合理的证据评估结果。
共振峰 似然比 法庭说话人识别
1 似然比方法概述
法庭科学家早在20年前就已经意识到了简单的“认定/否定”所带来的负面问题,因此都在探索更好的评判证据价值和表述检验结论的方法。目前,使用似然比方法的DNA证据及分析模式已经普遍为世界各国法庭所接受。因此,国外一些专家尝试效仿DNA技术,将似然比方法应用于其他法庭证据,如玻璃、油漆、语音和指纹等,并且进行了大量的测试和评估。澳大利亚、英国和欧洲一些国家的学者提出在鉴定结论的表述和价值评判上引入了似然比方法。在法庭证据评价体系中利用似然比方法评判证据力度是一种科学有效的评价方法。该方法通过比较检材和样本的相似度,计算两者的似然概率,同时以经验背景数据(先验概率)为参考,最后得到支持起诉假设(认定同一)的后验概率。似然比方法适用于多种法庭证据,如DNA、玻璃、油漆、语音等,并且各种证据的似然比还可以合并,进行综合评价。似然比方法有利于更科学地评判法庭证据的价值,供法官客观科学地判断和采信证据,对于完善证据检验鉴定体系具有重要意义。
2005年,美国亚利桑那州立大学的教授M.J.Saks和J.J.Koehler在《Science》上撰文指出,法庭识别科学正在向一个新的证据评估体系发展。2009年,澳大利亚新南威尔士大学的教授G.S.Morrison在《science& Justice》上撰文指出,在法庭语音比对领域,目前正处于新旧证据评估模式的转换进程中,明确指出了似然比证据评估体系的科学性,是未来法庭证据评估的发展方向。澳大利亚、英国和欧洲其他一些国家的法庭科学家也提出在法庭证据的检验和评估上应该借鉴DNA检验的成功做法,引入基于贝叶斯理论的似然比证据评估体系。该体系不仅可以对证据价值进行量化评价,还可以测试分析技术及方法的可靠程度和准确程度,因此,被科学界公认为是目前最科学、最正确和最符合逻辑推理的法庭证据评估方法。
2 似然比在法庭证据中的解释
目前,在国际法庭说话人识别研究中,似然比是最重要的组成部分,因为它可以量化证据对鉴定结论支持的力度。似然比可以表示成在一个给定的假设条件下观测到犯罪证据(罪犯和嫌疑人样本间的声学差异)的概率和在完全相反的假设条件下观测到犯罪证据概率的比值。因此,它们的比率就是当前语音证据支持同一人的假设和支持不是同一人假设的相对强度,强度的大小反映在似然比的幅度上。如果似然比的值等于1,那说明该证据对两个相反的假设支持的力度是一样的,故不具有证据意义。似然比和1的大小关系表明,当前的语音证据支持是同一人的假设还是非同一人的假设,似然比的值并不是真相的二值表示。也就是说,对于嫌疑人样本和罪犯样本是不是由同一人产生的这一问题,似然比并没有给出“是”或“否”的回答,它只是量化了当前语音证据对鉴定结论支持的强度。如果用P来表示概率,E表示证据,H代表假设,那么似然比(LR)可写成下面的形式:
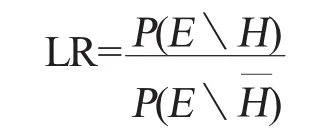
在法庭说话人识别中,似然比的分子量化了罪犯样本和嫌疑人样本之间相似的程度,其分母量化了罪犯样本和嫌疑人样本在参考人群里的典型性。如果罪犯样本和嫌疑人样本越相似,它们来自同一人的可能性就越大,似然比的值也就会越大。然而,这个结果还需要样本的典型性来平衡。这两个样本越是典型,它们就越可能是从人群中随机抽取的,似然比的值就会越低。因此,似然比的值是样本的相似性和典型性相互作用的结果,贝叶斯理论明确指明,相似性和典型性对证据评估来说都是必不可少的。事实上,在实际工作中,我们经常会忽视样本特征的典型性,认为仅仅相似性对证据同一认定就足够了,这是不正确的做法。
如果提取的特征为单个特征,即使用单变量计算似然比,则可采用Lindley提出的公式,详见参考文献[11];如果特征为多变量,则可采用Aitken和Lucy提出的多变量核密度的似然比计算方法,详见参考文献[12]、[13]。
3 共振峰的概念及其应用价值
共振峰是指在声音的频谱中能量相对集中的一些区域,共振峰不但是音质的决定因素,而且反映了声道(共振腔)的物理特征。在语音声学中,共振峰决定着元音的音质,也可以反应说话人的个性特征。
在法庭话者鉴别中,共振峰作为话者区分的最稳定的参数,一直都是备受重视的。语音的个体特性更多地体现在高频区,但是受到实际案件条件下电话等传输带宽的限制,高频语音成分很难保留,低频区元音的F1测量也不太可靠。因此,话者区分测试往往集中在第二和第三共振峰上。由于男性语音元音/a/的第一共振峰大概分布在800Hz左右,因此,第一共振峰的数据也是可以应用的。
4 实验结果
为了验证结果的稳定性,本文采用42人电话数据库,是由42人在不同时间段录制的电话对话录音,该录音从磁带被数字化以后,以16位的PCM格式声音文件保存,采样频率为11025Hz。对话中采用的是汉语普通话,参与者年龄都在20岁左右。由一位引导人询问他们相关的个人信息,由他们依次作答。本文选取了“啊”作为分析的对象,提取元音/a/进行分析。选取“a”作为分析对象还有另外一个优点,因为人们经常对其进行重读,因此其中的元音/a/发音比较饱满,能较好地反映个体的声道特征。
在似然比结果的讨论中,似然比经常以10为底的对数值表示,因为在对数域,越大的正数为同一人假设提供越大的支持力度,越大的负数则为不同人假设提供越大的支持力度。例如,对数似然比+1表示在当前的语音证据条件下,它们来自同一人的概率是来自不同人概率的10倍;对数似然比-1表示,在当前的语音证据条件下,它们来自不同人的概率是来自同一人概率的10倍。
图1为只使用第一共振峰F1作为识别结果时的Tippett图,左上较粗的曲线表示不同说话人的对数10似然比大于等于x轴刻度的样本所占的比率;右上较细的曲线表示同一说话人对数10似然比小于等于x轴刻度的样本所占的比率。两曲线相交的点为等误差点,可以用来判断该鉴别系统的好坏。图中的竖线为识别阈值,似然比的识别阈值为1,取对数后为0,最理想的情况就是粗线和细线和阈值都没有交点,同一说话人和不同说话人都达到100%的识别率。等误差点的数值越小,说明该说话人识别系统的性能越高。在图1中,系统的等误差率在0.2与0.3之间,使用的似然比计算方法为单变量的似然比计算方法。
如果将F1、F2和F3进行融合,即假设它们之间是相互独立的,是统计无关的特征,把F1、F2和F3的单独的似然比计算结果进行相乘,得到一个使用前三个共振峰特征的似然比的值,结果见图2所示。系统的识别性能得到明显的提高,等错误率降到0.1之内。
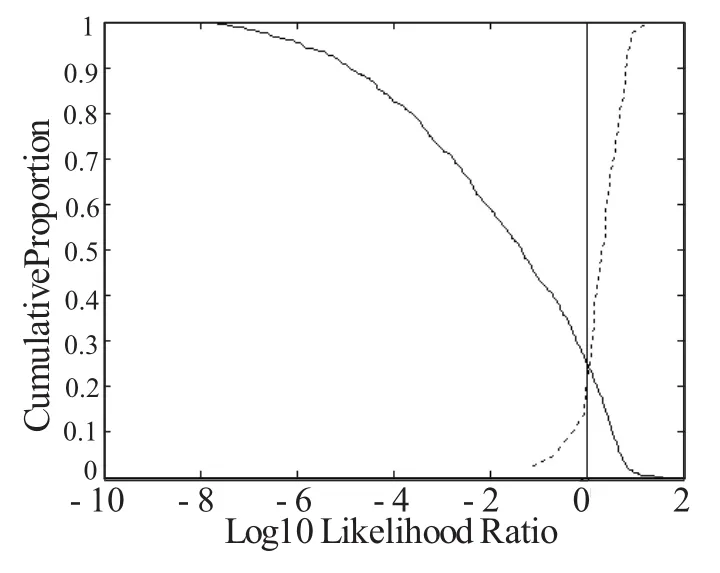
图1 特征为F1时的Tippett图
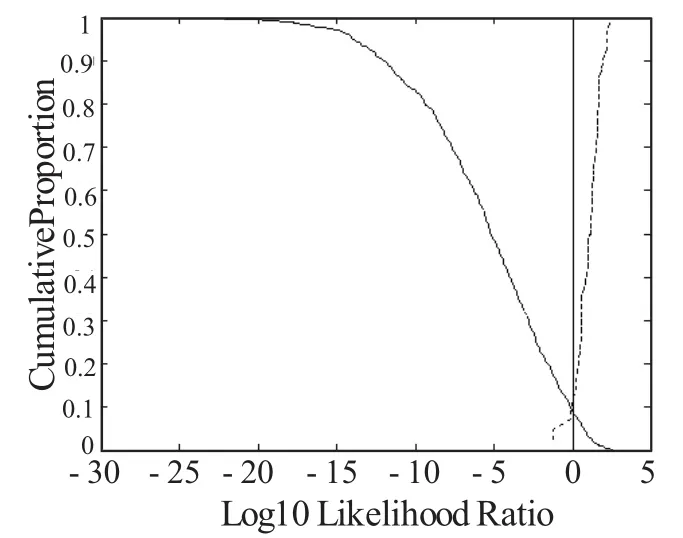
图2 F1&F2&F3融合的Tippett图
图3为使用MVK的方法计算似然比结果的Tippett图,系统的识别性能也比单独使用一个特征时要好,等错误率降低到0.1以下。
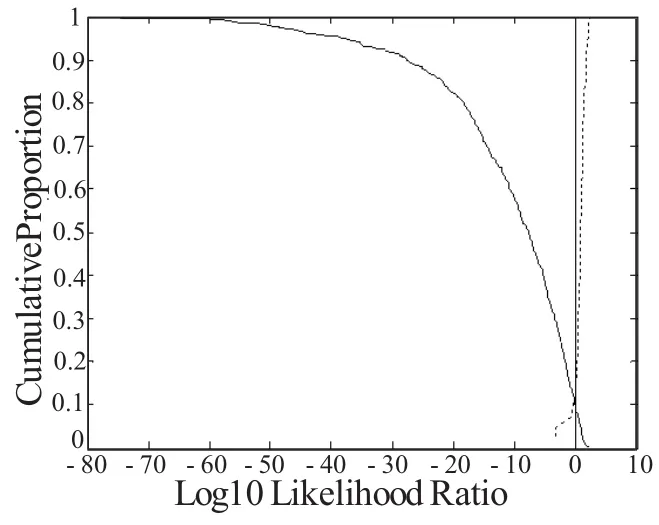
图3 基于MVK方法的Tippett图(F1&F2&F3)
5 结论及讨论
本文通过对42人数据库的测试,使用共振峰特征作为识别参数,取得了较高的正确识别率共振峰作为识别特征,具有很好的鲁棒性和稳定性,受信道和噪声的影响较小,具有其他数字特征所没有的稳定性好的优势,并且具有明确的物理意义。实验结果表明,通过分析共振峰的相关特征进行似然比计算的方法是法庭说话人识别的一个科学有效的方法,能大大提高识别的准确率,并且量化了证据的强度。本文仅使用了每个人的元音/a/,我们还可以使用更多数量的元音和特征,然后融合这些证据,获得一个全局证据力度,进一步提高识别结果的可靠度。
[1]Morris on G S, Zhang C, Rose P.An empiricalestimate ofthe precision oflikelihood ratiosfrom a forensic-voice-comparison system[J].Forensic science international,2011,208(1).
[2]Saks M J,Koehler J J.The coming paradigm shift in forensic identification science[J].Science,2005,309(5736).
[3]Morrison G S.Forensic voice comparison and the paradigm shift[J].Science&Justice,2009,49(4).
[4]Rose P, Morrison G.A response to the UK position statement on forensic speaker comparison[J].The international journal of speech,language and the law,2009,16(1).
[5]Zhang C, Morrison G S, Rose P.Forensic speaker recognition in Chinese:a multivariate likelihood ratiodiscriminationon/i/and/y/[A].INTERSPEECH[C]. Brisbane,Australia:The DBLP Computer Science Bibliography,200.
[6]Drygajlo A.Automatic Speaker Recognition for Forensic Case Assessment and Interpretation[M].New York:ForensicSpeakerRecognition.Springer,2012.
[7]Drygajlo A.Statistical evaluation of biometric evidence in forensic automatic speaker recognition[M]. Computational Forensics.Berlin Heidelberg:Springer, 2009.
[8]Gonzalez-Rodriguez J, Ramos D.Forensic automatic speaker classification in the"Coming Paradigm Shift"[M].Speaker Classification I.Berlin Heidelberg: Springer,2007.
[9]CampbellW M,BradyKJ,CampbellJP,et al. Understanding scores in forensic speaker recognition[A]. Speaker and Language Recognition Workshop[C],IEEE Odyssey2006,Puerto Rico:The.IEEE,2006.
[10]DrygajloA,MeuwlyD,AlexanderA.Statistical Methods and Bayesian Interpretation of Evidence in Forensic Automatic Speaker Recognition[A],in Proc. Eurospeech 2003[C],Geneva,Switzerland:Institute for PerceptualArtificialIntelligence,2003.
[11]WangHuapeng,Yang Jun.The comparison of "Idiot's Bayes"and multivariate kernel-density in forensic speaker identification using Chinese vowel/a/[A].3rd InternationalCongressonImageandSignalProcessing[C].Shanghai:The IEEE,2010,v8.
[12]Aitken C G G,Lucy D.Evaluation of trace evidence in the form of multivariate data[J].Journal of the Royal Statistical Society:Series C(Applied Statistics),2004,53(1).
[13]Morrison G S.Matlab Implementation of Aitken &Lucy's(2004)Forensic Likelihood-Ratio Software UsingMultivariate-Kernel-DensityEstimation[software], 2007.[EB/OL].http://geoff-morrison.net.
(责任编辑:孟凡骞)
TP391.4
A
2014-3-11
辽宁省自然科学基金资助项目(编号:2013020008);上海市物证鉴定中心重点实验室开放课题(编号:2013KF030110)。
王华朋(1979-),男,山东郓城人,中国刑警学院声像资料检验技术系副教授,博士,主要从事声像资料检验研究。
