一种检测溢油的快速分类辅助鉴别方法*
2014-04-17李福娟曹丽歆王鑫平李光梅孙培艳
李福娟,曹丽歆,王鑫平,李光梅,周 青,孙培艳*
(国家海洋局1.北海环境监测中心;2.海洋溢油鉴别与损害评估技术重点实验室,山东 青岛266033)
在海洋石油勘探开发过程中,极易因为试油、运输、储存以及其他原因造成突发性溢油事件。自1980年代以来,溢油事件呈上升趋势,几乎每年都发生由于井喷、漏油以及原油运输船舶的撞船、沉船等造成的溢油事件,这些事件会造成事故海域及流域的严重污染,而且还能间接危及陆地生物、人类健康和自然资源。对已发生的溢油污染事故,需要及时准确地确定污染源,以便实施应急措施、确定责任方、解决纠纷[1-2]。因此辨别溢油的来源便成为一个亟待解决的问题。
目前,在所有的方法技术中,气相色谱法、气相色谱-质谱联用是应用最广泛的。气相色谱分析技术尤其是毛细管柱气相色谱-质谱联用仪技术,已经得到较大提高,能够较好的分析石油中烃类物质。
近年来,越来越多的化学计量学方法应用到实验数据处理中来,并且已经变得非常重要。由于油品组成非常复杂,很难实现对所有样品的信息进行分析比较。大多数化学计量学方法只能从所获得的数据中提取最能代表原油特征的信息加以利用。这样做往往会丢失一些有用数据,存在着一定的局限性[3]。因此,可以在化学计量学分析中使用整个色谱数据来解决这个问题,然后通过聚类分析衡量不同样品的相似性。但是,实验过程中条件的稍稍改变就会引起保留时间的漂移,此方法对在时间轴上相近信息的提前或推后出现会产生较大的偏差,必须要对整个色谱图的保留时间进行校正。近年来,分析工作者提出了一系列检测和消除谱峰漂移的方法,例如,偏线性拟合方法(Partial linear fit,PLF)[4-5]、伪主成分回归 (Pseudo-principal component regression,PPCR)[6]、自动峰叠合算法(Automatic peak alignment algorithm,APAA)[7]、动态时间校正(Dynamic time warping,DTW)和相关系数优化校正(Correlation optimized warping,COW)[8-14]等。其中在校正时间轨道、色谱图和光谱图方面,相关系数优化校正因其耗时少,效果好而引起了人们的广泛关注。目前,有多种聚类分析方法,根据计算方法的不同分为:欧氏距离法、马氏距离法、类平均法、重心法、最长距离法、最短距离法、密度估计法、Ward最小方差法、主成分分析和系统聚类分析等[15-18]。
本文采用气相色谱和气相色谱-质谱联用2种方法进行油样分析,针对色谱组分保留时间的漂移问题,采用COW方法对色谱图的保留时间校正,大大提高了采集点的重合性。然后通过欧氏距离对校正后的新色谱数据进行聚类分析,达到了预期的分类效果。这种方法充分利用全指纹谱图的信息,使分析结果更为可靠,为溢油来源的判断提供了一种辅助鉴别方法。
1 理论与算法
COW是由Nielsen在1998年提出的一种分段优化数据的算法[19]。在运算过程中,向量的端点固定不动,根据松弛参数(t)将向量分成相同的段数。从最后一段开始同参照向量进行比照、校正,在松弛参数正负范围内进行优化,得到最大相关系数的一组数据向量,然后再在此基础上对第二段数据进行优化,依此类推,得到一组最优的重组数据向量。当抽样向量的时间点数和参照向量的点数不相同时,就在抽样向量内线性插入合适的点数得到相同段长的预处理向量。相关系数的计算公式如下:

COW只需2个输出参数进行分段线性相关系数优化校正[13],这成为它的一大优点。运算过程中可以选择一个适中的段长和较小的松弛参数来补偿色谱图中产生的时间漂移。
欧氏距离是两项间的差,即:每个变量值差值的平方和再平方根,目的是计算其间的整体距离,即不相似性。其公式如2所示:

其中:xik表示为第i个序列的第k个指标的测定值;yjk为第j个序列的第k个指标的测定值。Dij为第i个序列与第j个序列之间的欧氏距离。其具体应用的一般算法过程如下:(1)收集特征数据并且建立模型特征表;(2)规格化特征表;(3)计算各序列间距离并产生一个距离向量;(4)实施聚类分析;(5)根据分类距离等级要求决定把目标对象总体细分为几组,否则回到第3步继续;(6)产生分组结果。本文把信号点与点之间的欧氏距离的大小作为判别分类的依据。
2 实验过程
2.1 样品信息及前处理方法
在某次溢油事故中采集2个溢油样品,命名为样品1与样品2。在此次溢油事故中采集一个可疑油源命名为样品3。另外选择2个不相关油田的原油样品进行比较,其中样品4~7为来自油田A的原油样品,其中样品4为非降解油,样品5、6、7受到一定程度的降解;样品8~11为油田B的原油样品,均为重度降解原油(见表1)。
称取油样约0.8g,溶于正己烷,定容至10mL,离心10min后取上层油样200μL至进样瓶,同时加入800μL正己烷,混合均匀后上机分析。
2.2 仪器及工作条件
仪器 岛津GC2010气相色谱仪;岛津GCMS-QP2010气相色谱-质谱仪。毛细管色谱柱:DB-5(30m×0.32 mm×0.25μm)、DB-5MS(30m×0.25mm×0.25μm)(长度×内经×膜厚)。
分析条件 正构烷烃采用气相色谱/氢火焰离子化检测器(GC/FID)分析。毛细管色谱柱涂层为5%苯基、95%二甲基聚硅氧烷,涂层厚度为0.25μm,内径为0.32mm,长度为30m。色谱分析条件如下:载气:高纯氦气,1.0mL/min;进样方式:不分流;进样口温度:290℃;检测器温度:300℃;升温程序:在50℃保持2min,以6℃/min的速度升到300℃,保持16min。
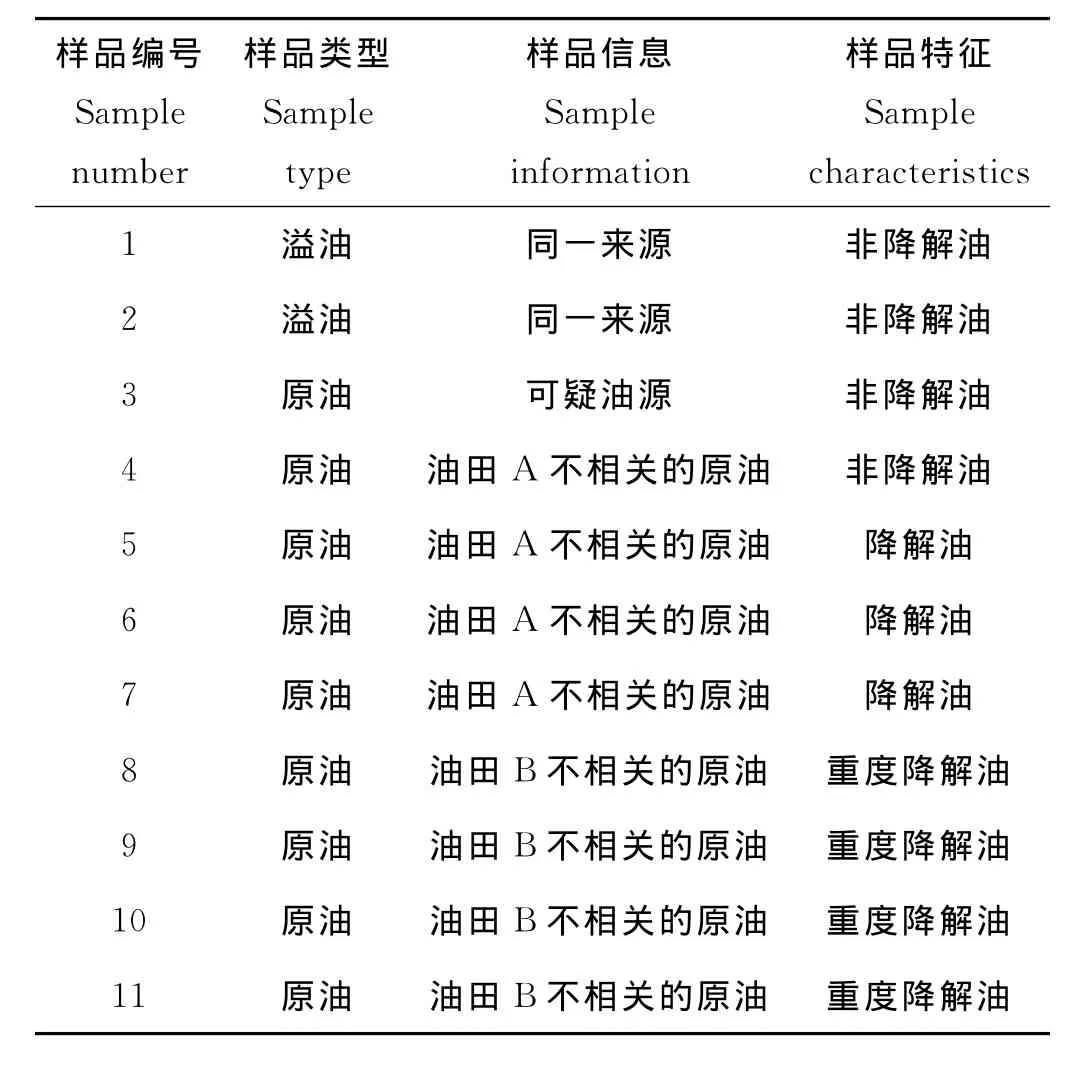
表1 11个样品的信息表Table 1 Information of 11samples
甾、萜烷类生物标志化合物均采用气相色谱/质谱(GC/MS)分析。毛细管色谱柱涂层为5%苯基、95%二甲基聚硅氧烷,涂层厚度为0.25μm,内径为0.25mm,长度为30m。色谱分析条件如下:载气:高纯氦气,1.0 mL/min;进样方式:不分流;进样口温度:290℃;接口温度:280℃;离子源温度:230℃;升温程序:在50℃保持2min,以6℃/min的速度升到300℃,保持16min。
3 分析结果
3.1 数据优化
采用COW算法对气相色谱数据进行校正,结果如图1所示,图1(a)为原始气相色谱图的一部分,2个色谱图在时间轴上的相近数值之间产生较大的漂移。图1(b)为相应数据校正后的气相色谱图。比较这2张色谱图,发现色谱峰的重合性大大提高,并且计算其相关系数,校正前为0.383 1,校正后为0.850 0,达到了理想的校正效果。
3.2 聚类分析
3.2.1 气相色谱数据聚类结果 根据欧氏距离公式对COW校正后的气相色谱数据进行聚类分析。COW校正前、后色谱数据的聚类分析树状图如图2~3所示。

图1 COW样品校正前a、后b的部分气相色谱图Fig.1 Data before and after the application of the COW algorithm

图2 基于未优化的色谱数据的聚类结果Fig.2 Clustering result based on unoptimized chromatographic data

图3 基于COW优化的色谱数据的聚类结果Fig.3 Clustering result based on optimized chromatographic data
基于原始色谱数据的聚类结果为:11个样品分为4组,溢油样品1、2与可疑油源3为一组;来自油田A的样品4、5、6、7分为2组,其中样品4单独为一组,样品5、6、7为一组;来自油田B的样品8、9、10、11为一组。基于优化后的色谱数据的聚类结果为:11个样品分为3组,样品4与溢油样品1、2和可疑油源3归为一类;来自油田A的样品5、6、7分为一组;来自油田B的样品8、9、10、11为一组。对照样品的色谱图(见图4)分析,溢油样品1、2与可疑油源3为非降解油(以样品1为代表),样品4为非降解油,样品5、6、7为降解油(以样品5为代表),而样品8、9、10、11为严重降解油(以样品8为代表)。结合聚类分析结果与样品的色谱图特征来看,两者的结果是一致的。因此,该聚类方法对于降解和非降解油来说是行之有效的,是完全可以进行分类的。但对受到风化影响的油品和为了准确查找溢油来源,还需要借助于质谱数据甾萜烷生物标志物的分析。
3.2.2 气相色谱-质谱数据聚类结果 甾萜烷生物标志物代表样品本身的性质,且在环境中几乎不受风化的影响,因此,在质谱数据中选择甾萜数据进行聚类分析。根据欧氏距离公式分别对COW校正前后的气相色谱数据m/z191(萜烷)和 m/z217(甾烷)进行聚类分析。COW校正前后的聚类分析树状图如图5~8所示。
通过聚类分析,利用m/z191的数据可以将11个样品分为3类。溢油样品1、2聚为一类(以样品1为代表);来自同一油田的4、5、6、7分为一类(以样品4为代表);可疑油源3与来自另一油田的样品8、9、10、11分为一类(以样品8为代表)。溢油样品1、2能很好的同其他2个油田的样品区分开来,但是也未与可疑油源样品3聚为一类,没有达到理想的聚类效果。对m/z191的优化后数据进行聚类分析后发现,可疑油源3与溢油样品1、2聚为一类,另外2个油田的样品分别归为一类,达到了理想的聚类效果。分析样品的萜烷谱图见图9,从谱图上分析也可以看出,样品1与样品3谱图一致,而与样品4、8谱图不一致。聚类结果与谱图分析和样品信息完全相符,样品数据的优化达到了优化聚类结果的目的。
对COW优化前和优化后的m/z 217的数据进行聚类后发现,2组数据的聚类结果是一致的,溢油样品1、2与可疑油源3聚为一类,另外2个油田的样品分别聚为一类。但从聚类效果来看,优化后数据溢油样品1、2与可疑油源3的差距明显缩小。聚类效果要优于未优化数据的聚类效果。分析样品的甾烷谱图见图10,从谱图上分析也可以看出,样品1与样品3谱图一致,而与样品4、8谱图不一致。聚类结果与谱图分析和样品信息完全相符,样品数据的优化达到了优化聚类结果的目的。

图4 4种油样的气相色谱图Fig.4 Gas chromatograms of 4kinds of crude oil

图5 基于未优化m/z191的质谱数据的聚类结果Fig.5 Clustering result based on unoptimized mass spectrometry data data(m/z 191)data

图6 基于优化m/z191的质谱数据的聚类结果Fig.6 Clustering result based on optimized mass spectrometry data data(m/z 191)data

图7 基于未优化m/z217的质谱数据的聚类结果Fig.7 Clustering result based on unoptimized mass spectrometry data data(m/z 217)data

图8 基于优化m/z217的质谱数据的聚类结果Fig.8 Clustering result based on optimized mass spectrometry data data(m/z 217)data
4 结论与展望
通过气相色谱法与气相色谱-质谱法分析油样的正构烷烃与甾萜生物标志物,然后结合相关系数优化(COW)方法,解决了色谱图保留时间漂移的问题。计算校正前后2个色谱数据的相关系数,发现校正后数据的相关系数大大提高,具有很好的重合性。然后以欧氏距离为判据对校正后的色谱数据进行聚类分析,通过与实际样品信息进行比较后发现,对气相色谱数据,该方法能有效分类降解和非降解油品;对气相色谱-质谱的甾、萜烷数据的聚类结果则与实际溢油来源排查结果是一致的,达到了理想的聚类效果,该聚类结果不受风化和降解的影响,更能代表油品本身的特点。并且欧氏距离为判据的聚类方法仅需几秒钟就可完成。该方法能够充分利用色、质谱采集信息,使分析结果更为可靠,为辨别溢油的来源建立了一种快速分类辅助鉴别方法。

图9 溢油样品与可疑油源样品的m/z191比对图Fig.9 Compared chromatogram of spilled oil and suspicious oil sources(m/z 191)

图10 溢油样品与可疑油源样品的m/z217比对图Fig.10 Compared chromatogram of spilled oil and suspicious oil sources(m/z 217)
[1]赵玉慧,孙培艳,王鑫平,等.多环芳烃指纹用于渤海采油平台原油的鉴别[J].色谱,2008,26(1):43-49.
[2]杨佰娟,郑 立,张魁英,等.原油中双环倍半萜指纹的内标法分析 [J].分析测试学报,2012,31(11):1421-1425.
[3]王鑫平,孙培艳,周青,等.原油饱和烃指纹的内标法分析[J].分析化学,2007,8:1121-1126.
[4]Westad F,Martens H.Shift and intensity modeling in spectroscopy-general concept and applications[J].Chemon intell Lab Syst,1999,45(1-2):361-370.
[5]Witjes H,van den Brink M,Melssen W J,et al.Automatic correction of peak shifts in Raman spectra before PLS regression[J].Chemon intell Lab Syst,2000,52(1):105-116.
[6]Brown T R,Atoyanova R.NMR Spectral Quantitation by Principal-Component Analysis. Ⅱ.Determination of Frequency and Phase Shifts[J].J Magn Reson,Series B,1996,112(1):32-43.
[7]Witjes H,Melssen W J A,int Zandt H J A,et al.Automatic correction for phase shifts,frequency shifts,and lineshape distortions across a series of single resonance lines in large spectral data sets[J].J Magn Reson,2000,144(1):35-44.
[8]Reiner E,Abbey L E,Moran T F,et al.Characterization of normal human cells by pyrolysis gas chromatography mass spectrometry[J].Biomed Mass Spectrom,1979,6:491-498.
[9]Wang C P,Isenhour T L.Time-warping algorithm applied to chromatographic peak matching gas chromatography Fourier-transform infrared mass-spectrometry[J].Anal Chem,1987,59(4):649-654.
[10]Pravdova V,Walczak B,Massart D L.A comparison of two algorithms for warping of analytical signals[J].Anal Chim Acta,2002,456(1):77-92.
[11]Tomasi G,van den Berg F,Andersson C.Correlation optimized warping and dynamic time warping as preprocessing methods for chromatographic data[J].J Chemometr,2004,18(5):231-241.
[12]Itakura F. Minimum prediction residual principle applied to speech recognition[J].IEEE Trans ASSP,1975,23(1):67-72.
[13]Sakoe H,Chiba S.Dynamic-programming algorithm optimization for spoken word recognition[J].IEEE Trans ASSP,1978,26(1):43-49.
[14]Zhang Dabao,Huan Xiaodong,Fred E,et al.Two-dimensional correlation optimized warping algorithm for aligning GC× GC-MS data[J].Anal Chem,2008,80(8),2664-2671.
[15]周健,成浩,曾建明,等.基于近红外的多相偏最小二乘模型组合分析实现茶叶原料品种鉴定与溯源的研究[J].光谱学与光谱分析,2010,30(10):2650-2653.
[16]张灵帅,王卫东,谷运红,等.近红外光谱的主成分分析一马氏距离聚类判别用于卷烟的真伪鉴别[J].光谱学与光谱分析,2011,31(5):1254-1257.
[17]刘志勇.常见气体的聚类分析[J].Fnend of Science Amateurs,2009,11(33):17-18.
[18]刘倩,孙培艳,高振会,等.衰减全反射傅里叶变换红外光谱技术结合模式识别进行油品鉴别[J].光谱学与光谱分析,2010,30(3):663-666.
[19]Nielsen N P V,Carstensen J M,Smedsgaard J.Aligning of single and multiple wavelength chromatographic profiles for chemometric data analysis using correlation optimised warping[J].J Chromatogr A,1998,805(1-2):17-35.
