CICF:一种基于上下文信息的协同过滤推荐算法
2014-04-14鲁凯张冠元王斌
鲁凯,张冠元,王斌
(中国科学院计算技术研究所,北京100190)
1 引言
近些年来,随着互联网的快速发展,互联网上的信息量越来越大,使得用户面临着严重的信息过载(Information Overload)问题。推荐系统通过在用户和信息之间建立联系,过滤掉大量无关的信息,然后将有用的信息提供给用户,是解决信息过载问题的有效手段。
推荐系统的研究产生于20世纪90年代,随着互联网中信息量的迅猛增长,推荐系统的研究得到了快速的发展,并且很多技术已经应用在实际系统中。例如,在电子商务中,Amazon,eBay等都部署了商品推荐并取得了巨大的成功;Netflix,Youtube等推出了电影及视频推荐;Yahoo!Music,Pandora及Last.fm等也提供了音乐推荐引擎。推荐系统使得互联网发生非常显著的变化。一方面,提高了用户的做事效率。通过给用户推荐其喜欢的物品(item),大大缩短用户的选择时间,提高了用户体验;另一方面,推荐系统可以直接给服务提供商带来实际的经济效益。因此推荐系统的研究是一件非常有意义的事情。
在推荐系统中,基于协同过滤(CF)的推荐技术可以满足用户的个性化需求,为用户提供更加精确的推荐,因此受到更多的关注。基于协同过滤的算法主要是对用户和物品之间的交互数据进行建模,然而目前大多数推荐系统所面临的问题是用户的反馈历史数据太少,稀疏的数据严重影响推荐算法的效果。因此研究如何有效地克服数据稀疏性的负面影响,对提高推荐效果有着非常重要的意义。
在用户反馈历史中具有丰富的上下文信息,因此本文主要基于两种上下文信息,提出了一种新的协同过滤算法CICF。通过在大规模评分数据集Yahoo!Music上的实验结果表明,CICF推荐效果明显优于传统的协同过滤算法,并且能够有效地缓解评分稀疏性问题。
本文后续内容组织如下:第2节介绍相关工作;第3节详细地介绍本文提出的CICF的算法;第4节给出实验和结论;第5节对全文进行总结和展望。
2 相关工作
CF方法主要包括两种:基于内存的CF和基于模型的CF[1]。基于内存的方法主要利用相似用户(物品)之间具有相似的喜好这一特点进行推荐,比较简单直观;基于模型的方法主要是学习在训练数据集中的复杂模式,相比基于内存的方法具有更强克服稀疏性的能力[2];其中效果比较好的方法有基于用户物品偏差的隐参数模型(RSVD)以及在此基础上考虑隐式反馈(Implicit Feedback)的SVD++模型[2]。
为了克服基于内存的CF方法中用户—物品评分信息的数据稀疏性问题,国内外研究者进行了一系列研究,提出了多种解决方法。早期研究较多的是预测填充技术。文献[3]采用BP神经网络进行评分预测。这种方法克服噪声数据能力较强,可以有效降低评分矩阵稀疏性。然而,BP算法会导致近邻查找时间的延长。文献[4]采用相似度传播的思想寻找到更多、更可靠的邻居,能够较好提高推荐效果,然而该方法计算时间较长,临时空间较大。此外,填充方法通常会带来归罪[5],使得算法效率随着数据增长变得非常低,并且效果不稳定。
限于矩阵填充的缺点,更多的研究者从数据本身特性进行解决稀疏性问题。一方面,由于推荐系统是动态的,很多研究者研究时间信息对用户兴趣的影响,Ding[6]提出,用户未来的兴趣主要受用户近期兴趣的影响,所以推荐系统侧重对用户近期行为建模来提高推荐的有效性。Lu[7]在传统的矩阵分解模型中,将用户和物品的特征向量看作是一个随着时间变化的动态特征向量,从而将时间作为新的一维加入到推荐模型中。Koren[8]从用户,物品等角度考虑各种时间效应,对提升推荐效果起到显著地作用。
另一方面,研究者利用数据中的物品属性及其它资源解决稀疏性问题。文献[9]研究利用人口统计学特征和用户行为数据构建用户的兴趣模型;然而该方法的缺点是粒度太粗。文献[10]使用物品的文字属性、社会化标签以及其他标签来缓解用户反馈数据的不足;该方法的缺点没有考虑用户的个性化偏好。文献[11]使用物品的分类信息对用户以及物品的偏好进行建模,然而没有考虑物品之间的关联关系对用户潜在喜好的影响。
根据上述不足,本文主要考虑用户评分的短期时间效应以及物品中的层次关联关系对用户潜在喜好的影响,从而缓解评分稀疏性的负面效应,提高算法的推荐效果。
3 本文工作
3.1 基于层次信息的隐参数模型
在推荐系统中,物品通常是多类别的。例如,在电子商务中物品按照不同用途可以分为图书、影视、电子产品、食品、生活用品等;对于电影可以分为影片、导演、演员、电影类型等;音乐可以分为歌曲(track)、专辑(album)、流派(genre)、演唱家(artist)等。对于不同类型的物品之间可能存在层次关系,例如给定专辑名字,我们能够确定它包含的歌曲集合,发布该专辑的演唱家等;具有关联关系的物品,可能会影响用户的潜在喜好,如喜欢一首专辑的用户,可能会喜欢该专辑中的代表歌曲以及该专辑所属的演唱家。因此,可以利用物品间的层次信息来挖掘用户的潜在喜好。
本论文重点研究音乐中的层次信息,但是需要注意的是本论文中的模型同样适用于其他领域。根据以上分析,音乐中的层次信息如图1所示。对于每一个用户u,我们可以根据其评分历史利用层次信息找到更多其潜在的物品。具体地,我们考虑以专辑、演唱家、流派为中心的三种关联关系:即对于每个专辑,我们考虑它包含的唱片,所属的演唱家及相关的流派;对于每个演唱家,我们考虑他包含的唱片、专辑以及和这些唱片、专辑相关的流派;对于每个流派,我们考虑其相关的唱片、专辑以及这些唱片专辑所属的演唱家。
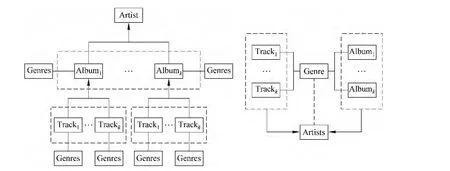
图1 音乐中的层次信息
我们在隐参数模型(RSVD)上进行改进,改进后的模型(HierSVD)如式(1)所示。
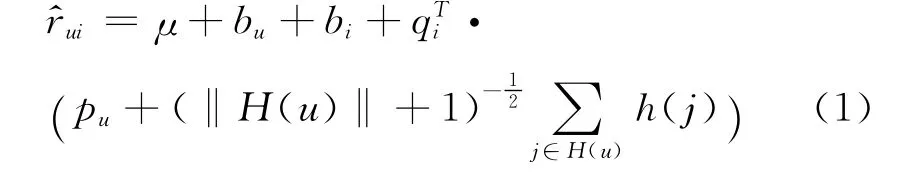
H(u)由三部分构成:H(u)=album(u)∪artist(u)∪genre(u),分别表示由于u对于专辑、演唱家、流派等的喜好产生的对相关物品感兴趣的集合。对于album(u)的生成过程如下:对于u评分的每个专辑i,我们取其相关的评分数最多的top-k歌曲,同时统计i相关的演唱家和流派的关联次数,取关联次数不小于阈值threshold的演唱家和流派。对于artist(u)和genre(u)的生成过程可以类似求出。
进一步地,可以在式(1)中加入用户评分集合同时忽略具体值,模型(HierSVD++)如式(2)所示。
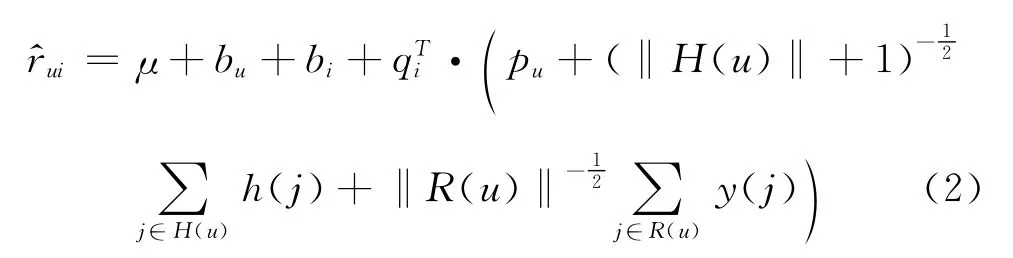
其中R(u)为用户u的评分集合,y(j)为其相关的变量。
3.2 基于用户短期时间段的隐参数模型
推荐系统是动态的,用户的兴趣以及物品的受欢迎程度都随着时间的推移而动态变化。例如,一首流行歌曲刚推出时非常受欢迎,但是经过一段时间之后,可能流行度下降,导致用户评分降低。相比物品来说,时间效应对用户的影响更大,并且用户更多的是受短期时间效应影响。比如用户在连续一段时间内评分,前面的评分可能导致其后面评分的变化,同时可能受当时心情以及环境等因素影响。因此本文重点考虑两种用户短期时间效应。
首先,我们观察到用户每天在不同时间段具有不同的评分倾向。例如,用户白天可能比较忙碌,心情比较紧张,此时评分值相对比较低;而在夜晚,相对比较清闲,心情比较轻松,打的分值稍微较高。因此,我们考虑特定时段信息对用户评分偏差及特征向量的影响,模型(PeriodSVD)如式(3)所示。
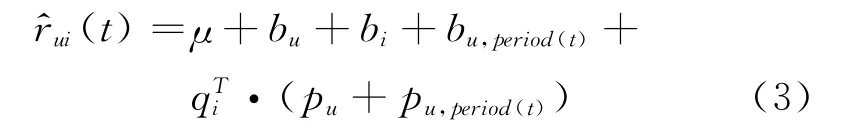
其中t表示用户每天评分的具体时间,period(t)表示t所处的时间段,为整数值。bu,period(t),pu,period(t)分别表示时间段效应对用户评分偏差及用户兴趣的影响。
另外,我们注意到用户在连续一段评分时间内具有明显的动态性。首先是用户前面的评分高低会影响用户后面的评分,假如用户非常喜欢听的第一首歌曲,评分非常高,那么之后的音乐他可能感觉都没有第一首歌曲好,评分都没有第一首歌曲高;此外,用户的评分还会受到当时心情的影响。因此,我们通过定义空闲时间段对用户的评分进行分割为连续的评分时间段,并考虑对用户偏差以及特征向量的影响,模型(TsliceSVD)如式(4)所示。
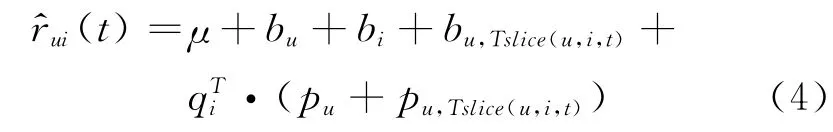
其中Tslice(u,i,t)表示评分信息(u,i,t)所处的连续时间段。
进一步,我们可以很容易地结合模型(3)、(4)同时考虑两种用户短期时间效应,定义为Short-TempSVD。
3.3 最终模型
在上面两节我们分别讨论了基于两种上下文信息的模型,由于两种方法都基于隐参数模型进行扩展,因此我们可以将两种信息融合在一起进行考虑,定义为CICF模型,如式(5)所示。

我们通过采用岭回归的方法,最小化在训练数据集上的预测误差,优化目标如式(6)所示。
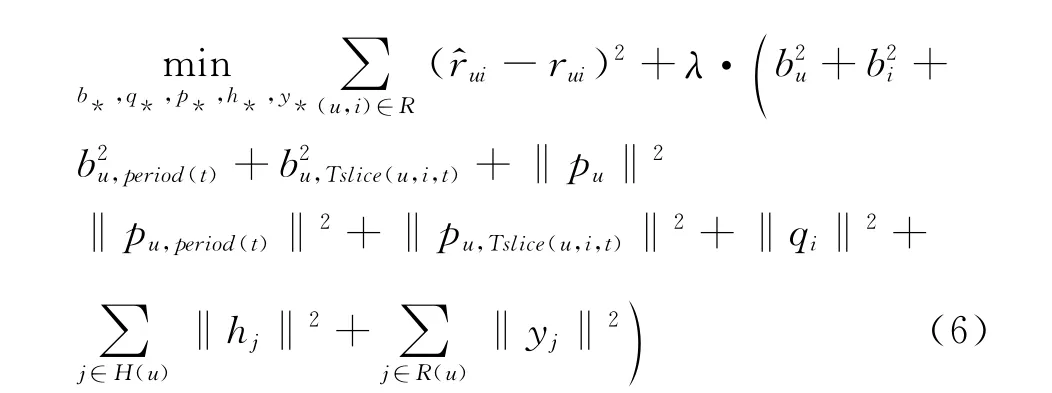
其中R为训练集,λ为正规化因子。对于该模型,可以很容易地采用梯度下降法求解。
4 实验和结论
4.1 实验数据
本论文主要使用Yahoo!Music音乐评分数据集评估相关模型。该数据集公开在2011年KDDCup比赛中,数据集经过11年9个月的时间搜集得到,其中评分值为[0-100]内的整数值,每个用户的打分数都在20以上。用户和物品id是连续的整数,评分日期是经过转化的整数,表示从起始日期到评分日期的天数,评分时间精确到秒。数据集主要包括三部分:训练集、验证集、测试集。数据详细信息如表1所示。

表1 Yahoo音乐评分数据集组成
通过表1可以看出整个数据集包含将近300M的评分数,是目前公开的规模最大评分数据集。通过计算,该数据集的稀疏度为99.6%,比Netflix电影评分数据集(98.9%)更加稀疏。另外该数据集评分值在[0-100]范围,因此异常稀疏的数据和较大的评分范围使得在Yahoo!Music上进行预测非常具有挑战性。
此外,该数据集中物品是多类别的:歌曲数目为507 172,专辑数目为88 909,演唱家数目为27 888,专辑数目为992。我们对Yahoo!Music中物品的各类别信息在不同用户评分数的分布以及评分时间效应统计结果如图2(a)~2(b)所示。
通过图2(a),我们可以看到在评分较少的用户中,演唱家和专辑的评分比重较多,通过用户对演唱家、专辑的评分更能准确地反映出用户的兴趣;用户评分数较多时,尽管用户对歌曲的评分占大多数,此时仍然能够利用各类别之间的层次关联关系对用户的潜在喜好进行建模。
从图2(b)中可以看出,用户在Yahoo!Music评分数据集中表现出每天在不同的时间段具有不同的评分倾向;在白天的评分比较低,晚上的评分比较高,而凌晨之后评分有下降的趋势。因此我们可以有效利用这一信息进行建模。
4.2 实验数据
在本文中采用均方误差(RMSE)来评价评分预测的准确度。RMSE对于较大的误差值赋予了较大的权重,近年来用得较多。RMSE值越小说明算法效果越好,计算公式如式(7)所示。
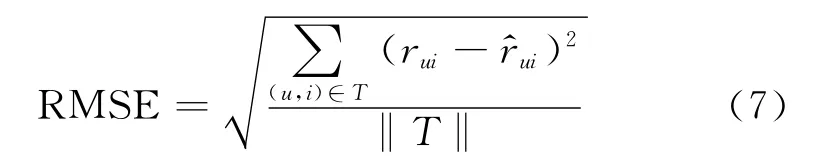
其中T是测试集合,rui是测试集中的真实评分值,是算法的预测值。
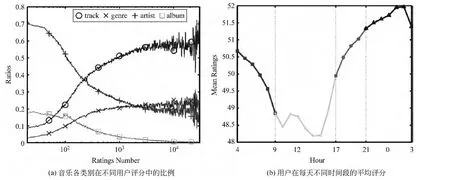
图 2
4.3 实验结果及分析
对于隐参数模型在训练时需要学习相关的正规化因子以及学习速率,本文采用自动参数学习方法[12]在验证集上进行学习相关参数,然后在测试集上进行评估算法的优劣。
首先,我们评估基于层次信息的模型(HierS-VD),在该模型中首先需要计算artist(u),album(u)和genre(u),计算时需要设定top-k及threshold的值,这两个值是依赖于数据集的。通过在验证集上的训练,设置为:top-k=10,threshold=0.3。HierSVD等模型在测试集上的结果如图3所示。
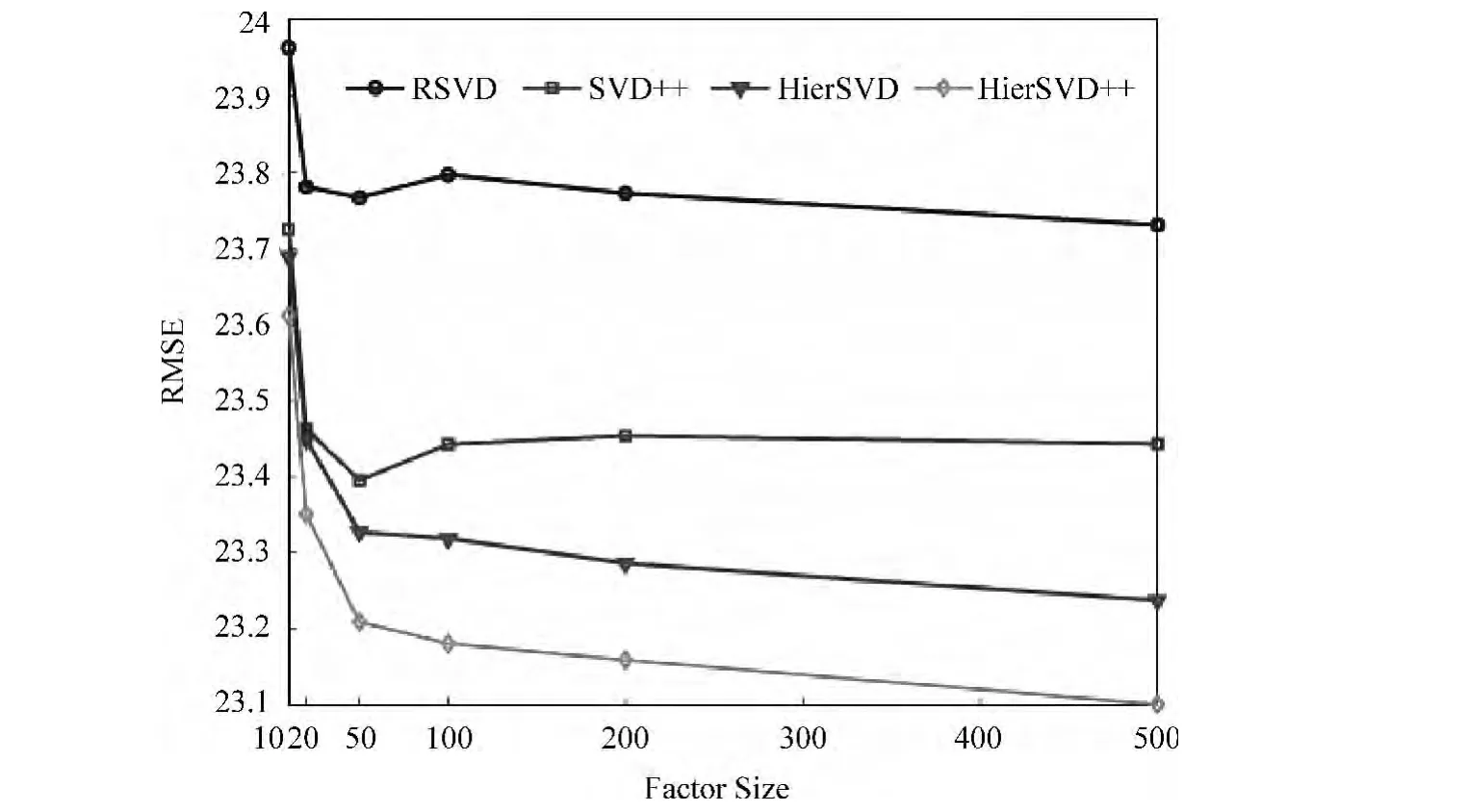
图3 基于层次信息的隐参数模型
图3中横坐标表示模型中的特征向量大小,纵坐标为在测试集上的误差。通过在不同向量维度上的实验结果表明,相比传统的RSVD,考虑物品中层次信息的模型HierSVD能够明显地提高预测效果;同时,通过层次信息发掘用户的潜在兴趣,比使用用户评过分的物品集合的隐式反馈模型SVD++的作用更有效果,表明使用层次信息能够更有效地发掘用户的潜在喜好;从HierSVD++的效果可以看出,考虑层次信息和隐式反馈的模型能够同时结合两方面的优势,进一步地提高预测精度。
其次,我们评价基于用户短期时间效应的相关模型。对于TSliceSVD,我们设定空闲时间段长为5小时;在PeriodSVD中需要设定Period(t)的取值范围,根据图2(b)所示,我们设置Period(t)如下:
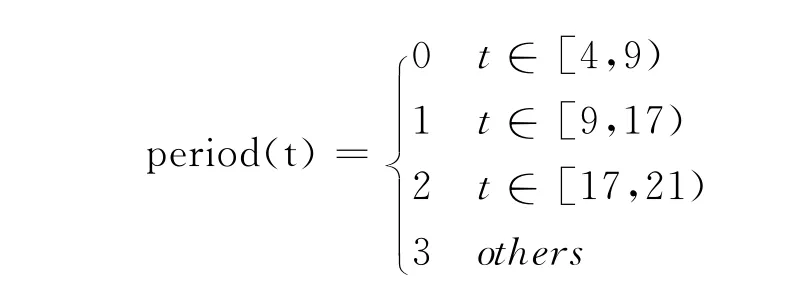
对于时间效应相关的模型在测试集上的实验结果如图4所示。
从图4中我们可以发现相比RSVD,基于用户特定评分时段的动态模型(PeriodSVD)以及连续评分时间的动态模型(TSliceSVD)都可以有效地提高RSVD的预测效果,从而证明这两种时间信息的有效性;另外通过实验结果的比较,我们可以发现将两种时间效应与其他时间信息结合起来,能够更加显著地降低预测误差;同时通过图3和图4的比较,可以发现考虑时间效应稍微强于基于层次信息的模型。
进一步地,我们给出本文中最好模型CICF在测试集上的效果,实验结果如表2所示。
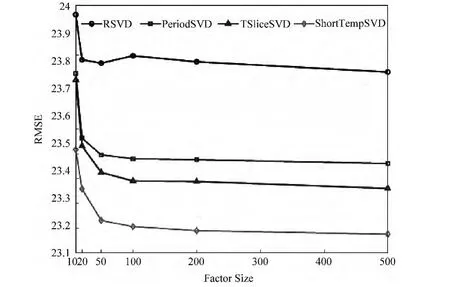
图4 短期时间效应模型的实验效果

表2 CICF在测试集上的实验效果
从表2中可以看出,CICF能够充分利用物品间的层次信息以及用户时间效应两方面的优势,非常显著地降低了预测误差,将RMSE值降低了0.93(3.92%),从而说明了利用音乐数据集本身的上下文信息能够克服评分稀疏性,提高算法的推荐性能。
最后,为了验证本文中算法能够有效缓解评分稀疏性带来的负面效应,我们在不同稀疏度的训练集上进行了相关实验。对于每个用户按照时间先后顺序分别取前K个评分作为新的训练数据,保持验证集和测试集不变,并取特征向量大小为50,评测结果如表3所示。

表3 在不同稀疏度训练集上的结果对比
从表3中可以看出,随着训练数据变得越稀疏,两种算法的预测效果都变得越差,说明评分稀疏性问题对推荐算法的效果影响很大;相比SVD,CICF算法在训练数据非常稀疏时的优势更加明显,当K=50时推荐效果提升了8.01%。由此可以充分说明CICF能够有效地克服稀疏评分数据带来的负面影响,提高算法的推荐效果。
5 总结和展望
本文主要介绍了一种融合两种上下文信息的协同过滤算法CICF,该算法一方面利用物品的层次信息找到更多用户可能感兴趣但是还没有评分的物品,另一方面通过对用户评分的短期时间效应建模来挖掘用户的动态偏好,进而提高预测的精确性。实验结果验证了CICF方法的有效性。
未来工作主要包括:利用物品的层次信息找到有关物品的更多更可靠的邻居集合;考虑数据中物品的时间效应;并将这些上下文信息统一融合在本文提到的模型中。
[1] Badrul Sarwar,George Karypis,Joseph Konstan,et al.Item Based Collaborative Filtering Recommendation Algorithms[C]//Proceedings of WWW10,2001:285-295.
[2] Yahoo!Music dataset[DB/OL].http://kddcup.yahoo.com/.
[3] FZhang,C H Y.A Collaborative Filtering Algorithm Embedded BP Network to Ameliorate Aparsity Issue[C]//Proceedings of International Conference on Machine Learning and Cybernetics.2005.
[4] 赵琴琴,鲁凯,王斌.SPCF:一种基于内存的传播式协同过滤推荐算法[C]//CCIR 2011.
[5] B M Sarwar,G Karypis,J A K,Riedl J.Application of Dimensionality Reduction in Recommender System Case Study[R].2000.
[6] Y Ding,X Li.Time weight collaborative filtering[C]//Proceedings of 14th ACM International Conference on Information and Knowledge Management(CIKM'04),2004:485-492.
[7] Z Lu,D Agarwal,and S Dhillon.A Spatio-temporal Approach to Collaborative Filtering[C]//Proceedings of 3rd ACM Conference on Recommender Systems,RecSys'09,NY,USA,2009:13-20.
[8] Y Koren.Collaborative Filtering with Temporal Dynamics[C]//Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.KDD09,NY,2009:89-97.
[9] M Montaner,B Lopez,Josep.A Taxonomy of Recommender Agents on the Internet[J].Artif.Intell.Rev.,2003,19:285-330.
[10] Lamere P.Social Tagging and Music Information Retrieval[J].Journal of New Music Research,2008,37(2):101-114.
[11] Dror G,Koenigstein N,Koren Y.Yahoo!Music Recommendations:Modeling Music Ratings with Temporal Dynamics and Item Taxonomy[C]//Proceedings 5th ACM Conference on Recommender Systems.RecSys'11,2011.
[12] Toscher A,Jahrer M,Bell R.The Bigchaos Solution to the Netflix Grand Prize[R].2009.
[13] Koren Y.Factorization Meets the Neighborhood:A Multifaceted Collaborative Filtering Model[C]//Proceeding of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,ACM 2008:426-434.
