多特征文本蕴涵识别研究
2014-04-14赵红燕王智强
赵红燕,刘 鹏,李 茹,王智强
(1.太原科技大学计算机科学与技术学院,山西太原030024;2.中国电子科技集团公司第二研究所,山西太原030024;3.山西大学计算机与信息技术学院,山西太原030006;4.山西大学计算智能与中文信息处理教育部重点实验室,山西太原030006)
1 引言
由于自然语言在表达形式上灵活多样,相同的含义往往可以采用不同的陈述形式来表达,或从不同的文本中推断出来,为了解决这种同义异形现象,Dagan和Glickman[1]在2004年提出用“文本蕴涵(Textual Entailment)”来为这些歧义现象建立统一的模型和处理框架。
所谓文本蕴涵[2],是指一个文本(Hypothesis,H)的意义可以从另外一个文本(Text,T)的意义推断出来。更确切地说,就是给定一个文本片段T和一个被称为假设的文本片段H,根据T的上下文语境和世界知识,可以从T的含义中推断出H的含义来,则称T蕴涵H。
自2005年以来,文本蕴涵识别(Recognizing Textual Entailment,RTE)已经得到了学术界的重视,由美国国家标准技术局(National Institute of Standards and Technology,NIST)组织的一年一度的国际文本评测会议(Text Analysis Conference,TAC)把RTE作为重要的评测任务之一,到目前为止RTE评测已经举办了7届。
针对文本蕴涵识别国内外学者提出了很多方法,构建了一定量的文本蕴涵识别模型和推理模型。目前文本蕴涵识别模型大都是基于词汇、句法、浅层语义等方面进行建模,利用各种语义词典、世界知识、语言知识及本体知识进行句子相似度计算或逻辑推理等方法来实现。例如,Shachar Mirkin[3]等提出的基于模式和词汇相似度分布的文本蕴涵识别模型,Peter clark[4]等提出了一个基于WordNet和DIRT的词汇知识文本蕴涵识别系统BLUE;北京工业大学刘江利[5]等提出基于词汇与句法关系匹配的蕴涵关系识别方法;山西大学张鹏[6]等提出利用FrameNet框架关系识别文本蕴涵等都取得了一定的成绩,但影响文本蕴涵的因素错综复杂,文本蕴涵模型总体识别准确度不高,2009年参加RTE5评测的21个团队中,2-ways任务评测最高准确率达到73.5%,平均准确率达到61.52%,文本蕴涵识别的准确度还有很大的提升空间。因此,本文综合考虑词汇特征、句法特征及语义特征对文本蕴涵的影响,提出一种多特征文本蕴涵识别模型,然后利用统计学习方法训练分类器。
SVM[7](Support Vector Machine)自从1995年由Vapnic提出以来,鉴于其具有坚实的统计学习理论基础、以及有效防止过学习能力及核函数的灵活运用等优点,在许多应用领域均获得良好的应用。并且,基于SVM的分类也被证明是当今最好的分类方法之一。1998年,Joachims[8]验证了SVM在文本分类中的优异性能。因此本文将文本蕴涵转化为二元分类问题,通过提取文本的词汇特征、句法特征及FrameNet语义知识库特征的多种选取特征方法构造特征矩阵,利用台湾大学林智仁[9](Lin Chih-Jen)老师等开发的SVM模式识别与回归的软件包LIBSVM训练分类模型,实现文本蕴涵识别。
本文后面的组织结构如下:第2节介绍了文本蕴涵识别模型及特征选取;第3节介绍了本文的实验及结果分析;第4节对本文提出了总结及展望。
2 文本蕴涵识别
文本蕴涵识别模型的输入是一个T-H对,通过算法判断T是否蕴涵H,输出非真即假的二元结果。文本蕴涵识别流程如图1所示。
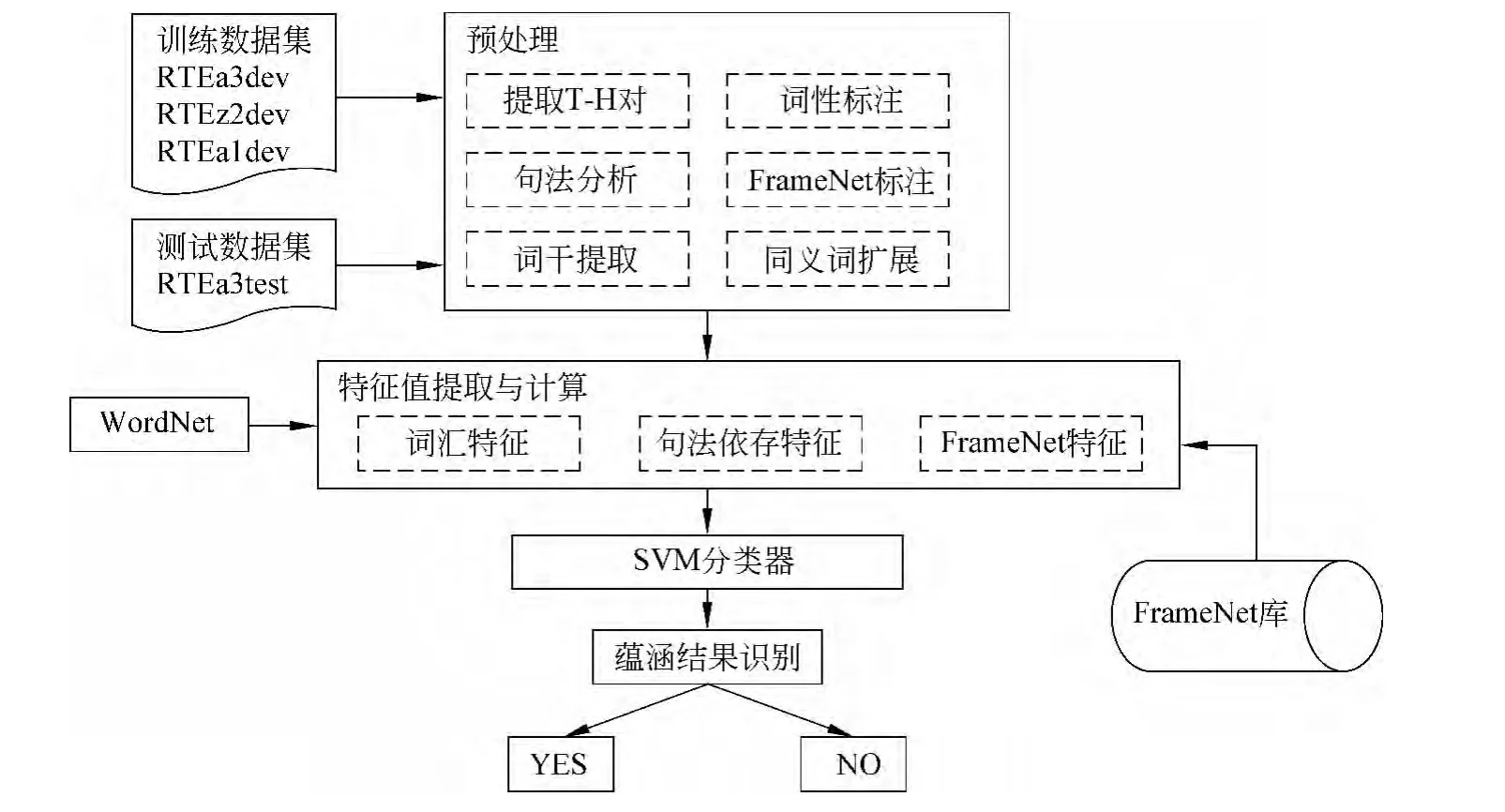
图1 文本蕴涵识别流程图
2.1 预处理
对训练数据集和测试数据集均做如下预处理:
(1)从RTE数据集的XML文件中抽取T-H对,把它存储成文本格式,称为file1;
(2)使用EnStemmer[10]对file1中的动、名词进行词形还原,并去掉停用词,存储为file2;
(3)使用POStagger[11]对file2生成的文件进行词性标注,生成file3;
(4)利用WordNet对file3进行同义词扩展生成file4;
(5)由Stanford Parser[12]对file1进行句法依存关系分析,生成file5;
(6)利用Frame-semantic Parsing[13-14]对file1进行FrameNet标注生成file6。
2.2 特征选取
2.2.1 词汇特征
在词汇层面[15]上假设T句和H句是由一组词汇组成的,如果H跟T具有相同的词目或词类,或通过一系列词汇转换,H中的词h都能跟T中的词t相配匹(忽略虚词),那么就认为T蕴涵H。
(1)词形特征
词形特征反映原语料中文本T和假设H两个句子中词语在基本形态上的配匹程度,以T-H对中所含有相同词的个数来衡量。T-H对词形配匹值计算如式(1)所示。
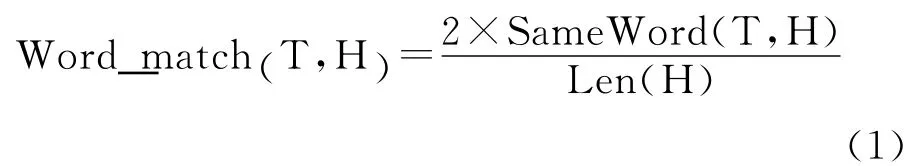
其中:SameWord(T,H)为文本T和假设H中所含相同词的个数,Len(H)为H句的长度。
(2)句长特征
句长特征反映两个句子在句子长度形态上的配匹程度。句长配匹计算如式(2)所示。
其中,Len(T)和Len(H)为T句和H句的长度。
(3)词干抽取后的词形配匹
词干是把名词和动词都还原成词根的形式,例如名词的复数形式:“boxes”被转化成“box”,这样避免了因词形不同而带来的识别误差。词干还原后的词形匹配计算公式如式(3)所示。
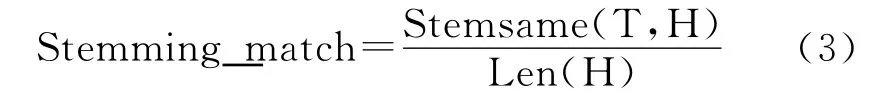
Stemsame(T,H)为抽取词干后T句和H句中相同单词个数,Len(H)为抽取词干后的H句长度。
(4)LCS最长公共子序列(Longest Common Subsequence)特征
一个序列S,如果分别是两个或多个已知序列的子序列,且是所有符合此条件序列中最长的,则S称为已知序列的最长公共子序列,它可以用来描述T-H对之间的重叠程度。
例1 T:I and Joe like apple and box.与H:I like box.
因T-H对的最长公共子序列是I like box,并且T包含H,故判定T句蕴涵H句。算法实现如下:
Step1 把T句和H句对表示为T={t1,t2,…,tn},H={h1,h2,…,hm}
Step2 计算T的第i个词和H的第j个词之前的最长公共子序列c [i][j],c [i][j]定义如式(4)所示。
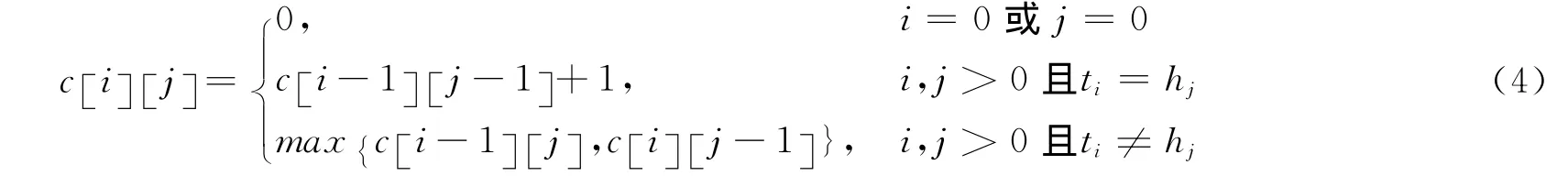
Step3:计算LCS特征配匹值为式(5)。
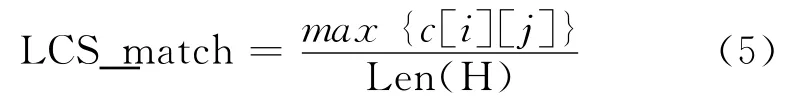
(5)基于WordNet的Unigram特征
具体步骤如下:
Step1 把T句T{t1,t2,t3,…,tn}利用WordNet扩展为T’{(t11,t12,t13,…),(t21,t22,t23,…),…,(tn1,tn2,tn3,…)},tij表示T句中第i个词的第j个同义词。

Step4 计算Unigram特征配匹值为式(6)。

(6)基于WordNet的Bigram特征
如果H中两个相邻的词出现在T中,则该类信息比Unigram匹配成功具有更有力的依据。在单个词匹配结束后,对于file4中的每个T-H对进行Bigram匹配。配匹过程如式(7)所示。

其中Bigramsame(T,H)为T和H中相同的二元文法个数,Bigram(H)为H中的二元文法个数。
2.2.2 句法依存特征
在句法层面[15]上,T-H对被看作由依存关系分析而得到的三元组集合。如果H中的关系被T中的关系覆盖或通过对T中的关系进行转化能够产生出H中的关系,则认为T句蕴涵H句。
本方法使用Stanford Parser对句子进行依存关系分析。该句法分析器定义了55种依赖关系。例如,We win the game.dobj(win,game),表示win和game之间具有dobj的关系。由于每种依存关系对蕴涵的影响程度不同,本文根据重要性把55种依存关系分成四个等级,如agent,iobj等关系比较重要设为第一级,而conj,nn的重要性次之,设为第二级等,一共设置了四个等级,权值分别为α、β、γ、δ,在实验过程中,选取最佳权值。如表1所示。
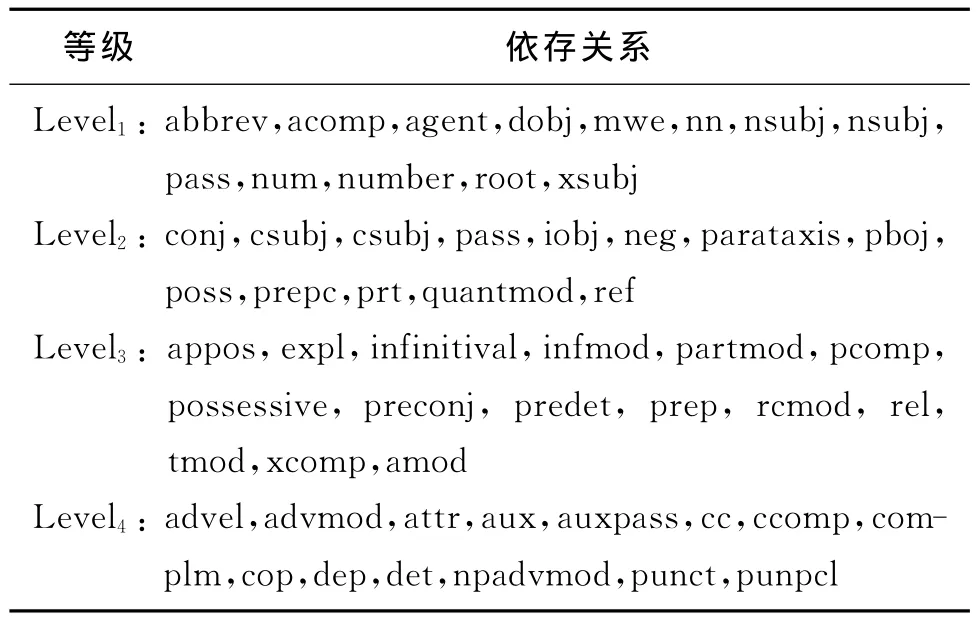
表1 句法依存关系等级
基于句法依存关系的T-H匹配算法如下:
Step1:使用Stanford Parser分析T,其所有的依赖关系构成集合Dt
Step2:使用Stanford Parser分析H,其所有的依赖关系构成集合Dh
Step3:对于Dh中的每一个依赖关系dj:

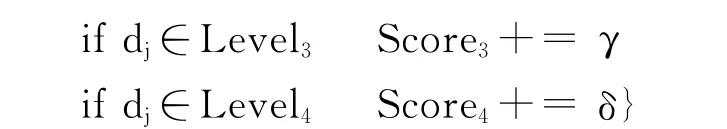
Step4:计算每一级的句法依存特征值如式(8)所示。
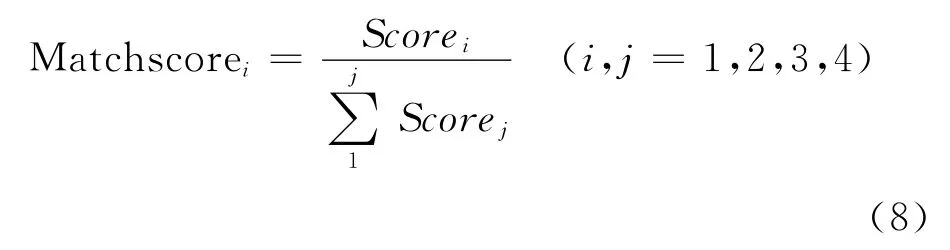
例2 RTE1中语句对
T:Satomi Mitarai died of blood loss.</t>
H:Satomi Mitarai bled to death.</h>
经过Stanford Parser依存关系分析后如图2所示。

图2 句法依存关系分析结果
从图2可以看出T和H都包含关系nn(Mitarai,Satomi),这两种关系都属于Level1,故Score1=α,Matchscore1=1,Matchscore2=Matchscore3=Matchscore4=0。
2.2.3 FrameNet特征
FrameNet[16]是美国加州大学伯克利分校构建的一个基于框架语义学词汇资源。FrameNet的框架库由框架表、框架元素表、框架关系表、词元表四部分组成。框架表给出了框架的定义和名称;框架元素表给出了框架元素名称及所属框架;框架关系表中定义了八种框架关系,描述了框架和框架之间的关系;词元表描述了该词的词性及所属框架。本文以框架语义学为理论基础,利用框架语义角色[17],从T句和H句中的框架关系及框架元素两个方面抽取可用于文本蕴涵识别的特征。实现过程如下:
Step1:利用Frame-semantic Parsing对所用语料进行FrameNet标注。例如,Baikalfinansgroup was sold to Rosneft.经过FrameNet标注后生成图3格式文件
从图3可以看出,通过FrameNet标注后,可以得到该句的框架名称为“Commerce_sell”、目标词“sold”及框架元素“Goods”。
Step2:提取经过上述标注的T句和H句中的框架和框架元素组,如图3中,Commerce_sell(Baikalfinansgroup)
Step3:分别进行框架和框架元素配匹。

图3 用Frame-semantic Parsing进行FrameNet标注文件格式
框架特征配匹,采用深度优先搜索的方法,在框架关系表中查找T-H句中的框架之间的上下位或继承等关系,由于迭代次数比较大,最多搜索三步之内的框架,并根据框架距离设置不同的权值,分别为F_scorei(i=1,2,3),通过实验,选择最佳权值,并记下不同距离T-H句中有上下位或继承关系的框架个数,分别记作fi(i=1,2,3)。如果找到T句和H句的两个框架相同或存在上下位关系,则比较该框架下的框架元素(利用WordNet进行同义词扩展),记下相配匹的框架元素个数FEsame(T,H)。框架配匹特征值F_Match和框架元素配匹特征值FE_Match的计算如式(10)所示。

其中,Frame(H)、FE(H)分别指的是假设H中的框架个数和框架元素的个数。
3 实验及结果分析
3.1 语料
为了检验上述方法的有效性,本文构建了基于多特征的文本蕴涵识别模型,该模型训练数据采用国际文本蕴涵识别技术评测提供的RTE数据集“RTE3_dev”(800对)+“RTE2_dev”(300对)+“RTE1_dev”(150对),共1250对T-H对,测试数据采用“RTE3_test”,共800对T-H对。根据评测规则,评测结果用ENTAILMENT=“YES”和ENTAILMENT=“NO”表示。
3.2 实验过程及结果
实验过程如下:
Step1:分别对训练集和测试集采用上述方法进行预处理和特征值计算,生成Libsvm的数据格式文件
Step2:对Step1文件进行Scaling处理
Step3:选用RBF核函数
Step3:用5折交叉验证方法对训练数据集选择参数c和g的最优值
Step4:用最优参数训练分类模型
Step5:对测试集进行预测
本实依次从词汇特征、词汇特征+句法特征、词汇特征+句法特征+FrameNet特征三个不同的角度去训练SVM分类器,并分别对测试数据进行预测,得到三个不同的运行结果,分别为RUN1(表2),RUN2(表4),RUN3(表5)。系统经过多次试验RUN2和RUN3运行中选用的参数值如表3。
表2是基于词汇特征的运行结果,蕴涵正例识别准确率达到70.2%,蕴涵反例准确率为61.2%,平均准确率为66.75%。表4是基于词汇特征和依存句法特征的运行结果,从表中可以看出加入句法特征提高了文本蕴涵识别的准确率,其中蕴涵正例识别准确率提高1.8%,蕴涵反例准确率提高6.6%,平均准确率提高3.75%。表5是综合词汇特征、依存句法特征及FrameNet特征运行结果,从表中可以看到在蕴涵正例、蕴涵反例及平均准确率方面都有较大提高,正例识别准确率达到78.1%,平均识别准确率到达75.9%。高于RTE3最高评测结果,并且从表5可以看出,本方法达到最高准确率时,召回率也达到最高。

表2 基于词汇特征的运行结果(RUN1)

表3 RUN2和RUN3中各参数的值

表4 基于词汇+依存句法特征的运行结果(RUN2)

表5 基于词汇+依存句法特征+FrameNet特征的运行结果(RUN3)
4 总结及展望
文本蕴涵对于自然语言的许多高层次的文本分析的研究有着重要的作用,本文从词汇、句法依存关系、FrameNet知识库三个层面考虑文本蕴涵识别特征,并通过三个RUNS训练SVM分类器进行文本蕴涵识别。试验结果表明相对于单独基于词汇或句法的文本蕴涵识别模型,本文提出的基于多特征的综合文本蕴涵识别模型有助于文本蕴涵识别准确率的提高。
但从三个RUNS的运行结果来看,本方法也存在一些不足,系统对于蕴涵反例的识别效果普遍偏低,也就是把一些非蕴涵的T-H对误识别为蕴涵的。究其原因:(1)使用WordNet进行同义词扩展,增大了蕴涵的可能性;(2)使用FrameNet关系库进行框架关系的多层搜索,也无形中提高了蕴涵的可能性,影响了实验结果的精度;(3)由于框架库的不完善、依存关系的稀疏也是影响实验精度原因。接下来的工作是进一步完善词汇、句法、语义三个层面的特征,尝试加入逻辑推理技术,以提高文本蕴涵识别准确率。
[1] Dagan Ido,Oren Glickman.Probabilistic Textua1Entailment:Generic Applied Modeling of Language Variability[C]//Proceedings of the PASAL Workshop on Learning Methods for Text Understanding and Mining,Grenoble France.2004.
[2] 袁毓林,王明华.文本蕴涵的推理模型与识别模型.中文信息学报[J],2010,24(2):3-13.
[3] Shachar Mirkin,Ido Dagan,Maayan Geffet.Integrating Pattern-based and Distributional Similarity Methods for Lexical Entailment Acquisition[C]//Proceedings of COLING-ACL 2006,Sydney,Australia,2006,7:17-21.
[4] Peter Clark,Phil Harrision.An Inference-Based Approach to Recognizing Entailment[C]//Proceedings of Text Analysis Conference(TAC).2009.
[5] 刘江利,杜永萍.基于词汇与句法关系匹配的蕴涵关系识别方法[A].第六届全国信息检索学术会议论文集[C];2010.
[6] 张鹏,李国臣,李茹等.基于FrameNet框架关系的文本蕴涵识别.中文信息学报[J],2012,26(2):46-50.
[7] Vapnic V.The Nature of Statistical Learning[M].New York:Springerl-Verlag,1995,126-178.
[8] Joachims T.Text Categorization with Support Vector Machines:Learning with Many Relevant Features[C]//Proceedings of theEuropean Conference on Machine Learning,Berlin,Springer,1998.
[9] http://www.csie.ntu.edu.tw/~cjlin/.
[10] http://www.pudn.com/downloads521/sourcecode/windows/dotnet/detail2161512.html.
[11] Stanford POStagger.http://nlp.stanford.edu/software/tagger.shtml.
[12] Stanford Parser.http://nlp.stanford.edu/software/lex_parser.shtml.
[13] Dipanjan Das,Noah A.Smith.Graph-Based Lexicon Expansion with Sparsity-Inducing Penalties[C]//Proceedings of NAACL 2012.
[14] Dipanjan Das,Noah A.Smith.Semi-Supervised Frame-Semantic Parsing for Unknown Predicates[C]//Proceedings of ACL 2011.
[15] 袁毓林.文本蕴涵的类型和识别机制(2008).中国中文信息学会成立二十七周年学术会议[C].
[16] FrameNet.http://framenet.icsi.berkeley.edu.
[17] Burchardt A.,Pennacchiotti,M.,Thater,S.,et al.Assessing the Impact of Frame Semantics on Textual Entailment.Nat.Lang.Engineering,2009:15(4).
[18] Julio Javier Castillo.Sangn inTAC2010:A Machine Learning Approach to RTE within a Corpus.TAC 2010Proceedings Papers.2010.
[19] Dagan I.,Dolan B.Recognizing Textual Entailment:Rational,Evaluation and Approaches.Natural Laguage Engineering,2009,15(4):i-xvii.
[20] Burchardt A.PH D Dissertation.Modeling Textual Entailment with Role-Semantic Information.2008.
