基于HNC理论的词语相似度计算
2014-04-14吴佐衍王宇
吴佐衍,王宇
(大连理工大学管理科学与工程学院,辽宁大连116024)
1 引言
词语的相似度计算在信息检索、信息抽取、文本自动分类、词义消歧、机器翻译等领域有着广泛的应用[1]。
目前词语相似度算法可以分为两种。一种是基于本体知识的方法。这种方法是根据人类对概念的理解,将词语构建成具有语义关系的词典或语义网络,利用概念节点之间的关系、语义距离、层次深度、密度等度量词语相似度。例如,基于WordNet,Wu和Palmer使用最近祖先概念节点来计算两个概念节点相似度[2],Rada用两个概念节点的最短路径长度来衡量相似度[3],Leacock在Rada的基础上加入了概念节点的深度影响[4];基于HowNet和同义词词林,刘群等分别提出了相应的汉语词语的相似度算法[1,5-9]。这种方法具有简单有效的优点,但它依赖于词典的建设,存在人为的主观性影响。另一种是利用大规模的语料库进行统计。这种方法通过计算两个词语在同一上下文共现的概率来度量词语的相似度。例如,Ricardo通过词语的共现分析计算相似度[10];Lin等利用两个概念共同拥有的信息量来度量相似度[11]。该方法能够较好地反应出词语相似度,但计算量大,且计算方法复杂。
本文是以HNC理论为语义知识来源,进行词语的语义相似度计算。HNC理论是中国科学院声学研究所黄曾阳先生提出的,以语义表达为基础,融语义、语法、语用为一体,通过词汇和语句两个联想脉络来“帮助”计算机理解自然语言[12]。利用HNC理论的概念联想脉络就可以非常容易地发现词语之间的语义相关性,也可以容易地给出其量化的数值[13]。
目前使用HNC理论进行词语语义计算中,晋耀红[14]利用语义相似度进行语义块的切分和组合;宋培彦[15]利用HNC构造中文词汇链时,只利用两个词语HNC符号的相同部分来求相似度;史燕[16]充分利用概念内涵和五元组,但忽略概念类别对相似度的影响。
为了充分利用HNC的语义信息,提高计算结果的准确性,本文利用HNC概念表达方式和概念HNC符号映射的特点,提出了基于HNC的字词的相似度计算方法,该方法综合概念内涵、概念外部特征、概念类别和组合符号来计算词语间的相似度。
2 相关工作
2.1 HNC简介
HNC理论是面向整个语言理解的理论框架,是中文信息处理的三个流派之一[17]。该理论通过建立局部和全局两个联想脉络来描述大脑认知结构的模式,局部联想脉络是词汇层面的联想,体现为一个概念表述体系,这个体系把概念分为抽象概念和具体概念,对抽象概念的外部特征使用五元组(v,g,u,z,r),即动态、静态、属性、值和效应五个侧面来表达;对抽象概念的内涵使用语义网络来表达;对具体概念采取挂靠展开近似表达方法[12]。
语义网络是树状的分层结构,树的每个节点代表一个概念,即概念基元,每棵树的概念节点形成一个概念聚类,每个子树节点概念形成一个子类[12]。树中任意节点的层次符号都可以通过从概念层次树的根节点开始、到该节点的一串数字符号唯一地确定。这棵树称为概念层次树,可以形式化为:CT(ss,node)。其中:ss表示具有独立层次符号设计概念的语义网络符号,ss∈{φ,j,l,jl,s,f,wj,pj,jw};node表示节点符号集,是0~e为十六进制整数[18],若cp为概念基元,则cp∈CT。
HNC理论采用形式化的方法描述语言概念空间,即通过概念基元符号体系与自然语言的词语建立语义映射关系。HNC符号映射理论就是根据词语的语义,选择恰当的概念基元和五元组用适当的组合符号连接成HNC符号。该理论对自然语言概念的符号化表述可以一般化为[12]:Σ{类别符号串}{层次符号串}{组合结构符号}{类别符号串}{层次符号串}
上式的BNF范式[14]如下:
<概念>::=={<概念表示>[<组合符号><概念表示>]}
<组合符号>::==‘#’|‘$’|‘&’|‘|’|‘,’‘;’|‘!’|‘^’|‘(,lm,)’|‘/’|‘‖’
<概念表示>::==<语义网络符号>+<五元组>+<语义符号>
<语义网络符号>::==ø|j|l|jl|s|f,h,q|x|p|w|jw
<五元组>::=={v|g|u|z|r}
<语义符号>::=={[<本体层符号>]+<高层符号>+[<中底层符号>]}
<本体层符号>::==500|52|53|9|c|6y(y=0~5)
2.2 相似度的定义
Dekang Lin认为两个对象的相似度取决于他们之间共性和差别,两个对象的共性越多,则相似度越大[11];而两个对象之间的差异越多,则相似度越小。当两个对象是同一对象时,相似度达到最大。当两个事物无关或独立时,则相似度最小。Wu和Palmer认为最近公共祖先概念节点是概念节点c1,c2共性的重要因素,提出下列相似度计算的公式[2],如式(1)所示。
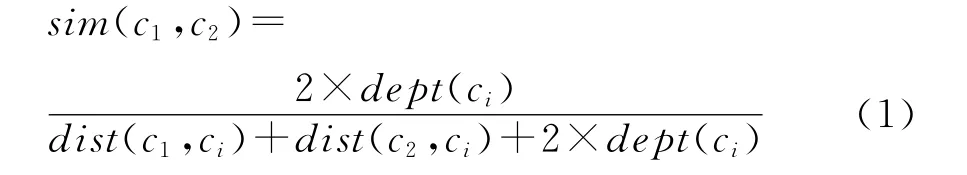
其中:cp是概念节点c1和c2最近公共祖先节点。
基于实例的机器翻译中,文献[1]提出词语相似度是两个词语在不同的上下文中可以互相替换使用而不改变文本的句法语义结构的程度。在下文中,我们分别借鉴Wu的最近公共祖先概念节点是概念节点共性的重要因素和文献[1]整体相似度由部分相似度合成的思想。
词语相关性和词语相似性又有着密切的联系。如果两个词语非常相似,那么这两个词语的相关性也会非常接近。同理,如果两个词语的特点相关且很接近,那么这两个词语一般也具有较高的相似度[1]。
3 基于HNC字词的相似度计算
通过上文的介绍,我们知道字词的语义信息是通过HNC映射符号来描述的,而该符号由概念基元、五元组、语义网络符号和组合符号组成。以“采纳”为例,其在HNC字词知识库中只有一个义项,HNC映射符号为“(v9380,v9218)”。由两个概念表示“v9380”和“v9218”通过“逻辑或”组合符号“,”组合而成(此处两个概念表示都省略了基元概念符号ø)。概念表示“v9380”的意义如表1所示。因此,本文提出了基于HNC理论计算字词相似度的主要思想:基于HNC理论表达概念的方式和特点,根据HNC映射符号的编码规则,充分利用HNC符号中的语义信息,综合概念内涵、概念类别、概念外在多元性表现和组合符号来计算字词的相似度。

表1 v9380符号意义
3.1 概念基元相似度计算
为了便于下文对概念基元进行相似度计算,首先给出以下两个定义。
定义1 概念基元的语义重合度:指两个概念基元cp1和cp2包含相同上位概念节点的个数。在实际计算中,可以转化为两个概念节点的最低公共父节点所在的层次深度,记为dept(cpp),其中cpp是他们的最低公共父节点;dept是层次深度,规定根节点的层次深度为1。
定义2 概念基元的语义距离:指连接两个概念基元cp1和cp2之间最短路径的长度,记为dist(cp1,cp2)。
概念基元是概念层次树中的节点,是语义描述的基本单位。HNC概念层次树具有良好的树状结构,图1为基元概念层次树的局部结构图。HNC概念层次符号的构造方式把最频繁、最基本的语义计算变成了对层次符号的简单逐层比较[12]。因此,概念基元符号的构造方式决定了使用语义重合度来表示两个概念基元的语义相似度;若两对概念的最低公共父节点一样,则相似度也一样,但他们在概念层次树中这两个概念节点的最短路径所跨的边数并不一样。例如,“经济”与“文化”语义距离为2,“经济”与“文学”的语义距离为3,其最低公共父节点都为“专业活动”。因此,概念基元的语义距离也需要考虑。由于概念层次树自顶向下,概念基元的分类由大到小,大类间概念基元的相似度一般要小于小类的。因此,两个概念基元最低公共父节点和语义距离都相同时,其相似度与两个概念基元所处层次深度和成正比,与两个概念基元的层次深度差成反比。

图1 基元概念层次树的局部结构图
综合概念基元语义重合度、语义距离和层次深度对两个概念基元相似度的影响,本文提出处于同一概念层次树下的任意两个概念基元cp1,cp2的语义相似度如式(2)所示。
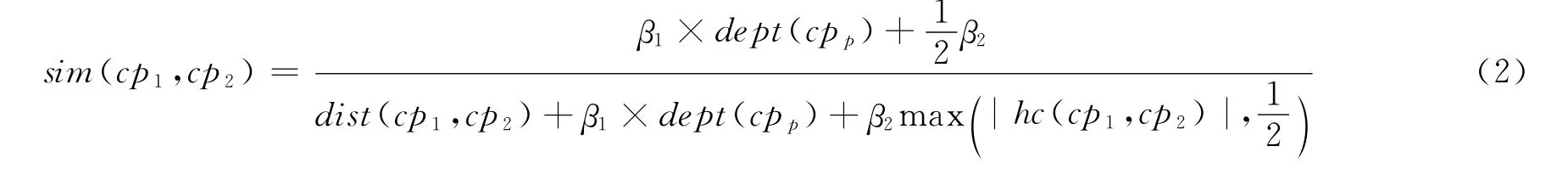
其中:参数β1>1>β2≥0,且β1,β2分别表示两个概念基元的语义重合度和层次深度差对概念基元相似度的影响,当β1=2,β2=0时,式(2)与式(1)相同;dist(cp1,cp2)+β1×dept(cpp)体现了两个概念基元的层次深度和;hc(cp1,cp2)=dept(cp1)-dept(cp2)为两个概念基元的层次深度差;max最小值取是为防止出现sim的错误;分子是为了归一化的需要。
3.2 概念类别的相似度计算
HNC理论将概念分为抽象概念、具体概念和两可概念。两可概念兼具有抽象概念和具体概念的特征。对抽象概念设置了五种类别基元:基元概念、基本概念、语言逻辑概念、“语法”概念和综合类概念,分别用符号ø,j,l,f,s表示;对具体概念设置两个概念基元:人和物,用符号p和w表示;以及兼具有抽象概念和具体概念双重特性的物性概念x。HNC通过语义网络符号和五元组的组合来表示概念类别,概念类别相似度为式(3)。

其中:cci表示概念类别,且p,jw和w表示具体概念,其他都是抽象概念;网络符号中p是人,jw和w是物。
3.3 概念外部特征的相似度计算
抽象概念需要从动态、静态、属性、值和效应五个侧面加以表达,这就是抽象概念的五元组特性,简记为:(v,g,u,z,r),它们是抽象概念外在多元性表现的基元。在自然语言中,表达抽象概念的词语必定是从五元组的某个或某几个侧面来表达某个抽象概念,五元组是词性的本质内容,是词性的基元[12]。例如,“思考和思维”就是从五元组的vg,g侧面对同一概念内涵的表达。当两个概念表示的外部特征都表现为五元组的某一个或几个相同的侧面时,则两个概念表示外部特征的相似度为1。因此,两个概念表示的五元组集合分别为ep1和ep2,则两个概念表示外部特征的相似度为式(4)。

其中:epi为五元组的集合,且epi⊆{u,g,v,z,r}。
3.4 概念表示的相似度计算
综合前面所述,在3.1~3.3节的基础上,本文提出两个概念表示cr1,cr2的相似度为概念基元、概念外在表现和概念类别相似度的合成,如式(5)所示。

其中:δ1+δ2+δ3=1,且δ1>δ2>δ3,δ1,δ2,δ3分别为对应计算的权重。
公式(5)由概念基元、五元组和概念类别三项组成。其中概念类别是针对HNC概念分类的特点而设计的;同时,本文认为五元组只是概念的外在表现形式,相同内涵的概念可以具有不同的表现形式,例如主宰vg441和权利rc441是概念441的不同表现形式。因此,概念的相似度是通过概念内涵和概念外在表现的五元组相似度以加权的形式共同决定的;概念基元的相似度主要通过语义重合度度量。综上所述,通过考虑概念类别和重新定义概念基元的相似度计算方式,使本文取得比文献[16]更合理的结果。
3.5 基于HNC字词相似计算方法及步骤
两个词语w1,w2在HNC知识库中不同义项的HNC映射符号的集合为HNC1,HNC2。即:

其中:hnc1i表示词语在词语知识库中的义项;p,q表示两个词在HNC知识库中的义项数。
本文采用文献[1]计算知网词语相似度的思想,两个词语的相似度等于其所有义项之间相似度的最大值,如式(6)所示。

其中:sim(hnc1i,hnc2j)是两个义项hnc1i,hnc2j的相似度,由式(7)计算得到,即:

其中:权重数组Az=(az1,az2,…),z=1,2,数组中元素与概念基元一一对应,表示概念基元在相似度计算中的权重,该数组根据下文介绍的式(8)~(11)求出。
权重数组的数值是根据不同的组合符号及其优先级来确定的。概念的组合符号都有明确的意义,在计算时必须将其转化为数值。文献[13]给出不同组合符号的运算式,但有些式子的结果大于1。为了使概念间的相似度总是小于等于1,本文对其进行了改进,改进后的运算式为(8)~(11),组合符号“非”和“反”的权重分别为λ10,λ11。表达式中的sim表示相似度计算函数,其结果是0~1的数值,csi和csij分别表示概念组合符号的作用域,它是一个概念基元或其组合。例如,cs1为wj2-000+v661,cs11为wj2-000,cs12为v661。
(1)作用组合符号“#”,前者是主体,后者是此作用的效应。例如,采掘是一种“基本劳作”,即“v961”,产生的效应是“入”,即“v201”,其HNC映射符号为“v961#v201”;效应组合符号“$”,后者是主体,前者是产生这个效应的作用;对象组合符号“&”,前后都是主体,后者是前者的对象;内容组合符号“|”,前后都是主体,后者是前者的内容;偏正组合符号“/”,后者是主体,前者是对后者的修饰,可以作为对本概念修饰成分的预期;主谓组合符号“‖”,后者是主体,前者可以作为后者的主语。这些组合符号的运算式可统一表示为式(8)。
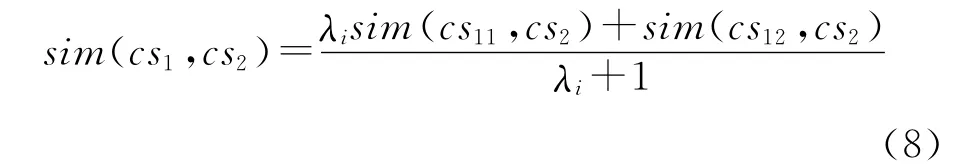
其中:cs1-cs11stcs12,st表示组合符号,且st∈ST={#,$,&,|,/,‖};λi表示组合符号对概念相似度的影响,当i=1,2,…,6时,分别表示作用、效应、对象、内容、偏正和主谓。
(2)一般逻辑组合“(,lmn,)”,前者是主体,后者是对前者工具或方法等的说明。例如,“直播”的HNC符号“(vc23aa,l11,su1021)”。其运算式为式(9)。

其中:cs1=(cs11,lmn,cs12)。
(3)展开组合符号“+”,表示逐步逼近。例如,“v93219”表示保护,它是对“包庇”的一级近似,其运算式为式(10)。
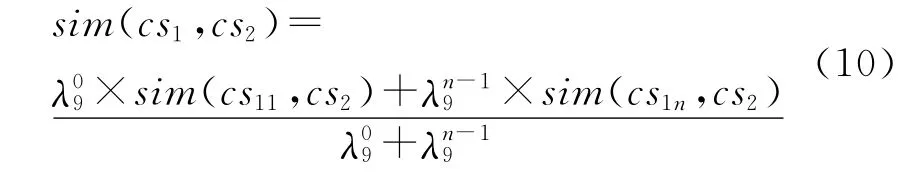
其中:cs1=cs11+…+cs1n。
(4)逻辑与组合符号“;”,其运算式如式(11)所示。
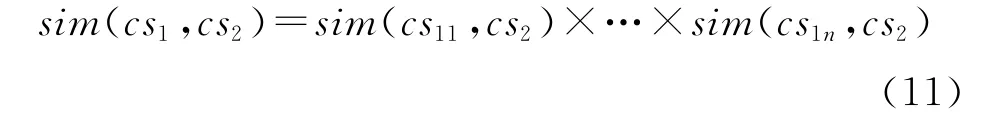
其中:cs1=cs11+…+cs1n。
(5)HNC层次符号有本体层与挂靠层之分,是抽象概念的一种表达方式,本体层体现概念表达的一类特定需要[11]。对抽象概念来说,本体层类型有基元概念的500,52,53,6m,9,c(m=0~5)和语言逻辑概念。对概念表示层次符号中存在以上类型的本体层时,其运算如式(12)所示。

其中:0<θ≤1;cs1=cs11cs12,cs11为本体层,cs12为挂靠层。
基于HNC词语相似度计算的步骤:
步骤一:输入两个词语w1,w2;
步骤二:在词语知识库中查找这两个词语的HNC映射符号集合HNC1和HNC2,用hnc1i和hnc2j分别表示HNC1第i个,HNC2第j个义项的HNC映射符号,其中1≤i≤m,1≤j≤n,m和n分别表示两个词语在词语知识库中的义项数;
步骤三:将hnc1i和hnc2j分解为概念表示数组CR1i和CR2j,则cr1ik和cr2jt分别是CR1i和CR2j的第k和第t个元素,1≤k≤p,1≤j≤n,且p和q为hnc1i,hnc2j组合符号数加1;
步骤四:用式(5)求数组CR1i,CR2j中任意两个概念表示cr1ik,cr2jt的相似度sim(cr1ik,cr2jt);
步骤五:根据式(7)求出两个词语各个义项的相似度sim(hnc1i,hnc2h);
步骤六:最后根据式(6)求出两个词语的相似度sim(w1,w2)。
4 实验及结果分析
我们选取几组典型的词语与文献[1]和文献[16]的方法进行比较。方法1是基于知网的词语相似度算法;方法2是基于HNC的方法;方法3是本文提出的方法;方法4是人主观判断的相似度。通过实验验证本文方法在计算字词相似度的有效性和合理性。实验中的参数设置如表2所示,实验结果如表3所示。

表2 实验参数设置
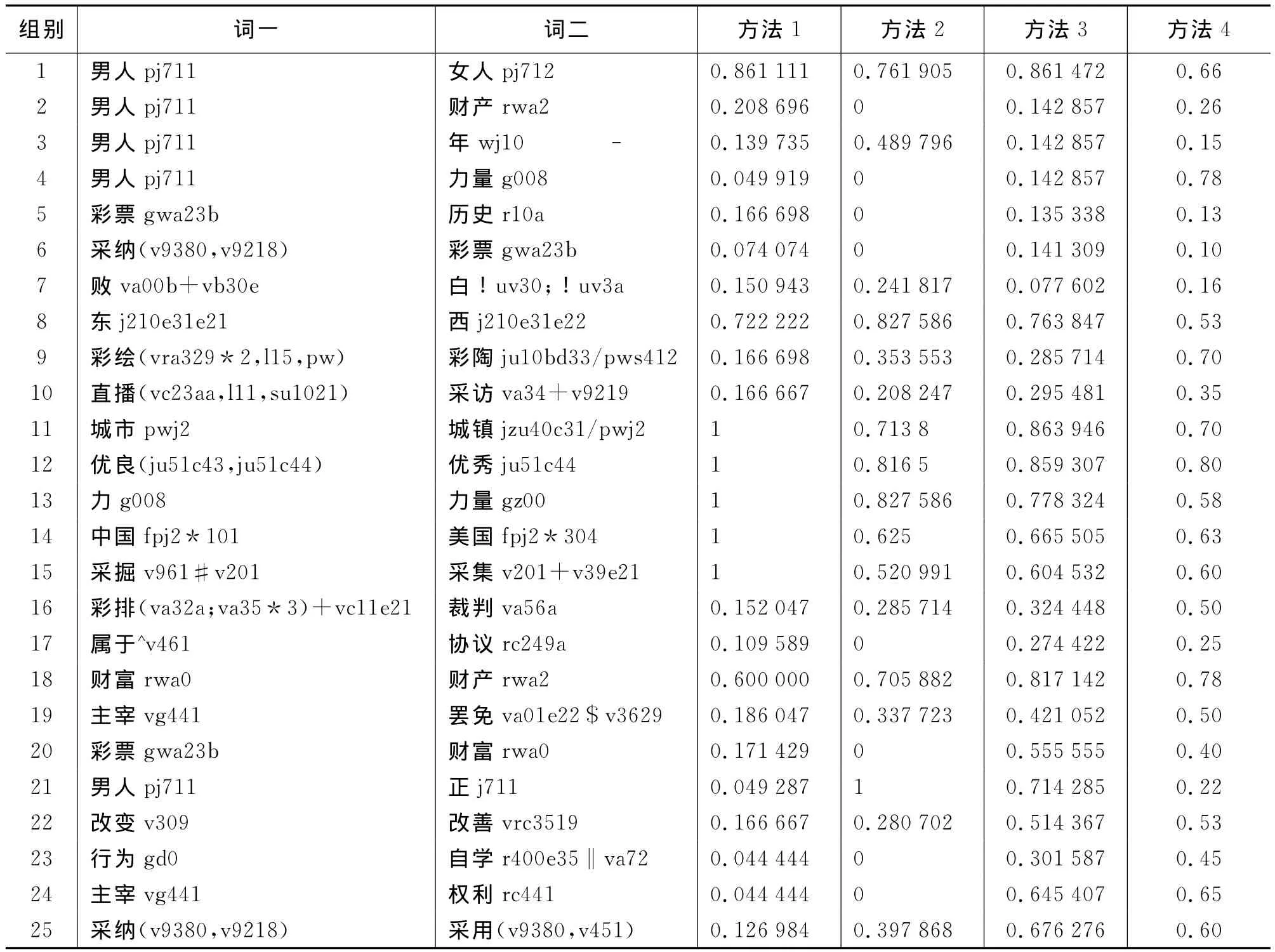
表3 实验结果
观察表3,方法1、方法2和方法3在表中前半部分(第1~13组)相似度的数值结果较为一致,但后半部分(第14~25组)结果却差别较大。同时可看出,方法2和方法3的数值结果具有较高的一致性,且总体上大于方法1。这是因为方法2和方法3运用了基于HNC理论来计算词语的相似度,HNC理论在构造概念的符号表达式时,考虑概念间的关联性知识。若两个概念的内涵相同或相似,则赋予它们相同或相似的层次符号。例如,“采纳”和“采用”有相同的层次符号“v9380”。
在方法1中,第11~15组词语的相似度都为1,而在方法2和方法3中,相似度在0.5~0.9之间,这与实际情况相符合。例如,“力”和“力量”都为抽象概念,力量为力的效应物,是力的一种度量,它们的语义并不完全相同。在本文的方法中,这两个词的HNC映射符号分别为“g008”和“gz00”,其中g,z为五元组,表示静态和值,是概念外部特征;基元概念“008”,“00”分别表示“物理作用”和“作用”。两个词具有相似的内涵,因此具有较高的相似度,方法3求出的相似度为0.778 324较为合理。
在方法1中,第22~25组的相似度都很低,从认知的角度来说具有不合理性。例如,《新华字典》中“改变”和“改善”的释义分别为:“变化,事物产生显著的差别”;“改变原有情况使比较好一些”,即改善是往好方向的改变,说明这两个词应该具有较高的相似度。方法1中它们的相似度只有0.166 667。在HNC中,抽象概念“改善”和“改变”具有相同的外部特征v,都是一种效应,因而,这两个词语具有较高的相似度。在方法3中它们相似度为0.514 367,更符合这组词语间的语义关系。
在方法1~3中,“男人”和“正”的相似度差别很大,原因之一是HNC对具体概念采用挂靠表达方式,在具体和抽象概念之间建立一种关联的符号表示。例如,“j711”和“j712”表示正负,则“pj711”和“pj712”表示男女。因此,“男人”和“正”之间具有相同的概念基元“j711”,所以在基于HNC方法中,它们具有较高的相似度。
方法2没有考虑两个词语概念类别的相似度,而且将五元组是否相似作为两个词语是否相似的前提。因此,很多对词语的相似度为0。例如,第24组实验,这对词语虽然具有相同概念基元“441”,但是它们五元组的相似度为0。
目前对词语相似度还没有形成统一的规范,比较两个字词之间的相似程度更多的是根据人为的直觉感观。而方法1、方法2和方法3采用两种不同的知识表示体系,方法1是基于知网的,方法2和3是基于HNC理论的。为了更好地比较两者在计算词语有效性和合理性,本文请大连理工大学信息管理实验室的8位同学,独立的给出每组词语的相似度,把得到的数值去掉最高分和最低分,取平均值,结果为表3中的方法4。
为了量化分析和比较各种方法计算词语相似度与人工判断的一致性,我们定义如下概念。
定义3:设Simi和Subi分别表示算法计算和人主观判断的第i对词语的语义相似度,则:对于第i对词语,算法计算结果与人主观判断结果的差为Ei,如式(13)所示。

其中α为阈值,表示Ei超过α时,Ei=1。
定义4:算法结果与人主观判断结果的兼容度Compat如[19]式(14)所示。
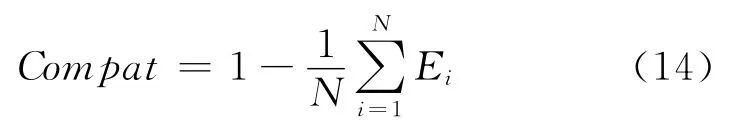
其中,Ei为算法计算结果与人主观判断结果的差;N为样本词语的组数;Compat表示算法计算与人主观判断相似度的吻合程度。
本文使用参数α=0.3和α=Subi求各算法与人主观判断的兼容度,结果如表4所示,且前者阈值固定和后者为人工判断的相似度。
由表4可知,基于HNC计算词语相似度与人主观判断具有较高的吻合度;在两组实验中,本文方法都取得最好的效果,分别为80.3%和84.1%,这说明本文方法与人的直观判断基本一致。
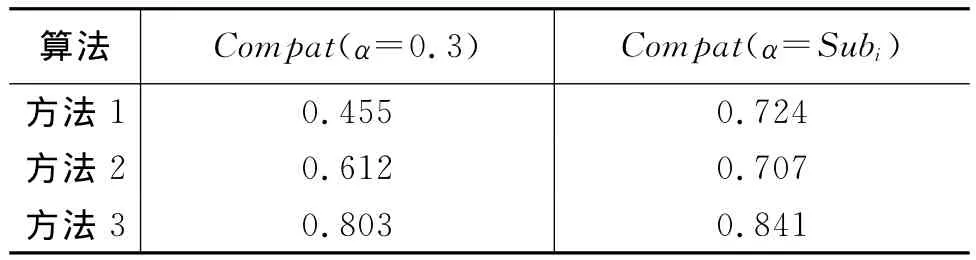
表4 各个算法与人主观判断的兼容度
5 结束语
本文以HNC理论为基础,提出了词语语义相似度的计算方法,该方法充分利用了HNC建立的具有语义信息的概念表达符号体系。根据HNC表达概念的特点,提出词语的语义相似度是通过概念内涵、概念外部特征、概念类别和组合符号来表达的。基于以上观点,构建基于HNC的词语相似度计算公式,并通过实验对比分析验证了该方法的准确性和合理性。目前,HNC的理论也在不断完善与发展,它为计算机理解和处理中文语义提供了很好的平台。在以后的研究工作中,可进一步利用层次符号中的中层符号的特点和不同概念层次树之间的关联性知识,设计更加合理的词汇相似度计算方法。
[1] 刘群,李素建.基于《知网》的词汇语义相似度计算[C]//台北:第三届汉语词汇语义学研讨会.2002:59-76.
[2] Wu Z,Palmer M.Verb semantics and lexical selection[C]//Proceedings of the 32nd Annual Meeting of the Association for Computational Linguistics.Stroudsburg:Association for Computational Linguistics,1994:133-138.
[3] Rada R,Mili H,Bieknell E,et al.Development and application of a metric on semantic nets[J].IEEE Transactions on Systems,Man and Cybernetics,1989,19(1):17-30.
[4] Leacock C,Chodorow M.Combining Local Context and WordNet Similarity for Word Sense Identification[J].An Electronic Lexical Database.1998:265-283.
[5] 李峰,刘芳.中文词语语义相似度计算——基于《知网》2000[J].中文信息学报,2007,21(3):99-105.
[6] 刘青磊,顾小丰.基于《知网》的词语相似度算法研究[J].中文信息学报,2010,24(6):31-37.
[7] 张亮,伊存燕,陈家郡.基于语义树的中文词语相似度计算与分析[J].中文信息学报,2011,24(6):23-29.
[8] 梅立军,周强,臧路,等.知网与同义词词林的信息融合研究[J].中文信息学报,2005,1(19):63-70.
[9] 田久乐,赵蔚.基于同义词词林的词语相似度计算方法[J].吉林大学学报,2010,28(6):602-608.
[10] Ricardo,Berthier.Modern Information Retrieval[M].ACM Press/Addison-Wesley,1999.
[11] Lin D.An Information-Theoretic Definition of Similarity Semantic Distance in WordNet[C]//Proceedings of the Fifteenth International Conference on Machine Leaning.San Francisco,USA:Morgan Kaufmann Publishers Inc.1998:296-304.
[12] 黄曾阳.HNC(概念层次网络)理论—计算机理解语言研究的新思路[M].北京:清华大学出版社,1998:11-43.
[13] 张运良,张全.基于HNC理论的语义相关度计算方法[J].计算机工程与应用,2005,41(34):14-18.
[14] 晋耀红.HNC(概念层次网络)语言理解技术及其应用[M].北京:科学出版社,2006:50-55.
[15] 宋培彦.基于语义网络的中文词汇链构造方法[J].图书情报工作.2011,55(22):26-29.
[16] 史燕.基于HNC的汉语句子相似度算法的研究[D].江苏:江苏大学硕士学位论文,2009.
[17] 许嘉璐.现状和设想——试论中文信息处理与现代汉语研究[J].中国语文,2000,(6):490-496.
[18] 何婷婷.语料库研究[D].武汉:华中师范大学博士学位论文,2003.
[19] 赵巾帼.基于语义距离的概念语义相似度研究[D].湖南:中南大学硕士学位论文,2008.
