Web日志挖掘中的数据预处理技术研究
2014-04-14杨玉梅
杨玉梅
(川北医学院 图书馆,四川 南充 637000)
0 介绍
Web挖掘是数据挖掘在Web上的应用,它利用数据挖掘技术从与WWW相关的资源和行为中抽取感兴趣的、有用的模式和隐含信息,涉及Web技术、数据挖掘、计算机语言学、信息学等多个领域,是一项综合技术。Web使用挖掘能提供网站设计的支持,提供个性化服务和其他的商业决策等。根据挖掘对象不同,大致有三个知识发现领域涉及到Web挖掘:Web内容挖掘、Web结构挖掘和Web使用挖掘,如图1所示。
Web内容挖掘是指对文本、图形、图像、视频、音频、多媒体和其他各种类型的页面数据进行的挖掘。这些数据的结构形式变化多样,可能是数据库中的结构化数据,也可能是网页的半结构化数据,或者是无结构的文本文件。
Web结构挖掘就是对在单个页面内部、特定页面集,或整个Internet的PIW(Publicly index-able Web)等多个尺度上对结构数据进行挖掘以获取增值信息。它的指导思想就是通过图论的方法对Web的拓扑结构进行研究,以获取有用的相关知识。
Web使用挖掘就是通过挖掘Web日志中的用户访问记录来发现Web用户的行为模式。Web使用挖掘中的数据源并不是用户的第一手数据,而是在用户与服务器交互的过程中形成的第二手数据,但是这些数据基本包含了用户访问网络的所有信息。

图1 挖掘分类
1 Web使用挖掘
Web使用挖掘就是通过挖掘Web日志中的用户访问记录来发现Web用户的行为模式。Web使用挖掘中的数据源并不是用户的第一手数据,而是在用户与服务器交互的过程中形成的第二手数据,如登记数据、用户会话、cookies、用户查询、鼠标点击等交互结果,但是这些数据基本包含了用户访问网络的所有信息。Web使用挖掘可以分为个性模式的挖掘和共性模式的挖掘,前者通过统计关联分析等挖掘算法找出特定用户与特定页面、特定时间、特定地域等要素之间的内在联系,为用户提供个性化的服务;后者通过挖掘用户群体的 Web日志获取用户访问的共性规律,对站点的性能和组织结构进行改善,从而将Web用户查找信息的效率和质量提高。Web日志挖掘的主要研究内容包括:日志数据预处理、序列模式挖掘、用户兴趣挖掘等。Web使用挖掘分析用户在一组相关网站与一个Web服务器交互的结果,如Web日志、点击流和数据库事务。Web使用挖掘也被称为Web日志挖掘,可以被视为一个三相过程,如图2所示。
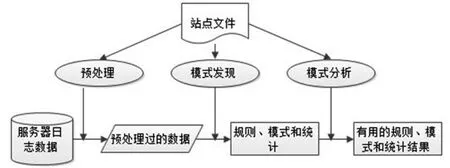
图2 Web使用挖掘过程
(1)数据收集和预处理:数据采集是Web日志挖掘中的一个非常重要的环节,不仅是数据预处理的前提,更是模式发现和分析的基础,其所获取到的数据源质量将会直接影响挖掘的效果。如果采集到的数据源是不完整的,则无论进行什么样的挖掘都是没有意义的,只有对全面的、完整的、能反映用户真实兴趣的数据进行的挖掘才是有意义的。数据预处理是Web日志挖掘的重点,其结果对挖掘算法产生的规则与模式有很大的影响,是保证Web日志挖掘质量的关键。进行数据预处理时应根据不同的应用需求,对冗余数据、干扰数据等进行相关处理,从海量的原始数据中抽取出挖掘算法需要的精确数据。通常根据应用需求包括数据清理、用户识别、会话事务识别等几个方面。
(2)模式发现:对数据预处理所形成的文件,利用数据挖掘的一些有效算法来发现隐藏的模式和关联规则。
(3)模式分析∶主要是对挖掘出来得模式、规则进行分析,找出用户感兴趣的模式,提供可视化的结果输出。
2 Web日志格式
Web使用数据包括从Web服务器的日志数据、代理服务器的日志、浏览日志和用户配置文件。使用数据可以分为3种不同的采集基础:服务器端、客户端和代理端。Web服务器日志文件是纯文本,独立于服务器平台。目前有三种可以用于记录的日志文件格式:w3c扩展日志文件格式、微软IIS日志文件格式和NCSA公用日志文件格式,他们都是ASCII文本格式。Web服务器日志文件包含了服务器的请求、按时间顺序的记录。最大众化的日志文件格式是普通日志格式(CLF)和扩展普通日志格式。一个普通的日志格式文件是由Web服务器创建跟踪发生在网站上的请求。一个标准的日志文件的格式如下:
3 预处理技术
数据预处理是对Web日志进行挖掘的首要前提,它关系到接下来挖掘算法的选取,是最终能否得到有较高效率模式的前提。Web日志文件中存储的是用户访问站点信息的原始记录,这些数据是不完整的(有些感兴趣的属性缺少属性值,或仅包含聚集数据),含噪声的(包含错误或存在偏离期望的孤立点值),并且是不一致的,因此直接在这些数据上进行挖掘是比较困难的。在使用算法或工具对其分析之前,进行预处理,不仅有利于随后的挖掘算法分析,而且对于最终形成准确可靠的用户浏览模式是极为重要的。
Web日志挖掘的数据预处理主要包括数据清洗、用户识别、会话识别、路径补充和事务识别等一系列工作,如图3。对日志进行预处理的结果直接影响到挖掘结果。

图3 数据预处理过程
3.1 数据清洗
数据清洗是清除错误和不一致数据的过程,当然数据清洗不是简单的更新数据记录,在数据挖掘过程中,数据清洗是第一步,即对数据进行预处理的过程。数据清洗的任务是过滤或者修改那些不符合要求的数据。不符合要求的数据主要有不必要得数据、不完整的数据、错误的数据和充分的数据等。比如图形、视频等后缀名为GIF、JPEG、CSS的数据。对于失败的HTTP状态码的纪录,通过在Web访问日志检查每个记录的状态字段,记录状态码超过299或低于200被删除。
3.2 用户识别
用户识别的任务是从原来的Web访问日志找出不同的用户会话。用户的识别是识别谁访问的网站和哪个页面被访问。一个会话是一系列网页用户的单一访问浏览,但要完成这一步是比较困难的,由于代理服务器和防火墙的使用令用户识别匾额复杂。例如,不同的用户在日志可能有相同的IP地址,同一个用户也可以通过不同的IP进行访问。用户识别主要工作需要解决这些问题,目前一般都用启发式规则来识别用户:
不同的IP地址区别不同的用户;如果IP地址是相同的,不同的浏览器和操作系统代表不同的用户。通过这些规则,即可以对用户进行识别。
3.3 会话识别
会话是理解为当用户通过一个给定的站点导航的时候的一系列由用户执行的活动。从原始数据中识别会话是一个复杂的步骤,因为服务器日志不一定包含所需要的信息。有服务器的日志不包含足够的信息来重建用户会话,在这种情况下启发式可以作为描述。如果所有IP地址、浏览器和操作系统相同,推荐信息应该纳入考虑。最简单的方法是面向时间,是基于总会话时间和基于单页面停留时间的另一种方法。页面设置在特定的时间的特定用户被称为网页浏览时间。它的变化范围从25.5分钟到24小时,30分钟时默认超时。第二种方法取决于两个时间戳之间的差异计算的页面停留时间。如果超过10分钟,那么第二项假设为一个新的会话。基于时间的方法是不可靠的,因为用户可能会涉及一些其它的打开网页的活动,或其他因素比如繁忙的通信线路、页面中组件加载时间、页面内容大小没被考虑等。第三种方法基于Web拓扑结构图。
在不同的时间相同的用户,会话识别可能包含以上的访问,时间向导启发式是用来将不同的访问分组为不同的用户会话。用户会话记录在网络日志,路经补全算法应用于获取完整的用户访问路径。
4 相关工作
用户识别是指识别谁访问网站和那些网页被访问。如果用户的登陆信息易于识别。事实上,有很多用户不注册信息。更重要的是,有大量的用户通过代理,多数用户使用同一台计算机,或有防火墙存在,一个用户使用不同的浏览器等访问网站。所有问题使得识别每一个独立的用户变得非常复杂和困难。我们可能使用cookies来跟踪用户的行文。但是考虑个人隐私,许多用户不使用cookie,因此有必要找到解决这个问题的前提方法。当用户使用同一台计算机或使用相同的代理时怎么识别他们?
提出方法不同的用户识别
针对这种现状,我们提出了一种新的算法称为独特用户识别(distinct user considering,DUI)。分析了诸多因素,如用户的IP地址、网站的拓扑结构、浏览器版本、操作系统和推荐页面。该算法有更好的精度和可扩展性。它不仅可以识别用户还可以识别会话。会话识别将在下一节讨论。提出的方法不仅显示基于用户IP,某处相同的用户IP可以产生不同的Web用户,基于任何用户选择的路径和链接页面的访问时间,我们找出不同的Web用户。给出一个清洁、过滤Web日志文件和记录集Web日志文件。记录R={r1,r2,r3…rn},这里n>0
Step 1:输入N个记录到日志数据库RUser
Step 2:不同的用户识别数据库
Step 3:RUSer=
Step 4:while(i Step 5:读取日志数据库RUser Step 6:检查如果r(i)用户IP不属于不同的用户识别数据库,那么它将作为新用户复制用户IP到不同的用户识别数据库。 Step 8:end if Step9:i=i+1 Step10:end loop Step11:end 为了验证该方法,及它的有效性和效率,我们对本校图书馆Web服务器IIS日志文件进行实验。我们的实验的初始数据源是从2011年1月1日到2013年6月30日,它的大小是1.03GB。我们实验在Intel(R)Core(TM)i3-2120 CUP@3.30GHz,2G内存,Windows 2003 professional,SQL Server 2005上执行。下图是我们的实验内容和结果。经过数据清洗,请求的数量从252167降到35685. 图4 日志文件部分内容 图5 清理后数据 表1 实验结果 在本研究中我们提出了不同的用户识别技术,其增强预处理在数据挖掘中的Web日志使用数据的步骤。这里介绍了一个先进的预处理不同的用户识别算法,该算法相对其他识别技术是非常有效的。在此基础上,我们可以针对具体情况,设计个性化网站,提高网站利用率。 [1]庞英智.Web数据挖掘技术在电子商务中的应用[J].情报科学,2011,29(2)∶235-240. [2]刘树超,李永臣,武洪萍.Web数据挖掘研究与探讨[J].制造业自动化,2010(9)∶163-166. [3]谭春辉,王俊.基于Web数据挖掘技术的企业网站客户忠诚度提升模型研究[J].图书情报工作,2009,53(14)∶138-142. [4]陈立建.基于Web数据挖掘技术的远程教育系统构建[J].中国成人教育,2010(6)∶116-118. [5]侯枫.Web日志数据预处理[J].河南工程学院学报:自然科学版,2008,20(3)∶54-57. [6]陈宝树,党齐民.Web数据挖掘中的数据预处理[J].计算机工程,2002,28(7)∶125-127.5 实验结果和分析


6 结论
