煤质数据库的建立方法
2014-03-16王洋赵明梁俊宇邱亚林
王洋,赵明,梁俊宇,邱亚林
(1.华北电力大学云南电网公司研究生工作站,昆明 650217; 2.云南电网公司电力研究院,昆明 650217)
煤质数据库的建立方法
王洋1,赵明2,梁俊宇1,邱亚林2
(1.华北电力大学云南电网公司研究生工作站,昆明 650217; 2.云南电网公司电力研究院,昆明 650217)
介绍为了保障节能发电调度中煤耗实时在线监测系统的准确性,减少煤质的复杂性和人为离线输入的不确定性对锅炉效率在线计算造成的偏差,采用统计分析和聚类计算等方法,构建了针对特定区域电厂的煤质数据库的方法。
煤质数据库;锅炉效率;在线监测;节能发电调度
1 前言
以等利用小时数按计划平均分配发电指标的传统调度方式没有考虑机组的性能和运行状态,导致我国的电力生产处于高能耗、高污染、低效率的粗放式增长模式。节能发电调度按照节能、经济的原则,优先调度可再生发电资源,按照机组能耗和污染物排放水平由低到高排序,依次调用化石类发电资源,最大限度地减少能源、资源消耗和污染物排放[1]。煤耗实时在线监测系统作为节能发电调度的重要保障手段,其准确性对于负荷分配的公平、公开、公正有着至关重要的作用。
锅炉效率在线计算的准确性对煤耗在线计算结果有着重要的影响,而在锅炉效率计算中,煤质是最主要的影响因素之一。随着电煤价格矛盾的日益突出,电厂用煤的来源和成分都复杂多变,各种煤质互掺燃烧使得入炉煤质很难确定[2-3]。而且,目前煤质成分的实时测量技术尚不成熟,常采用的离线取样分析方法存在结果滞后、误差大等问题,煤质数据的实时性得不到满足。
收集特定地区的历史煤质数据,通过统计分析和聚类计算等方法建立该地区的煤质数据库,以收到基低位发热量为索引,选取数据库中 “虚拟煤质”的元素成分进行锅炉效率的在线计算,可以很好的避免由人为化验、离线输入带来的各种问题,提高锅炉效率在线计算的准确性,从而保障了煤耗在线监测系统的公平、公开与公正。
2 理论基础
煤是植物残骸在适宜的地质环境中,经过了漫长的物理、化学和生物的复杂作用而形成的有机生物岩石。成煤物质、成煤条件和成煤年代等因素的复杂多变导致了煤质种类的多样性和煤质结构的复杂性[4]。
通过煤的元素分析可知,煤主要由 C、H、O、N、S以及水分和灰分构成:
C+H+O+N+S+M+A=100% (1)
式中:C、H、O、N、S、M、A分别为碳、氢、氧、氮、硫、水分、灰分的质量百分数,%。
根据用途的不同,煤的元素分析结果表示也不一样,在煤质特性研究中使用干燥无灰基(daf)表示:
Cdaf+Hdaf+Odaf+Ndaf+Sdaf=100% (2)
式中,Cdaf、 Hdaf、 Odaf、 Ndaf、 Sdaf分别为碳、氢、氧、氮、硫的干燥无灰基质量百分数,%。
研究表明[5-7],随着煤化程度的加深,煤中的碳含量不断增加,同时,氢和氧的含量逐渐减少。Hdaf—Cdaf、Odaf—Cdaf之间有良好的线性关系,如下式所示:
Hdaf=a1Cdaf+b1(3)
Odaf=a2Cdaf+b2(4)
对于我国大多数煤来说,煤中的氮与氢含量存在如下关系:
Ndaf=cHdaf(5)
式中,a1、a2、b1、b2、c为干燥无灰基组成特性系数,通过线性回归可以得到系数的经验值。
煤中硫的含量与煤的变质程度关系不明显,硫含量的高低主要取决于成煤时的沉积环境。
由此可知,煤质典型的多变性不在于它的干燥无灰基成分,而在于它所含的水分和灰分。对于同一类型的煤种,特别是同一或者临近矿点的煤种,煤质的干燥无灰基成分相对稳定,变化不大。
所以,通过统计分析,获取特定区域电厂燃煤较稳定的干燥无灰基成分,并与统计处理后的水分和灰分组合,可以得到该地区电厂燃煤煤质的工程数据库。
3 煤质数据库的建立
3.1 总体思路和模型
以发热量为索引去煤质数据库中取用煤质时,是用锅炉实际吸热量近似等于收到基低位发热量:
Qs=Qar,net(6)
式中,Qs为锅炉实际吸热量,kJ/kg;Qar,net为收到基低位发热量,kJ/kg。
煤质数据库中的发热量通过计算得到,为了提高计算的准确度,选用元素分析结果进行计算。所以,统计电厂历史煤质的收到基水分和灰分以及电力试验研究院化验得到的干燥无灰基元素成分,最终通过计算整理,构建出以收到基低位发热量为索引的煤质元素分析结果,如表1所示:

表1 煤质数据库的形式
3.2 数据分析整理
3.2.1 基于划分方法的聚类算法
聚类算法根据最大化簇内相似性和最小化簇间相似性的原则对数据对象进行自动分类,主要有划分方法、层次方法、基于密度和基于网格的方法,其中划分方法最基本也最常用[8]。划分方法主要有k-均值 (k-means)和k-中心点 (kmedoids)两种。
k-均值是一种基于形心的聚类技术,使用分配给该簇对象的均值作为形心,用簇内变差来度量簇的质量,通过不断改变簇内对象并不断计算形心来达到局部的最优聚类。簇内变差定义为簇内所有对象和形心之间的误差的平方和,误差通常选用对象与形心之间的欧氏距离。k-中心点是一种基于代表对象的聚类技术,与k-均值不同的是,簇的形心不是簇内对象的均值,而是挑选实际的对象来代表簇。算法基于最小化所有对象与其对应的代表对象之间的相异度之和的原则来进行划分。围绕中心点划分 (Partitioning Around Medoids,PAM)算法[9]是k-中心点聚类的一种流行的实现。k-中心点算法比k-均值算法的计算花销大很多,但是其对噪声和离群点的敏感性明显降低。
3.2.2 水分和灰分的处理
统计电厂用煤收到基水分Mar和灰分Aar,通过散点图获取其大致的分布区间,如图1所示:
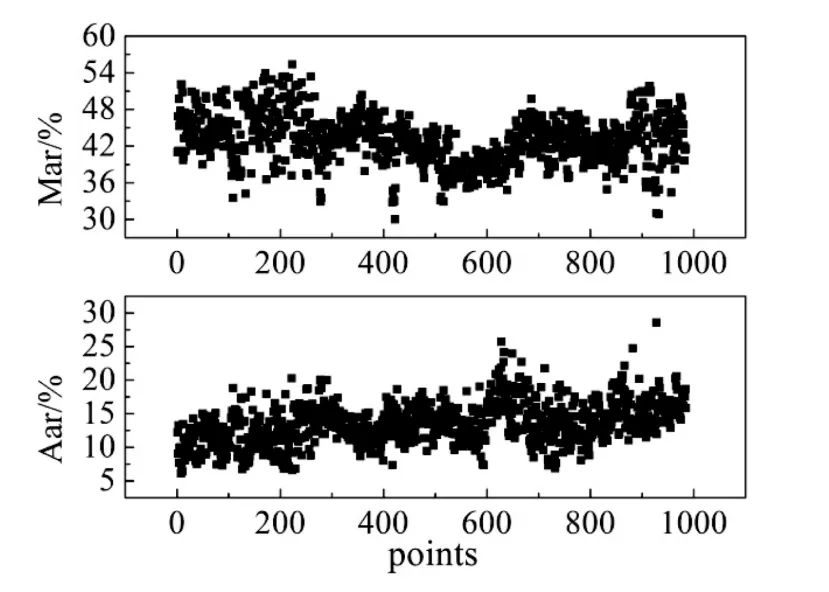
图1 Mar与Aar的分布范围
从图1可以看出收到基水分Mar的分布范围是35%~55%,收到基灰分Aar的分布范围是10%~17%。
将水分和灰分数据进行顺序排列,剔除明显存在统计错误的离群点,然后将数据导入MATLAB软件,调用软件自带的kmeans函数,将水分和灰分数据分别聚类成7类,调用格式如下:
[IDX,C]=kmeans(X,7) (7)
其中,X是水分和灰分的原始数据,IDX返回各对象的类标号,聚类后各簇的形心在矩阵C中。簇内各点与形心的距离采用默认的欧几里得距离。
矩阵C中的值是聚类得到的各个簇内的数据均值,可以作为该簇的代表。使用聚类获取的7个均值可以较好的反应原始数据的分布特征。如图2所示:
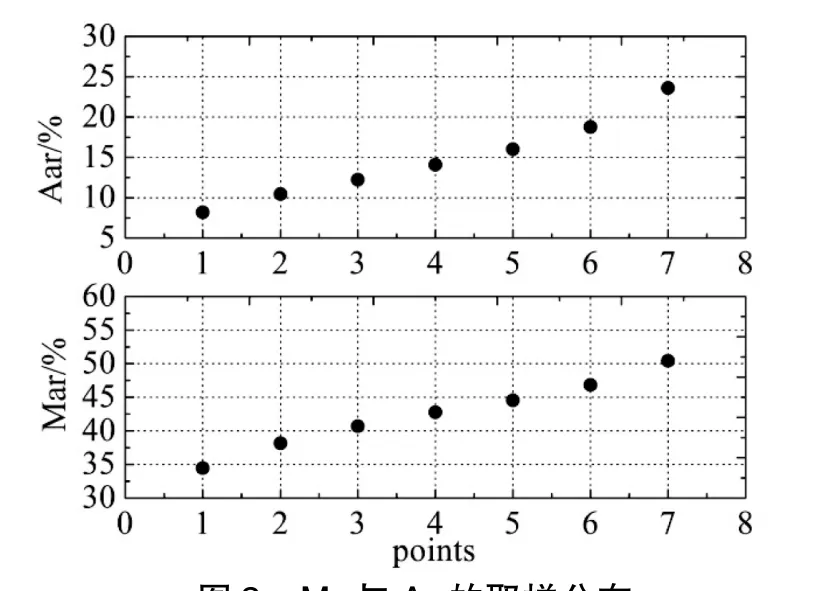
图2 Mar与Aar的取样分布
3.2.3 干燥无灰基成分的处理
统计电力试验研究院试验期间化验的煤质数据,将其换算成干燥无灰基元素成分。采用PAM算法从统计得到154种试验煤质中选取典型煤质作为分析对象。
每个数据对象含有6个属性,分别为 Cdaf、Hdaf、 Odaf、 Ndaf、 Sdaf以及Qdaf,net, 其中 Qdaf,net为煤质的干燥无灰基低位发热量,用以检验数据库中发热量的计算值的准确性。在MATLAB软件中进行PAM算法代码开发,算法的流程如下:
1)输入:簇的数目k和包含n个对象的数据集合D;
2)从D中随机选择k个对象作为初始的代表对象或中心点;
3)Repeat
4)将每个剩余的对象分配到最近的代表对象所代表的簇;
5)随机选择一个非代表对象Orandom;
6)计算用 Orandom代替代表对象 Oj的总代价S;
7)If S<0,then Orandom替换 Oj,形成一个新的k个中心点的集合;
8)Until不发生变化;
9)输出:k个簇的集合。
计算时导入煤质数据并输入k=40,得到聚类后的40种典型煤质成分,以此作为煤质数据库构建的干燥无灰基成分。部分典型煤质数据如表2所示。
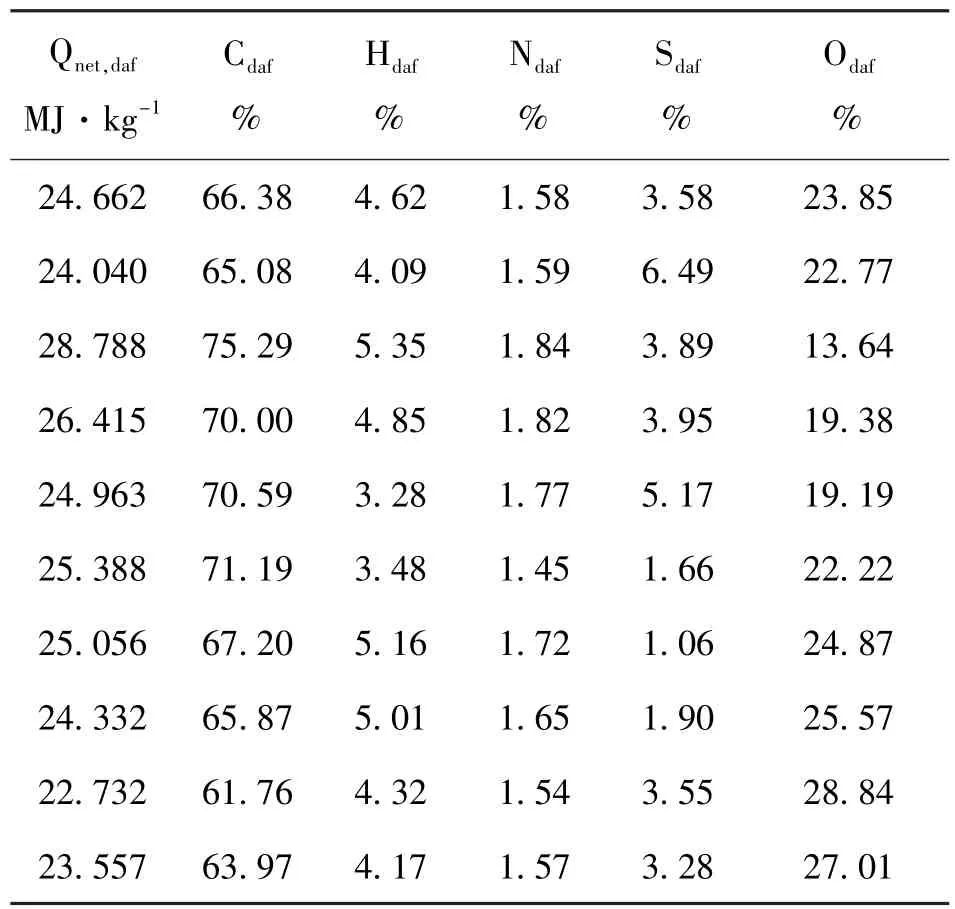
表2 典型煤质的干燥无灰基成分
把构造的收到基水分、灰分与选取的干燥无灰基元素成分的样本进行组合,就得到了7×7×40 =1 960种 “虚拟煤质”。
3.2.4 发热量的计算
煤的收到基低位发热量是锅炉热平衡、热效率、出力计算以及运行参数调整的重要依据,同时也是动力煤计价的主要指标,有着重要的技术和经济价值。利用元素分析结果计算煤的发热量有许多经验公式[10],如:
杜隆公式:
Qgr,daf=337.9Cdaf+1 441(Hdaf-0.125Odaf) + 104.5t,daf(8)
门捷列夫公式:
Qgr,daf=338.7Cdaf+1 254.5Hdaf-108.7Odaf+ 08.7St,daf(9)
适用于我国褐煤的回归式:
Qgr,daf=334.5Cdaf+1 275.4Hdaf-108.7Odaf+ 92St,daf-25.1(Ad-10) (10)
式中:Qgr,daf为干燥无灰基高位发热量,kJ/ kg;Ad为干燥基灰分,%。
各公式对不同的煤质成分有不同程度的适应性,本例中煤质为褐煤,经过计算和比较,最终选取发热量的计算公式[11]为:
Qar,gr=4.19(87Car+300Har+26Sar-26Qar)
(11)
最后,将计算结果全部换算到收到基,将公式计算得到的高位发热量换算成低位发热量。高、低位发热量换算采用公式[12]如下:
Qar,net=Qar,gr-206Har-26Mar(12)
4 结果与分析
4.1 发热量校验
采用上述方法建立的煤质数据库是否在实用允许误差范围之内,主要看其发热量是否和化验值相符。使用计算发热量与化验获取发热量的差值ΔQar,net来进行检验。

式中: Qj为收到基低位发热量计算值,
ar,netkJ/kg;Qsar,net为收到基低位发热量化验值,kJ/kg。
数据库中所有煤种发热量的计算误差如图3所示:
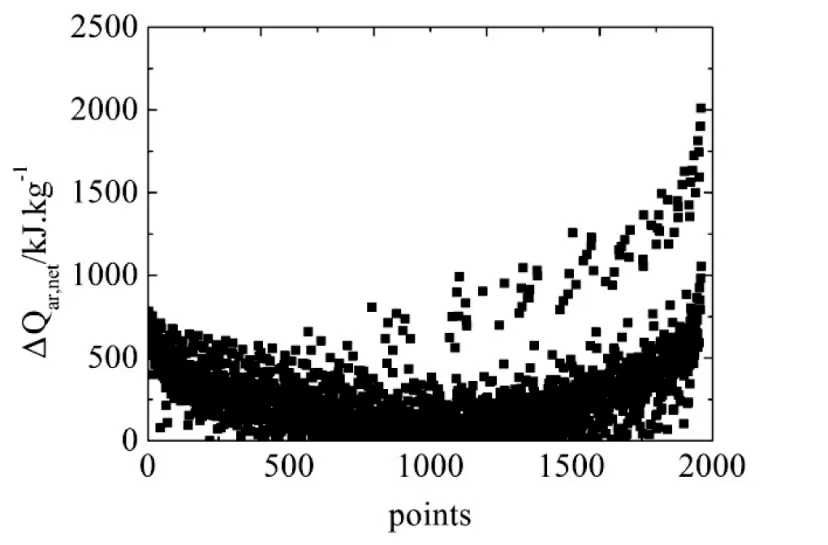
图3 计算发热量与试验值的误差
由图3可知,大部分煤质发热量计算值都比较准确,只有少数的一些点误差较大。结合数据分析得到,总体误差在0.37~2 011.12 kJ/kg之间,其中误差在600 kJ/kg以内的煤种占92.4%,总体匹配度较好。
由于煤质数据库中的煤种是根据实际煤质的干燥无灰基成分和人为给定的水分、灰分组合而来,是一种 “虚拟煤质”,其各元素成分的组成不一定能够满足基于大量实际煤质成分而得到的经验公式,小部分煤质热量的计算误差较大是可能存在的。
按照发热量大小对所有煤种进行排序,发现计算误差较大的煤种发热量并没有集中在某一个热量区域中,而是较均匀的分布于各个热量区间。所以,实际应用中删去这些煤种后不会影响总体的热量分布。本例中删去了误差大于600 kJ/kg的149种煤质。
4.2 数据库精简
针对实际应用过程中,由于煤质数据量太大而导致计算程序运行缓慢的问题,对煤质数据库的数据总量进行了精简。
将发热量升序排列后,计算出前后相邻煤种间的热量差值,以此作为相邻煤种的热量间距。当前后两种煤质热量相差很小时,可以删除其中一种,以达到精简数据库的目的。
计算后发现相邻煤种的热量间距值分布如图4所示:
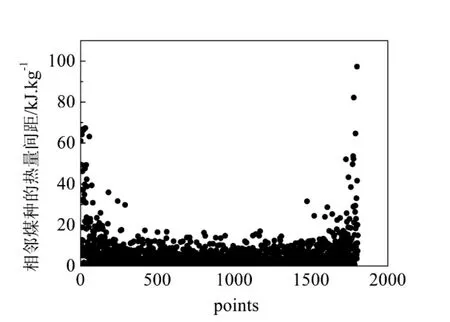
图4 相邻煤种的热量间距
由图4可知,只有少数煤种的热量间隔较大(有6种大于100 kJ/kg的煤种没有在图上显示)大部分热量间距都分布在10 kJ/kg以内。删除热量间距在5 kJ/kg以下的煤质数据,剩余580种煤质。这些煤质同时满足计算误差和热量间距的要求,使得数据库内煤质在保证准确性的同时,大大精简了数据量,提高了在线计算的效率。
4.3 实际应用
将构建的煤质数据库运用到煤耗在线监测系统的软件计算包中,根据现场实时采集的参数计算锅炉实际吸收热量值并取用煤质数据库中的“虚拟煤质”进行煤耗的实时在线计算。
一般来说,火电厂一天之内煤质化验的平均值是有代表性的,能较好地反映当天燃用的平均煤质。为了评估煤质数据库中选取的煤质与现场煤质的差异,验证煤质库的可靠性,将2012年12月10日至12月31日取用的 “虚拟煤质”与现场化验煤质的收到基低位发热量进行对比,结果如图5所示。

图5 数据库煤质发热量与电厂化验值的对比
从图5中可以看出,电厂化验煤质的发热量与煤质数据库选取 (计算值)的发热量在趋势上保持了高度的一致性,两者最大的差别约为700 kJ/kg左右。如果考虑电厂化验发热量的允许误差为±500 kJ/kg,则煤质数据库的选取结果完全可以满足锅炉效率在线计算的要求,适合于工程实际应用。另外,采用同样的方法建立的煤质数据库的应用有效的统一了特定地区各个火电厂的煤质数据来源,有效保障了煤耗在线监测系统的公平、公开与公正性。
5 结束语
1)煤质所含的水分和灰分是导致其多变性的主要原因,可以通过组合实际煤种相对稳定的干燥无灰基成分与人为给定的水分和灰分得到“虚拟煤质”。
2)基于划分方法的聚类算法适用于获取水分、灰分的代表值和煤质干燥无灰基成分的典型值,获取的样本点能够很好的保留母体的分布特征。
3)利用构建煤质的元素分析结果计算得到的煤质发热量与试验测取的发热量匹配度较好,计算误差在600 kJ/kg以内的煤种占92.4%。
4)采用构建的虚拟煤质数据库进行锅炉效率的在线计算时,计算中取用的煤质发热量与电厂当天化验的煤质发热量在趋势上保持了高度的一致性,两者最大的差别约为700 kJ/kg左右。因此,建立的煤质数据库可以满足工程实际应用,有效保障了煤耗在线监测系统的公平、公开与公正性。
[1] 王庭飞,孙斌,等.节能发电调度技术研究及实践与效果分析 [J].南方电网技术.2009,(3):1.
[2] 苏保光,田亮,等.一种在线煤质软测量方法 [J].电力科学与工程.2011,27(7):32.
[3] 高小涛.电站锅炉燃用混煤的煤质特性分析 [J].江苏电机工程.2009,28(1):63.
[4] 周桂萍.电厂燃料 [M].北京:中国电力出版社,2007.
[5] 刘福国.电站锅炉入炉煤元素分析和发热量的软测量实时监测技术 [J].中国电机工程学报.2005,25(6):140
[6] 刘福国,郝卫东,韩小岗,等.基于烟气成分分析的电站锅炉入炉煤质监测模型 [J].燃烧科学与技术,2002,8 (5):442-443.
[7] 谢克昌.煤的结构和反应性 [M].北京:科学出版社,2002.
[8] 韩家炜 (Han,J.),等.数据挖掘概念与技术 [M].北京:机械工业出版社,2012.
[9] 陈志强,刘钊,张建辉.聚类分析中PAM算法的分析与实现 [J].计算机与现代化.2003,9:1-2.
[10] 陈文敏.煤的发热量和计算公式 [M].北京:煤炭工业出版社,1989.
[11] 范从振 .锅炉原理 [M].北京:水利电力出版社,1986.
[12] 樊泉桂 .锅炉原理 [M].北京:中国电力出版社,2004.
A Method for Building a Coal Quality Database
WANG Yang1,ZHAO Ming2,LIANG Junyu1,QIU Yalin2
(1.Postdoctoral and Graduate Workstation of North China Electric Power University and Yunnan Power Grid Corporation,Kunming 650217; 2.Yunnan Electric Power Research Institute,Kunming 650217)
In order to ensure the accuracy of the online monitoring system for coal consumption in the energy-conservation power generation dispatch,a coal quality database for the power plants in a certain area was built based on the method of statistical analysis and clustering caculation to reduce the errors caused by the complex coal quality and the off-line input during the online calculation of the boiler efficiency.The results show that the errors less than 600 kJ/kg between the caculated heat of“virtual coal”and the laboratory values can be up to 92.4%.And the heat obtained from the database matches well with the laboratory values in the power plants in practical application,with the maximum error less than 700 kJ/kg.It can enhance the fairness and impartiality of the online monitoring system for the power plants in a certain region using the virtual coal database during the online calculation of boiler efficiency.
coal quality database;boiler efficiency;online monitoring;energy-conservation power generation dispatch.
TK3
B
1006-7345(2014)01-0044-05
2013-06-25
王洋 (1988),男,硕士研究生,云南电网公司研究生工作站,从事煤耗在线监测方面的相关研究 (e-mail)angus081428 @163.com。
