基于阶段递进的综合本体相似度计算方法
2014-03-15王国春郑山红董亚则
王国春,郑山红,赵 辉,董亚则
(长春工业大学a.软件职业技术学院;b.计算机科学与工程学院,长春 130012)
0 引言
随着本体的应用日益广泛,各领域都出现了大量的本体,只有把这些领域本体进行合并,才能充分利用已有的本体资源。本体合并的关键技术就是本体概念间的语义相似度计算,概念语义相似度计算已成为当今信息技术研究的一个热点[1]。目前概念的相似度计算主要有两种方法:1)基于语义网的概念相似度计算,包括通过语义距离、深度和广度进行概念的相似度计算;2)通过概念的属性、关系和实例等进行的综合相似度计算[2]。但这两种方法都有不足,基于语义网络的相似度计算局限性较强,语义网络本身就不完善,计算结果容易片面。而综合的本体相似度计算方法需要分别计算整个本体[3]中所有概念的属性、关系和实例的相似度,计算整个过程掺杂柔和在一起,导致计算过程很难控制,计算较复杂,有时甚至会出现计算组合爆炸的问题。传统相似度计算方法在对概念的相似度进行综合时,存在权值过多和难以准确确定等问题。
针对上述问题,笔者提出了一种基于阶段递进的综合本体相似度计算方法。该方法把计算相似度的过程分为4个阶段,前3个阶段分别计算概念的实例相似度、概念间的属性相似度和关系相似度,第4阶段通过主因素分析方法综合前3个阶段的相似度,得到概念的相似度。通过为每个阶段设定一个计算阈值的方法来减少相似度的计算量,通过实验数据表明,该算法在查全率、查准率和计算效率方面比Glue算法有较大提高。
1 基于阶段递进的综合本体相似度计算方法
1.1 基于阶段递进的综合本体相似度计算算法
描述基于阶段递进的综合本体相似度计算方法,把计算相似度的过程分为4个阶段:第1阶段计算概念的实例相似度;第2阶段计算概念间的属性相似度;第3阶段计算概念间的关系相似度;第4阶段将前3个阶段计算出的相似度进行综合,通过主因素分析的方法确定各部分的权重[4],得到概念的相似度。每个阶段根据实际情况设定一个阈值,如果此阶段计算的相似度大于阈值,则计算下一阶段的相似度,如果小于阈值,则认为该对概念间不相似,不必再计算以下各阶段的相似度。

1.2 第1阶段实例相似度计算
本体库中每个概念都有很多具体的实例,一个概念的实例也是他祖先类的实例。如果一个概念对的实例完全相同,则这两个概念是相关和相同的,如果这两个概念的实例相同的比率较高,则这两个概念是相近的[5]。
概念Ca和概念Cb的实例相似度记为I(Ca,Cb),计算函数为
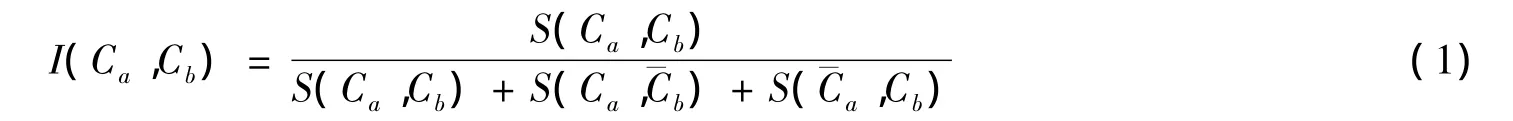
其中I(Ca,Cb)的取值范围为[0,1],两个概念相同为1,两个概念不同为0。
应用概念的实例计算相似度包括 S(Ca,Cb)概率、概率和 S(,Cb)概率。S(Ca,Cb)概率是从本体库中进行随机选择一个实例,并且该实例属于概念Ca,同时该实例属于概念Cb的概率。
1.3 第2阶段属性相似度计算
两个概念的属性是否相同或相近,主要取决于这两个概念的属性类型、属性名称和属性的值是否相同或相近。属性名称表示属性所描述的概念特征,属性类型表示所描述的属性取值情况和范围,属性的值表示属性的取值,所以属性相似度计算主要计算属性的名称、类型和属性值的相似度。属性的名称和字符可应用字符比较的相似度计算方法[6,7],设有两个字符m和n,则m和n的相似度
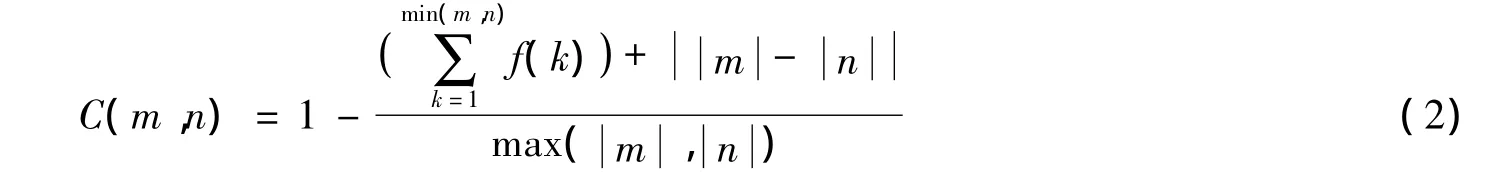
当 m[k]=n[k]时,f(k)=0,否则 f(k)=1。
设有概念 Ca的属性集合为 ACa(ACa1,ACa2,…,ACai),概念 Cb的属性集合为 ACb(ACb1,ACb2,…,ACbj),则概念Ca和Cb的属性相似度为
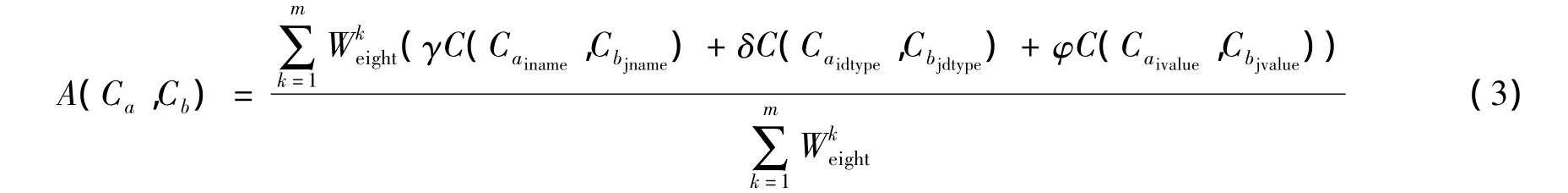
其中m表示概念C1和C2需要计算属性的个数,相应的权值为Wkeight,γ代表属性名称的权重,δ代表属性类型的权重,φ代表属性取值的权重,γ+δ+φ=1。
1.4 第3阶段关系相似度计算
本体库中的概念对都存在着特定的关系,这些关系描述概念间的紧密程度,关系主要包括关系名称和关系类型。计算本体中关系的相似度,可以通过计算关系名称和类型得到。关系名称和类型可以应用基于字符处理的相似度计算方法。
有概念 Ca和 Cb,其存在的关系集合为(RCa1,RCa2,…,RCai)和(RCb1,RCb2,…,RCbj),概念 Ca和概念 Cb共需要计算的相似度个数为m,通过设置相应的权为则概念Ca和概念Cb的关系相似度为
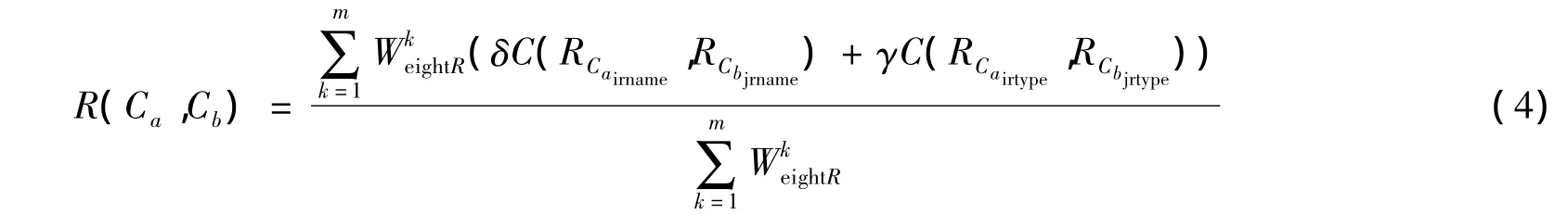
其中δ表示关系名称的权重,γ表示关系类型的权重,δ+γ=1。
1.5 第4阶段综合相似度计算
1)主因素分析。在递进的前3个阶段分别计算了概念的实例相似度、属性相似度和关系相似度,在第4阶段需要综合前3个阶段的结果,得到综合的相似度,这需要设置一些权值。权值设置的优劣直接影响到相似度计算的结果,而现在综合相似度计算的权值确定主要依靠领域专家的经验和多次试验得到,具有很大的随机性和片面性,所以通过主因素分析方法[8],即通过提取决定概念相似度的主要因素,将主因素对相似度的影响率作为分配权重的参考依据,使权重设置更加合理,提高相似度计算的准确性。
2)综合相似度计算。根据前3个阶段的计算结果,参考权重设置的值,推出概念对相似度为

其中α+β+δ=1,权值的确定通过主因素分析得到。
2 实验与性能分析
实验选择的是一个环境特征的本体片段(http://www.environmentontology.org/)。该本体片段描述了环境的特征信息,包括山地、河流、池塘、平原和喀斯特等环境特征的概念。从中随机选取了50对概念,通过笔者的相似度计算方法与Glue[9]方法的比较(见表1),进行实验数据分析。验证算法的有效性一般采用对概念的查全率和查准率进行衡量,查全率为通过计算发现的概念对数与可能存在的概念对数的比值,查准率为专家认为正确的概念对数与通过计算发现的概念对数的比值。

表1 相似度计算实验数据Tab.1 Similarity calculation of experimental data
由实验数据可知,笔者的算法在查全率和查准率两个方面比Glue算法和MAFRA都有较大提高,且该计算效率也有较大幅度的提高。各阶段权值的设置对算法计算时间的影响较大,当第1阶段权值较小时,系统运算效率最高,但查全率和查准率会有所下降;当各阶段权值设置较均衡时[10],系统运算效率下降,但查全率和查准率较高,所以权值的设置对系统的运算效率有较大影响。应用该方法能较大地减少计算相似度的工作量,提高了计算效率。通过设置合理的权重,得到了较精确的相似度值。但该方法也存在一些不足,在递进过程中,需要对每个阶段设置一个阈值,而阈值设置的合理性需要大量的实际经验而确定,对本方法的应用增加了一定的难度。
3 结语
笔者提出一种基于阶段递进的综合本体相似度计算方法。该方法把计算相似度的过程分为4个阶段,各阶段计算的相似度与设定的阈值进行比较,以此决定是否继续进行相似度计算。最后将各阶段计算的相似度进行综合,通过主因素分析的方法确定各部分的权重,得到综合概念的相似度。实验证实,该方法较大地减少了相似度的计算量,并且权重设置较合理,有一定的实用价值。
[1]MADHAVAN J,BERNSTEIN P A,RAHM E.Generic Schema Matching with Cupid [C]∥Proceedings of the 27th International Conference on Very Large Data Bases.Menlo Park,CA,USA:AAAI Press,2001:49-58.
[2]DOAN A,MADHAVAN J,DOMINGOS P.Learning to Map between Ontologies on the Semantic Web[C]∥Proc World-Wide Web Conf.[S.l.]:ACM Press,2002:662-673.
[3]EHRIG M,SURE Y.Ontology Mapping-An Integrated[C]∥Proceedings of the 1st European Semantic Web.Heraklion,Greece:Springer,2004:76-91.
[4]EHRIG M,STAAB S.QOM-Quick Ontology Mapping[C]∥Proceedings of the 3rd International Conference on Semantic Web(ISWC).Hiroshima,Japan:Springer,2004:683-697.
[5]刘欣荣,阳光.一种改进的基于加权模型的概念相似度计算方法[J].微电子学与计算机,2012,29(2):13-17.LIU Xinrong,YANG Guang.An Improved Model Based on Weighted Concept Similarity Calculation Method [J].Microelectronics and Computer,2012,29(2):13-17.
[6]崔其文,解福.改进的领域本体概念相似度计算方法[J].计算机应用与软件,2012,29(2):173-174.CUI Qiwen,XIE Fu.Improved Domain Ontology Concept Similarity Calculation Method[J].Computer Applications,2012,29(2):173-174.
[7]曹泽文,钱杰,张维明.一种综合的概念相似度计算方法[J].计算机科学,2007,34(3):174-175,191.CAO Zewen,QIAN Jie,ZHANG Weiming.A Compositive Approach for Concept Similarity Computation [J].Computer Science,2007,34(3):174-175,191.
[8]韩佳伟,KAMBER M.数据挖掘概念与技术[M].范明,孟晓锋,译.北京:机械工业出版社,2007,10(2):12-14.HAN Jiawei,KAMBER M.Data Mining Concepts and Techniques[M].Beijing:Mechanical Industry Press,2007,10(2):12-14.
[9]程勇,黄河.一个基于相似度计算的动态多维概念映射算法[J].小型微型计算机系统,2006,27(6):22-24.CHENG Yong,HUANG He.A Similarity Based Dynamic Multi-Dimension Concept Mapping Algorithm [J].Mini-Micro Systems,2006,27(6):22-24.
[10]李文杰,赵岩.基于本体结构的概念间语义相似度算法[J].计算机工程,2010,36(23):4-6.LI Wenjie,ZHAO Yan.Based on Body Structure Concept Semantic Similarity Algorithm[J].Computer Engineering,2010,36(23):4-6.
