基于过抽样技术的P2P流量识别方法*
2014-03-12钱亚冠
钱亚冠,张 旻
(1.浙江科技学院理学院 杭州 310023;2.杭州电子科技大学计算机学院 杭州 310018)
1 引言
近年来,P2P技术已被广泛应用于文件共享、视频内容分发、即时通信等网络应用领域。自2004年以来,P2P流量在整个互联网流量中逐渐占据主导地位(60%以上)[1,2]。P2P流量的快速增长给网络带宽带来了巨大压力,其近乎对称的流量模式更加剧了网络的拥塞。同时,基于P2P技术的恶意流量也开始肆虐互联网,造成带宽的过度消耗,甚至导致拒绝服务[3]。因此,如何快速正确地识别P2P流量已经成为当前网络管理者面临的巨大挑战。
互联网流量的识别技术经历了最初的基于TCP端口、深度分组检测(deep packet inspection,DPI)到目前兴起的机器学习方法和基于网络行为的识别等技术[4]。有的P2P应用为了躲避检测,开始采用动态端口、数据分组加密等技术手段,使得基于TCP端口与DPI的方法效率越来越低。而基于统计学的机器学习方法却可以克服上述不足,因而它逐渐显示出在P2P流量分类中的优势[5]。
传统的机器学习方法通常假设目标类是均匀分布的,而实际的互联网流量中的各种应用的分布是不均匀的。尤其是P2P这样的大象流(elephant traffic),它们按字节数统计在流量上占很大比例,对网络性能的影响很大,但从数据流(flow)角度统计却占很少比例[6]。目前基于机器学习的流量分类方法通常基于数据流的统计信息,因此占数据流比例很小的P2P流量往往难以识别,分类器倾向于将P2P数据流识别为如WWW这样的多数类。这种目标类比例严重失衡而导致少数类识别误差增大的问题通常称为类不平衡(class imbalance)问题,是目前P2P流量难以识别的一个重要原因。
网络流量中的众多应用比例极不均衡,流量分类问题面临的是多类不平衡问题[7]。而P2P应用本身在数据流中所占比重很小,又受到其他应用目标类的干扰,本文提出将P2P识别中的多类不平衡问题转化为两类不平衡问题的思路,并通过过抽样(over-sampling)方法增加P2P流量的比重,消除分类器在学习过程中的偏倚,提高P2P的识别率。本文提出改进的迭代SMOTE(i-SMOTE)过抽样方法来提高Na觙ve Bayes算法的识别率,实验结果证明本文提出的识别框架具有良好的识别性能。
2 类不平衡问题与SMOTE过抽样方法
目前基于机器学习的流量分类方法大多利用数据流层面的统计信息。因此像P2P这类应用,尽管在字节流上占很大比重,在数据流层面却占很小的比例,与WWW应用相比存在严重的不平衡性。这种不平衡性将导致P2P很高的误分类率。传统的机器学习分类算法旨在最小化全局分类误差,并假设假正例与假负例的错误代价是相等的,因此偏向于把少数类预测到多数类上,如将P2P预测为WWW。而实际网络管理过程中,可能对于识别类似P2P这样的少数类更有价值,因此需要有提高P2P识别率的有效方法。为了克服上述类不平衡问题,机器学习界提出重抽样技术来平衡目标类的分布,即对多数类(majority class)进行欠抽样 (under-sampling),对少数类(minority class)进行过抽样(over-sampling)。
传统的欠抽样与过抽样技术都具有自身的不足:对多数类欠抽样会导致一些信息的丢失,而对少数类的简单重复抽样在早期的研究中就已发现对于提高分类性能并无太大的帮助[8]。因此,Chawla N V等[9]提出了新的过抽样技术SMOTE算法,其基本思想是通过人工合成新的少数类样本来减轻类别的不平衡,解决传统过抽样技术因决策域变小而引起的过拟合现象。SMOTE算法的基本原理是在相距较近的少数类样本之间进行线性插值,从而生成新的少数类样本。首先根据过抽样倍率N,从每个少数类样本k(默认取5)个同类最近邻中随机选择N个样本;接着将每个少数类分别与它的N个选中的样本按式(1)合成N个新的少数类样本,并加入到原训练样本集中,形成新的训练样本集。
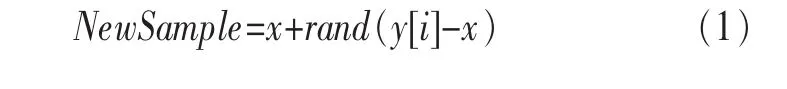
其中,i=1,2,…,N;rand表示0~1的一个随机数;NewSample表示合成的新样本;x表示少数类样本;y[i]表示x的第i个近邻样本。
3 P2P流量识别方法
整个P2P流量的分类识别方法框架如图1所示。
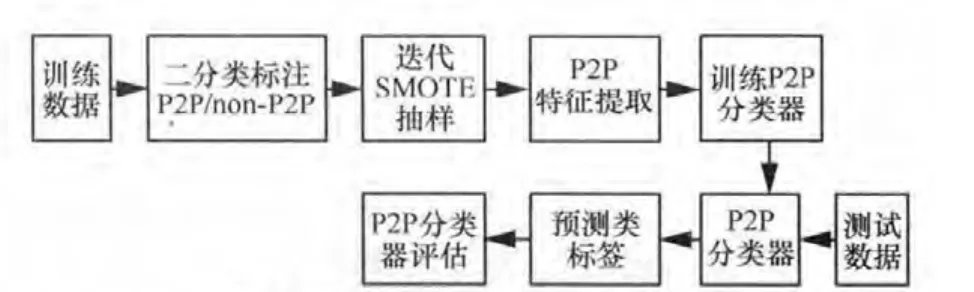
图1 P2P流量的分类识别方法框架
步骤1 将训练数据进行两分类标注,即标注所有的P2P数据流后,将其他应用的数据流均标注为非P2P(non-P2P)。这样就可将多标签分类问题归约到相对简单的二分类问题求解。
步骤2 采用i-SMOTE算法,获得更大的P2P数据流样本。原始的SMOTE算法只是在原有的少数类样本的基础上进行线性插值获得新的样本,但最新研究表明P2P这样的流量少数类具有明显的概念漂移现象[10],少量的原始样本不能完全表达P2P的概念。因此,采用多次迭代SMOTE算法的方法,在前一次迭代获得的样本集合上再进行插值运算,使得SMOTE算法的输入样本逐渐丰富,以便获得更完整的P2P概念表达。通过i-SMOTE算法,获得足够的P2P样本数,在此基础上进行步骤 3。
步骤3 特征提取,去除冗余特征,获得维度较低的特征空间。具体的特征提取算法可以采用基于相关性的方法[11]等。
步骤4 训练分类器,建立预测P2P流量的模型。目前已有很多机器学习的分类模型被尝试用于流量分类,如Na觙ve Bayes[14]、决策树[13]、支持向量机[14]、神经网络[15]等。这些模型被应用于流量分类,具有各自的优缺点。如Na觙ve Bayes具有模型简单、训练时间短的优点,但缺点是对于少数类的识别率低;而支持向量机与神经网络的识别率比较高,但模型复杂、训练与分类时间过长。本文考虑到实际环境中对P2P流量识别的实时性要求,认为选择简单的模型更有利于快速获得预测结果,因此选择Na觙ve Bayes模型作为评估模型。通过实验比较分析得出,当i-SMOTE方法获得足够的 P2P样本数时,Na觙ve Bayes模型可以对 P2P获得很高的识别率。i-SMOTE算法过程如下。

4 实验评估策略
本文提出通过i-SMOTE过抽样的方法来提高P2P流量的识别率。利用最简单的Na觙ve Bayes模型比较分析SMOTE算法和i-SMOTE算法过抽样效果:随着P2P样本数的逐渐增加,考察它们对识别率的影响。选择最简单的Na觙ve Bayes模型的原因是:在未进行过抽样的情况下,它的识别率非常低。如果过抽样技术能提高这类简单模型的识别效果,则可以证明过抽样技术对于P2P识别的有效性。
评估指标采用召回率(recall)与精度(precision)这两个指标:recall=TP/P,precision=TP/(TP+FP)。其中,P 为测试集中事先标识为P2P的样本数,TP为分类器正确预测为P2P的样本数,TP为被分类器错误地将non-P2P流量预测为P2P的样本数。
4.1 实验数据集合
本文采用的数据集1为剑桥大学Moore等提供的公开流量数据集[16]。该数据集通过连续采集24 h的流量数据,并随机抽取10个约28 min的数据块,在这些数据块上构建出数据流,构成10个数据子集Data1,Data2,…,Data10。笔者在10个数据子集上进行的实验结果非常相似,因此只列出了Data1的实验结果。原始Data1中共有12种流量类型,如WWW、E-mail、FTP等,将它们均表示为non-P2P数据流,共计24524条,P2P数据流共计339条,占总数的1.36%。
数据集2是从校园网中心的某台交换机上通过端口映射方法获得的流量数据,该交换机汇聚了某幢男生宿舍访问外网的所有网络流量。经过连续1 h(晚上 21∶30-22∶30)的连续数据采集,共计获得325538条数据流,其中P2P数据流有18632条,占总数的5.72%。为保护隐私的需要,只截取数据分组的分组头部分,并通过Tcpdpriv工具对IP地址进行了匿名化处理。
4.2 Na觙ve Bayes 模型评估
Moore等[12]早在2004年就已深入分析和应用Na觙ve Bayes模型到互联网流量分类中。通过选择合理的流量特征和核估计方法,Na觙ve Bayes模型在全局正确率(accuracy)上达到96.29%。但他们的工作只是提高了整体的正确率,并没有解决类不平衡的问题,因而对于像P2P这样的少数类的识别率提升有限。Na觙ve Bayes模型具有简单、计算效率高的特点,与其他复杂模型相比更具有实际应用价值,因此首选它作为评估过抽样技术的效果。
对数据集1、数据集2的原始P2P数据采用如下过抽样倍率:N=100%、300%、700%、1500%、3100%,应用 SMOTE算法过抽样获得新的P2P样本集,抽样结果分别见表1、表2。为了便于比较,提出的i-SMOTE算法每次迭代采用固定倍率N=100%,这样获得的P2P样本数可与前述SMOTE算法保持一致。另外,通过传统的随机过抽样方法产生一个同比例规模的数据集作为比较基准。
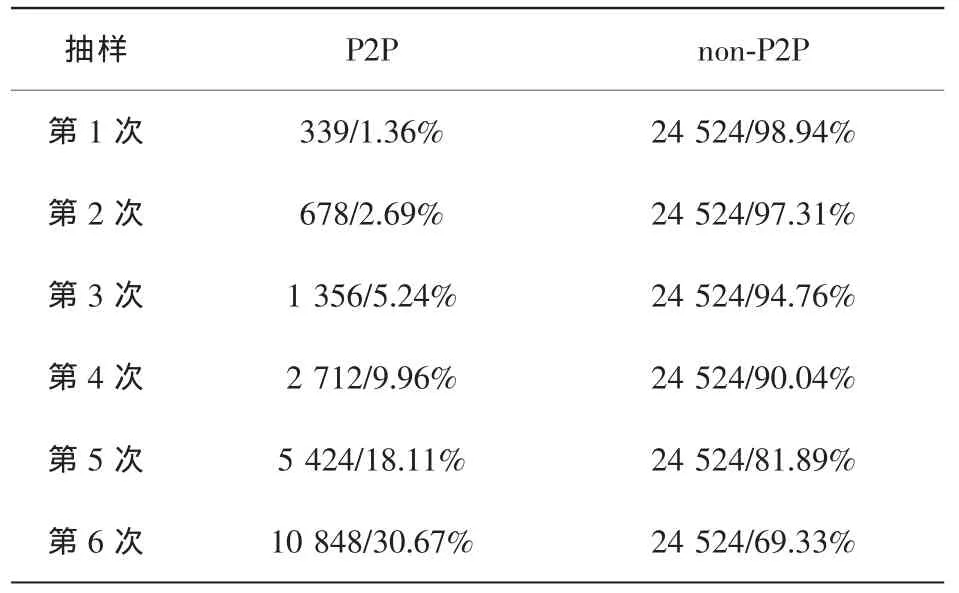
表1 过抽样数据集1获得的结果(样本数/所占比例)
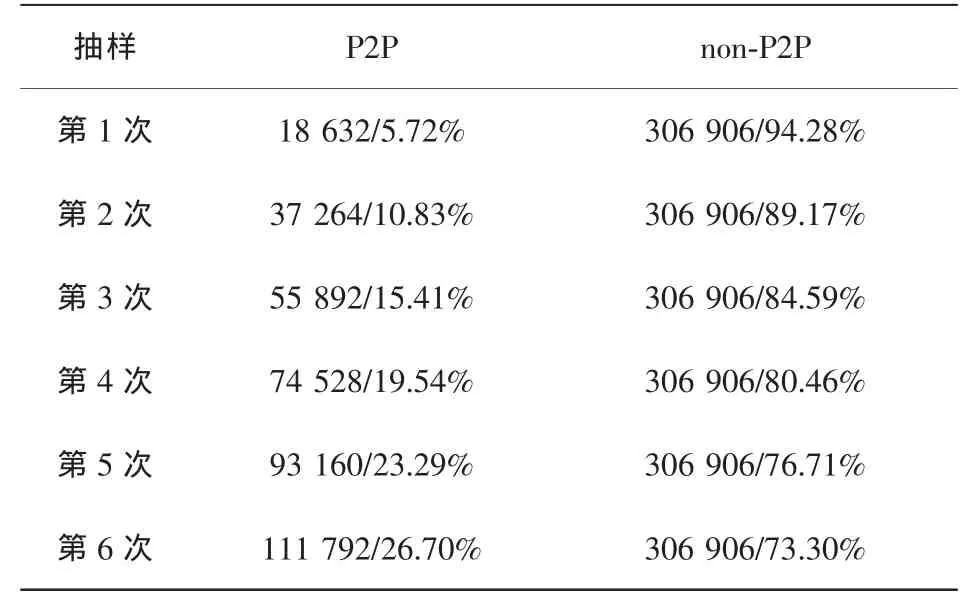
表2 过抽样数据集2获得的结果(样本数/所占比例)
采用10折交叉验证的方法对不同P2P样本数下 (见表1、表2)的识别率进行评估。特征选择采用FCBF算法[17]。图2给出了随机抽样、SMOTE算法与i-SMOTE算法同比例扩大P2P的样本数的情况下召回率的对比。可以明显发现P2P样本数从开始的339条数据流增加到2712条数据流时,即P2P比例从1.36%增加到9.96%时,Na觙ve Bayes模型在i-SMOTE数据集上获得的P2P召回率明显高于SMOTE数据集与随机过抽样数据集,前者为81.6%,后者分别为31.2%与21.8%。同样,当P2P样本数增加至5424条,比例增加到18.11%时,i-SMOTE数据集上的召回率达到98.5%,而SMOTE数据集与随机过抽样数据集分别只有78.5%与38.2%。最后当P2P的数量比例达到30.67%时,SMOTE数据集与i-SMOTE数据集上的召回率均在97%以上,而随机过抽样数据集仅为47.9%。从上述过程可以看出,i-SMOTE算法与SMOTE算法及随机过抽样相比,可以更快速地提高召回率。同样,可以看到三者在精度上的区别 (如图3所示)。随着P2P样本数的增加,3种过抽样方法获得的数据集在P2P识别精度上都得到了提升,但当P2P样本比例到达30.67%时,i-SMOTE数据集上的精度达到了99.1%,而SMOTE数据集上的精度却从94.7%跌至53.6%,甚至低于随机过抽样。图4、图5给出了数据集2的10折交叉验证的结果,与数据集1的验证结果相似。从图2~图5的比较分析中可以得出以下两个结论。
·通过对P2P样本的过抽样,与原始数据相比不论召回率还是精度都可得到提高。
·SMOTE算法可以使召回率与精度两者同时提高到90%以上,而SMOTE算法在召回率增长到一定程度时,精度会出现下降。精度的下降意味着non-P2P样本被错误地预测为P2P的比例增加,即假阳性率增加。传统的随机过抽样方法尽管有所提高,但提高程度有限。
因此,综合召回率与精度这两个评价指标,i-SMOTE算法比SMOTE算法及随机过抽样技术更为有效。
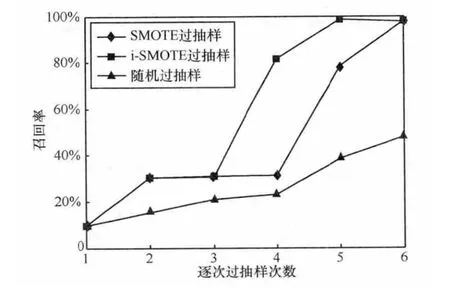
图2 数据集1不同规模的P2P样本数的召回率

图3 数据集1不同规模的P2P样本数的精度
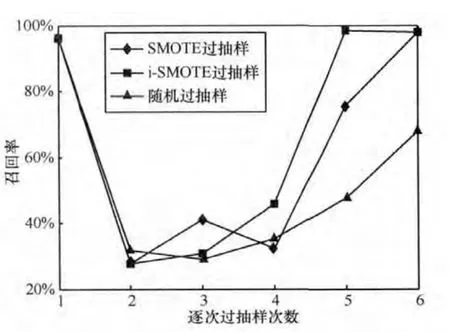
图4 数据集2不同规模的P2P样本数的召回率
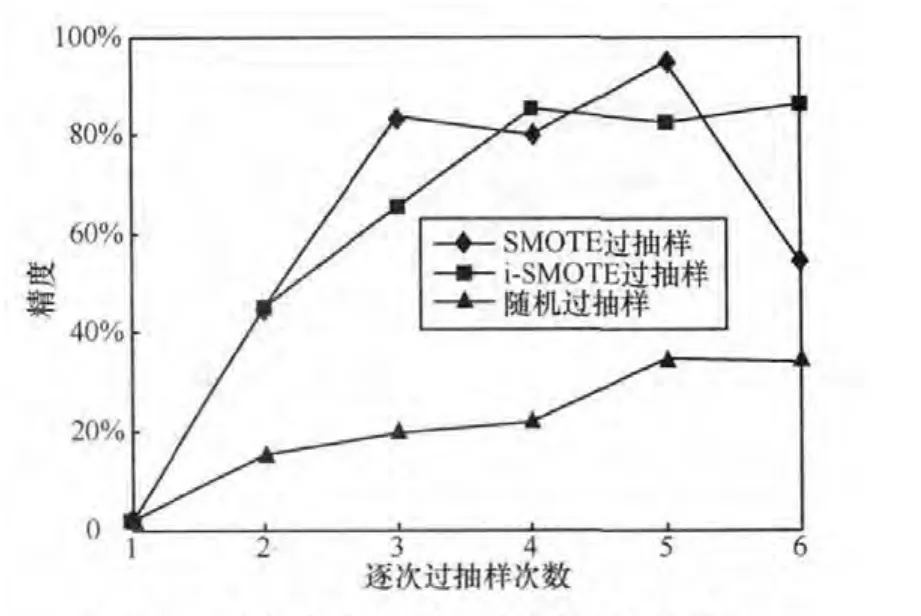
图5 数据集2不同规模的P2P样本数的精度
5 结束语
本文通过过抽样技术提高对P2P流量的识别率。提出基于迭代的SMOTE算法可以比原始的SMOTE算法及传统的随机过抽样方法具有更好的表达P2P概念的能力。实验结果表明本文提出的基于过抽样的方法可以有效地提高 Na觙ve Bayes模型对于 P2P 的识别率。Na觙ve Bayes模型由于其简单性,在流量分类中不及SVM、神经网络等复杂模型的正确率高,通常为研究人员所忽视。但正是Na觙ve Bayes模型的简单性,使得它具有很好的算法效率,容易被应用到实际工作环境。机器学习方法的分类正确率不仅仅取决于分类模型,与数据预处理的质量也有重要关系。本文正是通过改善数据质量的思路,使得i-SMOTE方法与简单的Na觙ve Bayes模型相结合实现对P2P的高精度识别。
1 Mochalski K,Schulze H.Ipoque internet study 2008/2009.http://www.ipoque.com/resources/internet-studies/internet-study-2008_2009,2009
2 MacManus R.Trend watch:P2P traffic much bigger than Web traffic.http://www.readwriteweb.com/archives/p2p_growth_trend_watch.php,2006
3 Sun X,Torres R,Rao S.Preventing DDoS attacks on internet servers exploiting P2P systems.Computer Networks,2010,54(15):2756~2774
4 Dainotti A,Pescapè A,Claffy K C.Issues and future directions in traffic classification.Network,IEEE,2012,26(1):35~40
5 Gong S F,Chen J.A P2P traffic detection method based on support vector machine.Applied Mechanics and Materials,2012,198:1280~1285
6 Erman J,Mahanti A,Arlitt M.Byte me:a case for byte accuracy in traffic classification.Proceedings of the 3rd Annual ACM Workshop on Mining Network Data,San Diego,California,USA,2007:35~38
7 Liu Q,Liu Z.A comparison of improving multi-class imbalance for internet traffic classification.Information Systems Frontiers,2012(7):1~13
8 Ling C,Li C.Data mining for direct marketing problems and solutions.Proceedings of the Fourth International Conference on Knowledge Discovery and Data Mining(KDD-98),New York,NY,1998
9 Chawla N V,Bowyer K W,Hall L O,et al.SMOTE:synthetic minority over-sampling technique.Journal of Artificial Intelligence Research,2002(16)
10 Wang R Y,Zhang L,Liu Z.Classifying imbalanced internet traffic based PCDD:a per concept drift detection method.Smart Computing Review,2013(2)
11 Hall M A.Correlation-based Feature Selection for Machine Learning.The University of Waikato,1999
12 Moore A W,Zuev D.Internet traffic classification using bayesian analysis techniques.ACM SIGMETRICS Performance Evaluation Review,2005,33(1):50~60
13 Xu P,Lin S.Internet traffic classification using C4.5 decision tree.Journal of Software,2009,20(10):2692~2704
14 Yuan R,Li Z,Guan X,et al.An SVM-based machine learning method for accurate internet traffic classification.Information Systems Frontiers,2010,12(2):149~156
15 Sun R,Yang B,Peng L,et al.Traffic classification using probabilistic neural networks. Proceedings of Natural Computation (ICNC),2010 Sixth International Conference on IEEE,Valencia,Spain,2010
16 Moore A W.Dataset.http://www.cl.cam.ac.uk/research/srg/netos/nprobe/data/papers/sigmetrics/
17 Yu L,Liu H.Feature selection for high-dimensional data:a fast correlation-based filter solution.Proceedings of the Twentieth International Conference on Machine Learning (ICML 2003),Piscataway,NJ,USA,2003
