基于双层Soar框架的数字化士兵行为建模方法
2014-03-11张国辉徐文超张文阁尚世锋
张国辉,徐文超,张文阁,尚世锋
(1.装甲兵工程学院信息工程系,北京100072;2.装甲兵工程学院装备指挥与管理系,北京100072)
为打赢信息化战争,发达国家在20世纪末相继提出了战场数字化计划。士兵成为战场上作战的主体,士兵数字化自然成为战场数字化计划中不可或缺的环节。美国最早提出“陆地勇士”计划,紧随其后,英国推出了“未来作战士兵系统”计划,法国推出了“先进战斗士兵系统”计划。随着士兵系统不断推出并陆续装备部队,数字化士兵以其明显的信息优势、强大的单兵火力和先进的防护装备在战场上发挥着越来越大的作战效能。目前,虽然士兵系统尚未普遍装备部队,对数字化士兵行为的研究还较少,但数字化士兵对未来战场的影响已初现端倪[1]。高分辨率数字化士兵行为仿真是数字化战场仿真的重要内容[2]。对数字化士兵的行为进行研究,探索数字化士兵对未来战场的影响,研究战争的发展趋势并应对未来战争的挑战,是数字化战场仿真研究的重要内容,也是作战仿真研究的前沿与热点。对士兵行为进行表示和建模是M&S(Modeling&Simulation)领域的难题之一,现有士兵行为模型大都存在自主性差、行为效果不逼真等问题。为此,笔者改进了Soar[3]认知框架,建立了数字化士兵基于双层Soar框架的行为模型,并通过仿真试验比较了数字化士兵与普通士兵的战场行为和作战效能。
1 数字化士兵的行为特点
先进的数字化装备能够极大地提高数字化士兵的作战效能,并对数字化士兵的战场行为模式和行动范围产生极大的影响。
1)数字化士兵的感知能力由战场局部感知提升为战场弱全局感知。战场弱全局感知是相对于战场局部感知和战场全局感知而言的。传统的士兵只能通过自身感知器官和部分辅助侦察装备对有限区域进行感知,其感知能力受环境影响较大,如地形的遮蔽、可见度等,这种感知称为战场局部感知。数字化士兵利用信息装备可获取上级及友邻单位的感知结果,能够形成对战场全局的态势感知,但获取的信息是粗略和不完整的,这种感知称为战场弱全局感知。战场全局感知是战场感知的理想状态,指士兵可以利用自身能力或其他方式对战场全域进行任意方式的感知。随着数字化士兵装备的不断发展,数字化士兵的感知能力不断向战场全局感知发展。
2)数字化士兵的战场决策更加理性。首先,在先进的数字化装备(以下简称“数装”)辅助下,数字化士兵能够获取更多的决策辅助信息,且对信息的处理能力更快、更强;其次,数字化士兵的通信能力大大增强,可以随时接收上级命令与指示信息;最后,面向单兵的辅助决策系统也为数字化士兵的决策提供了极大的帮助。
3)数字化士兵的行动能力大大增强。数字化士兵在导航设备和即将出现的外骨骼系统等的辅助下,在战场机动时选择路线更加灵活,机动速度更快,新式武器的使用也使得数字化士兵的射击精度更高、火力更强、打击距离更远。英国在“未来综合士兵技术”计划中决定采用的SA80步枪在300 m的距离上命中率达到90%,在600 m的距离上命中率达到50%[2]。士兵计算机和士兵电台的使用也使得数字化士兵的通信效率更高、通信距离更远,士兵电台把C4I的能力提供给单兵个人,使单兵同数字化战场有机地联系起来。
2 数字化士兵行为建模
2.1 基于双层Soar框架的行为建模方法
Soar框架是在行为建模与仿真领域应用较多的认知框架,是典型的基于“感知—决策—行动”环的框架体系。对于同一个体,由于状态不同而具有2种截然不同的行为模式时[4],使用Soar框架建立的行为模型在灵活性和适应性上显得相对欠缺。为了应对这种行为建模需求,本文改进了Soar框架,提出了行为建模的双层Soar框架,如图1所示。
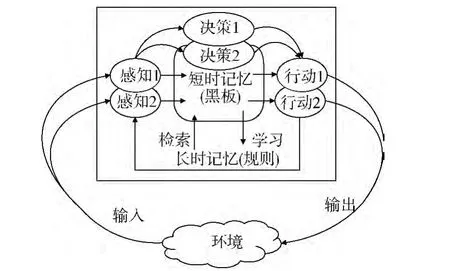
图1 双层Soar框架
由图1可见:双层Soar框架的感知、决策和行动3要素各有2种本文,在1种失效时仍能继续工作,且2种本文互为补充,该机制极大地提高了认知框架的灵活性和可靠性。对于具有2种本文的行为个体,双层Soar框架具有极大的针对性和适应性。
2.2 基于双层Soar框架的数字化士兵行为模型
在复杂的战场条件下,数字化士兵的士兵系统存在可靠性不足以及受到攻击会损坏的风险,且由于作战过程的不确定性,此系统也有可能失效。数字化士兵的行为在士兵系统正常工作和失效2种状态下差别巨大,因此本文构建了基于双层Soar框架的数字化士兵行为模型,用于描述数字化士兵2种可能状态的行为,如图2所示。
基于双层Soar框架的数字化士兵行为模型由自身感知模块、增强感知模块、自身决策模块、辅助决策模块、自身行动模块以及强化行动模块组成。纵向上可分为2层,即自身行为层和增强行为层。当数字化士兵的士兵系统正常工作时,2层共同发挥作用;当士兵系统暂时失效时,仅自身行为层发挥作用。横向上可分为3个子模型:感知模型、决策模型和行动模型。下面从横向角度进行详细论述。

图2 基于双层Soar框架的数字化士兵行为模型
2.3 数字化士兵感知模型
定义1:事件是作战过程中战场状态发生变化的一个瞬间。数字化士兵对战场的感知都是基于事件的。战场中的图像、声音、温度变化、气味变化、身体状况的变化等,都是数字化士兵对战场事件的感知内容。数字化士兵主要靠视觉与听觉来感知战场事件。
2.3.1 视觉模型
数字化士兵的视觉感知可分为视距感知、增强视距感知和超视距感知,其中:视距感知和增强视距感知是数字化士兵通过裸眼和单兵侦察设备实现的;超视距感知是通过己方对战场情况侦察后发送给数字化士兵实现的。数字化士兵裸眼的视觉范围为120°,可视距离受环境(如战场的通视性、环境的可见度等)的影响较大。使用数字化单兵侦察设备和战场传感器后,数字化士兵的可视距离大大增加,尤其是夜间的可视距离明显增加,对目标的分辨率也有显著提高,这都极大增强了数字化士兵的感知能力。
数字化士兵感知事件得到的视觉信息可以形式化为一个三元组:
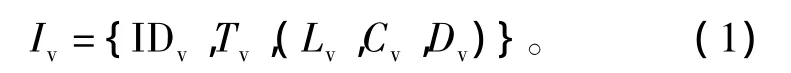
式中:IDv为视觉信息的编号;Tv为视觉信息的来源类型;Lv为事件与数字化士兵的距离;Cv为事件的状态变化;Dv为事件的威胁度。Tv可进一步表示为
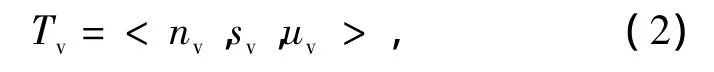
式中:nv为视距信息;sv为加强视距信息;uv为超视距信息。
2.3.2 听觉模型
战场中声音环境复杂,充斥着各种各样的声音。数字化士兵在不使用任何侦听设备时,其听觉频率范围一般为 20~20 000 Hz,响度范围为 10~140 dB,但由于声音的复杂性,不是所有的声音都可以被分辨出来,数字化士兵间的语音通信受环境影响严重。使用人造耳的数字化士兵可在20 m内任意交谈,安静情况下则可以扩展到40 m左右。
数字化士兵感知事件得到的听觉信息可以形式化为

式中:IDs为听觉信息的编号;Ts为听觉信息的来源类型;Ls为事件与数字化士兵的距离;dir为发生事件的方位;Cs为事件的状态变化;Ds为事件的威胁度。Ts可进一步表示为

式中:ns为人耳听觉范围信息;ss为增强听觉信息;us为超距听觉信息。
2.4 数字化士兵决策模型
数字化士兵的单兵作战能力大大增强的同时,作战过程中个体的伤亡对数字化部队的战斗力影响也很大。因此,数字化士兵在战术决策上需要更强的策略性,以尽可能减少个体的伤亡。为了体现这种策略性,本文提出了基于策略的决策模型。
定义2:策略是一种动作序列{mi}的规划,它不简单地追求单步行动的最优,而是以实现行动规划的最终目标作为策略成功的标准。常见的策略有包围、迂回等,策略π可以表示为

式中:xi-1为数字化士兵的状态;yi-1为敌方士兵的状态;mi为数字化士兵采取的行动。
定义3:期望效用是当动作对环境的影响不确定时,每个可能状态的效用值与该状态发生概率乘积之和,其表达式为
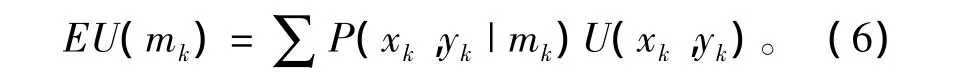
式中:P(xk,yk|mk)为数字化士兵选择行动mk输出的敌我状态为(xk,yk)的概率;U(xk,yk)为敌我状态为(xk,yk)的效用值。
行动执行可能付出的代价用C(mk)表示,包括时间代价、资源代价以及自身可能受到的伤害等。
基于策略的决策步骤如下:
Step 1,选择行动策略π;
Step 2,根据行动策略进行行动规划,产生动作规划表Tplan;
Step 3,确定关键节点 {m'1,m'2,…,m'n};
Step 4,顺序执行,执行到关键节点时转Step 5;
Step 5,计算关键节点的期望效用EU(m'k)=∑P(xk,yk|mk)U(xk,yk)-C(m'k),选择效用最大的行动mk={mk|max U(m'k)};
Step 6,若行动规划表中的动作全部完成,转Step 7,否则转Step 4;
Step 7,若开始新决策,转Step 1,否则退出。
由基于策略的决策模型的步骤可以看出:该决策模型并不追求每一个行动都达到最大效用值,模型只控制关键节点的效用,只要达到初始策略预计的目标,就认为数字化士兵的决策过程是合理的。
数字化士兵的辅助决策装备能够为数字化士兵提供更多的策略选择,能辅助数字化士兵形成更合理的行动规划表。
2.5 数字化士兵行动模型
行动建模是作战模拟的核心和基础[5],为了尽可能地实现资源共享,同时也为了加快模型的构建速度,建立了数字化士兵的元行动库,通过对元行动模型的组合和重构来构建数字化士兵的行动模型。
元行动模型可以形式化表示为

式中:IDm为元行动的编号;name为元行动的名称;Tm为元行动类型;Pin为元行动的输入参数,包括数字化士兵身体状态(如体力、伤病等)和环境对数字化士兵行动的影响参数;Pout为元行动的输出参数(如跑步速度、通信距离等)。Tm可进一步表示为
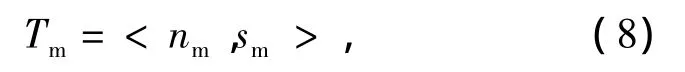
式中:nm为不使用数字化单兵系统的行动本文;sm为使用数字化单兵系统的增强本文。
元行动模型是数字化士兵行动的基本单元,是基于策略的决策基础,图3为决策模型与行动模型的关系。元行动模型库由元行动模型组成,每个元行动模型有2种模式,以元行动1为例:数字化士兵执行行动1时,若装备完好、能源充足,则优先执行1';若出现故障,则执行1。数字化士兵确定策略后形成行动规划表,其关键节点可能包含多个备选元行动模型,根据效用最大原则[6]选择最佳元行动。

图3 基于策略的决策模型生成行动
3 方法比较与试验验证
建模方法的优劣主要体现在所建立模型是否正确以及后续仿真是否真实可信。与物理、数学模型相比,行为模型由于行为主体智能的类型、层次等差别巨大,其校核、验证非常困难[7],在实际操作中往往使用专家经验评估的方法,但这样也导致了校核、验证过程中主观性过重的弊端。为此,本文采用方法比较和仿真试验的方法,对提出的数字化士兵行为建模方法进行校核与验证。
3.1 行为建模方法比较
认知结构是建立行为模型的基础,目前,在人类行为表示(Human Behavior Representation,HBR)研究成果中包含了多种行为建模框架。表1是双层Soar框架建模方法与3种常用和典型的行为建模方法的比较。
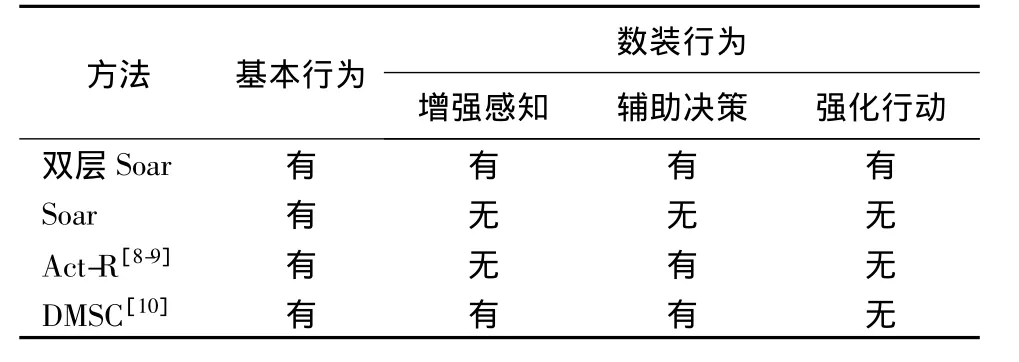
表1 行为建模方法比较
本文从基本行为和数装行为2方面对不同建模方法建立的数字化士兵行为模型进行了比较,由表1可见:基于双层Soar框架的行为建模方法能够更好地描述数字化士兵的行为特点。
3.2 仿真试验验证
3.2.1 仿真模型
根据仿真试验想定和仿真粒度,将数字化士兵的状态简化为3种:数装完好、数装失效和士兵死亡。其中:在数装完好状态下,数字化士兵依据增强行为层规则行动;在数装失效状态下,数字化士兵等同于普通士兵,依据自身行为层规则行动;在士兵死亡状态下无战斗力。利用这种方式,仿真模型对数字化士兵的士兵系统进行了简化,将士兵受伤与数装受损合并,并忽略了数装受损但仍具有部分能力的情况。数字化士兵行为模型仿真流程如图4所示。
3.2.2 试验想定及仿真方案
1)试验想定

图4 数字化士兵行为模型仿真流程
以一个夜间空降突袭机场为例,对数字化士兵行为模型进行验证。红方通过侦察确定了蓝方某临时机场的具体位置,决定派出一支特遣部队通过机降接近敌方机场,实施破坏。为实现此目的,红方运输机夜间在战斗机掩护下接近敌方机场,在距离机场3 km处特遣部队实施机降。特遣队机降后分布在1 km×2 km区域内,集结后向蓝方机场渗透,到达敌方机场后实施破坏。蓝方在机场周围有一个连的兵力,分散在机场周围实施警戒。
边界条件:红方机降后迅速集结,与蓝方接触30 min内完成作战任务,否则判定任务失败;蓝方发现红方特遣队后呼叫支援,迟滞敌方至少30 min,否则任务失败。
2)仿真方案
为了验证所建立的模型,设计了3组对比试验,在相同的作战条件下,分别采用基于双层Soar框架建立的数字化士兵行为模型(用DLSM表示)、基于单层Soar框架建立的数字化士兵行为模型(用SSDM表示)和基于单层Soar框架建立的普通士兵行为模型(用SSCM表示)进行仿真试验。
3.2.3 仿真试验及结果分析
本文将3种模型集成在某数字化战场仿真系统[11]中,对士兵行为模型进行了实现,并根据仿真试验想定、仿真方案和边界条件进行了仿真试验,仿真过程中的重要数据对比如表2所示。由表2可知:数字化士兵在夜战中具有较大的优势,基本上能够顺利完成任务,而普通士兵受限于感知距离、通信条件等,很难完成任务;而与SSDM相比,DLSM虽然集结时间长,部分成员的感知能力、机动能力受限,但由于区分出了数装受损和自身受伤,在伤亡人数上反而相对较少,最后的任务成功率也略有提高。试验结果表明:在高分辨率仿真中,采用基于双层Soar框架的数字化士兵行为建模方法建立的模型逼真度更高,证明所建立的模型是科学合理的。

表2 仿真试验数据对比
4 结论
本文提出了一种基于双层Soar框架的行为建模方法,在具有2种典型行为模式的数字化士兵建模中表现出极大的优越性。该方法能够更好地描述数字化士兵的行为特性,易于仿真实现;但其只能解决具有2种行为模式的建模问题,在同一行为主体具有多种行为模式的情况下,该方法仍需改进,且需进一步研究多种行为模式间的切换机制。
[1] 陈亚来.数字化士兵[M].北京:长征出版社,2001:13-14.
[2] 薛青.装备作战仿真基础[M].北京:国防工业出版社,2010:11-12.
[3] Jairam D,Kiewra K A,Rogers-Kasson S,et al.SOAR Versus SQ3R:A Test of Two Study Systems[J].Instructional Science,2014,42(3):409-420.
[4] Anderson J R,Both Ell D,Byrne M D,et al.An Integrated Theory of the Mind[J].Psychological Review,2004,111(4):1036-1060.
[5] 杨满喜,马亚平,马丰文.面向重用的元行动模型研究与实现[J].科学技术与工程,2011,11(32):8055-8060.
[6] 史辉,曹闻,朱述龙,等.A*算法的改进及其在路径规划中的应用[J].测绘与空间地理信息,2009,32(6):206-210.
[7] 田尊华,赵龙,贾焰.基于可拓学的行为模型验证[J].系统仿真学报,2009,21(16):4931-4933.
[8] Johnson T R.Control in Act-R and Soar[C]∥Proceedings of the 19th Annual Conference of the Cognitive Science Society.Hillsdale,NJ:Lawrence Erlbaum Associates,1997:343-348.
[9] 刘雁飞,吴朝晖.驾驶ACT-R认知行为建模[J].浙江大学学报:工学版,2006,40(10):1657-1662.
[10] Garland A,Alterman R.Autonomous Agents that Learn to Better Coordinate[J].Autonomous Agents and Multi-agent Systems,2004,8(3):267-301.
[11] 王锋,卢厚清,许长鹏.战斗建模中的作战Agent模型研究[J].装甲兵工程学院学报,2011,25(5):68-74.
