一种关联多本体的科技奖励检索方法
2014-03-07江健健熊李艳黄卫春
曾 辉,江健健,熊李艳,黄卫春
(华东交通大学信息工程学院,江西 南昌 330013)
一种关联多本体的科技奖励检索方法
曾 辉,江健健,熊李艳,黄卫春
(华东交通大学信息工程学院,江西 南昌 330013)
现有的科技奖励检索都是基于关键词的匹配,忽略了对用户查询的语义理解。针对传统信息检索存在的问题以及结合当前面向实际应用的基于本体的语义检索的特点,提出一种关联多本体的科技奖励检索方法。通过对科技奖励项目的领域本体构建,对概念相似度计算方法的改进及关联多本体概念,使扩展词语更能表达用户检索意图。实验结果表明,该方法对比传统查询检索和单独本体扩展检索获得了更好的召回率和准确率。
科技奖励;关联多本体;本体构建;概念相似性
科技奖励检索作为整个科技奖励平台的一部分,为用户及时、方便、准确地获取相关领域的科技信息提供了保证。现有基于关键词的科技奖励检索没有考虑用户检索条件的语义理解,造成返回的查询结果与用户所需要的信息内容不匹配。本体作为特定领域内概念以及概念之间关系的集合[1],具有良好的语义表达能力,非常适合用于概念语义的表达。
在面向实际应用的基于本体的信息检索中,大多是通过单一本体概念间相似度的计算对检索词进行扩展再送入搜索引擎中进行检索,这样,在召回率上必然大大提高,然而同时也会产生许多无关用户检索意图的结果,准确率提高不明显。针对大量的扩展概念,如何选择更能表达用户意图的概念组合成为引人关注的研究问题。基于此,提出了一种关联多本体的概念相似度计算方法来筛选扩展概念以改进科技奖励的检索。
1 相关研究
针对本体及信息检索,业界已有不少相关研究:文献[2]定义了本体的通用描述,即本体是共享概念模型的明确形式化规范说明,从内涵上来看,本体是某个领域的知识抽象表示,能够在知识层次上描述信息,为不同的主体(用户、机器等)之间的交流提供了一种语义基础。基于本体的内涵,文献[3]通过本体技术的引入,提出了一种智能检索模型的建立,从而解决网络教育资源杂乱无章的问题。文献[4]通过对交通信息进行抽象和分析,提出了一种基于Jena的城市交通领域本体推理和查询方法。文献[5]将本体应用在对政务信息进行标引、对检索条件的扩展和结构化检索条件的自动生成。文献[6]提出了一种基于领域本体的混合信息检索模型,通过建立关键词基础矩阵和语义扩展矩阵两层索引矩阵,保证一定的检索性能。文献[7]提出了一种基于语义相似度的个性化信息检索方法,有效地对用户的查询请求进行概念扩充,提高了搜索的查全率与查准率。文献[8]通过分析本体上下文结构,引入结构和实例相似度传播和快速匹配算法,设计一种复合匹配策略,用于本体映射。文献[9]通过本体模型和概念相似度的计算对检索信息进行检索意图树的构建并扩展,得到更好的检索结果。
纵观上述研究,目前信息检索中,都有考虑有效利用本体和语义信息来对文本进行语义检索。但都只是对单一本体概念进行扩展,没有将多个本体概念进行关联,需进一步完善。本文将本体引入科技奖励检索系统的主要目的在于对用户的检索输入进行语义分析,针对扩展检索词所在本体的不同情况,通过对扩展概念的相似性计算来对扩展概念进行组合、筛选,使扩展后的概念更能体现用户的查询表达,提高检索准确率。
2 领域本体构建及关联多本体检索方法
2.1 领域本体的构建
领域本体的构建是实现语义检索系统的重要基础和关键环节。同时,领域本体对检索文档的语义信息标注以及对用户检索意图的解析也都起着至关重要的作用。本文根据文献[10]提出的方法来构建领域本体。分为4个步骤:
1)确定本体的领域和范围。模型希望构建有关科技奖励申报项目所涉及的13个领域,根据每个不同领域所涉及的知识,考虑领域知识的深度和广度以及关系的复杂程度。
2)获取领域知识。文本构建的本体知识来源主要是科技奖励申报领域的文档信息,专家知识及可复用存在的本体。
3)定义类及其关系,建立本体模型。本阶段对收集的知识进行分析抽象,进而建立本体模型。本体类定义要明确,不应包括全部信息,应表示类的最突出属性。一个新类通常会增加其父类不具备的新的属性,或覆盖父类属性的约束。
4)使用OWL(web ontology Language)网络本体语言表示本体。为实现本体的形式化表示,我们可以使用OWL表示本体模型。OWL本体包括了类、属性、个体的描述[11]。OWL提供了丰富的公理,不仅准确描述了知识中的类、属性、个体,还对它们之间的复杂的逻辑关系进行精确描述,为知识的推理做了良好的准备。
如图1为本文构建的农业项目领域本体的部分关系图,采用的是protégé_4.1本体构建工具。

图1 农业项目领域本体部分关系图Fig.1 Partial diagram for domain ontology of agricultural projects
2.2 用户查询处理
通常用户查询输入的方式有3种:单一关键词,多个关键词及自然语言查询。对于单一关键词,直接用本体概念相似性对检索词进行扩展后进行检索;对于自然语言查询,通过结合领域概念进行分词最终转化为多个关键词的情形。本文主要叙述多个关键词的查询,其算法流程如下:

2.3 关联多本体方法
概念相似度计算是进行语义扩展的重要步骤,其精度也是提高检索质量的关键。目前常用的计算本体的概念相似度方法有:基于距离的、基于内容的和基于属性的语义相似度计算。这些方法都是在单一本体中对检索词进行概念相似度计算、扩展,没有考虑两组扩展词间的相似度,对其进行的是独立扩展。如何在给定检索扩展阈值T的情况下,选择语义相关性更大的检索词对进行组合,本文在文献[12]提出的相似度计算方法上,提出了一种新的方法来解决概念存在多个本体中的相似性计算方法。
文献[12]提出的方法通过计算被比较的两个概念所具有的共同和非共同分类包含的数量来评估概念相似性。C1和C2两概念节点,定义它们之间的相似度sim计算公式如下:

从公式(1)可以看出,该计算公式得出了一个评估分类特性的一个比值,可以用来比较独立的本体尺寸和粒度的相似性值。这个公式在多本体环境中是有相关性的,因为它能提供来自不同的本体获得结果的比较。
通常对查询概念的扩展分别是对单一本体概念的扩展,用扩展后的词语对数据源进行独立检索,没有考虑扩展词语间的关系。文本通过关联多本体概念,将处于不同本体的两个概念进行关联,挖掘该概念的深层次的关联性,使查询扩展词更能表达用户的检索意图。
目前,评估多本体间的概念相似性已有了一些解决办法,文献[13]提出的方法是通过合并不同本体成一个唯一的本体。然而这种方法有其必然的缺陷,在处理模糊重叠的概念和避免概念的不一致性时,会导致很高的计算量和人力成本。文献[14]在区别主要本体和次要本体的差异基础上,通过连接所有相等的节点把次要本体与主要本体联系在一起。
然而,由于语言歧义(同义和一词多义)和不同的知识表示过程中,术语的匹配提供了一个有限的召回率。为使这一问题减到最小,除了考虑常见的共同父节点作为那些术语的匹配,我们也考虑了他们所有的包含,无论有或没有一个完全相同的标签。事实上,每个继承术语等效上层概念的被评估概念递归地继承了所有上层概念包含。图2、图3分别为本体O1和本体O2的部分概念关系图。在评估本体概念相似度时,需要明确以下术语:
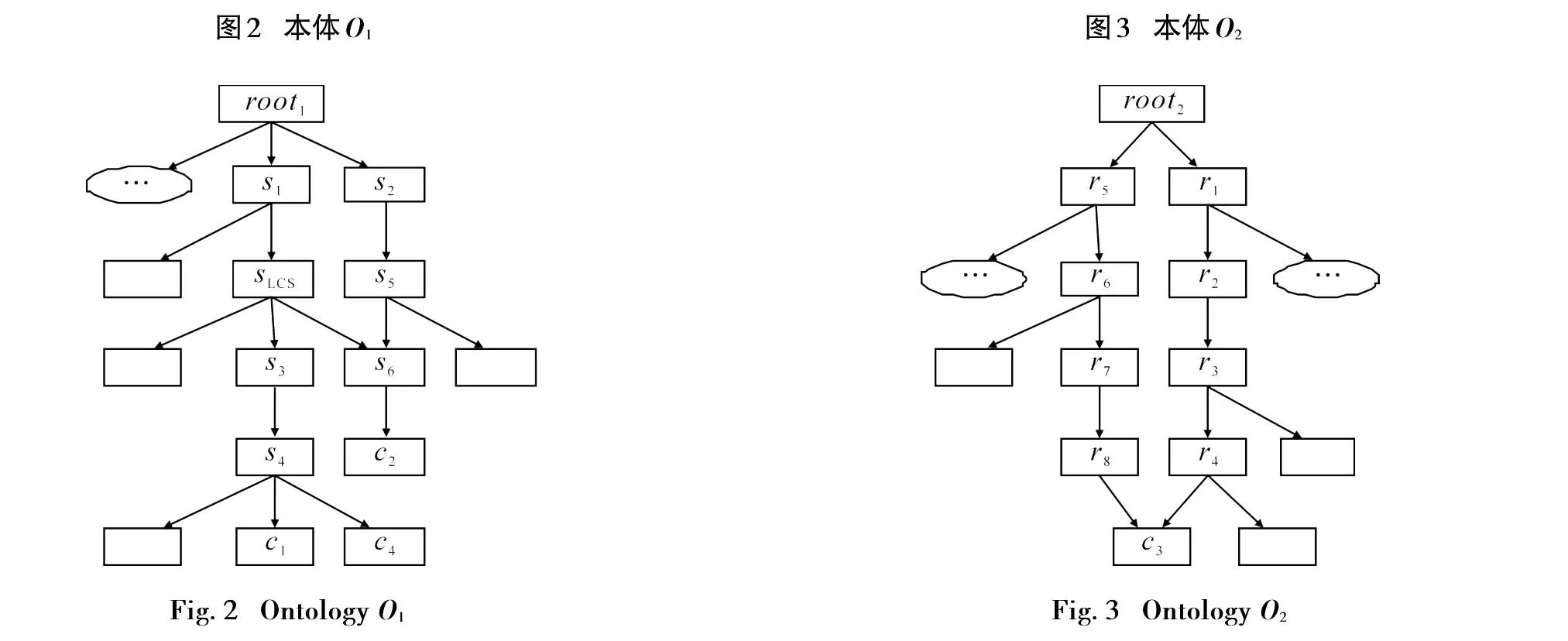
路径长度Path:指本体图中两概念节点间路径的长度。|Path(c1,c2)|为路径长度。从图2可知,Path(c1,c2)={c1-s4,s4-s3,s3-sLCS,sLCS-s6,s6-c2}。
得到|Path(c1,c2)|=5。路径长度与语义相似度成反比。
节点深度Depth:指概念c到根节点的路径长度,即Depth(c)=|Path(c,root)|。由图2可知,Depth(c1)=5。概念节点深度越大,表明此概念表示的意义越具体。
最近共同父节点LCS(least common subsumer):指在词汇分类学上被比较的两概念具有最短距离的概念。其计算公式如下

从图2可知,LCS(c1,c2)=SLCS,表明节点SLCS是节点c1,c2的最近公共父节点。
等效上层概念ES(equivalent superconcepts):指所属不同本体的两概念节点的父节点中存在等效的概念集合。通过计算两概念的上层节点,判断是否存在术语上等效的上层概念,其定义如下

式中:“≡”表示两概念等效。
不同本体间等值概念之间的检测已在本体联合领域中有所研究。基于不同的原理,已经提出了几种方法来评估不同本体的概念实际上是等效的可能性。许多方法依赖于语义相似度函数来进行评估,需要由专家或来自其他知识源的计算。然而一种无监督的方法是必要的。术语的匹配方法是可行的,他们发现等效概念完全依赖于概念标签匹配[15]。应用到我们的系统,当提到具有相同文本标签时,我们可以认为他们是等效上层概念。
概念c1包含在本体O1查询扩展集合中,概念c2包含在本体O2的查询扩展集合中。假设概念s3和r3是术语匹配概念,即s3和r3被认为是相同的概念。在这种情况下,易知,ES={s3}。通过得到术语等效概念,我们联系两本体,计算他们的共同特征节点集合。
共同特征节点集合CS(common specificity):指由ES元素及其父节点所组成的节点集合。计算公式为


通过找寻两本体概念的共同特征节点,可以将看似不相关的两个概念进行关联起来。最后,通过改进的本体概念相似度计算公式来计算所属两个不同本体的概念相似度,公式如下


3 实验结果及分析
本实验以“科技奖励推荐评审系统”中收集到的各学科研究领域的奖励申报书作为检索源,这些文档涉及了材料、农业、药物与医疗器械、计算机技术等13个学科领域。由于本体构建工作的复杂性,仅构建了农业领域的相关本体,因此选用的是农业领域200篇申报书作为实验数据。模型的评价使用的是在信息检索中常用的准确率(precision)和召回率(recall)作为评价标准。

实验分别采用关键词匹配、单独扩展本体和本文提出的关联多本体方法对农业项目相关领域进行检索,图4,图5,图6分别为输入“杂交水稻”的3种不同方法的检索界面图:
通过对后台数据库的检索,发现采用关联多本体的方法,在检索效率方面明显要低于单独扩展本体和关键词匹配。原因是采用关联多本体方法,需要进行多个本体间相似度计算和筛选,需要耗费一定的时间,但为了准确率和召回率的提高,以满意度换效率还是可行的。相比目前最强大的搜索系统GOOGLE,两系统最后都是通过关键词的匹配返回结果,在对关键词处理和后续结果显示方面存在如下区别:GOOGLE系统将对检索词提供关键字建议及同义词扩展,并对结果列表进行优化,召回率差,而且对领域相关知识的查询不令人满意;而本系统针对的有限领域语料库,在检索效率方面不是很好,但在查准率和查全率方面都有很好的性能。通过人工判断与“杂交水稻”相关的资源数,与检索结果进行对比,得到查询性能对比表,如表1所示。

图4 关键词匹配检索界面Fig.4 Matching keywords retrieval interface

图5 单独扩展本体检索界面Fig.5 Separate extension ontology retrieval interface

表1 3种方法的查询性能Tab.1 Query performance of three methods
由于检索资源库数量不大,相关资源数值小,少一两个相关资源数对计算结果数值会有很大波动。通过多次检索结果比较发现,在本次试验条件下,关联多本体检索方法可以提供更高的准确率和较好的召回率,可以给用户更直接、更满意的检索结果,具有一定的意义。
4 结束语
针对现有语义检索模型在查询扩展中存在的不足,提出了一种关联多本体的科技奖励检索方法。通过改进的关联多本体间概念的相似度计算方法来对扩展的用户检索请求进行关联、筛选,得出最能表达用户检索意图的检索词。通过实验结果表明确实提高了信息检索的准确率。同时,由于本体构建工作的复杂和评价指标的不确定性,只对农业项目的领域本体进行了构建,如果在其他领域本体完备的情况下,该方法适用于其他领域的检索。

图6 关联多本体检索界面Fig.6 Associating multiple-ontologies retrieval interface
[1]NECHES R,FIKES R E,GRUBER T R,et al.Enabling Technology for Knowledge Sharing[J].AI Magazine,1911,12(3):38-56.
[2]WALTMAN L,VAN ECKN J.Some comments on the question whether cooccurrence data should be normalized[J].Journal of the American Society for Information Science and Technology,2007,58(11):1701-1703.
[3]马骧飞,刘淑丽,孙滨.基于Ontology的网络教育资源语义检索模型研究[J].计算机与数字工程,2012,40(12):79-82.
[4]田宏,马朋云.基于Jena的城市交通领域本体推理和查询方法[J].计算机应用与软件,2011,28(8):57-59.
[5]于静,吴国全,卢燚.基于领域本体的政务信息检索系统[J].计算机应用,2010,30(6):1664-1167.
[6]熊忠阳,李春玲,张玉芳.一种基于领域本体的混合信息检索模型[J].计算机工程,2008,34(21):68-70.
[7]谢文玲,潘建国.基于语义相似度的个性化信息检索方法[J].计算机应用与软件,2011,28(5):161-164.
[8]凌仕勇,龚锦红.图解析方式的复合本体映射策略研究[J].华东交通大学学报,2013,30(3):82-88.
[9]胡川洌,符云清,钟明洋.基于领域本体的语义查询扩展[J].计算机应用,2012,21(7):83-89.
[10]韩韧,黄永忠,刘振林,等.OWL本体构建方法的研究[J].计算机工程与设计,2008,29(6):1397-1400.
[11]MICHAEL K SMITH,CHRIS WELTY,DEBORAH L MCGUINNESS.OWL Web Ontology Language Guide[EB/OL].(2004-02-10)[2013-10-20].http://www.w3.org/TR/2004/REC-owl-guide-20040210/2009.
[12]BATET M,SANCHEZ D,VALLS A.An ontology-based measure to compute semantic similarity in biomedicine[J].J Biomed In⁃form,2011,44(1):118-125.
[13]RODRÍGUEZ MA,EGENHOFER MJ.Determining semantic sim-ilarity among entity classes from different ontologies[J].IEEE Trans Knowl Data Eng,2003,15(2):442-456.
[14]AL-MUBAID H,NGUYEN HA.Measuring semantic similarity between biomedical concepts within multiple ontologies[J].IEEE Trans Syst Man Cybern,2009,39(4):389-398.
[15]LAMBRIX P,TAN H.A tool for evaluating ontology alignment strategies[J].J Data Semant,2007,182:182-202.
A Science and Technology Award Retrieval Method of Associating Multiple-Ontologies
Zeng Hui,Jiang Jianjian,Xiong Liyan,Huang Weichun
(School of Information Engineering,East China Jiaotong University,Nanchang 330013,China)
The existing science and technology award retrieval is based on keywords matching technology,which ignores the semantic understanding of user queries.To solve the problem of traditional information retrieval and combine characteristics of current practical application-oriented and ontology-based semantic retrieval,this pa⁃per proposes a science and technology award retrieval method of associating multiple-ontologies.By constructing the domain ontology for science and technology awards projects and by improving the concept similarity calcula⁃tion method and associating multiple-ontologies concepts,the proposed retrieval method makes the query expan⁃sion words further express retrieval intention of users.The experimental results show the method obtains better pre⁃cision and recall compared with keywords query and single-ontology extensions query.
science and technology awards;associating multiple-ontologies;ontology construction;concept simi⁃larity
TP391
A
1005-0523(2014)02-0112-07
2013-10-20
国家自然科学基金项目(61363072)
曾辉(1973—),男,副教授,研究方向为数据库技术,计算机决策支持系统。
