大兴安岭用材林不同强度采伐后土壤模糊聚类分析1)
2014-03-06朱玉杰董希斌
朱玉杰 董希斌
(森林持续经营与环境微生物工程黑龙江省重点实验室(东北林业大学),哈尔滨,150040)
土壤作为陆上植物赖以生存的物质基础,为植物的生长提供了所需的水分、养分和微生物,不仅直接影响着陆上植物的生长发育[1],而且也对植物种类的分布格局具有重要的影响[2-3]。因此,对林地土壤进行科学研究,并进行合理的分类,可为土地的整治规划、分块管理和合理利用等提供科学依据[4]。以往的土壤分类,大多属于单一的定性方法,一般是基于地理分布规律和发生演替规律等进行分类,这对于大范围的土壤进行分类是比较合适的,并且在我国土壤资源调查、土壤普查和流域规划中也起了一定作用;但是,其往往重视中心概念而模糊边界,缺乏量化标准,且有时将分类和分区相混淆,使土壤分类模棱两可,很难对小区域的土壤进行精细分类[5-6]。近30 a 来,随着土壤科学和数学方法的发展,模糊聚类分析法在土壤分类中得到广泛应用[7]。模糊聚类分析,是一种基于模糊集理论来解决聚类问题的数学方法,它可以对多指标事物进行综合分析,得到的分类结果表明事物在多大程度上属于某一类,非常适用于对界限不是很明显的样本进行分类[8]。如马咏真[9]根据2000年中国火灾统计资料,采用模糊聚类分析方法,把31 个省市分为重灾区、较重灾区、一般灾区、轻灾区4 类;Rao等[10]采用模糊聚类法,对美国印第安纳州的7 个水文区域的年最大流量和洪水频率进行分析,探讨了模糊聚类分析法在水文区域划分中的可行性。
森林采伐作业,对林地内的土壤具有重要影响[11-12]:一方面,表现在采伐作业过程中,人畜的行走等会导致土壤被压实,使土壤的密度、孔隙度等物理性质发生改变[13];另一方面,表现在不同采伐强度后,林地内的植被生物量会相应减少,导致林地内的阳光、水分等微气候环境发生改变,采伐剩余物的分解过程也随之发生变化,进而使土壤的pH、有机质等化学性质发生改变[14]。因此,采伐强度不同,土壤理化性质的改变程度一般也各不相同。本研究以大兴安岭用材林为研究对象,运用模糊聚类分析方法,对不同强度采伐后的林地土壤进行分类,旨在为大兴安岭用材林不同强度择伐后的土壤改良和下一步的森林精细化经营提供理论依据,同时也为我国森林土壤分类提供基础数据。
1 试验区概况
试验区位于黑龙江省新林林业局新林林场内,地处北纬51°20'以北的大兴安岭伊勒呼里山的东北坡;该地区平均海拔高度600 m,地势西南高、东北地,坡度不超过6°。森林植被以寒温带兴安落叶松(Larix gmelinii)为主,针叶树种有樟子松(Mongolica Litv)、云杉(Picea asperata),阔叶树种有白桦(Betula platyphylla)、山杨(Populus davidiana)、蒙古栎(Quercus mongolica)等;灌木植物包括偃松(Pinus pumila)、兴安杜鹃(Rhododendron dauricum)、胡枝子(Lespedeza bicolor)等;地被物种类有大叶樟(Cinnamomum porrectum)、越桔(Vaccinium vitis-idaea)、鹿蹄草(Pyrola calliantha H.Andres)等。土壤主要为棕色针叶林土,土层厚度一般在15~30 cm。含石砾30%~40%,表层腐殖质含量较高,土壤肥力中等,呈酸性反应;属于寒温带大陆性气候,大于10 ℃的年积温在1 800~2 000 ℃,年平均气温为-2.6 ℃,年平均蒸发量为924.6 mm,年降水量为480 ~510 mm,降水主要集中在6~9月份;8月下旬开始出现初霜,无霜期为90 d 左右;全年冻结期约为7 个月,结冰一般出现在9月下旬,终冻在4月下旬。
2007年3月,在大兴安岭新林林场的106、107、108、109 林班内选取20 个用材林样地,编号1 ~20,每个样地面积为20 m×20 m。试验样地地势平缓,土壤种类均为棕色森林土,平均厚度为15 cm;下木以兴安杜鹃为主,平均覆盖度为32%;地被物以越桔为主,多度为74%。其中1 号样地未进行采伐,其他19 个样地则进行不同强度的采伐,采伐剩余物采用堆腐法进行处理。1~20 号样地的采伐强度见表1。
2 研究方法
2.1 数据采集
于2013年的5月中下旬,在1 ~20 号样地上,按“Z”形布点法,各选择5 个土壤取样点,每个样点均取土壤剖面0 ~10 cm 的土壤;然后,按四分法混合取土样,共取100 个土壤样本,每个土壤样本1 kg;土壤样本在实验室进行自然风干处理,然后研磨过筛,用于分析土壤的化学性质。同时,用体积为100 cm3环刀在每个土壤取样点取环刀土壤样本,环刀土壤样本带回实验室用于分析土壤的物理性质。
土壤物理性质测定方法:用土壤的含水量,采用烘干法测定;土壤密度、最大持水量、毛管持水量、毛管孔隙度、非毛管孔隙度,均采用环刀法测定。

表1 样地概况
土壤化学性质测定方法:每个土样称取两个样品进行重复测定。土壤pH 值,采用50 ∶1 的水土质量比例,用酸度计测定;土壤有机质,采用油浴重铬酸钾氧化法测定;土壤全氮,采用自动凯氏法测定,仪器为全自动定氮仪;土壤全磷,采用酸溶-钼锑抗比色法测定;土壤全钾,采用碳酸氢钠浸提-火焰光度法测定,仪器为火焰光度计;土壤水解氮,采用碱解—扩散法测定;土壤有效磷,采用氢氧化钠浸提—钼锑抗比色法测定;土壤速效钾,采用乙酸铵浸提-火焰光度法测定。以上分析方法见森林土壤分析方法[15]。
2.2 数据分析
由于土壤本身带有模糊性,不同的土壤样本之间存在多元模糊关系;因此,本研究采用模糊聚类分析方法对不同强度采伐后的林地土壤样本进行分类,可使聚类分析结果更加符合实际。模糊聚类分析法,是将欲进行分类的样本的实测值进行无量纲化;然后确定各样本的模糊相似矩阵;再通过模糊等价关系变换,定量地确定各样本之间的亲疏关系,从而对样本进行科学分类的方法[16]。主要步骤:
①确定实测特征值矩阵。设有n 个需要被分类的样本,其组成论域U={x1,x2,…,xn},每个样本由m 个实测指标表示其性状,xi={xi1,xi2,…,xim},可得到其实测特征值矩阵X={xik}n×m;i=1、2、…、n,k=1、2、…、m。
②数据标准化。由于不同指标的量纲一般不同,为了消除量纲对分类结果的影响,同时也为了满足模糊矩阵的要求;因此,对实测特征值进行标准化处理,使实测特征值矩阵的元素在区间[0,1]上。一般采用“平移·极差变换”法达到上述目的,表达式:
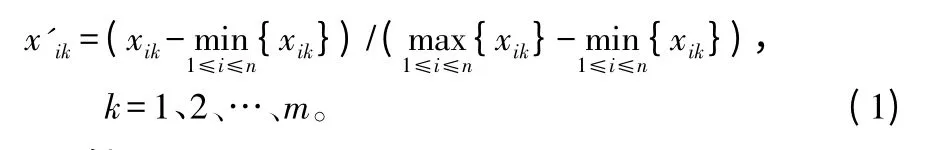
显然,0≤x'ik≤1。
③建立模糊相似矩阵。对样本进行聚类,确定各样本间的亲疏关系,需要建立样本间的模糊相似矩阵R={rij}n×n,i、j=1、2、…、n。
常用的方法有很多,如相关系数法、欧氏距离法、夹角余弦法等,本研究采用夹角余弦法进行标定,计算公式:

④绘制动态聚类图。模糊聚类的方法有很多,如传递闭包法、Boole 矩阵法、直接聚类法、最大树法、编网法[17-18];不同聚类方法的优缺点也各不相同,本研究采用传递闭包法对样本进行聚类。一般采用平方法求传递闭包t(R),得到的传递包t(R)即为模糊等价矩阵R*,运算过程:R→R2→R4→…→R2p→…,R2p=R2(p-1)◦R2(p-1)={r2pij}n×n。式中:r2pij=分别表示取大、取小运算符号。
当首次出现Rq◦Rq=Rq时,表明Rq存在传递性,则传递闭包t(R)=Rq。每一个阈值λ 都对应着一种分类结果,再将阈值λ 从大到小变化,即可得到模糊动态聚类图。
⑤确定最佳阈值。为得到最佳分类结果,必须确定最佳阈值λ。通常采用F-统计量进行选择,表达式:

式中:x(j)表示第j 类的中心向量;x 表示全部样本的中心向量;x(j)i表示第j 类中第i 个样本的特征值向量;║x(j)-x ║为x(j)与x 的距离;║x(j)i-x(j)║为与x(j)的距离;nj为第j 类的样本数目;n 为全部的样本数目;r 为分类数目。
如果F>F0.05(r-1,n-r),则说明类与类之间的差异较显著,即分类比较合理;若满足F>F0.05(r-1,n-r)的F 不止一个,则需进一步计算F 与F>F0.05(r-1,n-r)的差值,然后结合实际情况从差值较大者中选择满意的F 即可。
本研究采用Excel2010 和Matlab7.0 对数据进行计算处理。
3 结果与分析
对土壤进行分类,选择的指标应尽可能全面地反应土壤的性状,因此,在考虑东北地区土壤性质[19]和有关专家的指导下,本研究采用土壤pH、有机质、全氮、全磷、全钾、水解氮、有效磷、速效钾8 个化学指标,以及土壤密度、含水率、最大持水量、毛管持水量、毛管孔隙度、非毛管孔隙度6 个物理指标,表示样地土壤的性状。大兴安岭用材林20 个样地土壤的14 个理化指标实测值见表2。按公式(1)对表2中的实测特征值进行标准化处理,结果见表3。

表2 土壤指标实测值

续(表2)

表3 标准化处理后的土壤指标值
采用公式(2)对表3中的数据进行计算,得到 模糊相似矩阵R。

采用平方法,并通过Matlab7.0 编程,求传递闭包t(R),运算过程:R→R2→R4→R8∶R8◦R8=R8。可知,传递闭包t(R)=R8,因此,模糊等价矩阵R*=R8。

由模糊等价矩阵R*可知,当λ=1.000 0 时,土壤样本分为20 类:{1},{2},{3},{4},{5},{6},{7},{8},{9},{10},{11},{12},{13},{14},{15},{16},{17},{18},{19},{20}。当λ=0.950 5 时,土壤样本分为19 类:{1,16},{2},{3},{4},{5},{6},{7},{8},{9},{10},{11},{12},{13},{14},{15},{17},{18},{19},{20}。……
由于样本多,为避免冗余,分类结果不再一一列出。于是,可以得到土壤的模糊动态聚类图(见图1)。
采用F-统计量确定最佳阈值λ,根据公式(3)并通过Matlab7.0 编程进行计算,结果见表4。由表4可知,当20 个样地被分为20 类或1 类时,分类太细或太粗,均没有任何实际意义。当20 个样地被分为19 类、18 类、15 类、4 类或2 类时,F 与F0.05(r-1,n-r)的差值均小于0,说明这5 种分类均不合理。在其它分类中,F 与F0.05(r-1,n-r)的差值虽然均大于0,但有的差值太小,分类意义不大。而当20 个样地被分为3 类时,F 与F0.05(r-1,n-r)的差值最大,高达28.615,说明此时,类与类之间的差异非常显著,因此,这种分类结果是最合理的。所以,最佳阈值λ 为0.848 3,由动态聚类图可知,此时1 号(0)、4 号(40.01%)、5 号(20.86%)、6 号(16.75%)、7 号(12.52%)、10 号(47.87%)、13 号(53.09%)、14号(59.92%)、15 号(50.61%)、16 号(25.48%),聚为一类;2 号(34.38%)、8 号(49.63%)、9 号(13.74%)、11 号(56.51%)、17 号(67.25%)、18 号(27.85%)、19 号(51.48%)、20 号(19.00%),聚为一类;余下的3 号(6.23%)、12 号(3.42%),聚为一类。将20 个样地分为3 类,简化了林地的管理方案,降低了林地的管理难度和成本,经济可行。
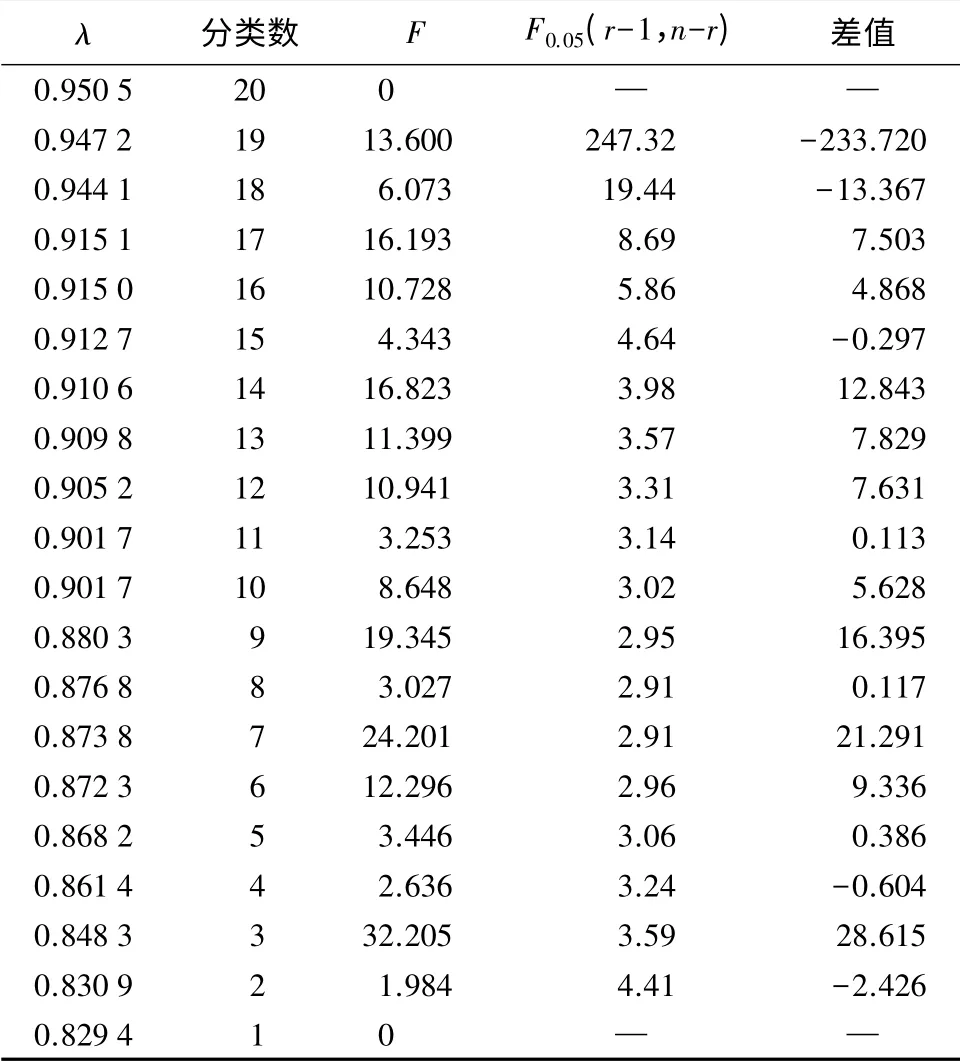
表4 阈值λ 的F-统计量比较
4 讨论
土壤分类是土壤科学的基础,也是土壤科学发展水平的重要标志[20]。上世纪80年代,我国在中国科学院和国家自然科学基金委员会的支持下,开始对“中国土壤系统分类”进行研究,逐步从定性分类转变为定量分类,也先后取得了许多重要成果[21]。但以往的科研工作者一般都是针对大范围的土壤进行分类研究的,而对小区域土壤分类的研究较少。虽然小区域的土壤之间具有相同的地理分布规律和发生演替规律,但是由于受人类活动的干扰以及一些自然因素的影响,它们之间仍然存在或多或少的差异,因此,对小区域的土壤进行分类,更加有利于土地生产管理者“因地施策”,对实际生产、经营和管理更加具有指导意义。

图1 土壤的模糊动态聚类过程
土壤分类的定量化是小区域土壤进行分类的前提,而分类指标和分类方法的选择又直接关系到分类结果的准确性。刘焕军等[22]选取中国松嫩平原吉林省农安县5 种主要土壤室的内光谱反射率作为研究对象,利用去包络线法提取反射光谱特征指标,对基于表层土壤反射光谱特性进行土壤分类的可行性探讨。张彦成等[23]以全氮、全磷、有机质、pH、代换量、耕层厚、密度7 个土壤理化因子作为土壤分类指标,对19 个土壤样本建立神经网络,最后对土壤样本分类结果的准确性进行验证,探讨了自组织特征映射神经网络在土壤分类中应用的可行性。本研究以土壤pH、、有机质、全氮、全磷、全钾、水解氮、有效磷、速效钾8 个化学指标,以及土壤密度、含水率、最大持水量、毛管持水量、毛管孔隙度、非毛管孔隙度6 个物理指标,共14 个土壤理化因子作为分类指标,采用模糊聚类分析法,对大兴安岭用材林不同强度采伐后的20 个样地土壤进行分类,结果表明:当阈值λ 为0.8786 时,全部样地土壤被分为3 类最为合理。1 号(0)、4 号(40.01%)、5 号(20.86%)、6 号(16.75%)、7 号(12.52%)、10 号(47.87%)、13 号(53.09%)、14 号(59.92%)、15 号(50.61%)、16 号(25.48%),分为第一类,该类土壤,全钾、有效率质量分数较高,土壤有机质、全氮质量分数较低,土壤密度较高,土壤含水率、最大持水量、毛管持水量、毛管孔隙度较低,土壤非毛管孔隙度较高,土壤物理性质较差;2 号(34.38%)、8 号(49.63%)、9号(13.74%)、11 号(56.51%)、17 号(67.25%)、18 号(27.85%)、19 号(51.48%)、20 号(19.00%),分为第二类,该类土壤,pH 值较低,土壤有机质、全氮质量分数较高,土壤全磷、全钾质量分数较低,土壤密度较低,土壤含水率、最大持水量、毛管持水量、毛管孔隙度较高,土壤物理性质较好;3 号(6.23%)、12 号(3.42%),分为第三类,该类土壤,有效磷、速效钾质量分数较低。因此,在以后的林地经营管理中,对于第一类土壤,可以适当施加有机肥和氮肥,提高土壤的有机质、氮质量分数,同时应对样地进行翻耕松土,改善样地的土壤物理性质;对于第二类土壤和第三类土壤,则可以适当施加磷肥和钾肥。
土壤种类的划分,往往存在一些模糊性和不确定性,而模糊聚类分析则正好可以解决这些问题,因为它克服了“非此即彼”的不合理性,考虑的是关系深浅程度,而不是有无关系[24]。陈朝阳等[25]选用土壤pH、有机质等19 个指标,对南平烟区植烟土壤进行模糊聚类分析,结果表明:南平烟区植烟土壤可分成5 个类群,符合南平烤烟生产实际,分类合理。A.B.Goktepe 等[26]采用模糊聚类分析方法,选择抗剪强度以及塑性指数作为分类指标,对120 个安塔利亚地区的土壤和20 个其他地区的土壤进行聚类,结果显示:140 个土样能被准确的分成两类。本研究采用模糊聚类分析法,对20 个不同采伐强度的样地土壤进行分类,结果显示:第一类土壤中,1 号(0)、5 号(20.86%)、6 号(16.75%)、7 号(12.52%)、16 号(25.48%)样地,采伐强度低于30%;4 号(40.01%)、13 号(53.09%)、14 号(59.92%)、15 号(50.61%)样地,采伐强度虽然较高,但其伐前样地蓄积量和林分密度较高,伐后蓄积量和林分密度与前几个样地接近。第二类土壤中,2 号(34.38%)、9号(13.74%)、18 号(27.85%)、20 号(19.00%)样地,采伐强度低于40%,伐后蓄积量和林分密度较高;而8 号(49.63%)、11 号(56.51%)、17 号(67.25%)、19 号(51.48%)样地,采伐强度较高,其中11 号样地伐前样地蓄积量和林分密度较高,伐后蓄积量和林分密度仍然较高,8 号、17 号和19 号样地伐后蓄积量和林分密度较低。第三类土壤中,3 号(6.23%)、12 号(3.42%)样地,采伐强度低于10%。说明分类结果与实际比较相符,值得推广。由于本研究在选用土壤聚类指标时,只采用了部分土壤理化性质指标,指标不能够全面反应土壤的整体性状;在以后的研究中,可以增加土壤质地、土壤水分特征曲线、耕层厚度、电导率等其他理化指标,以及土壤微生物等生物指标,相信这样会使分类结果更加准确和具有说服力。另外,限于篇幅,本研究主要是对大兴安岭用材林不同强度采伐后的林地土壤进行分类,而对每一类土壤的养分和肥力等级,则没有进行综合评价;但鉴于模糊数学在土壤研究中的有效性和适宜性,所以对每一类土壤的养分和肥力进行模糊综合评价将会是下一步的研究内容。
[1] 吕海龙,董希斌.不同整地方式对小兴安岭低质林生物多样性的影响[J].森林工程,2011,27(6):5-9.
[2] Raulund-Rasmussen K,Vejre H.Effect of tree species and soil properties on nutrient immobilization in the forest floor[J].Plant and Soil,1995,168(1):345-352.
[3] Passioura J B.Soil conditions and plant growth.Plant[J].Cell &Environment,2002,25(2):311-318.
[4] 付大友,袁东.聚类分析在土壤研究中的应用[J].四川理工学院学报:自然科学版,2005,18(2):66-72.
[5] Anderson-Cook C M,Alley M M,Roygard J K F,et al.Differentiating soil types using electromagnetic conductivity and crop yield maps[J].Soil Science Society of America Journal,2002,66(5):1562-1570.
[6] 龚子同,张甘霖.中国土壤系统分类:我国土壤分类从定性向定量的跨越[J].中国科学基金,2006(5):293-296.
[7] 刘兴久,许景刚,汪树明.模糊聚类分析在土壤分类中的应用[J].东北农业大学学报,1988,19(2):119-126.
[8] 付强.数据处理方法及其农业应用[M].北京:科学出版社,2006:105.
[9] 马咏真.模糊聚类分析在中国火灾危害分类中的应用[J].防灾减灾工程学报,2006,26(4):414-418.
[10] Rao A R,Srinivas V V.Regionalization of watersheds by fuzzy cluster analysis[J].Journal of Hydrology,2006,318(1):57-79.
[11] 刘美爽,董希斌,郭辉,等.小兴安岭低质林采伐改造后土壤理化性质变化分析[J].东北林业大学学报,2010,38(10):36-40.
[12] 王立海.森林采伐迹地清理方式对迹地土壤理化性质的影响[J].林业科学,2002,38(6):87-92.
[13] 王立海,田静,张锐.林地土壤压实对土壤呼吸影响的数学模型研究[J].森林工程,2007,23(1):5-7.
[14] 周新年,邱仁辉,杨玉盛,等.不同采伐、集材方式对林地土壤理化性质影响的研究[J].林业科学,1998,34(3):18-25.
[15] 张万儒,杨光滢,屠星南.森林土壤分析方法[M].北京:中国标准出版社,1999.
[16] Hammah R E,Curran J H.Validity measures for the fuzzy cluster analysis of orientations[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2000,22(12):1467-1472.
[17] 李军,李小梅,康志强,等.模糊聚类分析方法在乌兰察布市林业区划中的应用[J].林业资源管理,2009(1):114-117.
[18] 王宇,臧妻斌.Boole 矩阵法模糊聚类在地形图数据挖掘中的应用[J].高师理科学刊,2006,26(3):71-75.
[19] 黑龙江省土壤普查办公室,黑龙江省土地管理局.黑龙江土壤[M].北京:农业出版社,1991.
[20] 付强,王志良,梁川.自组织竞争人工神经网络在土壤分类中的应用[J].水土保持通报,2002,22(1):39-43.
[21] 龚子同,陈志诚.中国土壤系统分类参比[J].土壤,1999,31(2):57-63.
[22] 刘焕军,张柏,张渊智,等.基于反射光谱特性的土壤分类研究[J].光谱学与光谱分析,2008,28(3):624-628.
[23] 张彦成,段禅伦.基于自组织特征映射神经网络的土壤分览[J].计算机工程与科学,2008,30(10):113-115.
[24] 武伟,刘洪斌.土壤养分的模糊综合评价[J].西南农业大学学报,2000,22(3):270-272.
[25] 陈朝阳,陈星峰.南平烟区植烟土壤理化性状聚类分析与施肥对策[J].中国烟草科学,2012,33(3):17-22.
[26] Goktepe A B,Altun S,Sezer A.Soil clustering by fuzzy c-means algorithm[J].Advances in Engineering Software,2005,36(10):691-698.
