基于条件随机场与时间词库的中文时间表达式识别
2014-02-28黄德根
吴 琼,黄德根
(大连理工大学 计算机科学与技术学院,辽宁 大连 116024)
1 引言
时间表达式的识别在中文信息处理中有重要的作用和意义,时间表达式识别可为问答系统提供基本的素材,可以用于机器翻译、事件跟踪、信息检索中相关时间的定位,还可以用于定位事件发生的时间及回答时间相关的问题等。
1995年,信息理解会议(Message Understanding Conference)首次将时间表达式的识别作为命名实体识别的一个子任务。2004年,美国技术标准局(NIST)举办了第一届时间表达式识别与归一化(Time Expression Recognition and Normalization, TERN)的评测,随后,ACE2005(Automatic Content Extraction)和 SemEval2007(Semantic Evaluations)也将时间表达式评测纳入自己的任务中。
时间表达式识别的常用方法有两种: 一种是基于规则的方法[1],例如,文献[2]通过建立一些语法规则和补充限定条件,用规则匹配的方式识别时间表达式;文献[3]将时间信息划分为一系列的“时间基元”,使用启发式规则抽取时间表达式,再利用错误驱动方法对规则库进行剪枝,提高规则抽取的正确率;文献[4]提出一种基于正则表达式的TIMEX2[5-6]中文时间短语边界识别方法。由于时间表达式具有一定的稳定性,直到现在,仍有人用规则的方法识别时间表达式。规则[7]方法优点是使用简单,正确率高;缺点是很难将所有时间表达式完全覆盖,而且制定规则需要大量的人工,领域适应性较差。
另一种是基于机器学习的方法。这类方法一般借助于统计模型,常用的统计模型有: 条件随机场(CRF)[8]和条件最大熵[9]。条件最大熵的方法优点是能够将各种特征在同一框架内刻画,不需要特征独立性假设,缺点是时空复杂度大,耗费资源;CRF[10]方法能找出全局最优解,可充分利用上下文的信息,但是它的结果好坏过分依赖于训练语料的质量,还存在数据稀疏和词序依赖的问题。文献[11]将中文时间短语分为日期型和事件型两类,利用CRF加入任意特征表达长距离的上下文依赖信息的能力,解决了时间短语词数较少时的噪声过大问题。
除此之外,文献[12]提出基于依存分析和错误驱动的方法来识别时间表达式,解决了长距离依赖的问题。文献[13]将浅层语义分析中的语义角色标注加入中文时间词识别中,在CRF训练中达到了较好的识别效果。
当句子中存在时间短语时,机器翻译的效果通常不太理想,若能将时间表达式提前识别,并作为一个整体去翻译整句,不仅能降低句法分析的复杂度,而且机器翻译的效果能得到改善。
例如,在句子“土地基金於一九八六年根据中英联合声明的规定成立,订明由联合声明于一九八五年五月二十七日生效当天起至一九九七年六月三十日止”中,存在3个时间表达式。
第1个时间表达式: 一九八六年(英文1986)
第2个时间表达式: 一九八五年五月二十七日(英文May 27, 1985)
第3个时间表达式: 当天起至一九九七年六月三十日(英文the day until June 30, 1997)
上述句子用Google翻译得到: Land Fund in accordance with the provisions of the Joint Declaration was established in 1986, stipulates that the joint statement on May 27, 1985 ended June 30, the day of the entry into force until 1997.
若将“一九八五年五月二十七日”和“当天起至一九九七年六月三十日”作为一个时间表达式整体,再翻译则变成: Land Fund in accordance with the provisions of the Joint Declaration was established in 1986, Stipulates the joint statement entry into force on May 27, 1985 ended the day until June 30, 1997.
再如“为了投票,他们排队长达三、四个小时。”Google的翻译是: In order to vote, they waited three hours and four hours.将时间表达式“三、四个小时”作为整体识别后再翻译的话,得到正确的结果: In order to vote, they waited three or four hours.
2 基本概念及问题分析
2.1 时间表达式
TIDES 2003 Standard for the Annotation of Temporal Expressions 于2004年4月份发布的中文补充版[14]对时间表达式的定义是: 时间表达式是时间单元的一个序列。在本文中,时间表达式可认为是时间触发词与时间缀词的组合。SemEval2010(Semantic Evaluations)task 13首次将时间表达式的类型作为识别内容,将时间表达式分为以下4类。
• DURATION: 例如,two weeks;
• SET: 例如,every Monday morning;
• TIME: 例如,at 2: 45p.m;
• DATE: 例如,January 27,1920,yesterday。
结合中文时间表达式的特点与翻译的需要,本文在以上4类的基础上进行了修改,将时间表达式分为了以下7类,即DURATION类、SET类、TIME类、DATE类、LUNAR类、FUZZY类、RELATIVE-TIME类,其中DURATION和SET与SemEval2010 task 13定义的时间类型相同,而TIME和DATE进行了修正,新增加LUNAR、FUZZY、RELATIVE-TIME,具体如下:
• TIME类: 修改为一天中的某个具体时间点,例如,“4点半”;
• DATE类: 修改为年月日这类的标准时间,例如,“2013年9月1日”;
• LUNAR类: 表示中国传统节气,包括中国农历、节日等各种传统说法,例如,“国庆黄金周”、“大年初一”;
• FUZZY类: 表示模糊时间,例如,“数十年”;
• RELATIVE-TIME类: 表示相对时间,是相对于DATE来说的,不能具体到某一天的时间就称为相对时间,例如,“明天”、“下午”。
以上7类就是本文识别的时间表达式范畴,超出其中范围的时间相关的式子,不在本文识别范围内。
2.2 时间单元
本文中的时间单元是指时间表达式的最小组成单位。例如,“2014年5月2日下午3点”这个时间表达式中,包含有2014年、5月、2日、下午、3点这5个时间单元。
之所以选择时间单元作为CRF标注目标,是因为时间表达式是由时间单元组成的,时间单元之间搭配相对松散,没有很强的先后依赖关系,而时间表达式的形式多样。因此,时间单元的格式相对时间表达式比较固定,抽取难度小,准确度高。
2.3 时间触发词
时间触发词是判断一个短语是否是时间短语的关键词。通常是一个时间单位,表示时间概念,例如,“月”、“日”。根据识别的需要,本文将触发词分为两类,一类是独立触发词,另一类是数字触发词。
独立触发词指的是,单独存在就能表示时间的这样一类触发词。例如,“下午”、“昨天”等词语,不需要上下文信息,本身就可作为时间表达式。
数字触发词可细分为数字前缀触发词与数字后缀触发词,其中,当数字前缀触发词的前面为数字时,则数字与数字前缀触发词一起构成一个完整的时间单元(例如,“21世纪”、“2008年”),而其单独存在时不具有时间意义;数字后缀触发词的概念与数字前缀触发词类似,不同的是数字是在触发词的后面,如“星期三”。
2.4 问题分析
时间表达式识别作为自然语言处理的一个分支,其识别的难点是歧义问题。时间表达式是由时间触发词触发,但是,并非含有触发词的表达式就一定是时间表达式。例如,“后天因素”中的“后天”是时间触发词,但是“后天因素”这个词并不是时间表达式。再比如,“6分”可以是时间表达6分钟,也可能是得分6分。具体的含义要看上下文。这类问题都是时间表达式的识别歧义问题。
本文针对这类歧义问题,利用规则进行限定,查看其上下文信息,判断其是否为时间表达式。
3 时间表达式识别模型
中文时间表达式识别模型主要包含以下两部分,如图1所示。

图1 中文时间表达式识别模型
1) CRF生成特征模板部分: 输入训练集,选取CRF的模板特征,自动生成对应的特征模板。
2) 规则处理部分: 该部分主要是对CRF没识别的时间单元进行补充识别,并确定时间表达式边界。具体分为以下7个步骤。
第1步: 对测试语料的格式进行预处理,将语料格式转化为CRF要求的格式;
第2步: 对语料进行分词、词性标注*分词工具使用的是大连理工大学自然语言处理实验室的NiHao分词系统;
第3步: 使用第一部分生成的CRF特征模板对测试语料进行测试,得到标注出时间单元的语料;
第4步: 对CRF模型标注后的结果进行处理,去除错误的时间单元,自动获取时间单元中的时间词生成候选触发词表,通过评价函数对候选触发词进行除杂,将正确的触发词分类放入相应的触发词库中;
第5步: 考虑到CRF对于训练语料具有很强的依赖性,对某些不常用的时间触发词的标注效果不理想,因此,制定规则,对语料中的时间触发词进行补充标注;
第6步: 利用相邻时间单元合并的原则合并时间单元,由于时间表达式的上下边界通常是由时间缀词修饰,因此,借助时间前缀词库和时间后缀词库,确定时间表达式的上下边界;
第7步: 对标注的时间表达式进行筛选,去除其中错误的标注,得到正确的时间表达式。
3.1 基于CRF的时间单元标注
CRF是一种基于统计的无向图模型,它定义了在给定观察序列条件下,计算整个标注序列的单一联合概率分布。Lafferty 等人定义CRF为指数形式分布,这就使得不同状态下的不同特征的权值可以相互平衡。给定观察序列X={xi}(i=0, 1, …,n)和状态序列Y={yi}(i=0, 1, …,n),线性链的CRF定义序列Y的条件概率如式(1)所示。
(1)
其中,z(X)是归一化因子;n表示给定词序列的长度;fj(yi-1,yi,X,i)是特征函数,既可以表示无向图边的转移特征e(yi-1,yi,X,i),也可以表示节点的状态特征v(yi,x,i);λj是第j个特征函数的权重系数。时间表达式识别问题可以归结为序列标注问题,其任务是给定观察序列x的条件下,估计产生标注序列y的条件概率有多大。而CRF模型具有强大的特征描述能力和特有的克服标注偏置问题的能力,它可以非常容易地将观察序列中的任意特征加入到模型中,表达长距离依赖的上下文依赖信息,从而确定标注时间单元的左右边界。
基于CRF的时间单元识别模块的具体流程见图2。其中,训练集采用的是2000年的《人民日报》,共26万多条词,人工标注时间单元。本文特征选取的是: 当前词的词形、词性;前一个词的词形、词性;后一个词的词形、词性。
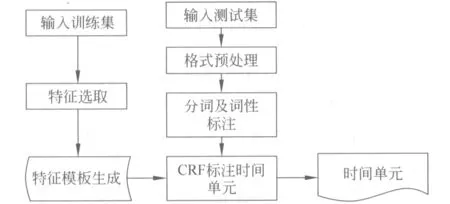
图2 CRF识别时间单元过程
前人也有尝试过使用CRF方法来标注时间表达式,但是标注的对象是整个时间表达式而非时间单元。由于时间缀词的不定性,导致标注的时间表达式容易发生边界错误。本文采用CRF方法标注时间单元,与时间表达式相比,粒度更小,而且,时间单元的格式较时间表达式更稳定,识别效果有一定的提高。
3.2 基于时间词库的规则方法
由于CRF的局限性,当遇到训练语料中很少出现的时间表达式类型,其识别效果很差,甚至不能识别。时间表达式边界的识别效果也不好。为此,本文通过以下两个方面对其进行补充修改。
对于训练语料中很少甚至不存在的时间单元,本文采取的方法是,构建时间触发词库,对其进行补充标注。初始的时间触发词库由人工构建,由于时间表达式的识别效果一定程度依赖于时间触发词库的规模,而人工完善的耗费太大。因此,利用转换规则自动获取时间单元中的候选触发词,生成候选触发词表。候选触发词表中含有很多错误的候选词,如若直接放入触发词库会极大地降低识别结果的正确率,因此需要对候选触发词进行除杂。本文通过引入评价函数Score(Ti)来对候选触发词进行打分,设置λ阈值进行筛选。获得的触发词根据类型分为数字触发词与独立触发词,分别放入对应的触发词库,达到完善时间触发词库的目的。
研究发现,时间表达式的边界一般是时间缀词,时间缀词对时间表达式的作用范围起到限定的作用。因此,我们构建了时间前缀词库和时间后缀词库,通过查看时间单元的前后词是否是时间缀词来确定时间表达式的边界。
本文使用的时间触发词库有两个: 独立触发词库和数字触发词库。设立两个触发词库的原因是,能有针对性的处理不同类型的时间单元,有利于下面的筛选环节。
基于CRF进行时间单元的标注后,再通过规则识别时间表达式,具体过程如下:
1) 将CRF标注时间单元中部分错误的标注去除;
2) 利用转换规则自动获取时间单元中的候选触发词,生成候选触发词表;
3) 候选触发词Ti{i=0,1,2,…n},将候选触发词表加入后的系统识别结果与语料的正确结果进行对比,每个候选触发词的得分计算方法为式(2)。
(2)
其中,True(Ti)表示候选触发词Ti在测试语料标注中正确的个数,False(Ti)表示错误的个数。设置阈值λ,将得分小于λ的候选触发词从表中删去,具体过程见图3。
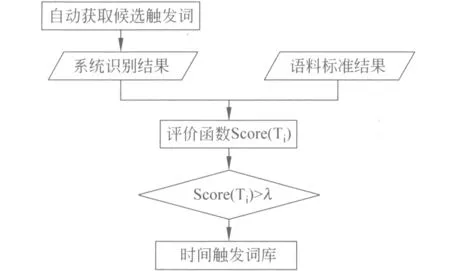
图3 自动获取时间触发词过程
4) 合并相邻的时间单元,并根据时间前缀词库与时间后缀词库,确定时间表达式的边界;
5) 设置限制条件,去除错误的时间表达式,得到正确的时间表达式。
4 实验结果及分析
4.1 特征选取
CRF模型使用CRF++-0.54*Available at http://crfpp.googlecode.com/svn/trunk/doc/index.html工具包获得。CRF的训练语料是纯人工标注,因此,训练效果比较好。据文献[9]统计,近49%的时间表达式为一个独立的时间单元;26%的时间表达式是由两个时间单元构成;21%的时间表达式为3个时间单元;2.3%的为4个时间单元;1.7%为5个以上时间单元组成。因此,选取了以下两个模板特征,分别做了开式测试实验(表1)。

表1 特征选取细节
为了测试上述两组特征哪个的效果更好,我们做了两组开式测试实验,测试语料是2011年的国际新闻,测试语料中共含有1026个时间单元,实验结果见图4。
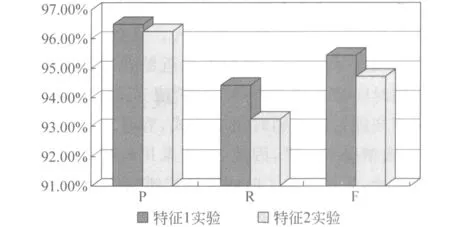
图4 不同特征识别时间单元效果
从图4可以看出,特征1模板的标注效果更好。本文最终选取的特征为: 当前词的词形、词性,前一个词的词形、词性,后一个词的词形、词性。
4.2 实验结果
本文采用的CRF训练语料是2000年的人民日报新闻,共含有24万条词;测试语料为2011年国际新闻,共含有18万条词,其中时间表达式1 954个。为了比较该方法的效果,我们分别做了两个基线系统: 基于CRF识别时间表达式与基于规则识别时间表达式。在实验数据集一致的情况下,结果如表2所示。
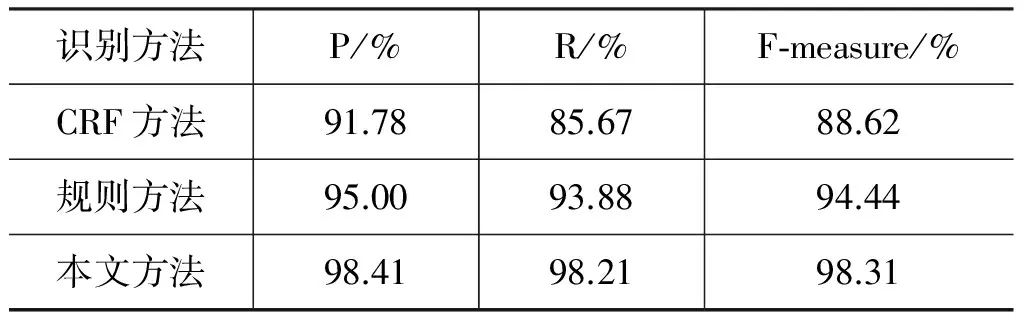
表2 时间表达式识别结果对比
从表2中的实验结果可以看出,本文采用的CRF与规则相结合的方法,比单纯用CRF方法或规则方法的识别效果好。CRF方法识别较复杂的时间表达式时容易发生边界错误,例如,时间表达式“3、4小时”,CRF识别的结果为“4小时”;并且,CRF识别结果中存在很多歧义问题导致的错误,例如,CRF标注的表达式“4.1分”表示得分4.1,并不是时间表达式;此外, CRF方法在训练语料比较单一,类型不丰富的情况下识别结果召回率低。文献[11]将时间词表、词性标注、位置信息等作为特征,采用CRF方法对中文时间表达式进行识别,日期型时间短语的识别结果F值为95.70%;文献[13]采用了语义角色标注之后CRF识别的方法,识别结果F值达到85.6%。与它们的实验结果相比,本文使用CRF识别时间单元,减小了识别粒度;增加了CRF错误标注去除部分,进一步提高CRF识别结果的精度;再制定了规则补充识别时间单元,提高了召回率;添加限制条件去除有歧义时间表达式,进一步提高识别精度,最后达到了F值为98.31%的较好效果。
规则的方法,精确率较高,但是召回率取决于规则的完善度,规则完善则召回率高,反之,则召回率低。制定规则需要大量人工,且领域适应性较差,对于不常见的时间词识别效果不好。文献[9]采用规则方法识别时间单元,再根据就近结合时间单元原则识别时间表达式,识别结果 F值为84.67%。单纯采用规则方法识别时间表达式,容易产生错误规则,导致精确率不高,因此,本文采用统计方法识别时间单元,并且添加了时间表达式错误处理部分,进一步提高了识别时间表达式的精确率。
本文在衡量两种方法的利弊后,采用两者结合的办法。在CRF识别时间单元的基础上,根据触发词库制定规则,补充识别时间单元,能有效地提高识别结果的召回率,弥补CRF由于训练语料不全面导致的召回率低的问题,还能通过完善触发词库较好的识别低频时间单元。识别的效果一定程度上受时间触发词库的规模影响,本文采用规则自动获取训练语料中的时间单元作为候选触发词,通过评价函数筛选之后,加入到触发词库中,自动获取触发词能节省人工,不断更新、完善触发词库,提高识别的召回率。在时间单元正确识别的基础上,根据时间缀词库,制定规则识别时间表达式的边界,能有效地解决时间表达式边界识别的难题。
5 结论及下一步工作
本文在TempEval2基础上,结合中文时间表达式实际情况,对时间类型进行补充、修改,使得时间表达式类型更符合中文的特点。利用CRF与规则相结合的方法,识别出中文时间表达式。在新闻领域的F1值达到98.31%,取得了不错的效果。时间单元的格式相对固定,转化应用的领域时,只需要较少的变动(修改相应的时间触发词库与时间缀词库)就能适用于其他领域,具有较好的可移植性。
基于测试语料自动获取时间触发词的方法可以提高时间表达式识别的召回率,但是,不可避免的会带来一些杂质,降低识别的正确率。评价函数能有效地去除一些明显的杂质,阈值λ的设置需要经过反复试验,过高容易过滤掉很多正确的触发词,过低则会极大降低识别的正确率。另外,评价函数只能作用于有正确标准答案的测试语料,而这部分的语料资源较少,导致自动获取的触发词较少,这也是本文不足的地方之一,需要进一步加以改进。
并非所有的时间表达式都含有触发词,存在不含有触发词的时间表达式,该类时间表达式的识别只能通过分析其语义确认, 例如, “2013底”。本文对于该类不含有触发词的时间表达式识别效果不好。下一步,我们将研究如何识别这类的时间表达式及中文时间表达式的规范化问题。
[1] 高霄云,杨建林.基于规则的中文时间词和数词的自动识别算法[J].现代图书情报技术,2007(3): 46-50.
[2] Mingli Wu,Wenjie Li,Qin Lu,et al. A Chinese Temporal Parser for Extracting And Normalizing Temporal Information[C]//Proceedings of international Joint Conference on Natural Language Processing (IJCNLP),2005(3651): 694-706.
[3] 乌桐,周雅倩,黄萱菁等.自动构建时间基元规则库的中文表达式识别[J].中文信息学报,2010,24(4): 3-10.
[4] 林静,曹德芳,苑春法.中文时间信息的TIMEX2自动标注[J].清华大学学报(自然科学版),2008,48(1): 117-120.
[5] Ferro L, Gerber L, Mani I, et al.TIDES 2003 Standard for fhe Annotation of Temporal Expressions[EB/OL]. http://timex2.mitre.org.2003.
[6] Ferro L, Gerber L, Mani I, et al.TIDES 2005 Standard for fhe Annotation of Temporal Expressions[EB/OL]. http://timex2.mitre.org. 2005.
[7] Pawel Maqur,Robert Dale. A Rule Based Approach to Temporal Expression tagging[C] //Proceedings of the International Multiconference on Computer Science and Information Technology.2007,293-03.
[8] 赵紫玉,徐金安,张玉洁,等.规则与统计相结合的日语时间表达式识别[J].中文信息学报,2013,27(6): 192-200.
[9] 李君婵,谭红叶,王凤娥.中文时间表达式及类型识别[J].计算机科学,2012,39(11A): 191-211.
[10] David Ahn,Sisay Fissaha Adafre,Maarten De Rijke.Towards Task-Based Temporal Extraction and Recognition[C]//Proceedings of Dagstuhl Workshop on Annotating, Extracting, and Reasoning about Time and Events,2005.
[11] 朱莎莎,刘宗田,付剑锋,等.基于条件随机场的中文时间短语识别[J].计算机工程, 2011,37(15): 164-167.
[12] 贺瑞芳,秦兵,刘挺,等.基于依存分析和错误驱动的中文时间表达式识别[J].中文信息学报,2007,21(5): 36-40.
[13] 刘莉,何中市,邢欣来,等.基于语义角色的中文时间表达式识别[J].计算机应用研究,2011,28(7): 2543-2545.
[14] Gerber L,Huang S,Wang X. Standard for fhe Annotation of Temporal Expressions, Chinese supplement draft[EB/OL].//timex2.mitre.org.2004.
