中文微博用户性别分类方法研究
2014-02-28王晶晶李寿山
王晶晶,李寿山,黄 磊
(苏州大学 计算机科学与技术学院自然语言处理实验室, 江苏 苏州 215006)
1 引言
近几年来,随着社交网络的迅猛发展,各种类型的微博即微型博客(Microblog)备受用户的青睐,例如,Twitter、Facebook等。新浪微博是国内知名的微博网站,截止到2012年12月,新浪微博注册用户突破5.03亿,用户每日发博量超过1亿条。由于微博既具有媒体传播特性,又具有社交网络特性。因此,吸引了众多研究人员对微博数据进行分析研究[1-2]。例如,利用微博进行在线用户潜在的人口特征识别[3]。
在微博数据研究中,性别特征的研究渐渐受到了越来越多的关注[4-6]。获得的用户性别信息可以被应用在很多领域,例如,市场推广、广告宣传和法律侦查等[7]。虽然基于微博的性别分类已经有了一定研究,但是针对中文的性别分类工作还很缺乏。而且,中文微博的用户性别识别同英文微博的用户性别识别存在一定的差异,例如,中文的用户名的尾字包含丰富的性别区分信息(例如,“刘雯雯”、“黄晓萌”中的“雯”和“萌”)。
通过观察中文微博信息,我们发现,对于用户性别识别,一种简单有效的分类方法可能是利用用户名文本进行判别。例如,“谢娜”、“曲婉婷”等包含“娜”、“婷”等女性化字词的用户名更有可能是女性用户,而“王刚”、“毕福剑”等包含“刚”、“剑”等男性化字词的用户名更有可能是男性用户。
此外,我们还可以利用微博提供的与用户有关的其他信息来识别用户性别。较常见的信息是用户发表的微博。这些微博内容可能会有效帮助识别该用户的性别。例如,“天哪!一双高跟鞋和一件连衣裙加起来才一千不到,老娘果断打劫了”,这条微博包含了“高跟鞋”、“连衣裙”、“老娘”这些女性使用比较频繁的词。因此,发表该微博的用户更可能是一位女性。像“我靠,防水的剃须刀,就是牛掰”包含了“我靠”、“剃须刀”等词的微博,更可能来自一位男性。
本文旨在提出一种基于中文微博的用户性别分类方法。具体而言,分别利用用户名及用户发表的微博文本信息对微博用户进行性别分类;在此基础上,我们进一步提出将用户名及用户发表的微博两种文本信息进行融合的分类方法,从而达到更好的分类效果。
本文其他部分组织如下: 第2节介绍微博中用户性别研究的相关工作;第3节介绍微博语料的收集;第4节介绍本文提出的基于用户名和微博文本的分类方法;第5节给出实验设置及结果分析;第6节给出结论,并对下一步工作进行展望。
2 相关工作
近十年来,自然语言处理领域的研究人员针对性别分类分别在博客、电子邮件、微博等平台上面进行了一定研究。
首先,较多的性别分类研究工作是利用博客文本识别用户性别。例如,Schler等[4]利用男女用户的博客文本在写作风格和内容上的不同,来确定一个未知用户的性别类型;Yan[5]利用朴素贝叶斯(Naïve Bayes)分类方法来识别博客用户的性别;Nowson等人[8]利用博客文本构建了一个自动识别性别的特征集。类似的,其他研究人员进行了进一步的研究去发现更有效的特征来提高分类性能。例如,Mukherjee等人[6]、Peersman等人[9]和Gianfortoni等[10]。值得注意的是,Ikeda等[11]提出了一个半监督学习方法,有效地利用未标注样本来提升性别分类性能。
其次,一些性别分类研究工作是利用电子邮件文本识别用户性别。例如,Corney等[12]从Email文本中抽取了一个与内容无关的特征集来进行性别分类;Mohammad等[13]发现不同性别的用户在他们工作邮件中使用的情感类词汇存在明显差异。
最近,随着社交网络的发展,一些研究人员开始把他们的目光转向微博文本。例如,Burger等[3]利用Twitter用户的tweets和个人资料(账户名、全名、个人描述)以及他们的结合作为特征来识别用户的性别;Miller等人[7]使用n元特征的感知器(Perceptron)和朴素贝叶斯(Naïve Bayes)算法去识别Twitter用户的性别;Ciot等人[14]第一次使用非英文文本来识别Twitter用户的性别;Alowibdi等人[15]在Twitter文本基础上探索独立于语言的性别分类。
我们的研究也是在微博文本基础上进行的。与以往微博研究不同的是: 首先,本文针对中文微博的用户性别分类,目前关于中文微博的用户性别分类方法研究还比较缺乏;其次,本文将组合分类方法应用到解决微博用户性别识别问题中,用于组合分别基于用户名特征和微博文本特征的两个基分类器。实验结果表明该方法要明显优于已有的特征叠加方法,例如,Burger等[3]。
3 语料描述
我们利用新浪微博*http://weibo.com提供的开放API接口获取用户数据。数据包含用户的个人信息(包含用户名、性别、及其认证类型等)及用户近期发表的微博。具体而言,我们首先随机选择一个用户,获取其用户信息包括他的关注者、粉丝ID;然后再收集其关注者、粉丝的微博信息;最后重复以上操作直到收集工作结束。需要说明的是,在获取语料的过程中考虑到存储空间的局限性及为了提高抓取的速度,我们限制每个用户的微博数目不超过500条。并且为了保证实验结果的精确性,我们过滤掉了发表微博次数小于3的用户。
新浪微博根据用户的认证类型将用户分为5大类: “黄V用户”、“蓝V用户”、“微博女郎”、“达人用户”和“普通用户”。其中“蓝V用户”是一些企业性质的用户而非个人用户,“普通用户”是指没有经过新浪微博官方认证的用户(包含个人用户和企业性质的用户)。为了避免大量的人工标注及保证实验结果的精确性,本次实验中我们抓取了除这两者以外的其他经过官方认证的个人用户,总共4 190个。其中男性用户1 880个,女性用户2 310个。各种认证类型的用户数目如表1所示。
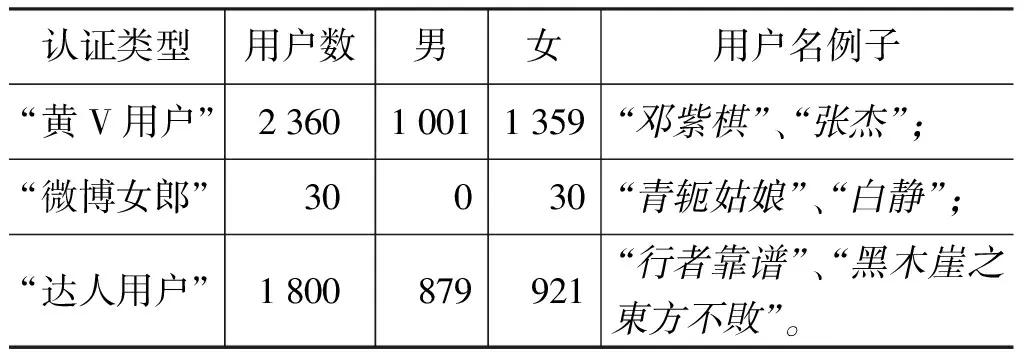
表1 不同认证类型的用户介绍及实例
4 微博用户的性别分类方法
本文采用基于机器学习的方法进行用户性别分类。首先,我们从两种文本(即: 用户名和用户发表的微博文本)中抽取特征;然后,基于这两种文本分别构建两个不同的分类器;最后,采用组合分类器方法对这两个分类器进行融合,以便获得更佳的分类性能。下面我们将具体描述这两种文本的特征及组合分类器方法。
4.1 特征分析
用户名文本: 根据用户名文本,我们发现女性用户的用户名尾字普遍包含偏女性化字眼。例如,“刘雯雯”、“黄晓萌”、“休眠中的王小姐”等。并且像“妞妞”、“女王不淡定叻”、及“珊珊”这些用户名,根据其首字判断其为女性用户的可能性较大;此外,男性用户的用户名也有类似的特点。例如“赵英俊是潇洒哥”、“林书豪”、“天行者-王猛”及“好好先生李大爷”这几个用户名,根据其尾字判断其为男性的可能性较大。因此,我们考虑将用户名的首尾字特征加入特征空间,即在首尾字特征后加入特定符号(例如“_f”、“_l”等)以示区别。
发表的微博文本: 对于用户发表的微博文本,我们利用一种标准的特征选择方法信息增益(IG)[16]计算了其每个词特征的性别信息量。并且对男性和女性用户的微博文本分别选取了前10个IG值最高的词特征,如表2所示。从表4中可以看出,用户发表的微博文本中包含了许多与性别相关的字眼和称谓,而这些特征能给我们预测用户的性别提供很好的线索。例如,“哥”、“老婆”这两个特征更可能来自男性用户,而“亲亲”、“老娘”等更像女性用户发表的。
表3和表4给出了一些例子来描述我们选择用户名和微博文本的具体特征的方法。其中,Unigram即一元特征,Unigram+首尾字特征是指在文本一元特征的基础上加入首尾一元特征,Uni+Bigram即一、二元的组合特征,Uni+Bigram+首尾字特征是指在一、二元特征的基础上加入首尾一、二元特征。

表2 男女用户微博文本中前10个IG值最高的词特征
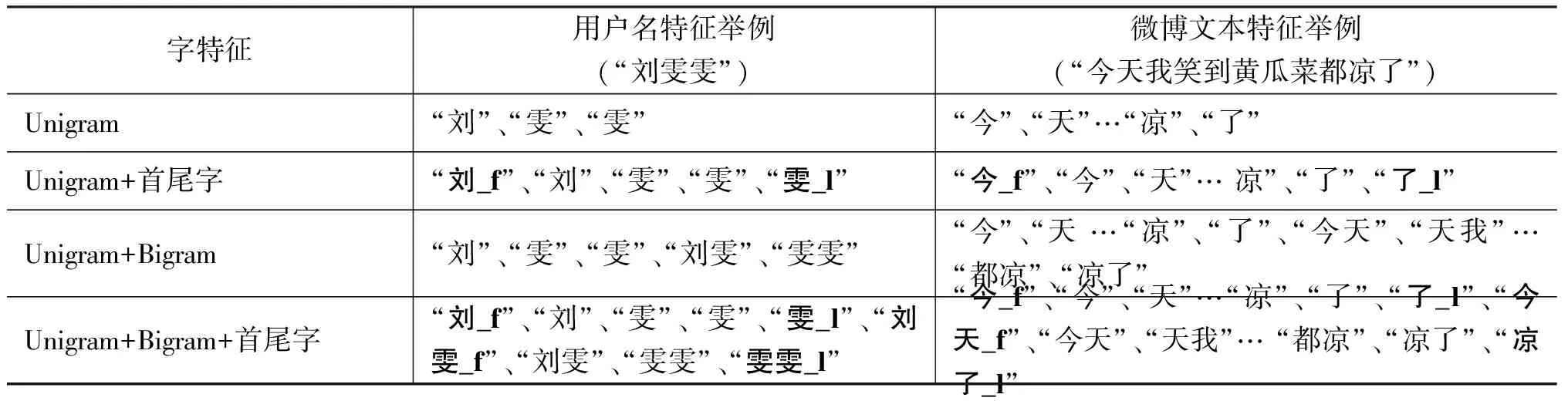
表3 文本字特征介绍及样例

表4 文本词特征介绍及样例

续表
4.2 分类器融合
组合分类方法是融合多个分类器的结果从而得到一个新的分类结果作为最终的分类决定[17]。组合分类方法是模式识别以及机器学习理论研究领域里面的一个重要的研究方向。
图1给出了组合分类器方法的系统框架图。从图中可以看出,我们的组合分类器方法主要分为两步。
(1) 训练基分类器: 我们通过训练两个不同的语料产生两个不同的基分类器。两个基分类器分别为基于用户名文本和基于微博文本训练的分类器。
(2) 分类器融合: 我们利用融合算法将两个基分类器结果融合得到最终分类结果。假设有R个参加组合的分类器fk(k=1,...,R),这些分类器给样本x的分类结果为Lk(Lk=c1,...,cm)。另外,他们提供出了属于每个类别的概率信息:Pk= [p(c1|dk), ...,p(cm|dk)]t,其中p(ci|dk)表示样本dk属于类别ci的概率。如果样本dk属于类别cj,在不同的融合算法中需要满足不一样的条件。本文中我们采用的是一种常见的固定融合算法,贝叶斯规则的条件如式(1)所示。

图1 组合分类器系统的框架架构
5 实验
5.1 实验设置
本实验中,我们利用新浪微博API收集了 4 190个经过官方认证的个人用户的信息及其发表的微博文本。其中男性用户有1 880个(正类样本),女性用户有2 310个(负类样本)。本实验的任务是利用用户的用户名和微博文本来识别用户的性别。在实验过程中,我们采用最大熵方法(Maximum Entropy,ME)作为分类算法,其中ME使用的是MALLET机器学习工具包*http://mallet.cs.umass.edu/。在使用个工具包的时候,所有的参数都设置为它们的默认值。此外,我们采用用户名和微博文本的字和词等特征构建分类器,具体的特征描述可参考4.1节。需要说明的是,我们采用复旦大学自然语言处理实验室开发的分词软件FudanNLP*https://code.google.com/p/fudannlp/对文本进行分词操作以便选取词特征。从搜集的样本中,我们选取2 800个样本作为训练样本,200个样本作为测试样本。
5.2 实验结果与分析
首先,图2给出了分别使用用户名文本和微博文本的不同特征时的分类结果。从结果可以看出:

图2 基于字和词特征的分类结果比较
1) 利用用户名文本进行分类时,其字特征要明显优于词特征,高出的幅度超过9个百分点。该结果主要是因为分词操作对用户名文本进行切分时,会将某些用户名作为一个整体,导致训练样本特征空间非常稀疏。此外,用户名中的某些字,例如,称呼(“姐”、“哥”等)对性别分类是有很大帮助的;而利用微博文本分类时,词特征要好于字特征。在Uni+Bigram下尤其突出,前者比后者高出了3.5个百分点。
2) 在Unigram基础上加入Bigram特征后,微博文本在字特征和词特征下分类性能都获得了提升,其中使用词特征时提高了3个百分点。然而,在使用用户名文本时,性能提高并不明显。
其次,考虑到首尾字对用户名分类的重要性,我们尝试将用户名的首尾字作为特征加入到特征空间中,具体来讲,在首尾字后追加特殊符号,例如“_f”、“_l”以示区别,实验结果如图3所示。由图3可以看出,对于用户名,加入首尾字特征后分类性能获得了提升。其中字的Uni+Bigram特征下最明显,提高了两个百分点;对于微博文本,加入首尾字特征对分类结果没有影响。这是由于用户名如4.1节特征分析中描述的一样,其首尾字对性别的区分有帮助,而微博文本的首尾字对性别分类并没有特殊意义,并且每条微博训练样本太长,分类器的特征空间太大,导致加入的两类用户名特征对分类结果没有影响。

图3 加入首末字特征的分类结果
值得注意的是,从图2和图3可以看出,微博文本的分类效果始终要明显优于用户名的分类效果。在使用字特征的时候,前者仍比后者平均高出10个百分点。为此,我们特地随机抽取200样本(男女各100),采用人为识别的方式对用户名进行性别分类,结果显示在表5中。如表5所示,分类器的分类效果(使用最好特征集合)只比人工标注的低4.8个百分点。即使通过人工来识别用户名,其分类效果仍比通过微博文本识别差8.2个百分点。其主要原因是某些用户的用户名不包含明确的性别特征,例如,“思想聚焦”、“爱吃鱼的列”、“幸运素数”等。

表5 用户名性别识别的人工识别效果和自动识别效果比较
综合以上结果分析得出: 对于用户名文本,利用其字的Uni+Bigram+首尾字特征分类效果最佳。而对于微博文本,其词的Uni+Bigram特征表现最好。因此,我们使用这两种特征作为两种文本的基分类器的特征实现,用于进一步的分类器融合。
在上述的特征研究的基础上,我们给出下面4种分类方法的分类结果进行比较。
• 用户名: 利用用户名文本的字的Uni+Bigram+首尾字特征训练基分类器;
• 发表的微博: 利用用户所发微博文本的词的Uni+Bigram特征训练基分类器;
• 特征叠加: 将上述两种方法中的两种特征叠加之后作为训练集训练分类器;
• 融合: 训练上述用户名和微博文本的两个基分类器,然后根据贝叶斯融合规则将两个基分类器融合,得到最终分类结果;
图4给出训练样本规模从900变化到2 800时这四种方法的分类准确率。从图中可以看出: 1)将用户名和微博文本进行特征叠加并不能明显提高分类性能。该结果的可能原因是微博的特征空间远远高于用户名的特征空间,导致用户名特征不足以对分类结果产生影响。相比而言,分类器融合方法获得的分类性能明显优于其他3种方法,比用户名分类器平均提高出18个百分点,比微博分类器平均提高3个百分点。2)训练样本从900变化到2 800时,融合的结果稳定提高,且始终高于其他3种方法。该结果表明我们的融合方法有较好的稳定性。

图4 4种分类方法分类结果比较
最后,我们对分类结果进行分析,发现分类错误主要存在以下几点原因: 1)测试样本中仍然存在某些特征未在训练样本中出现,导致分类器无法学习到该部分信息;2)存在部分用户由于发表的微博文本较少而且其用户名属于男性还是女性并不明显,即使人工查看也无法区分其类别,以至于分类方法无法对其进行分类,例如,“思想聚焦”、“爱吃鱼的列”、“幸运素数”等。
6 结论
本文提出了一种基于用户名和微博文本的分类器融合方法来对用户性别进行分类。具体来讲,首先利用用户名和微博文本分别训练两个基分类器,然后根据贝叶斯规则对分类结果进行融合。实验结果表明: (1)在中文微博性别分类中,用户名文本里面的字特征具有一定的分类性能(但分类性能有限);(2)使用微博文本能够获得比使用用户名文本更好的分类性能;(3)我们的分类器融合方法对用户性别的识别能取得最佳的分类性能,并且分类效果明显优于利用用户名文本、微博文本或两者文本特征叠加的分类方法。
除了用户名和微博文本外,微博中往往还包含了其他与用户性别相关的信息,例如,关注者、粉丝及转发等信息。在下一步工作中,我们考虑将更多用户信息加入到中文微博用户性别识别任务中。
[1] 文坤梅,徐帅,李瑞轩等. 微博及中文微博信息处理研究综述[J]. 中文信息学报,2012,26(6): 28-36.
[2] 张剑峰,夏云庆,姚建民. 微博文本处理研究综述[J].
中文信息学报,2012,26(4): 21-27.
[3] Burger J, Henderson J, Kim G, et al. Discriminating Gender on Twitter[C]//Proceedings of EMNLP-11, 2011, 1301-1309.
[4] Schler J, M Koppel, S Argamon, et al. Effects of Age and Gender on Blogging[C]//Proceedings of AAAI-06, 2006.
[5] Yan X, L Yan. Gender Classification of Weblog Authors[C]//Proceedings of AAAI-06, 2006.
[6] Mukherjee A, B Liu. Improving Gender Classification of Blog Authors[C]//Proceedings of EMNLP-10, 2010.
[7] Miller Z, B Dickinson, W Hu. Gender Prediction on Twitter Using Stream Algorithms with N-Gram Character Features[C]//Proceedings of International Journal of Intelligence Science, 2012,2(4):143-148.
[8] Nowson S, J Oberlander. The Identity of Bloggers: Openness and Gender in Personal Weblogs[C]//Proceeding of AAAI-06, 2006.
[9] Peersman C, W Daelemans, L Van Vaerenbergh. Predicting Age and Gender in Online Social Networks[C]//Proceedings of SMUC-11, 2011.
[10] Gianfortoni P, D Adamson, C Rosé. Modeling of Stylistic Variation in Social Media with Stretchy Patterns[C]//Proceedings of EMNLP-11, 2011.
[11] Ikeda D, H Takamura, M Okumura. Semi-Supervised Learning for Blog Classification[C]//Proceedings of AAAI-08, 2008.
[12] Corney M, O Vel, A Anderson,et al. Gender-Preferential Text Mining of E-mail Discourse[C]//Proceedings of ACSAC-02, 2002.
[13] Mohammad S, T Yang. Tracking Sentiment in Mail: How Genders Differ on Emotional Axes[C]//Proceedings of the 2nd Workshop on Computational Approaches to Subjectivity and Sentiment Analysis-11, 2011.
[14] Ciot M, M Sonderegger, D Ruths. Gender Inference of Twitter Users in Non-English Contexts[C]//Proceedings of EMNLP-13, 2013.
[15] Alowibdi J, U Buy, P Yu. Language Independent Gender Classification on Twitter[C]//Proceedings of 2013 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining, 2013.
[16] Li S, R Xia, C Zong, et al. A Framework of Feature Selection Methods for Text Categorization[C]//Proceedings of ACL-IJCNLP-09, 2009.
[17] Kittler J, M Hatef, R Duin, et al. On Combining Classifiers[C]//Proceedings of IEEE-98, 1998.

王晶晶(1990—),硕士研究生,主要研究领域为自然语言处理。E-mail: djingwang@gmail.com

李寿山(1980—),教授,博士后,主要研究领域为自然语言处理。E-mail: shoushan.li@gmail.com

黄磊(1989—),硕士研究生,主要研究领域为自然语言处理。E-mail: lei.huang2013@gmail.com
