汉语显式篇章关系分析
2014-02-28周国栋
丁 彬,孔 芳,李 生,周国栋
(苏州大学 计算机科学与技术学院,江苏 苏州 215006)
1 引言
篇章是指由一系列连续的从句、复句或句群构成,传达一个完整信息、前后衔接、语义连贯的语言单位。篇章分析的主要任务包括研究篇章的内在结构,理解文本单元间承接的语义关系等。篇章分析是自然语言领域至关重要的一部分,对自然语言处理的许多应用,例如,问答系统、指代消解和篇章连贯性评价等有着重要的作用。
近年来,随着宾州篇章树库(Penn Discourse TreeBank, PDTB)的发布,英文篇章分析越来越受到关注,许多基于它的研究工作陆续展开。
本文借鉴PTB和RST英文篇章标注体系,选取汉语树库(Chinese Treebank, CTB)中的500篇文本进行了汉语显式篇章关系的标注,并基于这一语料分析了词法和句法特征对汉语显式篇章关系的作用。
本文组织结构如下: 第2节介绍了显式篇章分析的相关工作;第3节介绍了汉语显式篇章关系语料;第4节给出了一个基于词法和句法特征的汉语篇章分析平台,具体介绍了连接词识别和篇章语义关系分类这两个子任务的具体实现;第5节详细分析了实验结果;最后总结全文并指出下一步工作。
2 相关工作
随着PDTB的发布出现了很多英文篇章关系分析的相关研究。基于PDTB语料库的篇章分析工作主要包括连接词识别、论元标注、语义关系的分类以及隐式篇章关系识别等。其中显式篇章关系研究的代表性工作包括以下几点。
在连接词识别方面,Pitler和Nenkova(2009)使用最大熵模型,第一次将句法方面的特征(这些句法特征已经广泛应用于论元分类等任务中)应用到连接词识别任务中。在只有句法特征的情况下,连接词识别的F1值达到了88.19%。在此基础上,他们将连接词与句法特征相组合,获得了94.19%的连接词识别F1值。Lin等(2012)在P&N的基础上新增了词法特征(包括连接词的词性和词与词性之间的组合)和两种句法路径作为特征。实验结果表明词法特征的加入进一步提高了英文连接词识别的性能,F1值达到了95.36%。
在篇章关系识别方面,PDTB将篇章关系分为4大类[1]。P&N使用上述句法特征对英文显式关系的语义分类进行了研究,在PDTB上使用朴素贝叶斯分类器进行10倍交叉验证。实验结果表明只有连接词作为特征时,4类篇章关系的识别精度为93.67%。加入句法特征后,识别精度提高到94.15%。
与英文相比,其他语言或非新闻领域也有一些相关研究,典型工作包括: Alsaif和Markert(2011)[2]依照PDTB的标注框架对APT(Arabic Penn Treebank)进行标注,并在此基础上研究阿拉伯语篇章中显式连接词的自动识别和篇章关系的分类。其中连接词识别的精度达到了92.4%。Ramesh等(2010)研究了在PDTB和生物语料库(BioDRB)上连接词识别的差异。他们使用条件随机场模型(CRFs)在PDTB上训练分类器,在PDTB和生物语料库上测试的F1值分别为84%和55%。在生物语料上进行交叉验证的F1值达到了69%。
相比之下,对汉语显式篇章关系的研究相对较少,这主要是因为缺乏汉语篇章级别语料。我们依照PDTB框架[3],选取500篇CTB文本进行了显式篇章关系的标注。汉语表达形式多样,篇章连接词的构成比英文复杂,这都给汉语显式关系分析造成了一定的困难。本文使用最大熵模型,结合词法、句法等特征,构建了汉语显式篇章关系分析平台,并通过实验分析了汉语篇章关系的复杂性。
3 汉语显式篇章关系语料库
目前可供研究的英文语料库主要有RST Discourse Treebank(RST-DT)和PDTB。RST-DT由美国南加利福尼亚大学和华盛顿国防部联合标注,2002年由LDC(Linguistic Data Consortium)发布。它先利用RST-Tool工具对文本进行预标注,主要包括文本的切割(生成小句)和初始修辞关系的生成,然后人工验证预标注的结果,判断文本的切分是否正确,并为功能语句对标注一个可能性最大的修辞关系。
PDTB由LDC于2008年发布,是目前规模最大的英文篇章级别的语料库。PDTB共标注了以下几种类型: (1)显式和隐式关系连接词;(2)Alternative Lexicalization(AltLex);(3)Entity-based Coherence Relation(EntRel);(4)No Relation(NoRel)。PDTB还定义了一个三级层次的语义结构,第1层包括Temporal、Contingency、Comparison和Expansion 4类语义,第2层包括16类语义,第3层包括23类语义。
与英文相比,汉语表达上更具多样性。参考RST理论,借鉴PDTB体系,我们选取汉语树库(Chinese Treebank,CTB)中的500篇新闻文本进行了汉语显式篇章关系的标注,共标注了1 690个显式关系,标注内容主要包括连接词及其驱动的篇章关系的类别。
与英文PDTB体系类似,我们将汉语连接词也限定在某一范围内,设定了258个词构成的连接词列表,并根据这些连接词在词语构成及语义表达上的主次关系选定了其对应的中心词,最终形成了180个连接词中心词列表。
在篇章关系方面,我们标注了4大类关系: 因果类、并列类、转折类和解说类。每一类细分了具体的关系小类,共17个。汉语篇章关系的划分如表1所示。

表1 汉语篇章关系的划分
接着我们以汉语中出现频度较高的连接词“而”为例介绍汉语显式篇章关系的标注。表2给出的6个例子均摘自CTB语料,我们可以看到,句1中“而”作为连接词,表述的是转折关系;但在句2中“而”并不承担连接词角色。此外,“而”作为连接词,不仅可以表述转折关系,还可以表述其它语义关系。在例句3—5中的连接词“而”表述的语义关系分别为: 递进关系、因果关系和例证关系。此外例句6中,“不……而”承担了篇章连接词的角色,但就连接词构成成分及其表述的语义关系看,“而”是这一连接词的中心词。

表2 连接词及其语义关系示例
4 汉语显式篇章关系分析平台
汉语表达形式多样,本节结合汉语特点给出了一个汉语显式篇章关系分析平台,由篇章连接词识别和篇章关系分类两部分构成。
4.1 篇章连接词识别
篇章连接词通常用来显式地表述基本文本单元之间承接的篇章关系。与英文类似,汉语中连接词候选也存在是否承担了篇章连接词角色的歧义。例如,表3给出的示例,就连接词候选“和”而言,例句1中的“和”承担了篇章连接词角色,表述的是并列关系,而例句2中的“和”并不是篇章连接词。所谓篇章连接词识别,正是针对连接词候选的这种歧义展开,主要任务就是确定连接词候选是否承担了篇章连接词的角色。

表3 连接词候选是否承担篇章连接词角色的歧义示例
本文将连接词识别看作一个二元分类问题,首先根据语料标注中预定义的180个连接词的中心词列表获取连接词候选集,再针对每一连接词候选来选取特定的上下文特征,使用最大熵方法进行训练和预测[4]。
我们考虑的上下文特征主要包括词法和句法两方面。词法特征主要描述连接词及其所处的上下文词汇集的信息,而句法特征主要基于句法分析的结果获取连接词所在位置的句法信息[5]。此外我们还考虑了连接词与句法特征的组合以及多种句法特征间的组合信息。以表2中的句1为例,表4给出了连接词识别模块所使用的特征集,及其详细描述和取值情况。图1给出的是该例句中连接词候选“而”所处上下文的部分标准句法树。
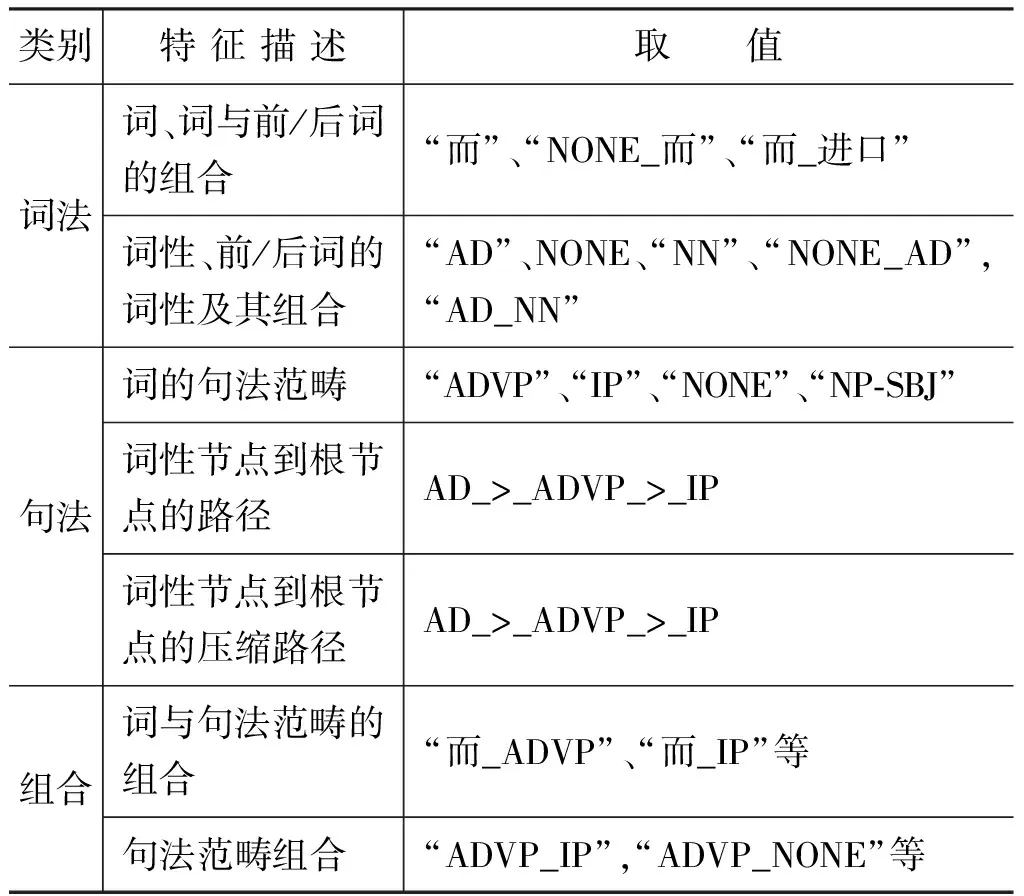
表4 特征集及其对应的描述
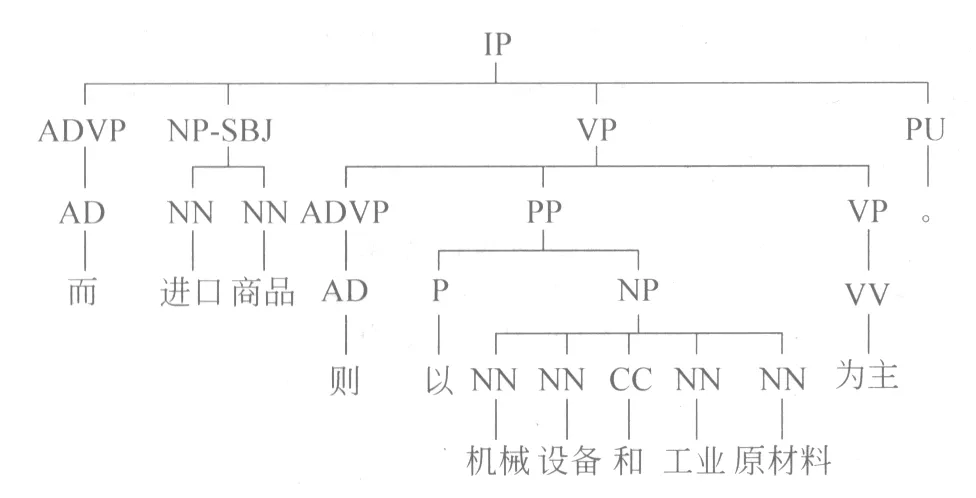
图1 表2示例中例句1对应的标准句法树
4.2 篇章关系分类
通常连接词在篇章中表述某个特定的语义关系,例如,“并且”承担连接词角色时,一般用来表述并列关系。但一些连接词在表述篇章关系时也存在语义上的歧义。例如,表5中给出的两个例句,“对此”都承担了篇章连接词角色,但例句1中的“对此”表述的是因果关系,而例句2中的“对此”则表述了一个评价关系。篇章关系分类主要完成的工作是,根据连接词及其所处的上下文判定其所表述的语义类别。

表5 篇章关系语义类别示例
本文将篇章关系识别看作一个多元分类问题。与连接词识别类似,我们针对每个连接词选定特定的上下文特征,再借助最大熵模型训练、判别连接词所表述的具体语义关系。由于显式关系是由篇章连接词驱动的,因此我们采用的特征包括词和它的词性。
5 实验与分析
构建了汉语显式篇章关系分析平台后,我们进行了实验验证。为了有效利用语料,我们采用10倍交叉验证的方法进行后续实验。实验中最大熵模型采用OpenNLP提供的maxent工具包*http://maxent.sourceforge.net/,参数均使用默认选项。标准句法树选自CTB,自动句法树使用Berkeley句法分析器*http://code.google.com/p/berkeleyparser/获得(使用完全正确的分词)。评测指标方面我们采用标准的准确率(Precision)、召回率(Recall)和F1值。
5.1 篇章连接词识别
本文采用了3类特征对连接词进行识别,表6给出了标准句法树下各类特征的贡献度。从表中可以看出只使用词法特征,连接词识别的F1值达到了65.9%。进一步考虑句法和组合特征,系统性能都有所提高。
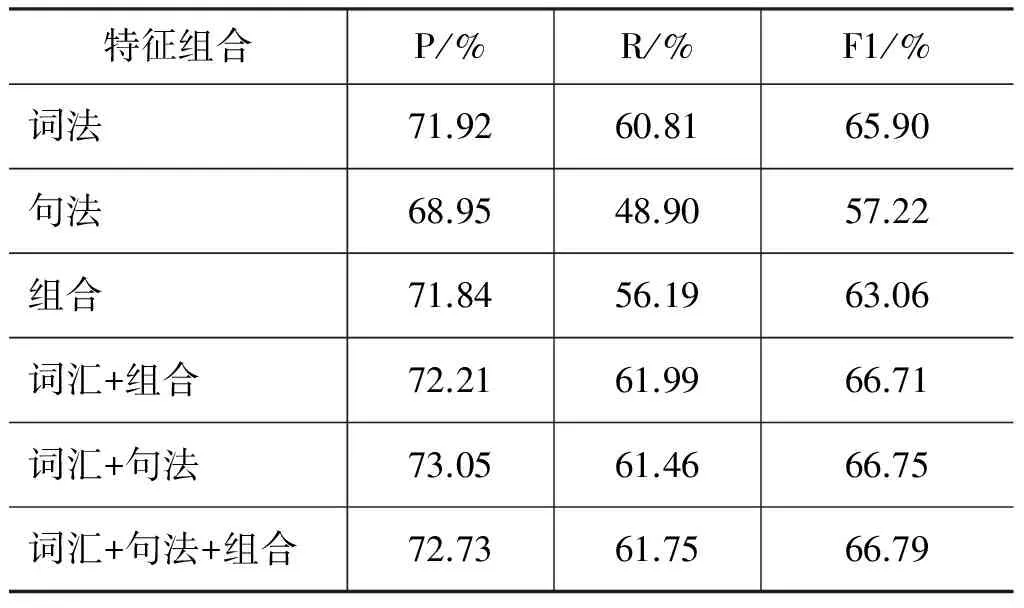
表6 标准句法树下各类特征的贡献度
表7给出了标准句法树和berkeley句法树下汉语篇章连接词识别的性能。我们可以发现篇章连接词识别的性能相差极小,即汉语篇章连接词识别性能对句法分析的性能好坏的依赖度较小*实际上这一结论与英文篇章连接词识别的研究一致。英文中自动句法分析对连接词识别F1性能的影响小于2%。。
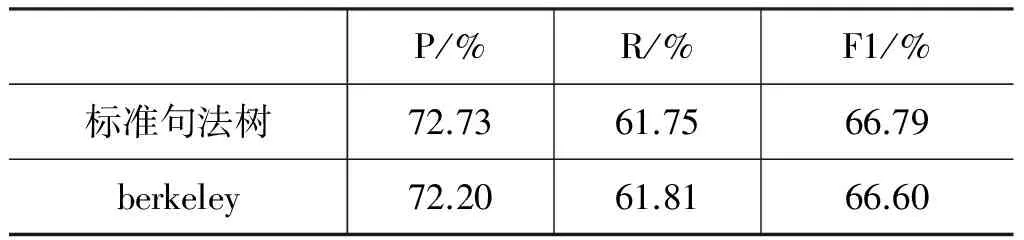
表7 连接词识别的性能
与英文连接词识别的性能相比,汉语连接词识别性能比较低。为此我们对180个中心词在语料中的分布情况进行了统计,其中有76个中心词在标注的显式关系中只出现了一次。我们对这76个中心词的识别情况进行了验证,发现由于训练实例较少,只有极少数被识别正确*训练、测试集中去除这部分连接词候选后,系统F1值提升了0.5%,但不能通过显著性测试。。
5.2 篇章关系分类
由于显式篇章关系是由连接词驱动的,连接词在篇章关系语义类别的表述上起着关键性的作用。表8给出了语料库中标注的1 690个显式关系在4大类上的分布情况,从中可以看到,并列关系比重最高,占到了一半以上,转折和解说类关系比重相对较低。
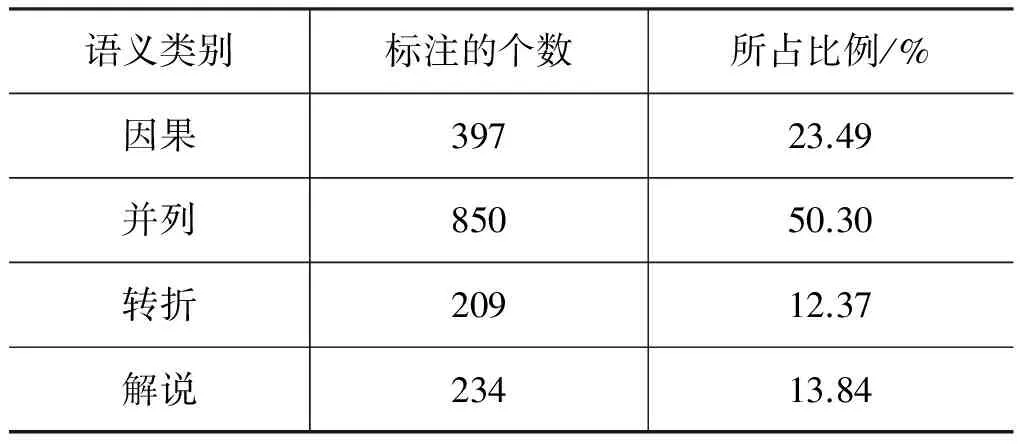
表8 语义类别的分布情况
我们采用词和词性作特征进行实验,表9给出汉语显式关系语义分类的性能。从实验结果可以看出,与英文显式关系类似,汉语显式关系的语义类别与连接词有很强的依赖,即确定了篇章连接词后,其语义一般没有歧义。
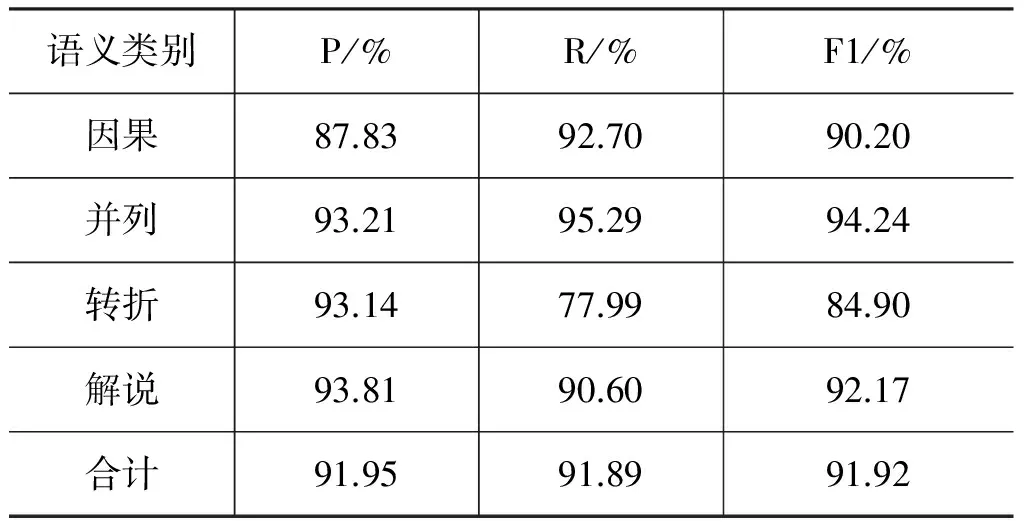
表9 汉语显式关系语义分类的性能
所有的连接词中,部分连接词在标注的语料库中出现的次数相对较多。从表10中我们可以看到,“并”、“其中”和“还”绝大多数实例都归为一类,构造出的分类器也确实将其归为了比重最高的一类。对于“而”,它的歧义最多,它在标注的语料中出现了81次,其中57次被标为并列类,约占70.37%,分析实验结果发现,我们的分类系统将它也均归为了并列类,其分类性能的F1值为82.61%。
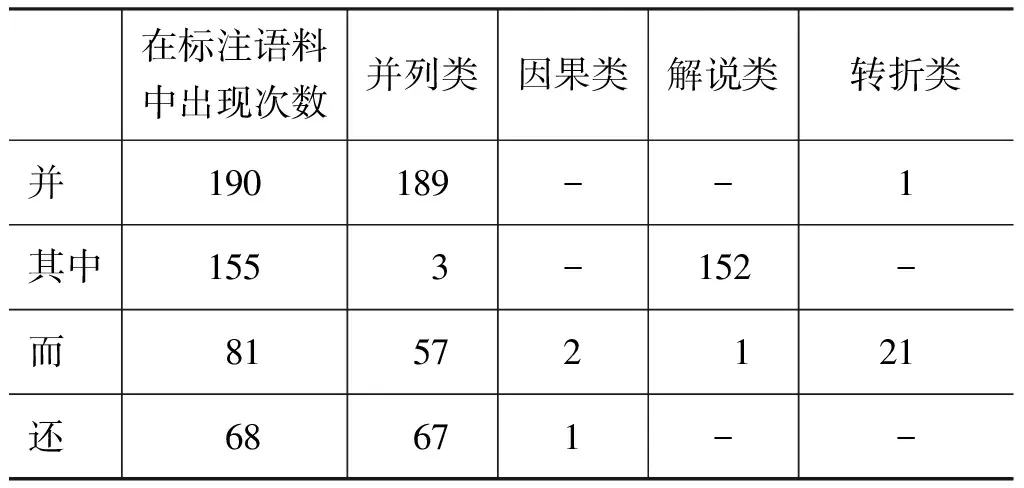
表10 出现频度较高(>50次)、有歧义的连接词的语义分布
6 结论
借鉴英文PDTB和RST语料,我们选取500篇CTB文本进行了汉语显式篇章关系的标注,基于这一语料构建了一个汉语显式篇章关系分析平台,并给出了实验结果及分析。为汉语篇章关系的分析奠定了良好的基础。但从实验结果看,与英文显式篇章关系分析相比,汉语篇章连接词识别的性能偏低。对此我们将尝试寻找新的符合汉语语言特性的特征,来提高汉语显式关系分析的性能。另一方面还将考虑利用汉语语料中标注的隐式关系,来辅助汉语显式关系的分析。
[1] Rashmi Prasad, Nikhil Dinesh, Alan Lee, et al. The Penn Discourse Treebank 2.0[C]//Proceedings of the 6th International Conference on Language Resources and Evaluation (LREC 2008),2008: 2961-2968.
[2] Alsaif A, Markert K. Modelling discourse relations for Arabic[C]//Proceedings of the Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 2011: 736-747.
[3] Xue N. Annotating discourse connectives in the chinese treebank[C]//Proceedings of the Workshop on Frontiers in Corpus Annotations II: Pie in the Sky. Association for Computational Linguistics, 2005: 84-91.
[4] Berger A L, Pietra V J D, Pietra S A D. A maximum entropy approach to natural language processing[J]. Computational linguistics, 1996, 22(1): 39-71.
[5] PDTB-Group. The Penn Discourse Treebank 2.0 Annotation Manual[OL]. The PDTB Research Group.2007.
[6] Emily Pitler, Ani Nenkova. Using syntax to disambiguate explicit discourse connectives in text[C]//Proceedings of the ACL-IJCNLP Conference Short Papers, Singapore, 2009.
[7] Ziheng Lin, Hwee Tou Ng, Min-Yen Kan. A PDTB-styled end-to-end discourse parser[J]. Natural Language Engineering. 2012,1(1):1-35.
[8] Ramesh Balaji, Hong Yu. Identifying discourse connectives in biomedical text[C]//Proceedings of AMIA Ann Symp Proc 2010:657-661.
