垂直搜索引擎中的分词算法研究
2014-02-27潘磊宁方建安金林骏
潘磊宁 方建安 金林骏
(上海市东华大学信息科学与技术学院 上海 201620)
0 引言
近年来,爆炸式增长的信息和不断发展的互联网技术,使得 WEB的信息量急剧增长,格式以及内容不断翻新,而通用搜索引擎由于存储、计算资源和带宽等方面的问题想要检索互联网上全部的网页是不可能的[1]。从海量的信息中准确快速地搜索出特定的内容十分困难,如何从网络中的海量信息里快速而有效地查询到所需有价值的信息己成为人们关注的重点[2]。
垂直搜索引擎具有专、精、深的特点,可通过面向某一特定的领域、人群或需求仅搜索网络中的特定主题信息。它采用主题爬虫对特定主题的网页进行抓取,对特定的领域进行了专业的过滤和筛选,使得某一特定领域内信息更加全面和深入,并且它可以聚合信息、处理索引,提供有价值的相关服务和信息,从而提高用户检索时的准确率[3]。因此,为了满足特定领域的用户需求,保证检索结果的专业性,人们开始对垂直搜索引擎进行研究。
面向主题的垂直搜索引擎与通用搜索引擎存在如下差别:首先,通用搜索引擎面向任何用户提供对任何信息的查询,而垂直搜索引擎则面向专业用户向他们提供对其所在专业的信息检索;其次,通用搜索引擎对网络进行逐页的爬行,试图遍历整个Web。而垂直搜索引擎则采用一定的策略预测相关网页的位置,动态地调整网页爬行方向,使系统尽可能的在与主题相关的网页集中的地方爬行,这将节约大量的网络资源。最后,通用搜索引擎对硬件的需求过大,而垂直搜索引擎由于没有遍历整个Web节约了大量的网络资源,而且没有自己的大型索引数据库所以硬件需求也比较低。因而,研究垂直搜索引擎具有很好的现实意义。
分词技术是任何一个垂直搜索引擎的“灵魂”,能否将检索请求中的关键字通过正确的理解从句子中正确切分出来并进行匹配查找,是一个搜索引擎能否得到正确结果的关键过程。分词的准确与否会直接影响到检索结果的正确率,因此文中将主要研究垂直搜索引擎中分词技术的算法的改进,并通过实验验证其有效性。
1 现有的分词算法
现有的中文分词算法主要可分为三大类:基于字符串匹配的分词算法、基于理解的分词算法和基于统计的分词算法。
基于字符串匹配的分词算法:基于字符串匹配的分词算法是指与已有词典里的词进行一一匹配,匹配上的词输出到结果,匹配不上的词常以单字的形式输出,它通过对已有词典的机械匹配来得到分词结果。按照扫描方向的不同,可以分为正向匹配和逆向匹配;按照优先匹配算法不同,可以分为最大匹配和最小匹配。
基于理解的分词算法:基于理解的分词算法让计算机模拟人对句子的理解,达到识别词的效果,基本思想是在识别词的同时进行句法、语义分析,利用句法和语义信息来处理歧义。这种分词算法需要大量的语言知识和信息,由于中文的复杂性,计算机很难成功地模拟理解语义,目前还处在实验阶段。
基于统计的分词算法:词是稳定的字的组合,在上下文中相邻的字同时出现的次数越多,就越有可能构成一个词,因此字与字相邻共现的概率能较好地反映成词的可信度。基于统计的分词算法对文本中相邻共现的字的组合进行统计,记录计算两个或多个汉字相邻共现的概率,当这一概率超过某一阈值时,认为这一字组构成了词。这一分词算法不需切分词典,但可能会误认一些共现概率高的字组为词,比如“我的”等,并且算法的时间和空间开销都较大。在实际使用中,经常将这一算法与基于字符串匹配的分词算法相结合,既发挥基于字符串匹配的分词算法分词速度快、效率高的优点,又利用了基于统计的分词算法结合上下文识别生词、消除歧义的优点。
中文分词的一个巨大非技术障碍乃是分词规范和标准问题,虽然中文分词已经有很多年的研究历史,但是迄今为止国内仍没有一个公开的、受到广泛认可的、可操作的分词规范,也不存在一个通用的大规模评测资料。这使得众多研究者的研究结果之间缺乏真正的可比性,从而制约了中文分词技术的提高,能够真正公开为大众所用的较好的分词工具很少。
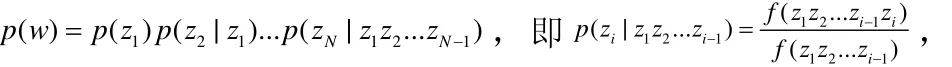
2 改进的分词算法
2.1 理论基础
字是组成文本的最小元素,词语是字为表示特定概念按照一定顺序组合在一起所形成的文字序列,设所有字的集合为Z={z1, z2, z3,...,zn},则一个词 wi可以表示为 zi1zi2zi3...zik,其中 zij∈ Z,并记词的集合为 W={w1, w2, w3,...,wm}。对于比较复杂的词语也可以通过词或字的相互组合来表示,比如w1= z1z2, w2= z3z4z5, w3=z1z2z3z4z5,则 w3= w1w2, w3= z1z2w2, w3= w1z3z4z5。
设 wi=zi1zi2zi3...zik是可以提取的一个文字序列,定义该文字序列在所有文本集中出现的频率为该文字序列的支持度,即支持度Support( wi)=,其中是文本集 T的文本总数量,freq( wi)是文本集 T中出现文字序列 wi的文本数量,即该序列在一个文本中出现的概率 S upport( wi)= P( wi)。根据贝叶斯概率公式,文字序列的支持度又可表示为Support( wi)= P ( zi1zi2zi3...zik)= P ( zi1zi2...zij)*P( zij+1zij+2...zik| zi1zi2...zij),记子序列 w=z z...z,i1i2ij w=zij+1zij+2...zik,则有 P( wi)= P ( w)*P ( w|w),或者
对于任意一个文字序列 wi=zi1zi2zi3...zik,可以将其拆分成多个子序列,如果存在一个拆分wi= zi1zi2zi3...zik= zi1zi2...zijzij+1zij+2...zik= ww,并且 w、 w都是一个词语,则称为一个文字序列 wi的一个有效拆分。
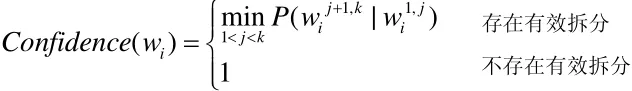
根据关联规则理论,强关联规则应同时满足最小支持度阈值和最小置信度两个条件,本文将强关联规则作为衡量文字序列是否可以称为词语的依据,根据关联规则理论如果一个文字序列能同时满足最小支持度和最小置信度两个条件,那么该文字序列可作为一个独立的词语存在;最小支持度与最小置信度是文字序列成为词语的充分必要条件。在现实文本中,存在大量高频短语,但如果某高频短语能拆分成更加高频的词语,那么使用该高频短语作为独立词语的意义将被消弱,相反对于一些不可拆分的短语,如果在文本中经常出现,那么它将很有必要作为一个词语来使用。
2.2 改进算法的描述
挖掘关联规则的通用算法是一种计算量比较复杂的算法,比如Trie字典树算法等,由于词语本质上就是连续的多个字组成的序列,在词语中字与字之间存在严格的顺序关系,本文在Trie字典树算法基础上,提出一种专门处理中文本文词语的改进分词算法。与Trie字典树算法类似,该算法挖掘关联规则的过程为先找到满足最小支持度的频繁集,并构造Trie树,然后由频繁集产生同时满足最小支持度和最小置信度的强关联规则来发现词语。
但不同的是Trie字典树算法是按照项目出现的频率大小顺序创建字典树,而该算法首先找出可能的所有阶的频繁集,并将频繁集按照字序列中字的顺序存储到字典树中;Trie字典树算法是按照深度优先的规则遍历字典树,而该算法按照宽度优先的规则逐层遍历字典树,判断文字序列是否能构成强关联规则,将构成强关联规则的文字序列确认为词语并保存在字典树中,否则删除该序列。
2.3 改进算法的具体构建
2.3.1 获取文字序列

2.3.2 建立字典树
字典树在文本挖掘中经常使用,它将文字序列放在一个树结构中,每个字对应树中的一个节点,前后两个字在树结构中构成父子节点关系,并通过hash表存储每个节点所拥有的孩子节点。一个独立的子序列在字典树中对应一个从根节点到某个节点的链路,并在序列末尾对应节点上标记该序列出现的频率,通过字典树可以快速查找某个文字序列是否出现在集合中。
2.3.3 分词
该算法在挖掘强关联规则的过程是逐层处理的,首先遍历字典树中由两个字组成的序列,根据置信度计算公式,计算每个序列的置信度,判断是否构成强关联规则,若构成强关联规则则选定为词语,否则删除该子序列,然后依次遍历三个和更多个字组成的序列的置信度。在分阶挖掘词语时,遍历字典树的过程使用宽度优先遍历算法,经过宽度优先遍历算法遍历字典树之后,字典树中剩余的文字序列均构成词语,再次遍历字典树可获取所有挖掘出来的词语。
3 改进分词算法的效果
语言模型的有效性一般通过考察准确率和召回率来衡量,准确率就是抽取正确的词语数量与所有抽取的词语数量的比值,召回率是自动抽取并出现在人工词表中的词语数量与人工词表数量的比值,即召回率=抽取正确的词语数量/所有抽取的词语数量,召回率=自动抽取并出现在人工词表中的词语数量/人工词表数量。
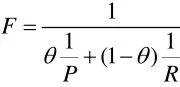
这里做了个实验,是在相同阈值情况下与N-gram模型的对比,为验证本文提出的算法的有效性,实验样本取自新浪新闻网(sina.com.cn)的2万篇中文网页,根据经验,该算法最小支持度取值0.005,最小置信度取值0.1,同时使用分别基于二元模型和三元模型的N-gram算法,词频阈取值20。在同样的硬件环境中分别运行三种算法模型,并记录各自抽取的词语数量和运行时间,同时采用随机抽样方式统计构词词语的有效性,结果对比如下表所示:
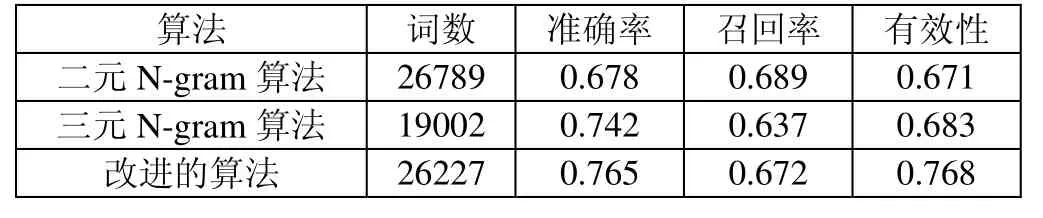
算法 词数 准确率 召回率 有效性二元N-gram算法 26789 0.678 0.689 0.671三元N-gram算法 19002 0.742 0.637 0.683改进的算法 26227 0.765 0.672 0.768
由上表可以看出,与常用的 N-gram算法相比,本文提出的改进分词算法更有效,获取的词语也更全面,同时能保持较高的运行效率。
4 结束语
为了提高垂直搜索引擎的检索效率,本文先是充分分析了现有的分词算法,并且介绍了有关的关联规则理论,然后在此基础上提出了一种改进的词算法。与最常用的是N-gram语言模型相比,该算法不受N值限制,可以从大量文本中自动快速获取文本中常用的词语,并构成词库。本文在最后通过实验证明该算法比N-gram语言模型更有效,获取的词语更全面,同时能保持较高的运行效率。
[1]缪丹,李天瑞.面向商品比价应用的垂直搜索引擎系统设计与实现.西南交通大学研究生学位论文.2012,5.
[2]赵立磊,潘东华.基于网页去重的垂直搜索引擎设计与实现.大连理工大学研究生学位论文.2012,6.
[3]Paolo Boldi,Bruno Codenotti,Massimo Santini and Sebastiano Vigna.Ubicraw ler:A scalable fully distributed web craw ler.Software:Practice &Experience.2004,8.
