基于规则的越南语命名实体识别研究
2014-02-27闫丹辉毕玉德
闫丹辉,毕玉德
(洛阳外国语学院,河南 洛阳 471003)
1 引言
命名实体是指文本中的固有名称、缩写及其他唯一标识,主要包括文本中出现的组织机构名、地名、人名、时间表达及数值表达等。命名实体识别是信息抽取的重要研究内容,在信息检索、机器翻译和问答系统等自然语言处理领域有着广泛的应用。
从目前所掌握的资料来看,在现代越南语(以下简称越南语)命名实体识别方面的研究仍相对较少,具有重大的研究意义及应用价值。
越南学者Tri Tran Q, Thao Pham T X, Hung Ngo Q, Dien DINH, Nigel COLLIER提出了一个基于支持向量机(SVM)的越南语命名实体识别模型[1]。这也是首次将该机器学习方法应用于越南语命名实体识别。实验表明,该模型的识别效果超过了基于条件随机域(CRF)的模型,总体F值达到了87.75。作者分析了越南语的构词特征及词形特征,在此基础上提出了一个基于SVM的越南语命名实体识别模型。实验结果表明,该系统对越南语人名、机构名、地名识别的准确率分别达到了92.91%、85.16%、89.13%,召回率分别达到了87.09%、77.11%、88.75%。
本文从语言学角度分析了每类命名实体的构成规律,并将这些规律在计算机中进行了形式化表达。该方法具有较好的扩展性,并在实验中取得了较好的识别效果。本文语料来源为2009年河南省洛阳市社科规划重点项目“现代越南语语料库建设(2009A028)”成果。语料涵盖人文社科、自然科学及综合类等各方面。
2 越南语组织机构名识别
越南语是一种孤立语,没有词汇的形态变化,声调多。越语音节界限分明,一个音节就是一个字,书写时每个音节之间用空格分开。例如,
越南语采用拉丁字母书写系统,是一种记音文字,因而存在字母的大小写问题。越南官方出台相关的书写规范。例如,规定越南人名、地名在书写时每个音节首字母必须为大写形式,这在越南人名、地名识别中是个非常有用的特征。对于机构名的书写来说,并没有明确的书写规定,但是通过对语料进行分析,我们发现机构名存在着特殊的书写习惯,可用于对越南机构名识别。
我们将越南语文本中可能出现的机构名称分为以下3类,以进一步对越南机构名的自动识别进行探讨。
2.1 越南国家权力、行政及司法类机构
行政机构是最有代表性的社会组织形式,越南行政机构分为四级,如表1所示。

表1 越南行政机构设置
经过对语料的分析,可归纳出越南国家行政系统机构类别如表2所示。

表2 越南国家行政系统机构类别
对语料中出现的此类越南机构名进行分析可以发现其具有一个显著的特点,即特征词位于机构名短语开头。
形式化表达式中,双引号中的字(“a”)代表字符本身,尖括号内(< >)包含的为出现1次的必选项,方括号([ ])内包含的为可重复1至有限次的项,大括号({ })内包含的为可重复0至有限次的项,竖线( | )表示在其左右两边任选一项。
从分析结果来看,当划分为较细的类别时可分别对每类进行形式化表达,举例如下:
(1) <特征词><工作用词>

(2) <特征词><工作用词>[<“v”>|<“-”>]<工作用词>

2.2 越南政党及社会团体类机构
当前,越南是一个一党执政的国家,越南共产党是越南的执政党。越南共产党各级组织机构的设置与我国类似,主要设置有以下几类机构(表3):
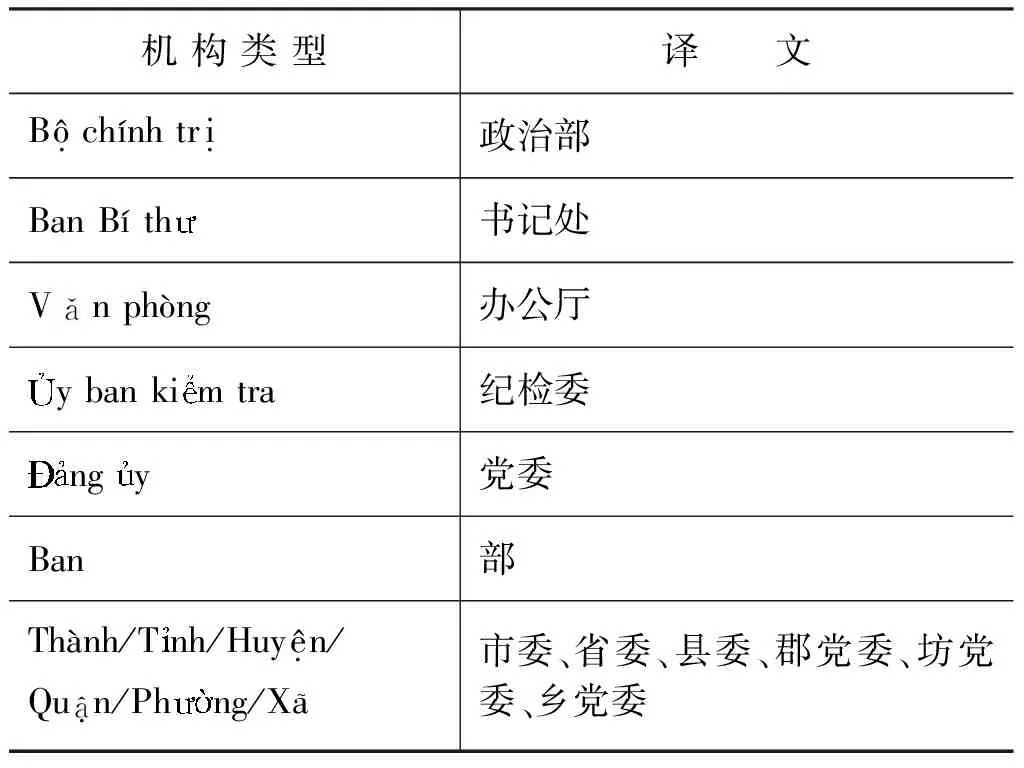
表3 越南共产党组织机构类别
这些机构类别同样可以作为越南共产党机构名识别的特征词。
越南社会同样存在大量的社会团体,例如,越南祖国阵线、越南劳动者联合会总会、越南农民协会等,其中越南祖国阵线是越南具有协商性质的民族统一战线组织,是越南最重要的社会团体,其机构设置具有典型的代表性。下面,我们以该团体为例,介绍越南社会团体中的机构设置。
在中央一级,越南祖国阵线主要设置有如下机构(表4):

表4 越南祖国阵线机构示例
在省一级,越南祖国阵线机构设置如表5所示。

表5 越南祖国阵线机构示例
对于越南政党及社会团体类机构,我们采取如下策略进行识别。首先,建立社会团体数据库,收录越南社会各主要社会团体,以静态匹配的方式对越语文本中的社会团体进行识别。其次,对越南政党类机构进行详细分类,并对每类机构进行形式化表达,以形式化表达作为其识别规则。举例如下:

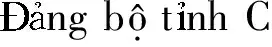

2.3 文化教育、公司企业类机构
对于此类机构名,我们将主要从越南教育系统内的各学校、越南的公司企业等两方面进行介绍和分析。
我们语料中收集了820所越南高校的名称,如表6所示。
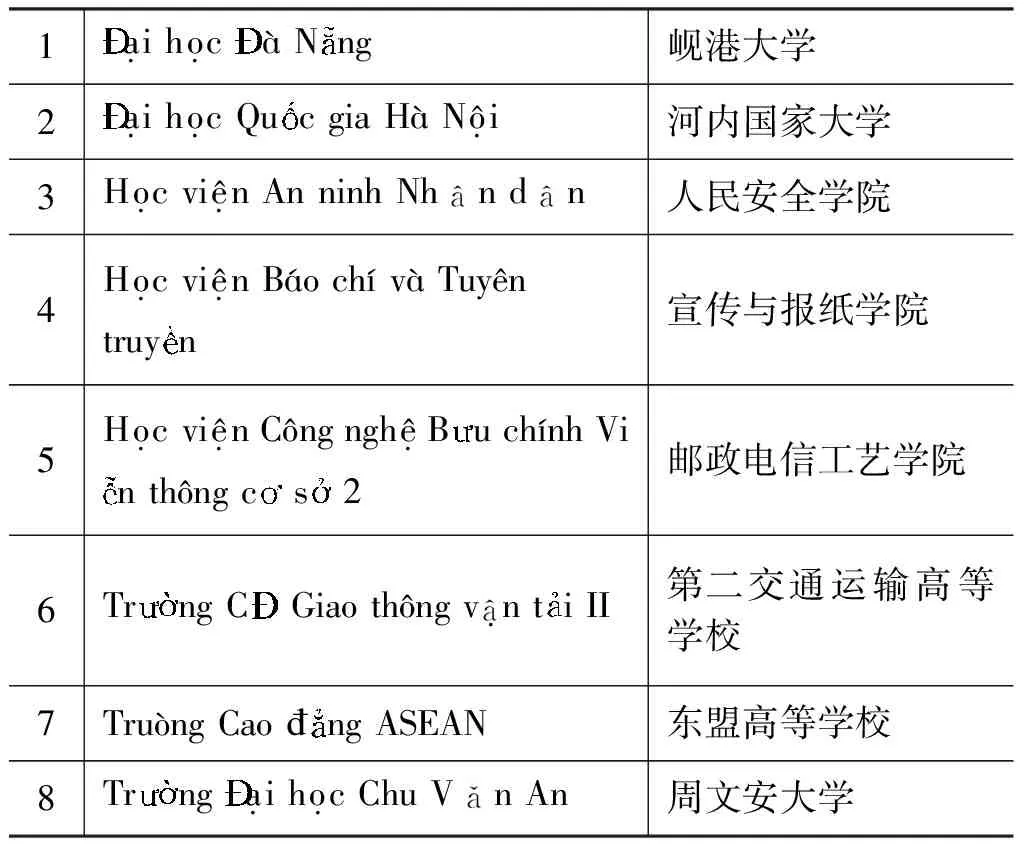
表6 越南高校示例
我们发现,总体上越南高校的命名方式并没有统一的规律可循,且在高校名称中使用缩略语是很常见的现象,例如,将caong(高等)缩略为C,将(中学)缩略为TH,将kinh t(经济)缩略为KT等等,这更增加了对其识别的难度。但对越南高校名称进行详细分类后,我们发现每类高校名的命名方式仍有一定的规律可循,可据此制定相关的识别规则。

表7 越南高校名称用词统计
从表7可以看出,以地名结尾的高校名称最多,占到了约70%;其次是以普通名词结尾的高校名,占约16%;以人名、数词和缩略语结尾的高校名所占比例较小,依次为3%,6%和5%。
在命名方式上,不同类别的高校名称具有不同的构成特点。从分析结果来看,当划分为较细的分类时可分别将每类高校名进行形式化表达。举例如下:
(1) <特征词>{性质}{<学科>|<行业>}<地名>
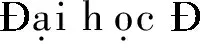
(2) <特征词>[<学科>|<行业>] {地名}[<数量词>|<缩略语>]
(3) <特征词>[<学科>|<行业>] {普通名词}
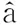
(4) <特征词>{<学科>|<行业>}<人名>
在公司企业类机构方面,我们对在河内证券交易所、胡志明证券交易所上市的各类公司企业名称进行了整理,收集了其中的779家各类公司企业的名称,如表8所示。
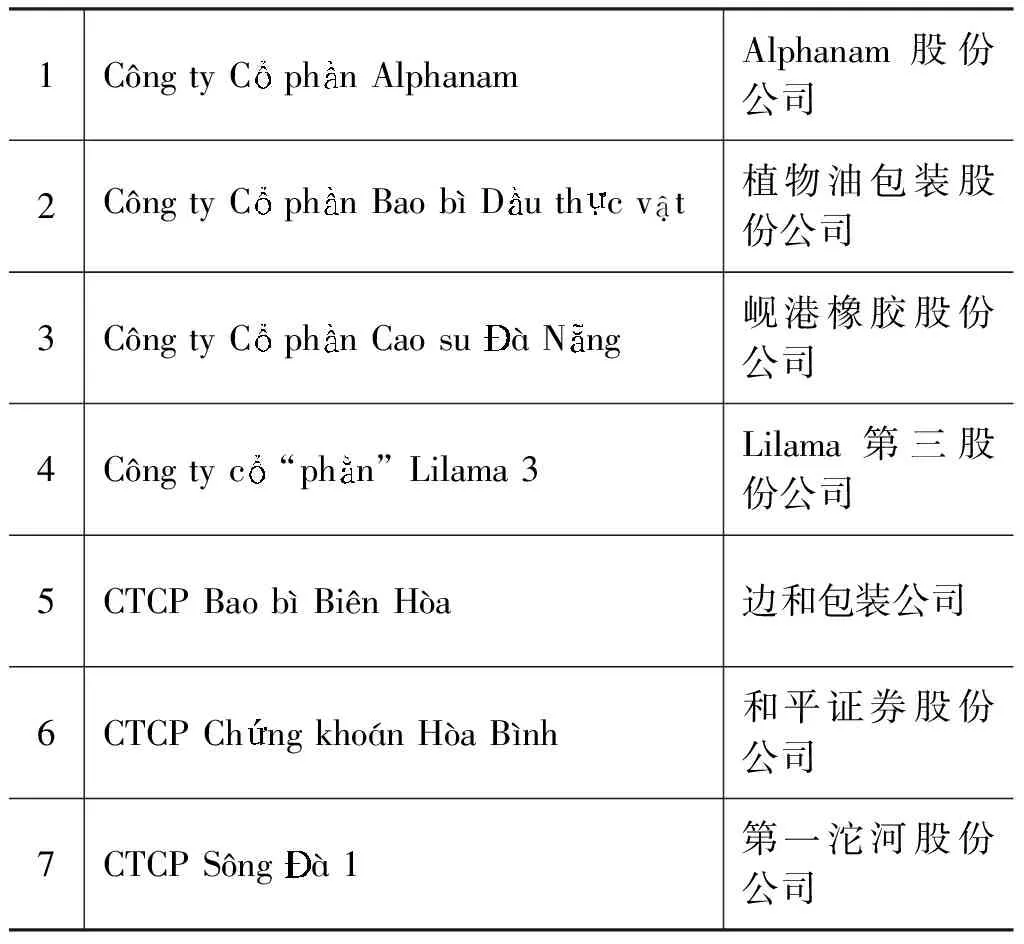
表8 越南公司企业名示例
根据统计结果,我们将越语文本中公司企业名用词分为如下5类: 第一类是公司企业的特征词,如Cng ty,Cng ty Cphn,CTCP,Cng ty CP,Cty CP等等;第二类是公司企业生产经营所涉及的产品类名词,例如,cao su(橡胶)、cp(电缆)、g(木材加工)等等;第三类是公司企业生产经营所涉及的行业类名词,例如,chbin(加工)(运输)等等;第四类是地名用词,这些地名一般为公司企业所在地的地名,例如,(越南)、Biên Hòa(越南地名,边和)等等;第五类是数词,例如,1、2、3等等;第六类是外来词及缩略语,如BECAMEX,LIX,CADOVIMEX等等。
从分析结果来看,当划分为较细的分类时可分别将每类企业名称进行形式化表达。举例如下:
(1) <特征词>[<地名>|<产品>]
(2) <特征词><外来词>{<数词>|<地名>}
(3) <特征词>{行业}<产品>[<地名>|<外来词>|<缩略语>|<数词>]
3 越南人名、地名识别
3.1 越南人名识别
一般来讲,越南人名均由2-4个越南语音节组成,下面,我们以一条语料为例来进行分析:
在越南人名识别方面,特征词通常表现为称谓用语。现代越南社会的称谓系统比较复杂,《越南语人际称谓研究》一书提出,以人际称谓的内涵作为分类标准,可以“将人际称谓分为亲属称谓、社会称谓、姓名称谓和指代称谓4部分”。其中,“亲属称谓是指互相有直接和间接血缘、婚姻、法律等关系的亲戚和亲属的名称”。例如,汉语中: 父亲、儿子、丈夫……;越语中的ng(先生)、b(夫人、女士)、bc(老伯)……等。“社会称谓指作为社会群体的人在互相交际时根据对方的社会角色所使用的称谓”。例如,汉语中: 部长、局长、处长……;越语中的(主任)、thtng(总理)(部长)……等。“姓名称谓是指人类社会中每一个具体成员的正式的代指符号”,即人名,例如,李白、曹操……;越语中的HChí Minh(胡志明)u(潘佩洲)……等。“指代称谓是指人们在交际时对自身、对方和他方所使用的代称”[2]。例如,汉语中: 我、你们……;越语中的ta(咱们)、tao(我)、my(你)……等。
经过对语料的分析,我们发现,出现在语料中的越南人名称谓用语主要涉及上述分类中的亲属、社会称谓,极少量涉及其他分类。鉴于此,我们收集整理语料中出现的称谓用词,构建用于越南人名识别的特征词库,如表9所示。

表9 越南语人名特征词示例
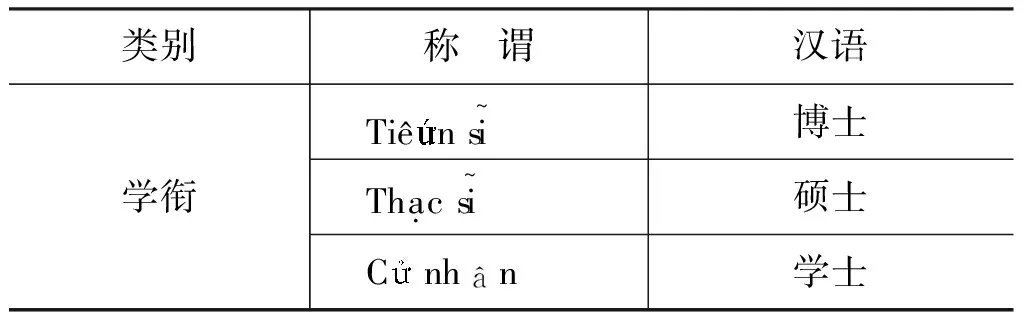
续表
《越南语人际称谓研究》一书对越南人名的构成形式进行了分析,提出了10种常见构成形式和4种罕见构成形式,认为越南人名的常见构成形式如下表10所示。

表10 越南人名常见构成形式[2]
通过对语料进行分析,我们发现,出现在语料中的人名绝大多数为2-4个音节,极少量由4个以上音节组成,如表11所示。

表11 越南语常见人名示例

续表
姓氏是人名中必不可少的组成部分,由此,我们构建越南常用姓氏库,用于对越南人名的识别。越南常用姓氏库按照《越南语人际称谓研究》一书指出的“以较为保守的态度确定的,应该是目前最无争议的越人的姓”[2]进行构建,见表12。

表12 越南常用姓氏库[2]

续表
另外,需要注意的是,不同题材的文本中出现的人名往往具有不同的特点,如小说中的人名通常以“称谓+名”的方式出现,例如,anh Huy(小辉),cNga(小娥),em Hoa(小花)等等,在制定规则时需要加以考虑。
根据以上分析,可采取基于规则的方法对人名进行识别,举例如下:
(1) 采取静态匹配的方式识别越南社会各领域内重要人物。
(2) 特征词+(2至4个)首字母大写音节。
(3) 以姓氏库位基础,姓氏+(2至3个)首字母大写音节。
需要指出的是,这些规则并不是唯一的,在实际的使用过程中,需要不断地分析实际情况,对规则进行修改,以更好地进行识别。
3.2 越南行政地名识别

陆利军在《越南行政地名研究》中对越南行政地名的音节结构形式进行了分析,提出越南行政地名用词可分为单音节、双音节、三音节和四音节四类,绝大多数为双音节和三音节。作者将越南全国有代表性的省份所属市县名进行了统计,如表13所示。

表13 越南部分省所属市县名音节结构表(%)[3-4]
从表13可以看出,双音节和三音节地名占了绝大多数,其中,海防省和安江省全部为双音节地名,而河江省和义安省超过90%以上的地名为双音节。根据分析,我们可以采取基于规则的方法对越南行政地名进行识别,举例如下:
(1) 采取静态匹配识别行政地名。
(2) 特征词+(2至4个)首字母大写音节。
4 实验结果分析
依据以上分析,我们共制定出越南语命名实体识别规则152条,构建了越南语命名实体通用词典,收录越南的常见命名实体,包含越南通用人名库共计20 361条实例、地名库共计11 911条实例、机构名库共计3 180条实例。开发了基于规则的越南语命名实体识别系统,采用Acess 2003作为数据库。数据库中包含ORG(机构名表)、LOC(地名表)和PER(人名表)三个表,每个表中设置ID(编号)、NAME(名称)、INTRO(简介)三个字段。系统的主要功能为调用规则识别待处理文本中的人名、地名和机构名,同时将识别结果存入数据库中。
系统包括以下5个模块:
(1) 文本预处理模块。该模块的功能是将待处理的文本进行格式化处理,删除多余的部分,只保留文本的正文,以更适合其他模块的处理。
(2) 机器词典查询模块。该模块利用通用词典查询待处理文本,识别出常见命名实体。
(3) 模式匹配模块。该模块集成了用以识别越南语命名实体的各种规则,将实现系统的主要功能,识别待处理文本中的命名实体。
(4) 命名实体分类模块。该模块的主要功能为对识别出的越南语命名实体进行自动分类。
(5) 命名实体数据库模块。对识别出的命名实体识别进行分类,并存入3个数据库中。
系统结构图见图1。
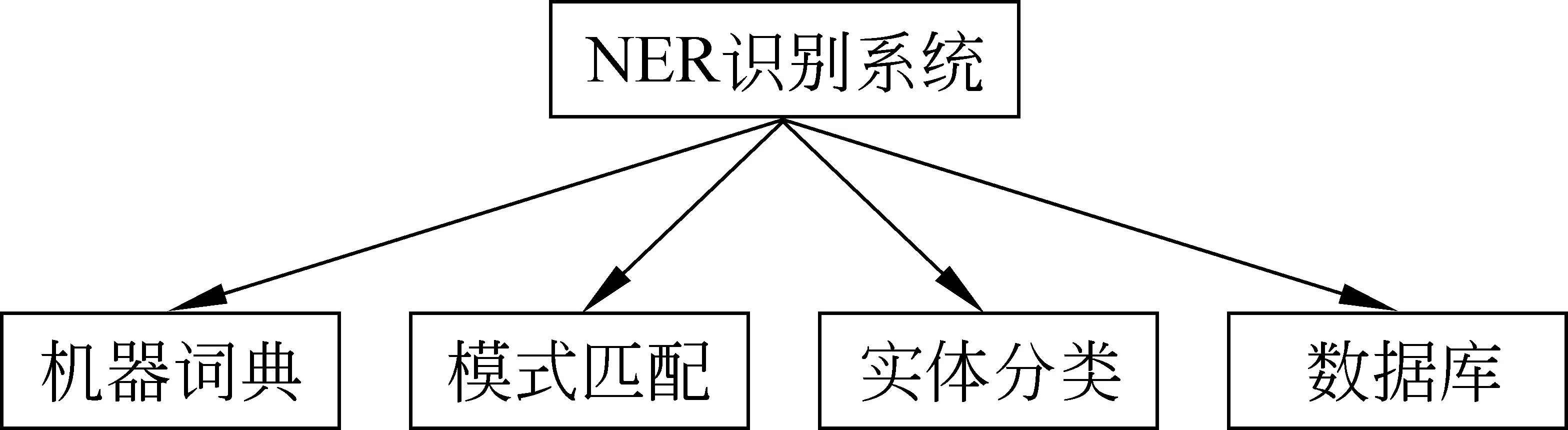
图1 系统结构图
系统流程图见图2。

图2 NER系统流程图
我们用500篇越南政治、经济类语料,对系统进行了封闭测试,以下为测试结果:

性能指标机构名人 名地 名准确率/%90.592.795.8召回率/%74.379.277.5
该方法的最大优势在于原理简单,容易实现,识别准确率高。在实际应用过程中可以随时添加规则,提高系统召回率。此外,该方法大量避免了识别结果中错误实例。
该方法的缺点在于难以手工总结出所有可能的规则,制约了系统召回率的提高。同时,要正确识别出某些嵌套结构的、由较多音节组成的组织机构名还比较困难,需要进一步提升规则的覆盖范围并优化算法中规则的执行顺序。
初次测试中系统规则的执行顺序为: 人名、地名、组织机构名。这导致了对机构名的识别不完全的现象,如对这条语料:
(投资者认为美国联邦储备局会尽早出台各项新的刺激措施)
由于未能获取到越南学者开发的越南语SVM命名实体识别工具,在此并未进行对比实验。但是从系统的测试结果来看,需要在算法中加入适当的统计因素,这将作为我们下一步的工作。未来,我们计划进一步扩大语料分析量,进一步完善规则库并优化规则执行顺序,提高系统召回率。同时考虑结合适当的统计方法[5-6],深入借鉴中、英文及越南语相关领域的研究成果[7-17],在保持该方法优势的同时提高召回率。
[1] Tri Tran Q, Thao Pham T X, Hung Ngo Q, et al. Named Entity Recognition in Vietnamese documents [J]. Progress in Informatics, 2007,4: 5-13.
[2] 孙衍峰. 越南语人际称谓研究[M]. 北京: 外文出版社,2009.
[3] 陆利军: 《越南行政地名研究》,(硕士论文)广西民族大学,2007年,第26页。
[4] 丛国胜. 越南行政地名译名手册[M]. 北京: 军事谊文出版社,2004.
[5] 宗成庆. 统计自然语言处理[M]. 北京: 清华大学出版社,2008.
[6] Daniel Jurafsky, James H. Martin, 冯志伟 孙乐译. 自然语言处理综论[M]. 北京: 电子工业出版社,2005.
[7] 俞鸿魁,张华平,刘群等. 基于层叠隐马尔可夫模型的中文命名实体识别[J]. 通信学报,2006,27(2).
[8] 张晓艳,王挺,陈火旺. 基于混合统计模型的汉语命名实体识别方法[J]. 中文信息学报,2009,(2).
[9] Chen, Hsin-His, Yang Changhua & Ying Lin. Learning Formulation and Transformation Rules for Multilingual Named Entities [C] // Proceedings of ACL-2003.
[10] Chieu, Hai Leong & Hwee Tou Ng. Named Entity Recognition with a Maximum Entropy Approach [C] // Proceedings of CoNLL-2003.
[11] Dat Bat Nguyen, Son Huu Hoang, Son Bao Pham & Thai Phuong Nguyen. Named Entity Recognition for Vietnamese [J]. ACIIDS 2010. Part II, LNAI 5991, pp. 205-214.
[12] Klein, Dan, Joseph Smarr, Huy Nguyen & Christopher D. Manning. Named Entity Recognition with Character-Level Models [C] // Proceedings of CoNLL-2003.
[14] Thao Pham T. X, Tri T. Q., Ai Kawazoe, Dien Dinh & Nigel Collier. Construction of Vietnamese Corpora for Named Entity Recognition [C] // Conference RIAO2007. Pittsburgh PA, U.S.A. May 30-June 1, 2007.
[15] Tri Tran Q., Thao Pham T. X., Hung Ngo Q., Dien DINH, Nigel COLLIER. Named Entity Recognition in Vietnamese documents [J]. Progress in Informatics, No.4, pp.5-13,(2007).
[16] Whitelaw, Casey & Jon Patrick. Named Entity Recognition Using a Character-based Probabilistic Approach [C] // Proceedings of CoNLL-2003.
[17] WU, Youzheng, ZHAO Jun & XU Bo. Chinese Named Entity Recognition Combining a Statistical Model with Human Knowledge [C] // Proceedings of ACL-2003.
