一种基于内存的高效在线数据处理服务框架
2014-02-27林祥辉黄康平许洪波程学旗
林祥辉,张 瑾,黄康平,许 磊,许洪波,程学旗,程 工
(1. 中国科学院计算技术研究所,北京 100190;2. 中国科学院大学,北京 100190;3. 国家计算机网络应急技术处理协调中心,北京 100190)
1 引言
处于信息爆炸的时代,我们的生活被海量数据所包围。从大量的数据源中挖掘出有价值的信息成为了大规模数据分析挖掘系统的重点。大规模数据分析挖掘系统的主要处理流程是收集来自各个数据源的数据进行存储,然后对负责数据分析的应用程序提供数据服务,进行数据分析处理。传统的架构是设立中心数据库来实现数据的存储和服务。各种数据源将数据写入到中心数据库中进行统一存储;应用分析程序从数据库中读取数据,进行分析和处理。但是在海量数据环境下,随着数据来源种类的增加、来源数据量的增长和应用分析程序数目的增加,中心数据库架构的问题日益突显。中心数据库架构的缺点主要体现在三个方面: 1.对数据库写入频率的增加影响了数据库的实时响应性能;2.数据要经过中心数据库存储后才能被应用程序使用,这种串行的工作模式增加了数据处理延时;3.随应用程序个数的增加,对数据库的重复读取次数呈线数增加,严重影响了数据库的IO访问性能。本文针对在海量数据环境下的基于中心数据库的架构所带来的问题,提出了基于内存的在线数据处理服务框架,通过在数据库之前增加了一个基于内存的数据缓存层,改变了数据处理流程,实现了对于数据库的读写分离。基于内存的在线数据处理服务框架的使用提高了整个系统的响应速度,缩短了平均数据处理延时,减少了应用分析程序读取数据库的次数。
本文的组织结构如下: 第2节介绍基于中心数据库架构和数据处理的相关工作以及现有解决方案存在的问题;第3节提出了基于内存的高效在线数据处理服务框架并且介绍实现方法;第4节在实验中对比了基于中心式数据库的处理框架和基于内存的高效在线数据处理服务框架的响应速度和平均数据处理延时;第5节对目前的工作成果进行总结并展望下一步的研究内容。
2 相关工作
2.1 基于中心数据库的处理架构
在数据分析处理应用中,基于中心数据库的分析处理架构被广泛使用。如图1所示,大规模数据分析处理系统通常采用中心数据库的架构,中心数据库主要提供了存储服务和数据服务。来自不同数据源的数据被写入到中心数据库中进行存储,应用分析程序从数据库中读取数据进行分析和处理。但是数据量的增长给基于中心数据库的处理架构带来了挑战。

图1 基于中心数据库的分析处理架构示意图
传统的数据来源包括了新闻、论坛和博客[1-2]三种主要的信息渠道。随着互联网应用的普及,来自搜索引擎、微博平台[3-4]和社交网站的数据成为了新的数据来源。各种产生速率和数据量都不相同的数据源同时对中心数据库提交请求,会增加数据库事务的复杂性,增加数据库锁的处理时间从而降低了数据库的实时响应时间。在基于中心数据的处理架构中数据需要经过中心数据库后才能被应用分析程序所使用,这种串行的处理模式增加了数据平均处理延时。应用程序个数的增加使得读取数据库的次数增加,每一条数据记录都会被所有的分析程序请求,对于数据库的读请求的次数将会随着应用分析程序数目的增长呈线性增长。多次的数据读操作导致数据库读操作的效率下降,影响了数据库的性能。Brad Fitzpatrick在2003年开发了Memcached[5],通过在数据库之前加入缓存,减轻了数据库的读取压力,但是其无法有效降低对数据库的写负载。
随着数据来源、数据量和应用程序的增加,传统的基于中心数据库架构的数据处理分析系统的缺点日益凸显,亟须提出一种新的数据处理架构来使得以上问题得到有效解决。
2.2 消息中间件技术
消息中间件[6-8]是一种由消息传送机制或消息队列模式组成的中间件技术。消息可以通过消息中间件被发送到各个应用程序,通过使用消息中间件可以减少对数据库的读取。在大型的面向消息中间件系统中,发布/订阅[9-11]模式是一个重要数据访问范式。该模型通过一个消息队列和数据访问控制机制将应用程序分为发布者和订阅者,发布者负责将产生的消息放在消息队列中,订阅者可以从中获取自己感兴趣的数据。这种发布者和订阅者的松散耦合可以允许更好的可扩放性和数据访问的控制。
消息中间件已经广泛应用在金融、邮电、交通等行业。面向企业级应用的产品如Apache ActiveMQ[12-13],IBM Websphere MQ[14-16]都是针对这种企业级的应用需求而产生。在企业级应用的需求中消息传递的关注点是要保证消息能够安全到达对方,但是这种解决方案增加了数据处理和传输的延时。
越来越多的公司和研究机构尝试使用分布式消息处理系统来缓解中心数据库架构所带来的问题。LinkIn公司2010年提出的Kafka[17],VMWare公司支持的开源项目RabbitMQ[18-19]等都是基于分布式架构的消息处理系统,能够高效处理海量数据环境下的消息服务。然而这些系统都是基于主键的数据读写,不能支持按照某一个关键字段的查询,无法完全取代关系型数据库的查询功能。
3 基于内存的高效在线数据处理服务框架
3.1 基于内存的高效在线数据处理服务框架
针对基于中心数据库的数据处理分析架构的不足,我们提出了一种基于内存的高效在线数据处理服务框架,其工作原理如图2所示,我们在原有的基于中心数据的数据处理分析处理系统的基础上增加了一个内存在线缓存层。来自不同数据源的数据写入到基于内存的数据缓存中。存在于缓存中的数据分成了两个数据流向,一方面,写入到缓存中的数据可以对应用程序提供在线的数据服务;另外一方面,缓存中的数据会被写入到数据库中进行存储。
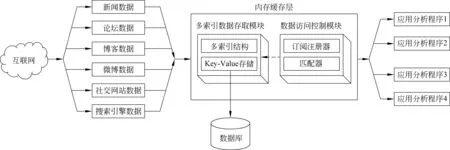
图2 基于内存的高效在线数据处理服务框架
内存在线缓存层包括了多索引的数据存取模块和数据访问控制模块。多索引的数据存取模块通过多索引缓存结构和高效的并发控制实现了对于高并发的读写请求的实时响应。数据访问控制模块对应用分析程序的数据读取进行记录和控制,有效地减少了数据库的读写次数。相比于基于中心数据库的架构,增加了内存在线缓存层之后数据库只需要处理内存在线缓存对于数据库的写请求,而原来对于数据库的读请求则由内存在线缓存提供的在线数据服务进行处理。数据在进入中心数据库之前就可以由基于内存的在线缓存对应用分析程序提供数据服务。内存在线缓存层的加入实现了对于数据库的读写分离,有效地减少了数据库读写负载。
3.2 多索引的高效数据存取模块
基于内存的高效在线数据处理服务框架为了高效地处理对于内存在线缓存的读写请求,我们设计了一种多索引的高效数据存取模块。如图3所示,多索引的高效数据存取模块采用Key-Value[20]数据存储结构,同时借鉴了关系型数据库的设计思路,根据业务需求,在多个字段建立索引,以提高插入和查询的效率。多索引数据存取模块在平均情况下以O(1)的时间进行去重操作,在最坏情况下以O(logn)的时间进行插入和查询操作。
首先,我们将来自不同数据源的数据按照Key-Value的方式进行存储,Key由一个全局唯一的64位的整型数字表示,Value包括了数据的一些原始属性,包括发布时间、采集时间、原文内容等字段。在内存在线缓存中,我们规定所有数据的Key值是全局唯一的,如果有重复Key值要进行写操作时,内存在线缓存应该阻止重复数据写入内存缓存中。不同的应用分析程序会按照时间段在内存在线缓存中进行查询,例如一个应用分析程序会请求从 “19:00” 到“20:00”之间的数据。内存缓存需要高效地处理应用分析程序的读请求为其提供数据服务。
其次,为了满足高效的读写需求,我们针对不同的读写需求通过建立不同类型的索引结构来提高内存缓存的读写性能。针对数据Key值唯一性的要求, 我们对每一条记录的Key值建立散列索引来判断写入的数据是否已经存在。对Key值建立了散列索引后,只需要花费O(1)的时间代价就可以判断待写入的数据是否重复。对于按照字段进行区间查询的需求,我们对查询字段建立B+树索引。应用分析程序可以在内存在线缓存中以O(logn)的时间代价按字段进行区间查询。

图3 基于多索引的数据存取结构
3.3 基于发布/订阅模式的数据访问控制
数据访问控制模块的任务是防止同一条数据被同一程序反复读取。基于内存的高效在线数据处理服务框架对应用分析程序提供了数据服务,将原来对于数据库的多次读数据请求转移到了内存在线缓存层中。虽然基于内存和网络的数据服务的读写开销要小于数据库的读写,但是对于同一条数据记录的多次读取仍会造成网络负担。所以,我们在数据访问控制模块中采用了发布/订阅者模型来进行数据访问控制,让一条数据记录以最少的次数被分析应用程序所使用。在我们的应用中各种不同的数据源是发布者,往在线缓存中发布数据;应用分析程序是订阅者,对自己需要的数据进行读取。通过发布/订阅模型控制一个应用分析程序只能对同一条数据读取一次, 这样就避免了数据重复传输。访问控制模块由订阅注册器和匹配器组成,下面将介绍订阅注册器和匹配器的工作流程。
首先,应用分析程序需要在在线缓存的注册模块进行注册申请,然后可以根据注册所得到的访问标识来对数据进行访问。图4中Register算法描述了分析程序在获取数据之前需要进行的注册流程。我们设定注册订阅的程序的最大数目为32,用一个32位整数的每个比特位来标识一个具体的分析程序。对于每一个申请注册订阅的分析程序,根据其名字在一个保存着应用程序名字和数据获取标识的映射结构。当一个分析程序开始注册时,将在这个映射结构中进行查询,如果分析已经注册成功,那么就将其之前注册的数据获取标识返回给分析程序;如果一个分析程序是第一次进行注册,那么就把当前最大位的左一位标示的数字作为这个新注册的分析程序的数据获取标识;如果目前已注册的用户达到了最大限度,那么算法将返回-1,表示分析程序注册失败。

图4 Register算法
然后,在应用分析程序注册成功后通过匹配器对所需要的数据进行读取。分析程序使用自己的appName来进行数据获取请求,图5-a中描述了应用分析程序取数据库的逻辑。首先根据分析程序的名字在名字—标识映射结构中取得appName所对应的数据获取标识,然后针对目标数据计算其数据访问标志位,如果此数据未被当前分析程序所访问过,则将这条数据返回给当前的分析程序;如果此数据已经被当前分析程序使用过,那么算法则不会返回这条数据。
一个具体的数据访问流程的例子如图5-b所示。已知一条数据当前的访问标识位为0000000000001000(十进制标示为8)。首先分析程序appName4,试图请求获取这条数据,AccessData算法从之前的映射结构中查询得知appName4是已经成功注册的分析程序,其数据访问标识为8,然后将8和此数据的访问控制位进行按位与(&)运算,在运算结果中检查appName4的数据访问标识所代表的位置(此处为第4位)的值,如果该值为1,说明appName4程序在之前已经使用过这条数据, 因此appName4就不能取得这条数据。然后分析程序appName5请求这条数据,与之前的流程一样,使用appName5的访问控制标识对数据的访问控制位进行按位与运算之后,检查appName5所对应的位置的值为0,说明appName5在之前尚未访问过这条数据,所以算法会将此数据返回给appName5,同时会将这条数据的记录访问控制位置为1,以防止appName5在下一次重复访问到这条记录。

图5⁃a AccessData算法图5⁃b AccessData流程示意图
4 实验
为了验证我们所提出的基于内存的高效在线数据处理服务框架,通过内存在线缓存提供的在线数据服务,可以缩短数据平均处理延时;通过内存在线缓存对外提供读写服务,可以减少数据库的读写,同时缩短数据库的平均响应时间。我们分别采用基于中心数据库(Oracle数据库)的架构和基于内存的在线数据处理服务框架进行系统性能对比。实验部分分别对两种架构下的平均处理延时进行统计和分析,并分析在两种架构下的数据库的平均响应时间的变化情况。
4.1 数据平均处理延时对比实验
实验在数据规模相当(1亿条数据)的两套线上系统进行,两个系统分别采用了基于中心数据库的架构和基于内存在线数据处理服务框架。我们将系统从数据源获取到一条数据的时间到该数据被应用分析程序处理完成的时间定义为一条数据的处理延时。图6中我们分别统计了13批增量数据的平均处理延时。

图6 数据处理延时对比图
从图6中可以看出,基于中心数据库架构的数据延时曲线整体高于基于内存的在线数据处理服务框架的数据处理延时曲线,这说明数据通过在线缓存进行转发能够有效的提高数据处理的时效性。从表1中可以看出,在基于内存的在线数据处理服务框架下,数据的平均处理延时为32秒,而基于中心数据库架构的数据平均处理延时为则是82秒,在线缓存框架使平均数据处理时间缩短了61%。

表1 数据处理延时对比表
值得注意的是,两种架构中数据的处理延时曲线都呈现出了一种周期性的规律,但是由于内存在线缓存处理和转发数据的速率要明显快于数据库,所以可以看出基于内存的在线数据处理服务框架的曲线的周期要明显小于由基于中心数据库的数据处理延时曲线。一个有意思的现象是图中第10批数据通过在线缓存转发的处理延时为42s,而通过数据库分发的处理延时仅仅是16s。出现这种情况的原因是数据到达的时间周期正好与分析程序请求数据库的周期开始处相吻合,数据刚刚写入到数据库中,很快就被分析程序所请求。但是从整体趋势上分析,数据通过数据库转发的平均处理延时明显大于通过内存在线缓存进行转发的平均处理延时。本文所提出的基于内存的在线数据处理服务框架有效地提高数据分析处理的时效性。
4.2 数据库平均事务响应时间对比实验
本实验中,我们分别对两个系统的Oracle数据库生成自动工作负载报告[18](Automatic Workload Repository,以下简称AWR报告),通过AWR报告计算两种架构下数据库的平均事务响应时间。
AWR是从Oracle10g开始提出的一种记录数据库工作负载的报告。AWR永久地保存系统的性能诊断信息给DBA们提供了更加有效的系统监测工具。在工业界中AWR报告被广泛地应用在数据库性能分析上。
Oracle在10g版本明确引入time model[19],选取了事务平均响应时间来衡量数据库对事务处理的响应速度。基于事务的平均响应时间,可以看作性能优化效果的一个交付和对比。事务平均响应时间的计算方法如式(1)所示
avg trans respone time(s)=

(1)
表2是两个对比实验数据库在一个小时内的AWR报告的片段。从中可以看出在基于中心数据库架构的环境下,数据库的文件顺序读次数为10 671次,数据库平均事务响应时间为7.09s。在使用了基于在线缓存的架构之后,由于应用程序不再从数据库中读取数据,所以数据库文件顺序读取次数下降为385同时平均事务响应时间下降为2.88s。在使用了在线缓存的结构之后,数据库的负载大大减小, 数据库的响应时间也得到了显著的缩短。本实验证明了本文提出的基于内存的在线数据处理服务框架,大大减少了数据库的读写负担,有效地提高了数据库的实时响应速度。

表2 数据库事务平均响应时间对比
5 结论
本文针对在海量数据环境下传统的基于中心数据库的数据分析处理架构所带来的数据库响应速度慢、数据分析处理延时长、数据库读请求次数多的问题,提出了基于在线缓存的数据分析处理框架。实验结果表明,基于在线缓存的数据处理服务框架有效提高了数据库的响应速度,缩短数据处理周期,减少了对数据库读请求的次数。然而,随着数据量的进一步增长,基于单机内存的在线缓存将无法容纳所有的数据。我们的下一步工作将着眼于采用分布式的架构来解决这一问题。
[1] 李盛韬,余智华,程学旗,白硕. Web信息采集研究进展[J]. 计算机科学,2003(02): 151-171.
[2] 郭岩,刘春阳,余智华,等. 网络舆情信息源影响力的评估研究[J]. 中文信息学报, 2011,25(3):64-71.
[3] 曹鹏,李静远,满彤,等.Twitter中近似重复消息的判定方法研究[J].中文信息学报,2011,25(1):20-27.
[4] 郭浩,陆余良.基于信息传播的微博用户影响力度量[C]//CCIR2011.
[5] Fitzpatrick B. Distributed caching with memcached[J]. Journal Linux, 2004,124:7559.
[6] Krakowiak, Sacha. “What’s middleware?”. ObjectWeb.org. Retrieved 2005-05-06.
[7] 徐晶,许炜. 消息中间件综述[J]. 计算机工程, 2005, 33(16):73-76.
[8] 李文逍,杨小虎. 基于分布式缓存的消息中间件存储模型[J]. 计算机工程,2010,36(13):93-95.
[9] Birman K, Joseph T. Exploiting virtual synchrony in distributed systems[C]//Proceeding of SOSP ’87 the eleventh ACM Symposium on Operating systems principles, 1987: 123-138.
[10] Hasan, Souleiman. Approximate Semantic Matching of Heterogeneous Events [C]//Proceeding of the 6th ACM International Conference on Distributed Event-Based Systems 2012, 252-263.
[11] Eugster P T, Felber P A, Guerraoui R. The Many Faces of Publish/Subscribe Proceeding of ACM Computing Surveys, 2003,35(2): 114.
[12] The Apache Software Foundation ActiveMQ[DB/OL] http://activemq.apache.org/, 2012.
[13] Snyder, Bruce, Bosanac, Dejan, et al. ActiveMQ in Action (1st ed.)[M], Manning Publications, 2010: 375.
[14] Iyengar A, Jessani V, Chilanti M. WebSphere Business Integration Primer: Process Server, BPEL, SCA, and SOA 1st[M], IBM Press , 2007.
[15] Kloppmann M. IBM Deutschland Entwicklung GmbH Business process choreography in WebSphere: Combining the power of BPEL and J2EE[J], IBM Systems Journal, 2004, 43(2): 270-296.
[16] B.Mann. Worldwide Product Manager Providing a Backbone for Connectivity with SOA Messaging[M], 2009.
[17] Kreps J, Narkhede N, Rao J. Kafka: a Distributed Messaging System for Log Processing[M], 2011.
[18] Videla A, Williams J J W. RabbitMQ in Action:Distributed messaging for everyone[M]. 2012.
[19] home page http://www.rabbitmq.com/[DB/OL], 2012.
[20] Seeger M. Key-Value Stores: a practical overview Computer Science and Media[A], Ultra-Large-Sites September 2009.
[21] Automatic Workload Repository (AWR) in Oracle Database[DB/OL], http://www.oracle-base.com/articles/10g/automatic-workload-repository-10g.php.
[22] Oracle Database Performance Method page[M/CD].
[23] http://docs.oracle.com/cd/B19306_01/server.102/b28051/tdppt_method.htm[DB/OL].
