基于特征提取的垃圾邮件检测
2014-02-26卜华龙郑尚志
卜华龙 夏 静 郑尚志
(巢湖学院计算机与信息工程学院,安徽 巢湖 238000)
1 引言
随着互联网技术的深入普及,电子邮件(EMail)凭借其方便等独特特点成为常用的联系方式。EMail在带给人们带来方便的同时,也伴随着大量垃圾邮件的入侵。近年来,很多单位和个体在未经邮件用户同意的前提下,利用群发软件等工具大量发送广告信息,既造成用户的不满,也浪费了网络资源,其中的淫秽和信息还会严重损害青少年的健康成长[1,2]。因此,垃圾邮件检测已经成为当前网络研究重要方向之一。
垃圾邮件过滤本质上可以看作文本分类问题,文本分类通过文本的内容,根据分类算法将文本归至某种类别,通过采样网络文本数据可以发现样本数据特征间存在大量的相关性,表现为既影响检测模型的响应时间,也干扰分类器的正确分类[3]。例如文本分类中其特征空间经常高达几万维且很多特征维值为0,这种高维性和稀疏性的特性会严重影响分类效果,从而向传统分类算法提出严重挑战[4]。
维数约简算法通过将数据的维数降低到一个合理范畴并尽可能多的保留原始的信息达到提高分类效率目的,特征提取是维数约简的典型做法之一,其核心是通过采用某种变换将原始高维数据映射至低维空间[5]。偏最小二乘法(Partial least square,PLS)作为一种常见的特征抽取方法能够保留所有的解释变量或样本点,在吸收标签变量的前提下,能定性解释预测且对解释变量个数多且样本量少时保持很高的效率[6]。
基于以上原因,本文提出先PLS特征抽取并利用遗传算法寻找其降维空间最优子集,再通过SVM算法的PLS-SVM垃圾邮件检测算法。
2 背景及相关工作
2.1 偏最小二乘算法PLS
PLS作为一种多线性回归工具在生物、化学与信号处理等领域都得到了大量应用[7]。PLS主要通过对与响应变量间有高度协方差的预测变量进行非线性转换,以获得隐藏变量,是一种监督学习方法。
PLS通过最大化原始数据X和目标变量y的协方差构造成分变量:
wk其主要约束条件:wTSXw=0,1≤ i< j, 因此 PLS 核心在于计算最优权重向量 wi=(i=1,…,K)。
具体来说,为求得变换后的成分[t1,t2,…tk],PLS将原始数据X和y(分类标签)分解,从而得到X与y的双线性表示:

其中w为PLS成分向量t=X w的权重,q为标量,E、F为残差。PLS时间复杂度为O(npK),为n、p的线性函数。
2.2 支持向量机SVM
支持向量机(SVM)于上世纪90年代由Vapnik及其合作者提出,已经广泛研究和应用于数据挖掘、模式识别、生物信息处理等领域[8]。
为得到泛化边境,我们需要最小化SVM的以下目标函数:

其中 yi=(< w·xi> +b)≥1-ξi,i=1, …,e;松弛变量ξi当问题不可行时被引入,常数C>0是一个惩罚函数,C越大表示更大的误差。
接下来,通过建立Lagrangian并使用Karush-Kuhn-Tucker(KTT)互补性条件,可以将以上问题转化为求最优化值。利用KKT条件,我们定义那些使约束非零的Lagrangian算子ais相应的点为支持向量(sv),由此我们可以将分类超平面表示成a和b:
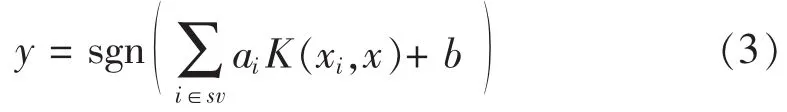
这里 K(xi,x),作为一个核函数以处理非线性问题,高斯核函数为常用核函数。
3 PLS-SVM算法框架
垃圾邮件通过检测模型将正常邮件和垃圾邮件分开,因此可以看作一个二分文本检测问题。垃圾邮件检测的一般模式为:
1)将正常和垃圾邮件数据集X预处理,提取分类特征[t1,t2,…,tK],达到维数约简的目的;
2)将待测邮件(未标记)投影到[t1,t2,…,tK],得到新的数据表示X′,再利用分类器对X′进行检测。
由此可见,垃圾邮件检测主要依赖于预处理的效果和学习器的效果。本文采用PLS算法,如 2.1 所述,PLS 需要确定[t1,t2,…,tK]的特征个数K,若K等于X阶时,其规模等同于原始数据,因此能较好保持数据的内部信息,但也面临以下问题:
1)冗余特征和弱相关特征仍然存在;
2)当K等于X阶时并没有削减维数规模。
因此,我们需要选择合适的PLS投影特征子集规模,传统做法有用户根据经验决定、交叉验证或计算回归拟合程度[9]等,本文考虑到遗传算法的全局寻优性,采用遗传算法(GA)[10]解决特征子集选取问题。图1给出PLS-SVM算法的主要流程。
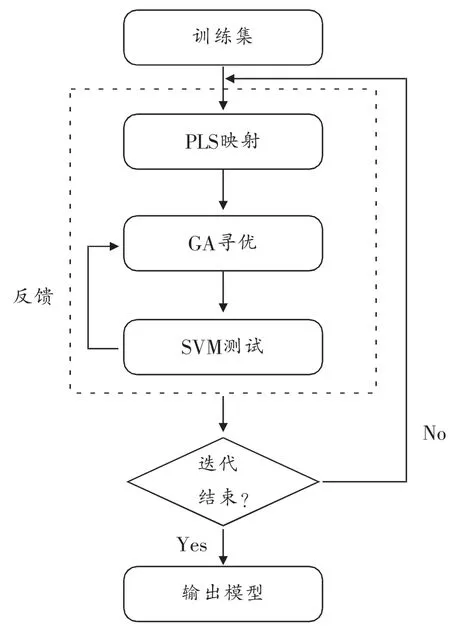
图1 PLSSVM算法流程图
首先利用PLS将原始特征空间变化至新特征空间,再利用GA确定此特征空间的主要成分,并通过分类器SVM以提供反馈 (wrapper类方法),即主要利用分类器的分类表现验证选择特征子集的有效性以及挑选合适的预测模型。
4 实验方案及结果分析
4.1 实验方案
本文将PLS-SVM算法应用于垃圾邮件检测,数据集来自于中文邮件语料集(Spamand ham collected during July 2005),该数据集有9042个标记为正常邮件的样本和20308个标记为垃圾邮件的样本,样本中已经去除邮件头等信息,只保留邮件主题和内容。我们首先合并标记为垃圾邮件和正常邮件的数据集并打乱结构得到数据集C,再将C分成训练集C1和验证集C2,为避免样本不均匀分布以及验证小样本对算法的影响,将数据集C1和C2再拆分成 3个子集 C11、C12、C13和 C21、C22、C23分开讨论。
为评价检测效果,我们采用常用的性能评价方法:召回率R与准确率P[11]。设垃圾邮件个数为N,垃圾邮件检测分类如表1所示。
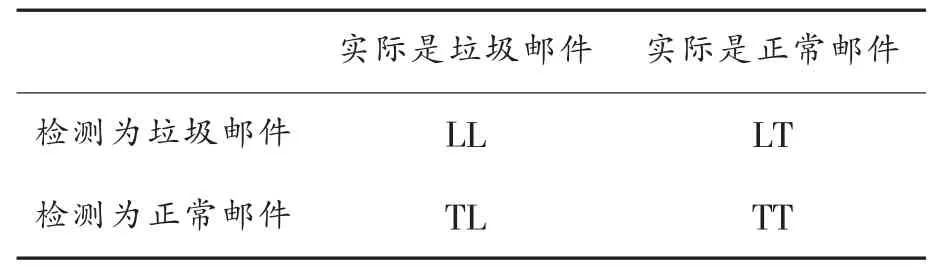
表1 系统检测分类表
在实验设计环节,我们将训练集C1的9/10用作模型训练,1/10用于测试且迭代10次以选取最佳检测模型,并给出在验证集C2上的效果。考虑到本文重点,实验中除特别标注部分,其余参数都采用默认参数,实验平台采用MATLAB。
为了对比研究,我们设计了1)不使用特征抽取算法的SVM法;2)使用PLS降维的PLSSVM方法。
4.2 实验结果及分析
2种垃圾邮件检测算法的检测准确率和召回率如表2所示,其中平均分类准确率用precision表示,平均召回率用recall表示,表2所列为基于C1i训练优化模型在验证集C2i上的平均检测结果。
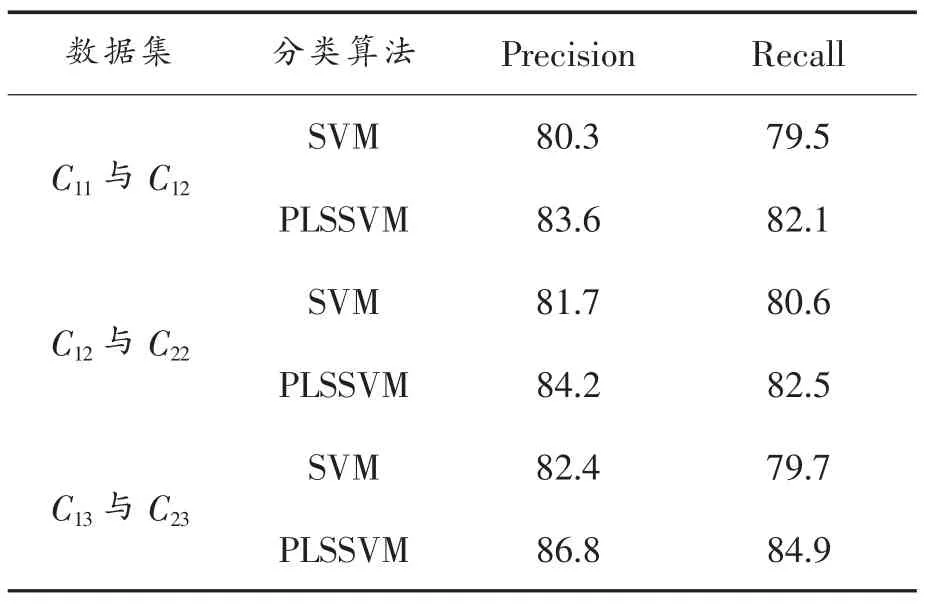
表2 检测结果
通过对比2种算法及其在3个数据集上的研究发现:
使用PLS特征提取后的检测准确率普遍高于没有使用PLS的结果。如前所述,由于提取特征前干扰信息多,模型的稳定性和预测能力不理想, 单纯的SVM无法在多个数据集上取得满意检测效果,模型不稳定。经过PLS-SVM降维和检测后,模型的稳定性包括预测能力得到较大幅度提高。实验表明特征抽取起到了消除冗余和无关特征的作用,且降维后特征信息更有利于垃圾邮件检测,验证了本文算法对检测效果的作用。
5 结束语
针对互联网时代用户面临查找、过滤和管理海量信息的困难,本文提出线性判别分析和偏最小二乘相结合的网页自动分类方法,充分利用这两种算法的互补特点,保证了较高的识别准确率,提高算法的稳定性。两个标准数据集的实验结果表明,本文方法无论从分类准确率还是稳定性都具有良好的表现。
[1] 曹麒麟 ,张千里.垃圾邮件与反垃圾邮件技术[M].北京:人民邮电出版社,2003.
[2] 陈凯.反垃圾邮件技术的研究与实践[D].北京:北京邮电大学,2006.
[3] 苏金树,张博锋,徐昕.基于机器学习的文本分类技术研究进展[J].软件学报,2006,(9):1848-1859.
[4] 宋枫溪.统计模式识别中的维数削减与低损降维[J].计算机学报,2005,(28):1915-1922.
[5] Guyon, S.Gunn, Feature Extraction[M].UK, Springer Verlag,2006.
[6] A.L.Boulesteix, K.Strimmer, Partial Least Squares:A Versatile Tool for the Analysis of High-Dimensional Genomic Data[J].Briefings in Bioinformatics,2006,(7):32-44.
[7] I.S.Helland, On the structure of partial least squares regression, Communications in statistics[J].Simulation and computation,1988,(17):581-607.
[8] 周志华.机器学习及其应用[M].北京:清华大学出版社,2006:170-188.
[9] G.Z.Li,H.L.Bu,M.Q.Yang,etc.,Selecting subsets of newly extracted features from PCA and PLS in microarray data analysis[J].BMC Genomics,2008,(9):179-183.
[10] I.Guyon,A.Elisseef,An introduction to variable and feature selection[J].Journal of Machine Learning Research,2003,3:1157-1182.
[11] 袁鼎荣,钟宁,张师超.文本信息处理研究述评[J].计算机科学,2011,(12):9-13.
