基于Hive的数据管理图形化界面的设计与实现
2014-02-08左谱军朱晓民
左谱军,朱晓民
(1 北京邮电大学网络与交换技术国家重点实验室,北京 100876;2 东信北邮信息技术有限公司,北京 100191)
基于Hive的数据管理图形化界面的设计与实现
左谱军1,2,朱晓民1,2
(1 北京邮电大学网络与交换技术国家重点实验室,北京 100876;2 东信北邮信息技术有限公司,北京 100191)
本文提出了一种对Hive进行图形化界面管理的设计方案,实现了用户对Hive数据仓库的数据表管理,数据查看检索,以及用户对数据库的权限管理等功能,使用户可以友好的访问属于自己权限Hive数据内容。
Hive;图形化界面;数据管理
为了处理海量的原始数据,很多大型数据仓库开发者和程序员在过去5年内实现了数以百计的、专用计算方法。这些计算方法可实现类似网络爬虫程序的文档抓取,Web请求日志处理等操作;也可处理各种类型的衍生数据。上述大多数数据处理运算由于输入的数据量巨大,想在可接受的时间内完成运算,现行条件下的单台机器无法满足要求,需要采取分布处理技术,亦即将这些计算分布在成百上千的主机上完成。
针对大规模和超大规模数据的分布式计算处理技术成为倍受关注的工程研究课题。工程研发界普遍关注在互联网领域得以广泛应用的Hadoop技术,Hadoop是一个分布式系统基础架构,由Apache基金会开发,其主要子项目包含HDFS和MapReduce,HDFS是Hadoop的分布式文件系统,而MapReduce是Hadoop分布式计算框架[1]。
分布式数据存储仓库Hive是基于Hadoop的一种数据仓库基础框架。因此在功能上有些不同于传统意义上的Orical和Mysql数据库,不支持随机插入记录和删除记录的操作。它能提供应用工具来支持数据提取,转化和加载(ETL),可用来查询,存储和分析存储在Hadoop中的大规模数据集。使用简单的类SQL语言,称为HQL(Hive Query Language,Hive查询语言)。
1 Hive技术构架
Hadoop两个基础构架HDFS(Hadoop Distributed File System,Hadoop分布式文件系统)和MapReduce同样是Hive架构的根基。如图1所示,Hive架构包括如下组件: CLI(Command Line Interface,命令行接口)、JDBC/ODBC、Thrift Server、Hive Web Interface、Metastore和Driver(Complier、Optimizer和Executor),这些组件按照功能来分可以分为两大类:服务端组件和客户端组件。
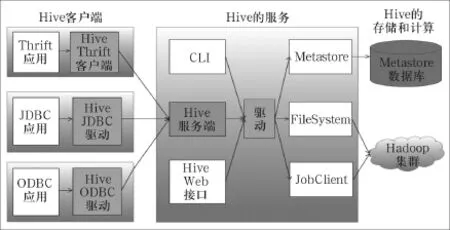
图1[2][3]Hive系统框架图
1.1 服务端组件
(1)Driver组件:该组件包括Complier、Optimizer和Executor,它的作用是将HQL(类SQL)语句进行解析、编译优化,生成执行计划,然后调用底层的MapReduce计算框架。
(2)Metastore组件:元数据服务组件,所谓元数据,指的是Hive数据库或者数据表的属性信息,包括表结构,表名以及字段名等等信息。Metastore这个组件用来管理Hive的元数据,Hive的元数据信息持久化在关系数据库里,目前最新版本Hive-0.12.0支持的关系数据库有Derby、Mysql。元数据对于Hive十分重要,因此Hive支持把Metastore服务独立出来,安装到远程的服务器集群里,这样一来可以解耦Hive服务和Metastore服务,保证Hive运行的健壮性。
为了能够存储和管理Hive的元数据,从结构上说,Metastore组件包括两个部分:Metastore服务和后台数据的存储。后台数据存储的介质就是关系数据库,用例如Hive默认的嵌入式磁盘数据库Derby,还有Mysql数据库。Metastore服务是建立在后台数据存储介质之上,并且可以和Hive服务进行交互的服务组件,默认情况下,Metastore服务和Hive服务安装在一起,运行在同一个进程当中。也可以把Metastore服务从Hive服务里剥离出来,Metastore独立安装在一个集群里,Hive远程调用Metastore服务,这样可以把元数据这一层放到防火墙之后,客户端访问Hive服务,就可以连接到元数据这一层,从而提供了更好的管理性和安全保障。使用远程的Metastore服务,可以让Metastore服务和Hive服务运行在不同的进程里,这样也保证了Hive的稳定性,提升了Hive服务的效率。(3)Thrift服务:Thrift是Facebook开发的一个软件框架,它用来进行可扩展且跨语言的服务的开发,Hive集成了该服务,能让不同的编程语言调用Hive的接口。
1.2 客户端组件
(1)CLI:Command Line Interface,命令行接口,用于操作Hive数据库和数据表。
(2)Thrift客户端:上面的架构图里没有写上Thrift客户端,但是Hive架构的许多客户端接口是建立在Thrift客户端之上,包括JDBC和ODBC接口。
(3)WEBGUI:Hive客户端提供了一种通过网页的方式访问Hive所提供的服务。这个接口对应Hive的hwi组件(Hive web interface),使用前要启动hwi服务。
2 平台设计的实现
本文致力于开发一个基于Hive的数据管理图形化界面,底层以Hadoop和Hive平台为依托,针对轻技术人员,即普通的业务人员,使其可通过该平台实现数据管理。系统架构可以分成3个层次,如图2所示。
2.1 客户端
客户端实现的是对于数据表的基本操作,包含数据表的操作、数据库的操作以及数据展示,将客户端操作转化为相应的指令,提交到服务端执行。

图2 基于Hive操作的图形化平台系统架构
(1) 数据表的操作,Hive表是以数据和Hive表元数据分离的形式实现的,当创建一个数据表的时候,需要创建这两部分信息,Hive表的元数据存储在Mysql数据库,而数据存储在Hadoop集群上,以分布式文件的形式存在,由于Hadoop不支持对文件数据的随机修改,因此对于Hive表数据的添加只能以整个文件的形式上传,不支持对Hive表数据单条数据的插入,数据的删除同样不支持对单条数据记录的删除。Hive表的原数据包含的是数据表的属性,数据表是否是外部表,所谓外部表,就是修改的内容仅限于元数据,存储的位置,列名,列的类型,数据间隔等等。数据表的操作,包含清空,创建,删除,更改。
(2) 数据的展示,数据展示所需要的是Hadoop集群上的数据,如果文件中数据需要正确展示,那么它数据的格式必须得匹配数据表的元数据,否则数据无法正确显示,例如,当文件中数据间隔以“ ”为间隔,而元数据设置数据表的格式以“u0001”为间隔,在客户端就不能显示正确的数据。数据显示一次性显示100条数据,随着滚动条下拉,每次增量显示200条数据。数据表同时展示整个数据表内容所占空间的大小。
(3) 数据库操作,对于不同的用户,拥有对不同数据库的操作权限,默认一个用户只能拥有3个数据库,但是操作的数据库格式不限,用户可以将一个数据库的操作权限赋予其他的用户,被赋予操作权限的用户只能对数据库的数据表进行操作,不能删除数据库,只有数据库的拥有者才能删除数据库。数据库里面包含数据表,数据库之间数据表可以相互移动。
2.2 客户端和服务端的通信
客户端和服务端通信是通过Thrift工具实现,Thrift是一个服务端和客户端的架构体系,Thrift具有自己内部定义的传输协议规范(TProtocol)和传输数据标准(TTransports),通过IDL脚本对传输数据的数据结构(struct) 和传输数据的业务逻辑(service)根据不同的运行环境快速的构建相应的代码,并且通过自己内部的序列化机制对传输的数据进行简化和压缩提高并发、大型系统中数据交互的成本,图3描绘了Thrift的整体架构,分为6个部分:
(1)业务逻辑实现(Your Code),业务逻辑的实现需要自己编写特定的thrift-code。
(2)客户端和服务端对应的Service,对于每一个客户端为建立一个连接。
(3)执行读写操作的计算结果,由服务端执行,将结果返回给客户端。

图3 Thrift的整体架构
(4)TProtocol,定义数据格式协议,包含二进制编码协议TBinaryProtocol 和高效率的、密集的二进制编码格式进行数据传输TCompactProtocol 。
(5)TTransports,定义数据传输方式,包含阻塞式I/O进行传输TSocket和非阻塞方式TFramed Transport,底层只有一个服务,所以传输方式选择的事阻塞式I/O。
(6)底层I/O通信,底层通信协议。
2.3 服务端
服务端处于整个系统的中间层,往上负责和客户端通信,接收客户端的请求,并且将执行结构返回给客户端;往下负责和底层服务沟通,将执行指令提交到底层服务执行,另外管理一些缓存的内容,主要完成的功能是权限管理,数据表管理,数据库管理以及连接池管理。
(1) 权限管理,Hive本身不存在对数据表和数据库的限制,为了限制不同用户对Hive数据库的使用,服务端建立了一套权限管理体系,用于管理不同用户的数据库和数据表,不同用户对数据库操作拥有不同的权限,这一部分信息存储在Mysql数据库当中。
(2) 数据表管理,数据表的元数据信息可以通过底层MetaStoreServer获得,权限信息则需要通过权限管理体系获取,数据表的信息经常要被访问,为了能够及时的反馈客户端请求,服务端存储了一份数据表的缓存信息,以减轻对底层Hive的操作次数。
(3) 数据库管理,不同的用户对Hive数据库拥有两种权限,一种是数据库的拥有者,另外一种是数据库的可操作者,数据库拥有者能够删除自己创建的数据库,而数据库的可操作者权限,则需要数据库拥有者赋予。
(4) 连接池管理,连接池为Hive操作提供连接,用于Java客户端访问元数据库,在服务器端启动Meta StoreServer,客户端利用连接通过MetaStoreServer访问元数据库,为了保证连接有效性,对已经建立的连
接间隔一定的时间做信息发送操作,若连接中断,则重启连接服务,以保证服务的可靠性。
2.4 底层服务配置
底层服务由Hadoop为支撑,需要配置MetaStore服务和Hive服务,MetaStore服务底层是以Mysql为支撑,存储Hive的元数据。Hive服务提供数据信息,底层依托Hdfs。
3 总结
Facebook主要依靠可以使业务开发者同时使用的Hadoop、标准商业智能工具的Hive以及由Facebook自主开发的闭源终端用户工具HiPal等方式拓展业务。为了使业务人员更加方便的使用Hive,基于Hive的数据管理图形化界面的实现解决了Hive数据操作图形化的问题,能够直接与Hive对话,并且具有数据查询,数据删除,数据库管理功能。
[1] A. Gates, O. Natkovich ect. Building a high-level dataflow system on top of Map-Reduce: The pig experience[M]. In Proc. of VLDB, 2009:1414-1425.
[2] Tom White著,周傲英等译. Hadoop权威指南(中文版)第二版[M].北京:清华大学出版社,2011.
[3] Tom White. Hadoop: The Definitive Guide[M]. Second Edtion O’Reilly Media, 2011.
Graphical data management design and implementation based on hive
ZUO Pu-jun1,2, ZHU Xiao-min1,2
(1 State Key Laboratory of Networking and Switching Technology, Beijing University of Posts and Telecommunications, Beijing 100876, China; 2 EBUPT Information Technology Co., Ltd., Beijing 100191, China)
This paper proposes a design of graphical interface that provides the user table management of Hive data warehouse, data view retrieval and the database user priority management functions, so that the user can access their own Hive data friendly.
Hive; graphic UI; data management
TN915
A
1008-5599(2014)01-0089-04
2013-12-05
国家973计划项目(No. 2013CB329102);国家自然科学基金资助项目(No. 61372120,61271019, 61101119, 61121001, 61072057, 60902051);长江学者和创新团队发展计划资助(No. IRT1049);北京市支持中央高校共建项目——青年英才计划。
