3D图形硬件加速纹理映射单元设计
2014-01-20向前周珍艮
向前,周珍艮
(铜陵学院电气工程学院,安徽铜陵244000)
3D图形硬件加速纹理映射单元设计
向前,周珍艮
(铜陵学院电气工程学院,安徽铜陵244000)
随着第三代(3G)手持电子产品的发展,极大地拓宽了实时图形学的应用领域,而纹理映射是提高图形真实感最为有效的方法。电子技术的发展,为硬件加速芯片的设计提供了更多的选择。设计了基于FPGA的纹理映射电路,采用MIPmapping纹理映射算法,电路由纹理映射地址计算、三线性滤波和纹理存储器三部分组成。综合结果表明,对于24bits像素的绘制速度可达到41.145Mpixels/s和329.16Mtexels/s。
电子产品设计,实时图形学;纹理映射;电路;算法
1 引言
随着移动电子市场的发展,第三代(3G)多媒体设备,如PDA、智能手机等变得越来越普遍。这些设备不仅具有MP3音频、MPEG-4视频实时解码电路,甚至于具备了三维图形功能。3D图形学对在游戏、广告和网络虚拟角色方面的应用具有极大的诱惑力,它们的数据通过有限带宽的无线网络下载。为了满足手持设备实现3D图形这类市场的需要,近些年来国外进行了大量的研究尝试,开发了各种专用硬件加速电路方法,或者纯软件方案。尽管如此,还是永远不能满足市场要求,仅仅实现有限的图形明暗操作,而没有纹理映射所产生的真实感和其它特定的绘制效果,对于3D游戏这类应用是永远不够的[1]。
纹理映射就是将二维纹理图像映射到计算机产生的图形上,以提高图像的视觉真实感。它是高质量图像合成中最成功的新技术之一。
纹理映射在计算机图形计算中属于光栅化阶段,处理的是像素,主要的特点是数据的吞吐量大,对实时系统来说转换的速度是一个关键的因素,人们寻求各种加速算法来提高运算速度。传统的方法是用更快的处理器,并行算法或专用硬件。随着数字技术的发展,尤其是可编程逻辑门阵列(FPGAs)的发展,提供了一种新的加速方法。FPGAs在密度和性能上都有突破性的发展,当前的FPGA芯片已经能够运算各种图形算法,而在速度上与专用的图形卡硬件相同。因此,FPGA芯片非常适合这项工作[2]。
2 纹理映射过程
纹理映射就是将任意的平面图形或图像覆盖到物体表面,形成表面细节。纹理映射过程就是寻求每个屏幕像素所对应的纹理像素,将这些像素从存储器中读出,并对其进行加权后用来替换屏幕像素颜色值。所以整个纹理映射涉及纹理寻址以及纹理加权。纹理加权又称为后置滤波。
基于硬件加速的纹理映射按其后置滤波的原理可分为各向同性和各向异性,常用的各向异性算法如椭圆形权重平均、区域求和表法由于运算量太大,难以硬件实现。硬件实现的各向异性滤波方法称为足迹集合(Footprint assembly)的滤波方法,主要用于图形工作站及高档个人电脑。基于分级细化(MIPmapping)的各向同性滤波,由于它的运算量小和易于硬件实现,以及可以产生良好的图像质量,成为最普遍的纹理滤波方法,当前各种图形加速卡都以各自的方式对它进行支持。

图1 MIPm apping纹理映射
图1 为分级细化的纹理映射过程[3]。首先将纹理图像从原始图像开始,以1/2的分辨率进行缩减采样,并将图像以金字塔方式存储在存储器中,不同分辨率的图像称为不同细节层次(LOD)。纹理映射时,将每个屏幕像素看成是单位正方形,利用透视投影函数将正方形四个顶点投影到原始纹理空间(LOD= 0),形成一个任意形状的四边形,这个过程称为透视校正地址计算。接着根据四边形的四个边在横坐标与纵坐标上的最大跨度来计算所要采样的纹理图像细节层次。如果采样不在整数层次上,则需要在两个层次上进行采样。
图1中假设LOD为1.64,故在第1层次及第2层次上进行采样。映射到该细节层次上的纹理坐标可能不在整数位置上,这时要对其邻近的4个纹理进行采样加权,称为双线性插值。在两个层次上对8个纹理双线性插值后的结果还要进行一次插值,称为三线性插值。得到的最终颜色值送到帧缓冲中进行纹理混合,用来取代屏幕上的像素颜色值,完成整个映射过程。
3 纹理映射电路实现
3.1 总体结构
MIPmapping纹理映射硬件实现的总体框图如图2所示[3][4],主要由三个部分组成:纹理地址产生、纹理存储器及后置滤波单元。纹理地址单元的作用是计算出屏幕像素点(x,y)所对应纹理在存储器中的存储地址,它包括透视投影转换的透视校正地址计算、像素在纹理图像上映射坐标的双线性纹理地址计算,以及纹理存储物理地址的计算。
从纹理存储器中读出的4个或8个纹理在纹理滤波器中进行加权,得到最终用于与屏幕像素混合的颜色值。后置滤波由两个双线性滤波和一个三线性滤波组成,当然,如果纹理访问只在单一层次上进行,只需要进行一次双线性插值即可。
纹理存储单元是用来存储所需纹理,每个纹理按不同的细节层次存放,不同的纹理有一个起始地址(entry_address)。
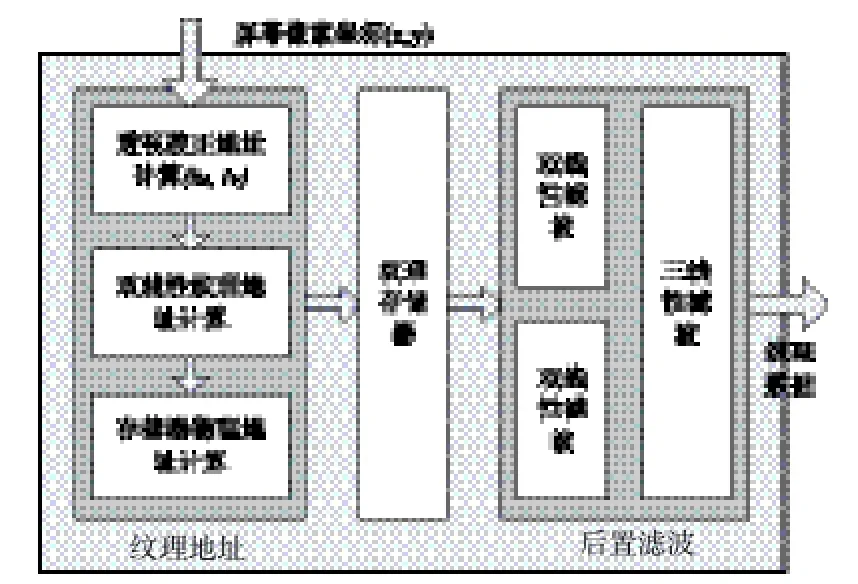
图2 纹理映射总体框图
3.2 透视校正地址计算
根据屏幕像素坐标来求对应的纹理坐标称为逆向映射,转换式为[4]:
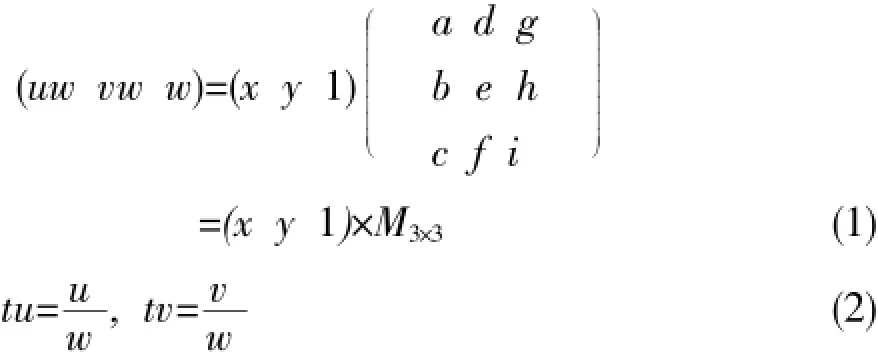
式中(x,y)与(u,v)为屏幕空间及纹理空间的坐标,(xw,yw,w)与(uw,vw,w)分别为它们的齐次坐标。矩阵M3伊3为逆向映射的转换矩阵。齐次坐标再除以w得到透视校正笛卡尔坐标地址(tu,tv)。
为获得大的数据吞吐量,和满足实时处理要求,这里采用流水线结构的正交矩阵电路[5]。由于相乘矩阵的维数分别是3伊1和3伊3,结果为3伊3阵列,所以共需9个单精度浮点乘累加处理器单元PEij。矩阵M3伊3元素mij先导入到PEij寄存器中,(xi,yi,zi)的输入方式,通过FIFO堆栈,每个周期依序输入(x1,0,0)、(x2,y1,0)、(x3,y2,z1)…。
图3中3伊3阵列完成齐次坐标(uw,vw,w)计算,两个单精度的浮点除法器(Div)完成笛卡尔坐标转换。

图3 透视校正地址计算矩阵
3.3 双线性地址及存储器地址计算
双线性地址及存储器地址计算包括细节层次(Level_of_datail)、基地址(Base_address)、双线性地址(Bilinear_Address)及存储器地址(Memory_Address)四个单元组成,三个流水线阶段,见图4。
MIPmapping映射将屏幕像素看成单位正方形,将其四个顶点透视映射到原始纹理图像上,在纹理图像空间正方形映射成任意四边形足迹(Footprint),四边形在纹理空间横向与纵向最大跨度的对数,便是所要采样的纹理图像层次。四边形足迹最大跨度:

Iwidth及Iheight分别为原始纹理图像高宽。于是纹理采样所在细节层次:

lod层2D纹理图像数组距离该纹理存储的起始地址偏移量基地址用base表示:

式中lw=log2(每个像素RGB比特数),24位。
像素中心映射到lod细节层次纹理上整数横坐标u及纵坐标v可由下式来计算:
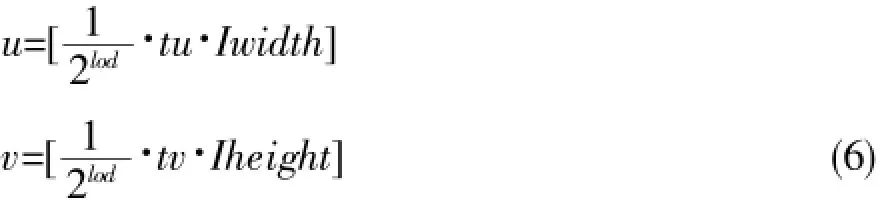
对应lod细节层次上纹理映射四边形对应的宽与高:

lod+1细节层次上纹理映射四边形对应的宽与高减半。
在lod细节层次上双线性地址offset0和lod+1细节层次上双线性地址offset1则可计算如下:

存储器地址的计算是将前一流水线阶段产生的base,offset,entry_address相加,就可产生实际的纹理存储地址。

图4 纹理地址计算
3.4 纹理滤波电路
图5给出了三线性滤波顶层综合电路,由两级流水线组成,由两个双线性插值和一个三线性插值单元组成。其中dintetp为三线性插值系数,I01~I14是从存储器中读出的8个纹理颜色值,Pixelcolor则是滤波后的纹理像素颜色值。u0f、v0f、u1f、v1f为层次lod和lod+1上的双线性插值系数。双线性插值系数实际上是屏幕像素映射到对应纹理层次上坐标的小数部分:

式中对应的是lod层次上插值系数,lod+1插值系数只要将lod加1即可。
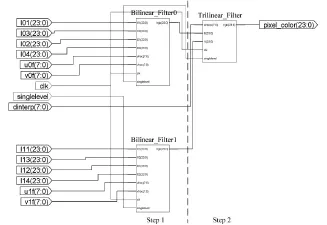
图5 纹理滤波电路
双线性滤波的公式为:

式中I同一层次上的四个纹理,uf、vf为双线性插值系数。
三线性滤波是将两个双线性滤波的结果再进行一次插值,以得到最后的像素颜色值:

I0、I1分别为两个双线性滤波输出的结果。
4 仿真结果
电路综合结果在表1中列出,包括所耗资源,各单元的频率。乘累加模块的频率最低,为41.145 MHz,共有9个PE单元,脉动阵列每一行数据从输入到输出共需12个周期。纹理存储地址采用3级流水线结构,所以从信号输入到输出共需3个时钟周期,最大综合频率为141.683 MHz。后置滤波电路由两个双线性滤波及一个三线性滤波电路组成,分为2级流水线,用于对所读取的纹理进行滤波,综合后最大频率为106.940 MHz。
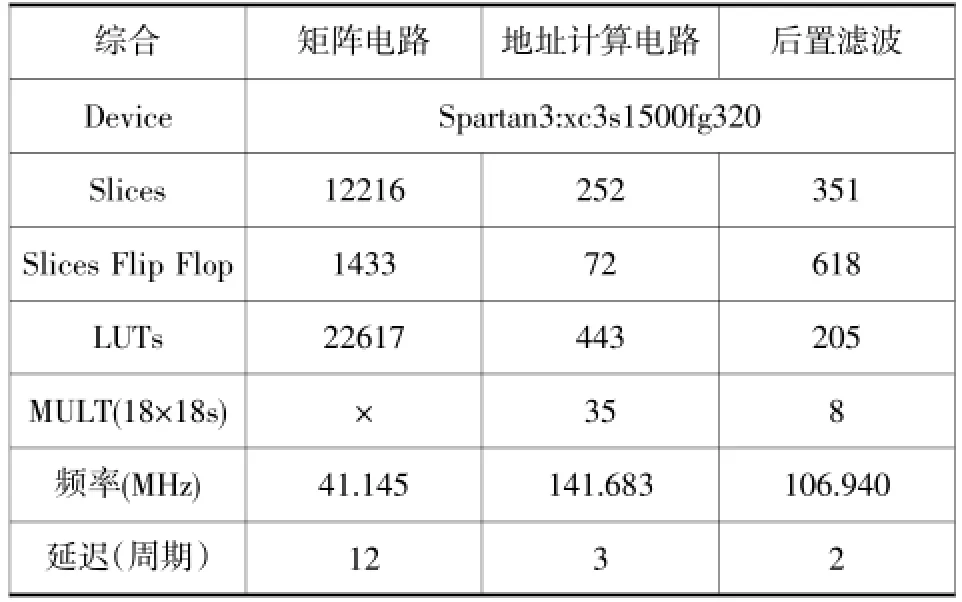
表1 电路资源耗费及性能列表
电路综合结果表明,纹理映射单元可达到41.145MPixels/s及最大329.16MTexels/s的处理能力,大于一个640伊460尺寸屏幕个人移动电子产品所需的18MPixels/s处理能力。
5 总结及未来的工作
本文设计了纹理映射单元纹理地址发生电路及后置滤波电路。各电路采用流水线来实现,综合结果达到41.145MPixels/s及329.16MTexels/s。
纹理映射单元由于计算量巨大以及存储器读取,能量消耗很大,进一步工作是要减小这部分电路的面积及能量损耗,以适应移动设备的要求。初步的方案是将浮点数透视校正地址计算矩阵转换成定点数运算,以减小电路面积,同时采用缓存的方法减少纹理存储器访问次数,对后置滤波部分,利用纹理像素在空间上的连续性来减少乘累加的次数。
[1]Ramchan Woo,Sungdae Choi,Ju-Ho Sohn,Seong-Jun Song, and Hoi-Jun Yoo,A 210-mW Graphics LSI Implementing Full 3-D Pipeline With 264 Mtexels/s Texturing for Mobile Multimedia Applications[J],IEEE JOURNAL OF SOLID-STATE CIRCUITS, VOL.39,NO.2,FEBRUARY 2004,p358-p367.
[2]Xilinx Incorporated.http://www.xilinx.com.
[3]Kurt Aleley,Pat Hanrahan,Real-Time Graphics Architectures [M],http://www.graphics.stanford.edu/courses/cs448a-01-fall/.
[4]P.S.Heckbert,Fundamental of texture mapping and image warping [D],M.S.thesis,Comput.Sci.Div.,Univ.California,Berkeley,CA,1989.
[5]Pavel.Zemcik.Hardware Acceleration of Graphics and Imaging Algorithms and about ingltering and texture memory.ng circuit Using FPGAs[D].http://www.fit.vutbr.cz/zemcik/publics/sccg2002.pdf.注:本课题为安徽高校省级自然科学研究项目(编号:KJ2012Z415),铜陵学院自然科学研究项目(编号:2006tlxykj004)
Design of Texture M apping Unit for 3D Graphics Hardware Acceleration
XIANG Qian,ZHOU Zhenyin
(The Electrical Engineering College of Tongling University,Tongling,Anhui 244000,China)
Development of the third-generation(3G)hand electronic products has great原ly broadened the application space of real-time graphics,while texture mapping is the most effective way to improve the sense of reality of graphics.Development of electronic technology has provided much more choice for the design of hardware acceleration chips.A texture mapping circuit was designed based on FPGA and using MIPmapping texture mapping algo原rithm.The circuit consisted of texture mapping address calculation,trilinear filtering and tex原ture memory.Comprehensive results showed its mapping speed can reach 41.145Mpixels/s and 329.16Mtexels/s for 24bits pixels.
design of electronic product;real-time graphics;texture mapping;electric cir原cuit;algorithm
TP332
B
1006-6764(2014)04-0068-04
2014-01-07
