基于数据驱动的区域交通TOD时段识别方法研究*
2014-01-18王海起王劲峰
王海起 张 腾 王劲峰 孟 斌
(中国石油大学(华东)地球科学与技术学院1) 青岛 266580)(中国科学院地理科学与资源研究所资源与环境信息系统国家重点实验室2) 北京 100101)(北京联合大学应用文理学院3) 北京 100191)
0 引 言
TOD(time of day)多时段配时属于交通信号离线配时方式,它根据交通流的变化情况将1d分为多个时段,每个时段内的交通量基本不变,各时段分别采用不同的配时方案,信号灯根据实时时钟自动进行配时方案的切换.
随着智能交通系统的发展,城市道路、交叉口等安装了不同类型的交通流检测设备,这些采集系统积累了大量的交通流历史数据,借助于聚类手段,可以将1d不同时刻的交通流数据聚为不同的几类,不同的类代表高峰、低峰等不同的交通状态,属于同一类的各时刻具有相近的交通状态[1],因此,同一类中的连续时刻可以归为同一个TOD时段,从而可以确定1d的TOD时段分布.
然而,对于区域交通TOD配时,由于参与聚类的交通检测器数目较多,且数据质量参差不齐,可能导致出现无效的TOD时段(无效时段一般指长度少于30min,没有实际价值的TOD时段)或TOD时段数过多,各时段间的切换需要耗费时间,频繁的TOD时段切换将导致信号配时性能下降,因此应减少参与TOD时段识别的检测器,重点考虑关键路口的检测数据[2].所谓关键路口是指对区域路网性能具有关键影响的信号交叉口.
本文提出了一种基于数据驱动的区域TOD时段识别方法,包括交通数据整理、关键交通流选取、聚类分析、TOD时段识别等步骤,数据整理的目的是对检测设备获取的交通数据进行质量监测,定位缺失值和无效值,并采用合适的方法进行插补;交通流选取的目的是在空间上识别出整个区域路网的关键交通流,包括确定关键交通流个数和定位关键交通流位置2个步骤;聚类分析的目的是对关键交通流不同时刻的观测值进行聚类,从而获取不同类型的交通状态,包括聚类分析、聚类效果判别及类数确定等;TOD时段识别的目的是根据各时刻所处的交通状态,识别出一天的TOD时段数及各时段间隔.
1 基于数据驱动的区域TOD时段识别方法
1.1 交通数据整理
1.1.1 数据质量监测
造成原始检测数据缺失或无效的可能原因有多种,包括检测器故障、通信故障、人员或系统数据处理错误等[3].
原始数据中的缺失值一般以零值或空白作为记录,容易判断,缺失现象的出现较随机,可能缺失某一个或多个时段的数据,可能缺失1d或多天的数据,也可能出现在单个或多个检测器上.
相对于数据缺失,交通数据的无效性判断要复杂些,无效数据是指不符合交通流特征与参数关系的检测数据或异常高、低的离群数据.
Turochy和May提出了无效数据探测的交通数据筛选规则[4],包括:非零值检验、预筛选检验和可行流量值检验.
离群数据探测可采用可视化与统计相结合的手段[5].例如,对于道路某方向可绘制连续时刻流量的变化曲线,一般来说,流量的连续变化总是相对平滑的,因此,如果相邻时段流量突然剧增或剧减,那么该数据存在高度离群的可能,进一步的判断可采用正态分布χ2检验、偏度峰度检验、四分位检验等统计方法.
由于涉及的研究区域线圈检测器仅采集流量数据,并没有占有率和速度数据,因此本文对无效值的判断集中于离群数据的探测.需要指出的是,对采用可视化、统计等手段探测出的离群数据应作进一步辨识,以判断是由于设备、通信故障等造成的伪数据,还是特定交通状况的真实反映,可从时空两方面进行识别:在时间上将离群数据所处时段和前后时段、前后若干天同一时段进行对比,在空间上将离群数据所在交通流向和同一路口其他流向对应时段、相邻路口同一流向对应时段等进行对比,以确认离群数据的真伪性.
1.1.2 缺失及无效数据处理
处理缺失、无效数据的简单方式是将其对应的记录从交通数据仓库中删除.但是,对于TOD时段识别,简单删除将导致对应时段的观测值出现空白,而对一天不同时刻观测值进行聚类要求参与聚类的时段能够反映不间断的交通变化状况,即各时刻须具有相应的观测值,因此可对缺失或无效数据进行插补以获得合理的估计值.韩卫国比较了几种用于流量缺失数据插补的方法,包括历史平均值法、相邻时段平均值法、相邻检测器平均值法、EM(expectation maximization)方法,MCMC(markov chain mento carlo)方法,以及改进的空间EM方法,实际效果表明后三种方法明显好于其他方法[6].本文采用EM方法进行插补.
1.2 关键交通流选取
对于单个信号交叉口而言,可能仅有4个入口,却可能有12种交通流向(每个入口有左转、直行和右转3个方向),如果每个方向均安装检测器,那么单个路口就存在12种交通流的观测数据.对于包含多个交叉口的区域路网来说,检测器数目增加得更快.从数据挖掘角度来说,大量的数据总能提供更多有价值的信息.然而,对交通工程来说,一方面,交通网络中不同路口、不同方向、交通流的重要性是不一样的,那些对整个路网性能起到关键影响的交通流向总是被优先考虑;另一方面,对于随后的聚类分析,如果参与的检测器过多(即交通流过多),可能导致获取的交通状态及相应的TOD时段数过多,各TOD配时方案的频繁切换不仅耗费时间而且会干扰交通流的正常流动,从而降低整个交通控制系统的性能.
因此,关键交通流选取就是识别路网的主要交通流,在维持交通控制系统性能不降的前提下仅保留那些包含主要特征的变量(每个交通流视为一个变量)以降低问题空间维数,采用多元相关分析和主成分分析法.
1.2.1 多元相关分析
基于多元相关分析的主要变量选取思路就是选取一个指定数目的变量子集,使子集中的变量(看作解释变量)与子集外的其余变量(看作因变量)具有最大的复相关系数.
设全体变量的个数为k,需从中选取p个主要变量,有以下2种方法.
方法A1,每次从全体变量中选取p个变量作为一组,计算该组p个变量与其余k-p个变量中每个变量的复相关系数,并保留其中最小的复相关系数,最后比较各组的最小复相关系数,数值最大的那组即为最终选取的p个主要变量.该方法可以找到一组最佳的主要变量,但需获取p个变量的所有组合,效率较低.
方法A2,每次在全体变量中寻找与其他变量复相关系数最大的那个变量将其舍弃,并在剩余变量中重复该过程,直至剩下p个变量.该方法比方法A1速度快,但不能保证找到最佳的p个主要变量.
1.2.2 主成分分析
将贡献率小的主成分最能解释(即变差比例大,主成分与原始变量之间的相关系数称为变差比例)的原始变量舍弃掉,剩余的原始变量即为需保留的主要变量.
从k个原始变量中选取p个主要变量有以下2种方法.
方法B1,从最小特征值开始的k-p个主成分,对每个主成分选取其最能解释的一个原始变量,每次选取时不考虑之前已被选取的变量,直至最后得到k-p个需舍弃的原始变量.
方法B2,从最大特征值开始的p个主成分,对每个主成分选取其最能解释的一个原始变量,每次选取时不考虑之前已被选取的变量,直至最后得到p个需保留的主要变量.
1.2.3 主要变量个数
选取多少个变量足以包含原始数据集的主要特征,即多元相关分析和主成分分析中p的确定.
Jolliffe认为当舍弃的变量个数等于相关矩阵小于0.7的特征值个数时,其效果较好,称为Jolliffe’s eigenvalues less than 0.7方法.
在SAS,SPSS等统计软件中,常用的是主成分个数与协方差矩阵或相关矩阵大于1.0的特征值个数相同,称为eigenvalues-great-than-one.
Velicer提出了基于偏相关矩阵的MAP(minimum average partial)方法,该方法依次构建各阶偏相关系数矩阵(阶数从零到变量个数减1),计算各阶矩阵中相关系数平方的均值(即矩阵上三角或下三角元素平方的均值),则具有最小均值的阶数即为主要变量个数.
另外,Horn提出了平行分析法PA(parallel analysis),是eigenvalues-great-than-one方法基于样本的改进版本.首先构建与样本数据集具有相同变量、样本个数的随机数据集,然后比较样本数据集和随机数据集相关矩阵的特征值,若前者的特征值大于后者对应的特征值,则相应的主成分被保留,最后保留的主成分个数即为主要变量个数.
基于多检测器数据识别路网的关键交通流时,首先采用上述4种方法确定关键交通流的个数,然后采用A1,A2,B1和B2方法识别出关键交通流所处的空间位置.
1.3 聚类分析
采用层次聚类对区域关键交通流各时刻的观测值进行样本聚类,从而获取不同类型的交通状态.
1.3.1 层次聚类
使用聚合聚类中的Ward法,聚合聚类初始将每个对象单独作为一组,每次仅聚合两个组,直至所有对象聚合为同一组,Ward法要求同类对象间的离差平方和较小,类间对象间的离差平方和较大.
1.3.2 聚类效果及类数判别
包括R2、半偏R2、伪F、伪t2等统计量.R2统计量即RSQ(Root SQuare Variance),其值越大,类内离差平方和在总离差平方和中所占比例越小,说明各类之间区分越明显,即聚类效果好。伪F统计量即PSF(PSeudo FStatistic),其值越大,表明聚类的分类效果越好。伪t2统计量即PST2(PSeudo t2Statistic),其值为正数且显著时表明2个类合并后的类内离差平方和比合并前的类内离差平方和要大,说明合并的2个类应分开,即合并前的聚类效果好。半偏R2统计量即SPRSQ(Semi-Partial RSQ),该统计量与t2统计量有类似的含义,当两个类合并后其值为正数时,说明合并前的聚类效果好。
这四4统计量将用于区域关键交通流不同时刻观测值聚类效果的判别,在综合各统计量结果的基础上确定聚类的最终类数.
1.4 TOD多时段识别
1d的各时刻依据其观测值的聚类结果可归为不同的类,各类可通过均值、中值、最大最小值等统计特征描述其反映的交通状态,进而,处于同一交通状态的连续时刻可归为同一个TOD时段.
然而,由于样本数据包含检测器几天、几个月、甚至几年的观测值,聚类结果中不同天的同一时刻可能归为不同的类,即可能具有两个或更多的交通状态,从而无法确切地认定同一时刻所属的TOD时段.解决方法是对一个时刻统计其所属各交通状态的天数,天数最多的状态即为其最终的交通状态,可利用统计直方图完成;在此基础上,可识别出一天的TOD时段数及各时段起止时刻,对于间隔小于30min的TOD时段则视具体情况合并到前一或后一时段中.
2 应用研究
2.1 研究区域
选择北京西城区西二环和西三环之间一面控子系统为研究区域(见图1),9个平面交叉口,每个交叉口的4个入口均埋设有环形线圈检测器用于采集不同流向的流量数据,共37个检测器.
采集时间为2002年8月~11月4个月,重点考察工作日的检测数据,共87d,检测器每天24h每15min采集一次流量数据,每天有96个观测值,故原始数据集Dataset0共有37个检测器变量,8 352个样本观测值(87d×96).
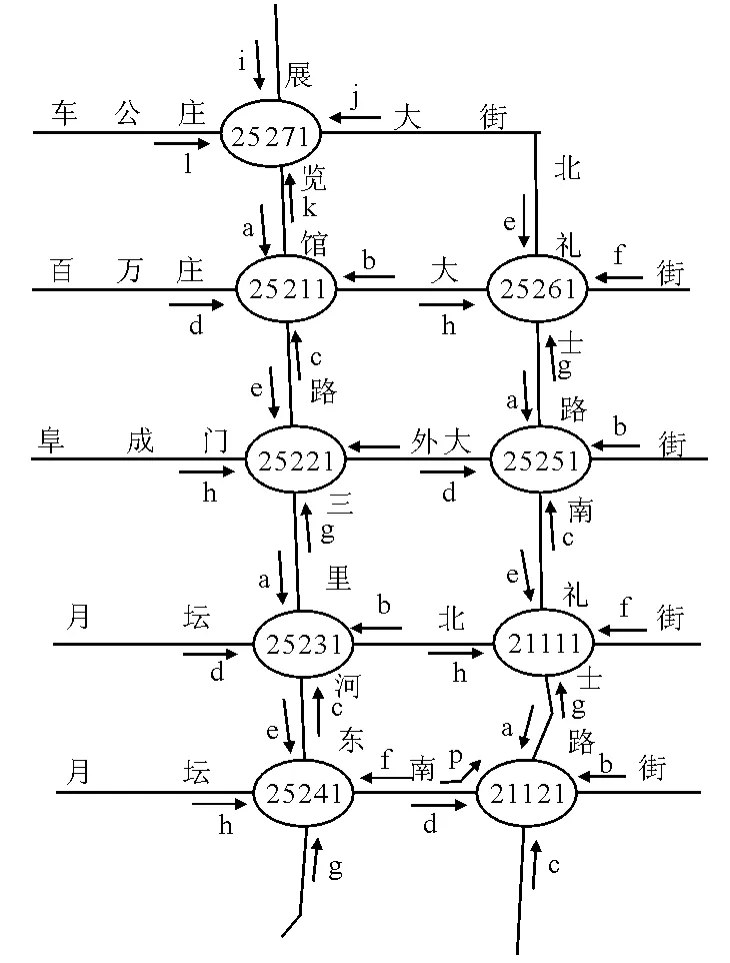
图1 研究区域交叉口检测器分布及监测交通流方向示意图
2.2 流量数据整理
对数据集Dataset0的整理发现检测器21111f,21121b,25241e,25271i并没有采集数据,对其余33个检测器进行缺值统计,发现数据缺失现象存在2个较长的连续时段:9月9日~9月17日、11月18日~11月29日,其他缺失时段较为分散.
对于较长时段的数据缺失,过多的插补数据会包含太多的人为信息,因此,基于如下两个原则剔除相关的检测器和观测天数据:(1)如果一个检测器有一半以上的观测天(即大于43d)没有数据,那么该检测器将被剔除.据此,检测器21111g,21121p被剔除;(2)如果某天缺失数据超过40个的检测器数目>=3,那么该观测天的数据将被剔除;另外,也不考虑节假日数据,即10月1日~7日.
再对其余零散的缺失采用EM方法进行插补,最后得到的数据集Dataset1有31个检测器变量,4 896个观测值(51天×96).
2.3 关键交通流选取
采用 Eigenvalues-great-than-one、Jolliffe’s eigenvalues less than 0.7,MAP和PA 4种方法得到的关键交通流个数(即检测器个数)分别为4,6,6,6,其中3种方法的个数相同,因此将从31个检测变量中挑选6个主要变量.
采用多元相关分析的A1,A2方法和主成分分析的B1,B2方法识别出的6个主要检测变量见表1,并分别计算主要检测变量(看作解释变量)与其余每个变量(看作因变量)的复相关系数,表中给出了每种方法的最小复相关系数,其中方法A1值最大,说明该主要变量子集对其他变量的解释能力最强,因此,以方法A1的选取结果为准,在这6个检测器中,3个监测自北向南的交通流,2个监测自南向北的交通流,1个监测自西向东的交通流,反映了该区域南北向为主要交通流方向.相应的数据集Dataset2包括6个主要检测变量,4 896个观测值.

表1 4种方法识别的主要检测变量及最小复相关系数结果
2.4 聚类分析
采用层次聚类对Dataset2中6个变量的所有观测值进行聚类,具体实现利用SAS软件的Cluster过程完成,图2~5为统计量RSQ,SPRSQ,PSF和PST2随类数的变化情况.
聚类中的每个类可以定义为一种交通状态,如前所述,过多的类会增加配时方案切换的频率,当然,过少的类也不能充分反映交通状况的变化,Wang认为对于交通信号配时,聚类类数介于4~7之间较为合适,结合聚类统计量结果,最终类数选择为5类,则相应的数据集Dataset3中4 896个观测值均可归属为某个确定的类.
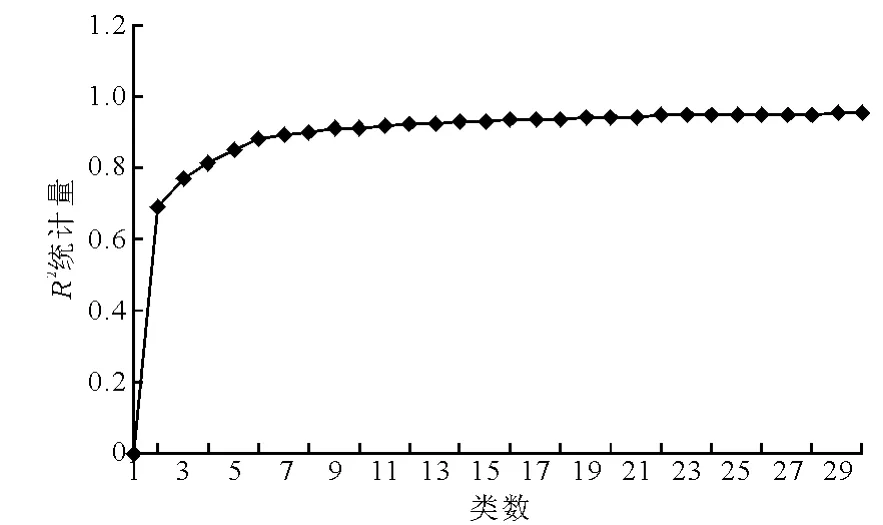
图2 Ward聚类R2统计量的变化
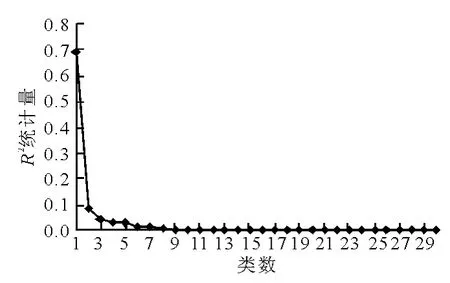
图3 Ward聚类半偏R2统计量的变化
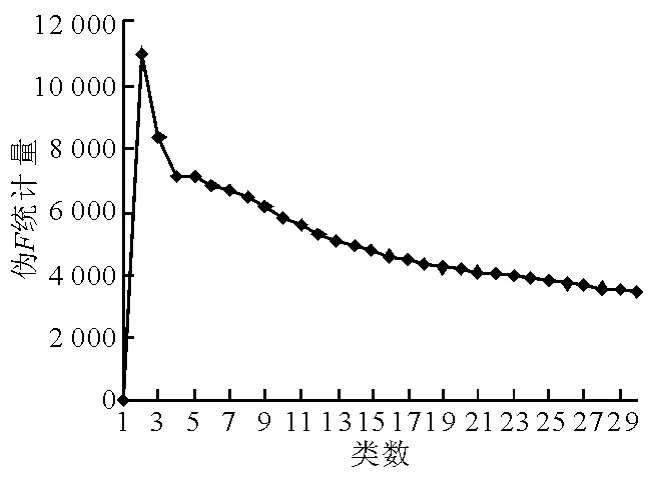
图4 Ward聚类伪F统计量的变化
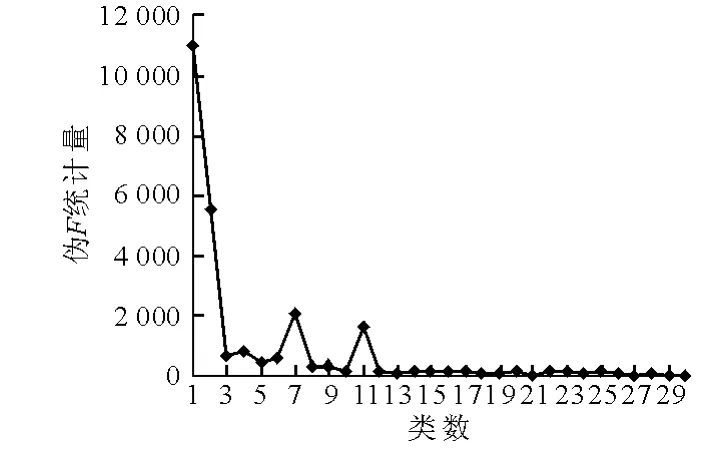
图5 Ward聚类伪t2统计量的变化
2.5 TOD多时段识别
图6 是各类平均流量变化情况,每个类代表的交通状态可描述如下.
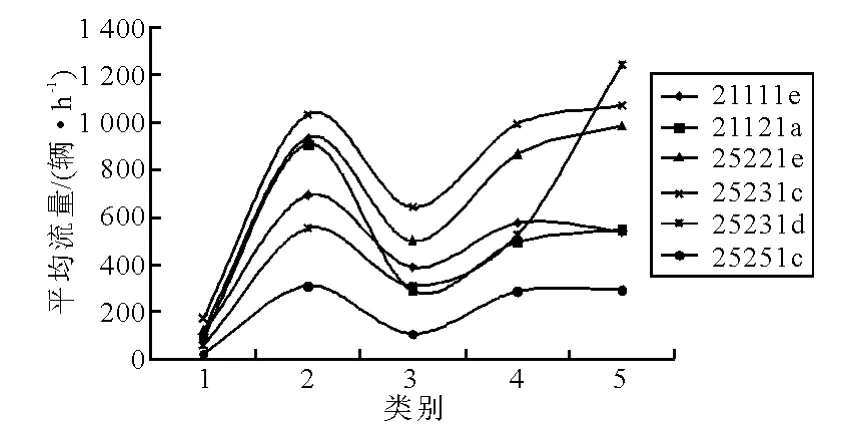
图6 5个类各主要检测器平均流量变化情况
1)类1 代表了低流量需求的交通状态,如午夜或凌晨期间的交通状况.
2)类2 代表了整个区域南北向、东西向高流量需求的交通状态,反映区域各方向交通高峰期.
3)类3 代表了中等流量需求的交通状态,如高峰来临前或高峰结束后的交通状况.
4)类4 代表了由展览馆路、三里河东路组成的干线南北向高流量需求的交通状态,反映干线南北向交通高峰期.
5)类5 代表了由展览馆路、三里河东路组成的干线南北向、东西向高流量需求的交通状态,反映干线各方向交通高峰期.
根据数据集Dataset3中各观测值的采集时间和所属的类,可以对1d内不同时刻的交通状态分布进行描述,图7是1d各时刻5种交通状态频数统计直方图.

图7 1d各时刻5种交通状态频数统计直方图
可以看出,存在着不同天的同一时刻具有多种交通状态的现象,这是由交通系统的随机性、不确定性决定的,实际上,期望每天同一时间的交通状况保持不变是不现实、也不可能的,因此基于多天观测数据获取的一天不同时刻交通状态的分布情况应该是一种总体的或平均的分布描述,对于某个时刻,以出现次数最多的状态为其最终的交通状态,并据此将处于相同状态的连续时刻归为同一个TOD时段,同时对间隔较小的TOD时段进行合并,最终确定的该区域工作日一天内TOD时段数为8个,各时段的起止时间见图8.

图8 研究区域工作日1d各时刻交通状态最终分布情况
其中,晚上10:45~早晨06:30时段车辆较少,属于低交通量时期;早晨06:30~07:30时段随着上班外出车辆的增多,预示着高峰期的即将到来,属于中交通量时期;早晨07:30~上午09:15时段是展览馆路、三里河东路各方向交通量高峰期,上午09:15~中午12:00和下午02:00~04:15两个时段属于整个区域各方向交通量高峰期,中午12:00~下午02:00和下午04:15~晚上08:00两个时段属于展览馆路、三里河东路南北方向交通量高峰期,各高峰时段不同交通状态的形成与不同时期车辆的出行目的有关,与该区域居民区、商业区、行政事业单位等交通影响因素的空间分布差异和聚集程度有关,也与该区域的区位和在交通组织中承担的主要功能有关,原因的探究需采取进一步的相关调查(如OD调查等);晚上08:00~10:45时段随着出行车辆的减少,预示着交通低峰期的即将到来,属于中等交通量时段.
3 结束语
海量交通流数据中隐含着大量有价值的交通关系、模式或特征信息,本文基于数据驱动方式首先关注不同交通流的空间分布,识别出反映区域路网主要特征的关键交通流,接着关注这些关键交通流的流量变化,从而识别出一天各时刻所处的交通状态及相应的TOD时段分布.
需要指出的是,不同交叉口的交通流之间具有紧密的关联关系,因此在识别区域关键交通流时,进一步分析不同路口、不同方向交通流之间的空间、时空关联关系能更好地描述区域交通状态的时空分布及变化格局,区域交通的“热点”路口也应是判断关键交通流优先考虑的位置.
[1]HAUSER T A,SCHERER W T.Data mining tools for real-time traffic signal decision support & maintenance[A].2001IEEE International Conference on Systems,Man,and Cybernetics[C]∥IEEE,2001:1471-1477.
[2]WANG T.A methodology for data-driven signal timing optimization[D].Virginia:University of Virginia,2003.
[3]施莉娟,朱 健,陈小鸿,等.基础交通数据质量评价研究[J].交通信息与安全,2011,29(5):57-61.
[4]TUROCHY R E.Traffic condition monitoring using multivariate statistical quality control[D].Virginia:University of Virginia,2001.
[5]韩卫国,王劲峰,王海起,等.基于数据可视化的交通流量分析[J].武汉理工大学学报:交通科学与工程版,2004,28(5):668-670.
[6]韩卫国,王劲峰,胡建军.交通流量数据缺失值的插补方法[J].交通与计算机,2005,23(1):39-42.
