基于边缘强度匹配的图像融合并行算法的研究
2014-01-17吴粉侠
吴粉侠,李 红
(咸阳师范学院 信息工程学院,陕西 咸阳 712000)
图像融合是一门综合了传感器、图像处理、信号处理、人工智能等的技术,它是将不同传感器或相同传感器得到的多幅图像经过一定的融合算法进行处理,最终得到一幅包含多幅图像的特征和信息的高质量图像。图像融合充分利用了多个待融合图像中冗余信息和互补信息,是信息融合的一个有力工具,广泛应用于军事、遥感、医学图像处理、制造业等领域。
目前图像融合的算法主要分为3个层次,像素级图像融合,特征级图像融合,决策级图像融合。像素级图像融合是在基础数据层面上进行的信息融合,准确性高,细节信息多,但处理的信息量最大。特征级图像融合是对预处理和特征提取后获取的图像信息如边缘,形状和区域等信息进行综合与处理,它既保留了足够的重要信息,又可对信息进行压缩,利于实时处理。决策级融合是根据一定的准则以及每个决策的可信度做出最优决策,此种融合实时性好,并且具有一定的容错能力。像素级图像融合的算法有最大值最小值融合法,均值融合法,区域能量最大值融合算法,边缘强度最大融合算法等[1]。
随着图像的规模的增大及图像融合算法复杂度和提高,图像融合面临着新的处理速度的挑战。传统的图像融合加速算法多用CPU并行处理模式,如ChaverD等基于通用多处理机系统研究图像融合过程中大规模图像的并行分解算法[2];其处理速度也仅是常数倍的提高。GPU(Grahic Process Unit)从其诞生之日起,处理能力就以超越摩尔定律[3]的速度增长,使用GPU进行加速,其处理速度是以数量级增长的。
本文分析了边缘强度最大融合算法的并行特性,提出了一种改进的边缘强度最大的图像融合策略,并在GPU上实现了该算法。首先分别计算两幅图像对应像素的边缘强度并以边缘强度作为图像融合规则对图像进行融合,需要处理的数据量大,而对这些数据处理操作基本相同,本质上是一种局部的邻域算法,易于并行化,因此利用GPU对其进行了并行加速。实验结果表明本文算法得到的融合图像包含了源图像中较多信息,边缘保持度好,从客观评价指标上总体较好,并且与在CPU上处理速度相比最大加速比达到近6 000倍。
1 算法思想
1.1 边缘强度
图像的边缘包含了图像的重要纹理信息,边缘强度是图像边缘的客观描述。边缘强度的计算公式如式1[4]所示。
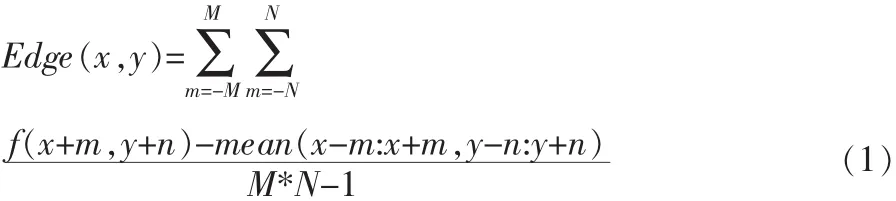
其中 Edge(x,y)表示像素的边缘强度,f(x+m,y+n)为邻域像素的灰度,窗口大小为M×N,一般取3×3或5×5,mean(x-m:x+m,y-n:y+n)为区域均值。
1.2 边缘强度最大图像融合规则
边缘强度最大的融合规则指的是,对应像素的边缘强度计算以后,选择边缘强度绝对值最大的图像的当前像素的灰度作为融合后的图像的灰度[4]。由于边缘强度值较大的像素的灰度对应图像中对比度变化较大的边缘特征,所以,边缘强度最大法能够较好地融合源图像的高频信息。
1.3 改进的边缘强度最大图像融合规则
本文对边缘强度最大的融合规则进行了改进,对应像素的边缘强度计算以后,计算两幅图像的边缘强度差,依据其差值确定融合结果,融合规则如式2所示。
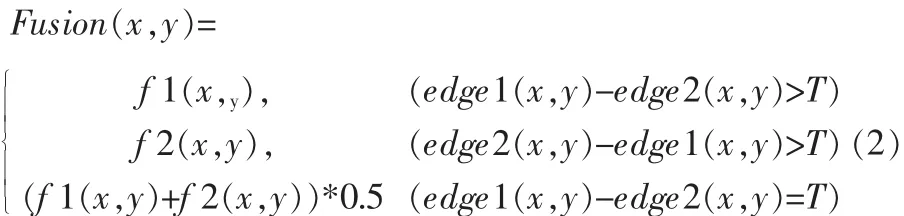
1.4 融合算法
本文所提出的图像的融合算法首先分别计算图像1和图像2对应像素M×N为邻域的均值,再依据式(1)计算对应位置的边缘强度,最后再依据式(2)图像边缘强度最大的融合策略对图像进行融合,获得融合结果图像对应像素的灰度。

图1 GPU硬件模型Fig.1 GPU hardware model
2 GPU加速算法的实现
2.1 GPU体系结构
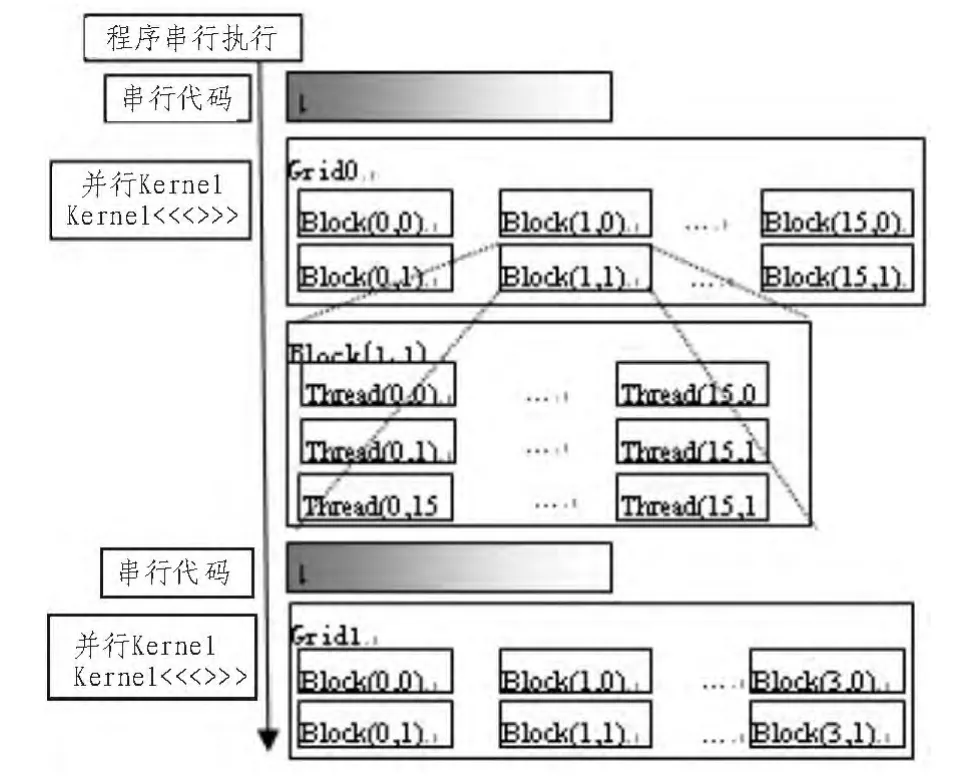
图2 CUDA编程模型Fig.2 CUDA Programming model
GPU(Graphics Processing Unit)即图形处理器,是一种专用的图形渲染设备,是显卡的计算核心,它分担了中央处理器(CPU)的图形处理任务。GPU的高度并行化的架构和可编程的着色器使人们将它用于计算通用任务,随之产生了GPGPU(General Purpoise Computing on Graphics Processing Unit) 图形处理器通用计算技术,该技术使显卡可以进行通用计算任务,从2009年开始,利用显卡计算已渐成主流,GPGPU也渐被GPU计算代替[5]。GPU通过单指令多数据(SIMD)指令类型来支持数据并行计算。如图2所示,在SIMD结构中,单一控制部件向每条流水线分派指令,同样的指令处理部件同时执行。例如NVDIA8800GT中包含有14组多处理器(Multiprocessor),每组多处理器有8个处理器(Processor),但每组多处理器只包含一个指令单元 (Instruction Unit)。从线程角度讲,每个多处理器可并行运行768个活动线程,即包含14组多处理器的GPU可并行运行10 752个活动线程。从存储器角度讲,每个多处理器有16 kB可读写共享内存、8 kB只读常量内存Cache、8 kB只读纹理内存Cache和8 192个 322 bit寄存器[6]。
2.2 CUDA编程模型简介
CUDA是NVIDIA公司于2007年正式发布的一种不需借助图形学API就可以使用类C语言进行通用计算的开发环境和软件体系。它包括一个硬件驱动程序和一个应用程序接口,直接将GPU作为数据并行计算设备。它能够利用NVIDIA GPU的并行计算引擎比CPU更高效的解决许多复杂计算任务[7]。
CUDA编程模型将CPU作为主机(Host),GPU作为协处理器(co-processor)或者设备(Device)。在一个系统中,可以存在一个主机和若干个设备。CPU和GPU协同工作,CPU负责进行逻辑性强的事务处理和串行计算,GPU则专注于执行高度线程化的并行处理任务。CPU和GPU各自拥有相互独立的存储器地址空间:主机端的内存和设备端的显存。运行在GPU上的CUDA并行计算函数称为kernel(内核函数),它是整个CUDA程序中的一个可以被并行执行的步骤,以网格(Grid)的形式执行,不同的网格则可以执行不同的核函数;每个网格由若干个线程块(Block)组成,每一个线程块又由多个线程(thread)组成[7]。属于同一线程块的线程拥有相同的指令地址,能够并行执行,并且能够通过共享存储器(Shared memory)进行线程块内通信。如图2所示,一个完整的CUDA程序是由一系列的设备端kernel函数并行步骤和主机端的串行处理步骤共同组成的,主机端调用标准C编译器生成目标代码,设备端则由NVIDIA的C编译器生成相应的含有PTX(Parallel Thread Execution)的目标代码,之后两者链接生成完整的可执行程序[7]。
2.3 GPU算法实现
算法中每一个像素点的融合都是点处理,边缘强度的计算是以像素点为中心的邻域处理,均可以对其进行并行加速处理。本算法的GPU实现由主机端程序和设备端程序协同工作完成。主机端程序负责I/O数据的传输和程序流控制,设备端内存的分配与释放及内核函数的启动[7]。本文中,主机端程序实现图像数据的读写、主机端和设备端存储空间的分配、主机端和设备端数据的传输、纹理内存的绑定与释放、内核函数的启动及主机端和设备端内存空间的释放等功能。在设备端,按本文算法进行边缘强度的计算及融合。本文算法中使用一个核函数来完成图像融合的并行处理,使用一个线程格Grid,Grid中含有和图像高度一致的线程块数,每个线程块含有的512个线程。本文算法将两幅源图像数据均与纹理存储器绑定,通过读取纹理存储器中的数据进行快速并行访问。
本文算法处理流如图3所示,具体算法步骤如下:
1)通过CPU分别将将两幅图像数据读取到主机端内存h_Src1,h_Src2中,并分配主机端内存h_Des以存放融合结果图像,根据读取的图像的大小在GPU上分配设备空间cuArray1、cuArray2、d_Des,拷贝 h_Src1 中的数据到设备内存cuArray1中,拷贝h_Src2中的数据到设备内存cuArray2中;
2)声明纹理引用tex1并与cuArray1绑定,声明纹理引用tex2并与cuArray2绑定;
3)设定GPU的线程组织;
4)运行自定义的kernel函数对图像进行融合,处理结果存放到设备端内存变量d_Des;
5)解除tex1与cuArray1纹理绑定,解除tex2与cuArray2纹理绑定;
6)从设备端向主机端拷贝结果数据d_Des到主机端h_Des中,并将h_Des保存到磁盘上;
7) 释 放 设 备 端 cuArray1、cuArray2、d_Des 及 主 机 端h_Src1、h_Src2,h_Des的内存空间。
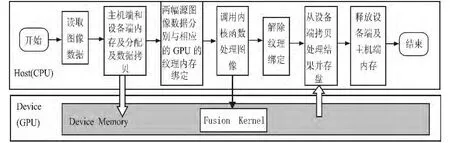
图3 本文算法流程Fig.3 The process of this algorithm
3 实验结果
实验编程环境采用Visual Studio 2010,GPU编程语言CUDA 4.2。实验的硬件平台为PC机,CPU是Intel(R) Core(TM) i5-2380P,显卡为Novidia GTX 560 SE,含有288个CUDA核心。实验中用到了两组不同的多聚焦图像 (如图4所示)。本文采用的融合算法有3种,方法一为利用像素取最大值的方法,方法二为边缘强度取最大法,方法三为本文所用融合算法,文中选用的窗口大小为3*3计算像素点的边缘强度。
对于融合算法的性能评价采用了熵、互信息和QAB/F,SF 4个准则[8],熵是衡量信息量丰富程度的一个重要指标,通过图像信息熵的比较可以对比出图像的细节表现能力,熵越大则表示融合图像所包含的信息量越丰富,融合质量越好。互信息作为两个变量间的相关性的度量,用来衡量融合图像包含源图像中信息的多少,其值越大表明从源图像中继承的信息越多,融合结果越好。QAB/F利用Sobel边缘检测来衡量图像边缘信息保持度,其值越大说明边缘保持越好。SF反映一幅图像空间域的总体活跃程序,其值越大,图像越清晰,即融合效果越好。
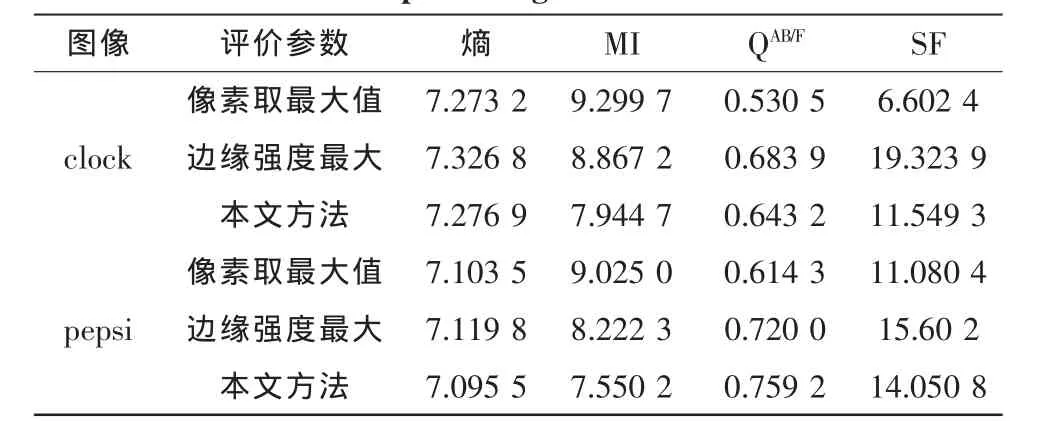
表1 不同算法图像处理效果比较Tab.1 Comparison of different algorithms of image processing effect
从实验结果看,与方法一相比,本文方法得到的结果从视觉效果上看图像对比度清晰,从评价指标来看,熵的指标差不多,MI指标本文算法偏低,而后面二个指标的值本文算法明显偏高,表明在对比度,纹理清晰度方面本文算法优于绝对值取大融合算法,纹理清晰,边界保持较好说明本文采用的方法对多聚焦图像融合时效果较好;与方法二相比,熵的指标差不多,MI指标略低,第三个指标相差不多,SF指标对clock来说低了许多,对Pepsi图像来说,相差不大。从视觉效果上看,本文算法所获取的图像边缘清晰,对比度明显,图像自然,没有出现法二所示的伪轮廓和边缘。总体上说,本文算法对多聚焦图像融合的效果较好。
通过对图像进行20次测试取平均值的方法对CPU上实现的算法与GPU上实现的算法的处理速度做了比较。从表2中可以看出GPU上的加速效果非常明显,随着图像尺寸的增大,采用CUDA进行大规模并行计算的加速比增大,实验中的最大加速比达到近6 000倍。

图4 待融合图像Fig.4 The images for fusion

图5 像素取最大值的方法Fig.5 Method of pixel maximum value

图6 边缘强度最大法Fig.6 method of maximal edge strength

图7 本文方法Fig.7 Proposed method
4 结束语
本文提出的基于边缘强度匹配的图像融合并行算法,依据图像的边缘强度决定采用何种融合策略,并在GPU上对其进行了实现。实验结果表明采用本文所用算法得到的融合图像在保持视觉效果良好及客观评价参数较高的情况下,具有非常高效的处理速度。

表2 不同尺寸图像处理速度比较Tab.2 Comparison of different size of the image processing speed
[1]赵娟,孙澎涛.基于像素级的图像融合[J].长春工程学院学报,2011,12(2):106-108 ZHAO Juan,SUN Peng-tao.The image fusioin based on pixel-level[J].J.C h angchun Ins t.T ech ,2011,12(2):106-108
[2]Chaver D,Prieto M,Pinuel L,et al.Parallel Wavelet Transform for Large ScaleimageProcessing [C]//Proc of Parallel and Distributed Processing Symposium.2002:4-9.
[3]Owens J,LuebkeD,Govindaraju N.A Survey of General Purpose Computation on Graphics Hardware[J].Computer Graphics Forum,2007,26(1):80-113.
[4]李红,吴粉侠,赵蓓娟.基于结构相似性的多源图像融合[J].咸阳师范学院学报,2012,27(6):45-48.LI Hong,WU Fen-xia,ZHAO Pei-juan.Multi-source image fusion based on structural similarity[J].Journal of Xianyang Normal University,2012,27(6):45-48.
[5]仇德元.GPUGPU编程技术[M].北京:机械工业出版社,2012.
[6]吴粉侠,李红.GPU实现的椒盐噪声自适应中值滤波算法[J].咸阳师范学院学报,2013,28(4):47-51.WU Fen-xia,LI Hong.Improved adaptive filtering algorithm based on programmable GPU[J].Journal of Xianyang Normal University,2013,28(4):47-51.
[7]CUDA programming guide Ver2.0{EB/OL}.[2009-12-29].http://developer.nvidia.com/object/cuda_2_0downloads.html.
[8]敬忠良,肖刚,李振华.图像融合理论与应用[M].北京:高等教育出版社,2007.
