具有MUX 模式的新型LUT 结构及其优化算法
2013-12-23郭旭峰王作建
郭旭峰,王作建,李 明,于 芳
1)中国科学院微电子研究所,北京100029;2)中国科学院大学 物理学院,北京100049;3)飘石科技有限公司,北京100029
多路选择器(multiplexer,MUX)作为数字电路系统中构建数据通路的常用组件,被广泛用于各种现场可编程门阵列(field programmable gate array,FPGA)设计中,如处理器、各种总线结构、网络交换电路和数据加解密电路等. 根据Altera 公司对120 个实用设计的测试分析[1],用于MUX 实现的平均面积占用率达25%. 可见,MUX 是FPGA结构设计和电子设计自动化(electronic design automation,EDA)优化算法的重要考虑对象[2].
硬件描述语言(hardware description language,HDL)是目前FPGA 最主要的设计方式[3-5]. HDL源文件中大量使用的条件运算符“?:”及case,ifelse 等分支语句是网表中MUX 的直接来源. 理论上MUX 可先打散为基本逻辑门,再经逻辑优化和工艺映射后生成工艺相关的网表[6-8],但事实上为有利于总线结构的生成和高效利用FPGA 内部的MUXFX 资源[9],MUX 优化往往在逻辑优化前进行[10]. 现普遍使用的基于4 输入查找表(look-up table,LUT)结构的FPGA[11],可由1 个LUT 实现1 个2 选1 的MUX2,但LUT 的4 个输入端只利用了3 个,即LUT 内部配置单元有效利用的数目为8个(总数为16)[12],半数逻辑被浪费. 而对于一个4 选1 的MUX4,其输入数最小为6,无法由1 个LUT 来实现. 图1 (a)是含MUXF5 资源的FPGA 实现MUX4 的方式之一,从中可知,两个LUT 同样都存在半数逻辑的浪费. 图1 (b)是文献[10]提出的一种较紧凑的MUX4 实现方式,其实现面积较小,但信号需经两级LUT 延迟,时序性较差.

图1 MUX4 的两种实现方式Fig.1 Two way of MUX4 implementation
本研究提出M-LUT 结构,并设计配套的优化算法. 该新型LUT 结构在传统4-LUT 结构的基础上进行微小改动而得,它能在兼具传统4-LUT 功能的基础上新增MUX 模式,仅需1 个配置为MUX 模式的M-LUT 即可实现1 个MUX4,大幅提高了实现MUX 所需的逻辑资源利用率,同时将MUX4 的延迟缩小到一级LUT 延迟,有效改善了电路性能.
1 M-LUT 结构及其模式配置
图2 (a)为本研究提出的M-LUT 结构. 其中,灰框外是传统4-LUT 结构,灰框内是新增结构,包括1 个模式配置单元MODE,2 个由MODE 控制的N 型管开关SW1、SW2及2 个信号输入端D2和D3.图2 (b)是图2 (a)对应的原理图,从中可见,传统4-LUT 内部本身就有M0—M4这几个MUX4. M-LUT结构的核心思想是尽可能复用自身的MUX4 来提高实现MUX 的逻辑利用率. 由于M0—M3的输入与配置单元是硬连接,欠灵活性,复用代价较大,故本研究的M-LUT 通过复用M4方式实现.
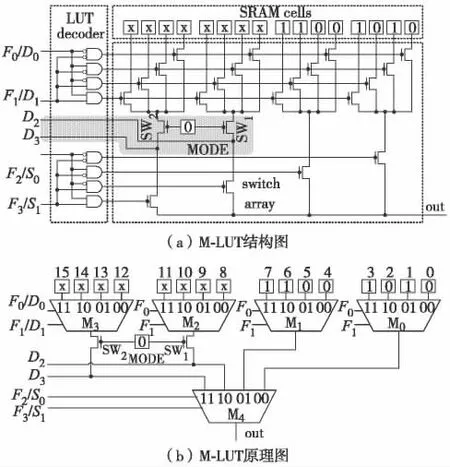
图2 M-LUT 结构及MUX 模式配置方案Fig.2 M-LUT construct and MUX mode configuration
M-LUT 的MUX 模式配置方案为:
1)配置单元MODE=0,则开关SW1和SW2处于开路状态,D2和D3作为M4的两路数据信号;
2)接入M0的配置单元配置为1010,则M0的输出信号将等于D0,作为M4的一路数据信号;
3)接入M1的配置单元配置为1100,则M1的输出信号将等于D1,作为M4的一路数据信号;
4)S1和S0分别作为M4的两个控制信号.
经上述配置,仅需1 个M-LUT 就实现了1 个MUX4 的功能,且电路延迟仅为1 级LUT 延迟.
M-LUT 的普通模式配置方案为:配置单元MODE=1,则开关SW1和SW2处于通路状态,同时令D2和D3输入端悬空. 经上述配置后M-LUT 即退化为传统4-LUT 模式.
图2 (a)中,配置单元MODE 为典型的6 管SRAM 单元结构[13],开关SW1和SW2皆为N 型晶体管,加上输入端D2和D3与外部的2 个布线开关,M-LUT 相对传统4-LUT 仅增加了10 个晶体管. 在自主研发的SOI 工艺FPGA VS300 型号中,1 个可配置逻辑块(configurable logic block,CLB)的等效晶体管数为16 588,内含4 个4-LUT. 采用M-LUT 结构后等效晶体管数为16 628,面积比仅为16 628/16 588≈1.002 4,该面积比将在后续对比实验中作为M-LUT 数目的加权系数,以便与传统4-LUT 数进行合理的比较.
2 MUX 优化
为充分且高效利用M-LUT,以减少逻辑资源占用,还需针对性地优化网表中的MUX. 首先定义几个基本概念:MUX 树,即除根节点外的全部节点均为单扇出MUX 的有根树;最大MUX 树,即若某个MUX 树不被其他MUX 树包含,则该树为最大MUX 树;MUX2 三联体,如图3 (a)电路结构由3个MUX2 节点构成的满二叉树. 经过对控制端重新编码,MUX2 三联体可转换为如图3 (b)的二进制MUX4,此二进制MUX4 恰可通过1 个M-LUT 实现. 此转换是本研究MUX 优化的基础.
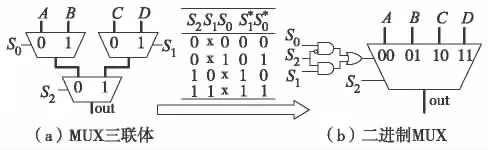
图3 MUX2 三联体转换为二进制MUX4Fig.3 MUX2 triplets to binary MUX4 recoding
MUX 优化算法的核心是将MUX 树尽可能转化为多个MUX2 三联体子树,然后由M-LUT 来实现.MUX 优化大体分为MUX 分组、MUX 树同构化和MUX 树重构与映射3 个阶段.
2.1 MUX 分组
MUX 分组即在网表中找出所有的最大MUX树,每个最大MUX 树为1 个MUX 分组. MUX 分组函数伪代码如图4. 遍历网表中所有MUX 节点,对于某个MUX 节点M,若其为多扇出节点,则M为根节点;若M 为单扇出节点且其后继非MUX,则M 为根节点. 将根节点命名为R,从R 出发递归寻找前驱节点,若前驱节点是单扇出MUX,则将此MUX 节点加入R 所在分组,迭代结束后即建立以R 为根节点的最大MUX 树.

图4 MUX 分组函数伪代码Fig.4 Pseudo codes of MUX grouping
2.2 MUX 树同构化
为便于调整MUX 树的结构,首先需对其进行同构化处理,即将MUX 树内的全部MUX 节点分解为最简单的MUX 结构—MUX2. 图5 (a)的MUX 树经同构化处理后转换为图5 (b)的结构.
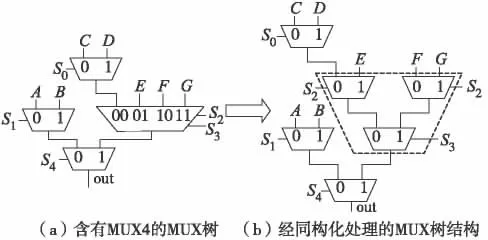
图5 MUX 树的同构化处理Fig.5 MUX tree unification
2.3 MUX 树重构与映射
经同构化处理后,就可重构MUX 树,保证将MUX 树尽可能多的划分出MUX2 三联体,然后将三联体映射为M-LUT,达到优化逻辑资源占用的目的.
MUX 树重构时,需先将1 个MUX2 携带其一个分支跨跃到其后继节点之后,另一分支则接入其后继节点. MUX 树映射的过程中需用到图6 的3 种基本重构形式. 图6 (a)MUX 树中M1携带左分支移动后,MUX 树重构为图6 (b)的MUX2 三联体.图6 (c)MUX 树中M1携带右分支移动后,MUX 树重构为图6 (d)结构,在树的末端形成一个MUX2三联体. 图6 (e)MUX 树中M2携带右分支移动后,MUX 树重构为图6 (f)结构,进一步令M3携带左分支移动后,MUX 树重构为图6 (g)结构,在树的末端形成一个MUX2 三联体.
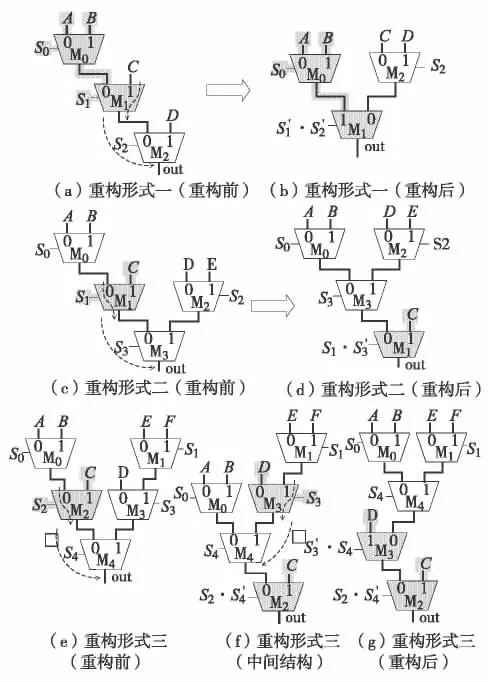
图6 三种基本的MUX 树重构方式Fig.6 3 basic methods of MUX tree reconstructing
MUX 树的映射是一个起始于根节点的递归过程,其算法伪代码如图7. 函数Mapping ()的返回值是尚未映射的MUX2 个数,显然Mapping ()函数的每次递归过程中待处理的MUX2 个数Nunmapped只会在1 到5 之间. 当Nunmapped为1 或2 时,不做任何处理;当Nunmapped=3 且MUX 子树为三联体时,直接将三联体映射为M-LUT;当Nunmapped=3 但MUX子树为图6 (a)结构时,由图6 第1 种方式重构为三联体后再映射至M-LUT;当Nunmapped取值4 或5时,MUX 子树必定是图6 (c)和图6 (e)结构,通过图6 的第2 和第3 种方式在子树末端重构出三联体映射至M-LUT,同时将零散的MUX2 节点归入MUX树尚未映射的部分以待进一步处理,因此映射算法可最大限度的将MUX2 映射至M-LUT.对整个MUX树映射完成后零散的MUX2 总数仅为1 或2 个.

图7 MUX 树映射算法伪代码Fig.7 Pseudo codes of MUX tree mapping algorithm
图8 (a)是MUX 树同构化示例中同构所得MUX 树,至少需5 个传统4-LUT. 通过前移M1重构变换为图8 (b)后,实现MUX 树主体仅需2 个M-LUT,大幅减少了逻辑资源的占用.

图8 MUX 重构与映射示例Fig.8 MUX tree reconstructing and mapping
由前述内容可知,在三联体转化为二进制MUX4 及MUX 树重构过程中都会引入额外的控制逻辑,但MUX 树主体优化后减小的面积可抵消此新增的控制逻辑面积. 尤其当MUX 树为总线结构时,总线的每一位都共享同一套控制逻辑,控制逻辑面积的增大被每一位分摊弱化,突显了此时MUX 树主体每一位面积都有所减小的优势将.
3 实验结果与分析
为验证M-LUT 及其配套优化算法的优化效果,随机抽取20 个OpenCores 官方发布的实用设计进行对比实验. OpenCores 是著名的开源芯片设计组织,其项目大多采用HDL 语言开发,因此以这些设计作为测试用例最能反映被测项目的应用效果. 测试时使用自主开发的RTL 级FPGA 综合工具—HQFPGA,实验对比项目包括LUT 数、时钟频率、运行时间及内存占用. 表1 为实验结果,比例项指第2 组结果与第1 组结果对应项目的比值. 需要说明的是,为反映M-LUT 结构内新增晶体管带来的面积影响,方便与传统4-LUT 占用数进行合理比较,M-LUT 数目乘以第1 节计算得出的面积加权系数1.002 4.
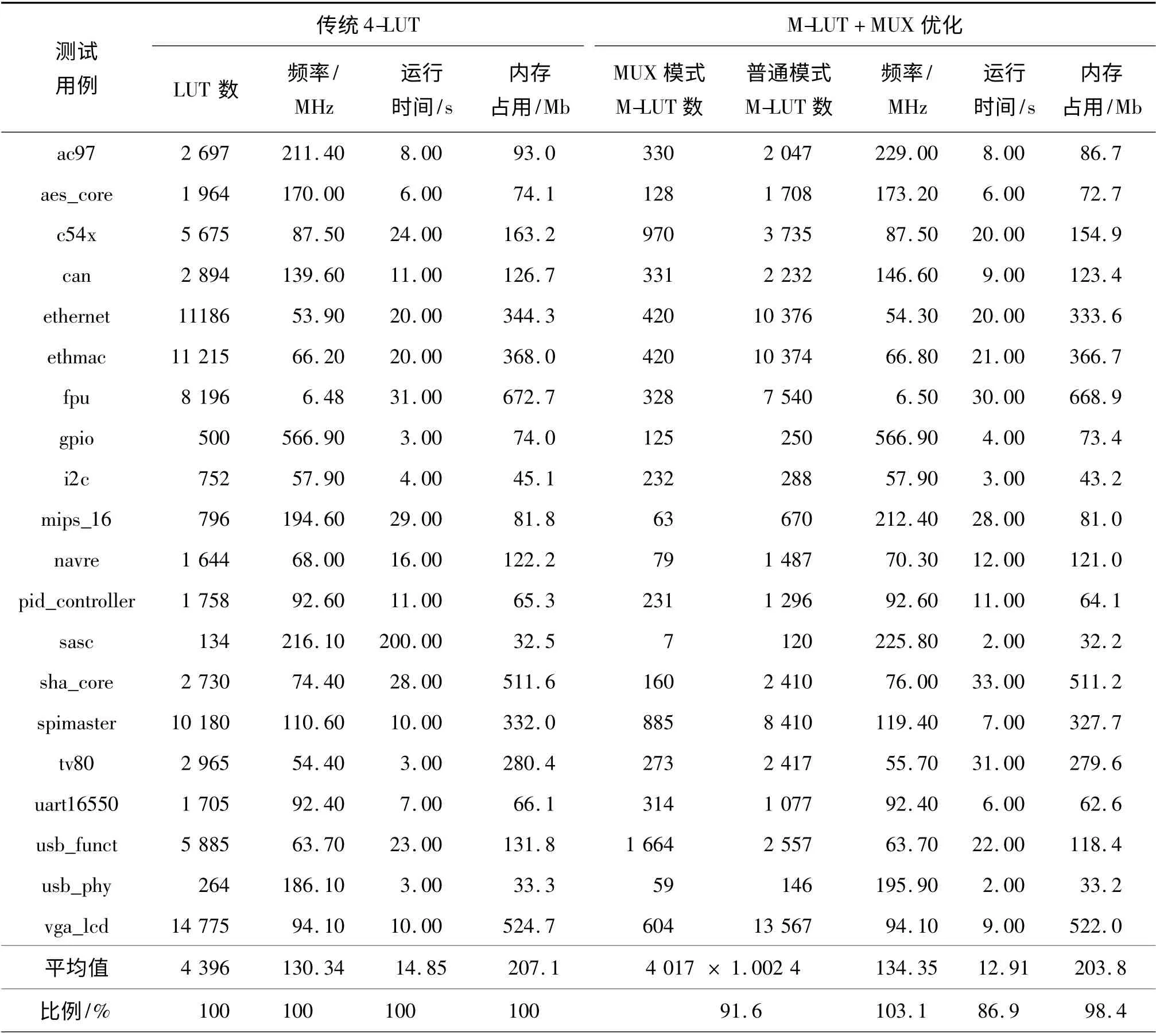
表1 采用M-LUT 加优化算法与采用传统4-LUT 的综合结果对比Table 1 Comparison of M-LUT plus optimization algorithm and traditional 4-LUT results
实验结果显示,与采用传统4-LUT 结构相比,采用M-LUT 结构加配套优化算法的综合结果,在LUT 资源占用上平均减少了8.4%,电路时钟频率平均提高了3.1%,充分证明M-LUT 作为MUX 实现方案的面积和延迟优势. 另外,综合过程的运行时间和内存占用也分别有13.1%和1.6%的改善,这主要得益于MUX 优化后网表结构得到简化,缩短了后续逻辑优化的运行时间.
结 语
本研究针对传统4-LUT 实现MUX 逻辑利用率低,延迟略大的不足,提出具有MUX 模式的新型LUT 结构—M-LUT. M-LUT 在传统4-LUT 结构基础上进行微小改动而得,在兼容传统4-LUT 功能的基础上新增了MUX 模式,仅需一个配置为MUX 模式的M-LUT 即可实现一个MUX4,同时将MUX4 的延迟缩小到一级LUT 延迟. 为充分利用M-LUT 的优点,本研究设计了配套的MUX 优化算法. 实验结果显示,采用M-LUT 加配套优化算法后,LUT 资源占用平均减少8.4%,同时电路时钟频率平均提高了3.1%,综合过程的运行时间和内存占用也获得小幅改善.
/ References:
[1] Altera Corporation. FPGA Performance Benchmarking Methodology [M/OL]. San Jose (USA):Altera Corporation,2007. [2012-12-15]. http://www. altera.com.cn/literature/wp/wpfpgapbm.pdf.
[2]Anderson J H,Wang Q. Area-efficient FPGA logic elements:architecture and synthesis [C]// The 16th Asia and South Pacific Design Automation Conference (ASPDAC). Yokohama (Japan):IEEE Press,2011:369-375.
[3]Liu Fuqi. Verilog HDL Design and Practice [M]. Beijing:Beihang University Press,2012.(in Chinese)刘福奇. Verilog HDL 设计与实战[M]. 北京:北京航空航天大学出版社,2012.
[4]Samir Palnitkar. Verilog HDL:A Guide to Digital Design and Synthesis [M]. NewJersey (USA):Prentice Hall PTR,2003.
[5]Qi Xiaolei,Cai Xueliang,Sun Dewei. Methods and principia of FPGA design using Veriog HDL [J]. Electronic Test,2008(3):67-71.(in Chinese)祁晓磊,蔡学良,孙德玮. 用Verilog HDL 进行FPGA设计的原则与方法[J]. 电子测试,2008(3):67-71.
[6]Cong J J,Minkovich K. Optimality study of logic synthesis for LUT-based FPGAs [J]. IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems,2007,26(2):230-239.
[7]Chen Zhihui. FPGA Technology Mapping Algorithm Research [D]. Shanghai:Fudan University,2011.(in Chinese)陈志辉. FPGA 工艺映射算法研究[D]. 上海:复旦大学,2011.
[8] Yang Jingqiu. LUT-based FPGA Technology Mapping Algorithm Research [D]. Chengdu:University of Electronic Science and Technology,2006.(in Chinese)杨劲秋. 基于LUT 结构的FPGA 的工艺映射算法的研究[D]. 成都:电子科技大学,2006.
[9]Ken Chapman. Multiplexer Selection [M/OL]. San Jose(USA):Xilinx Inc. 2008. [2012-12-15]. http://www. xilinx. com/support/documentation/white _ papers/wp274.pdf.
[10]Metzgen P,Nancekievill D. Multiplexer restructuring for FPGA implementation cost reduction [C]// Proceedings in the 42nd Design Automation Conference. New York:Association for Computing Machinery,2005:421-426.
[11]Gao Haixia. Analysis of the effect of LUT size on FPGA area and delay using theoretical derivations [C]// The 6th International Symposium on Quality of Electronic Design (ISQED 2005). San Jose (USA):IEEE Computer Society,2005:370-374.
[12]Betz V,Marquardt A,Rose J. Architecture and CAD for Deep-Submicron FPGAs [M]. Wang Lingli,Yang Meng,Zhou Xuegong,trans. Beijing:Publishing House of Electronics Industry,2008:10-11.(in Chinese)贝 兹,马夸特,罗 斯. 深亚微米FPGA 结构与CAD 设计[M]. 王伶俐,杨 萌,周学功,译. 北京:电子工业出版社,2008:10-11.
[13]Li Shaojun,Wang Ziou,Wang Yuanyuan,et al. A novel 6-T SRAM cell design with high reliability and low power [J]. Modern Electronics Technique,2011,34(16):123-125,130.(in Chinese)李少君,王子欧,王媛媛,等. 新型高可靠性低功耗6 管SRAM 单元设计[J]. 现代电子技术,2011,34(16):123-125,130.
