基于关联关系的数字家庭服务资源推荐体系
2013-12-23聂规划游怀杰
聂规划,游怀杰,孟 洁
(武汉理工大学 经济学院,湖北 武汉430070)
随着三网融合进程的不断加快,数字家庭产业开始迅猛发展。除了提供各种多媒体、物联网服务外,数字家庭还提供包含数字高清交互购物平台、家庭社群互动、数字家庭文化公益、数字医疗和智能监控等在内的诸多服务。然而,随着数字家庭服务内容的不断扩充,用户量不断增加,运营商和用户所面对的信息量巨大,用户要想从大量应用服务中找到自己所需要的,或潜在感兴趣的服务变得更加困难。对运营商来说,如何从纷杂的信息中发现用户消费的特点,并为用户提供个性化的服务以加深用户体验成为其必须考虑的问题。因此,建立一个面向数字家庭服务资源的推荐系统成为必然趋势。
目前主流的推荐方法有协同过滤推荐,基于内容的推荐和关联规则推荐等[1],笔者主要讨论关联规则推荐在数字家庭领域的应用。关联规则挖掘是近年来知识发现研究中一个很重要的课题,自1993 年AGRAWAL 等首次提出关联规则及Apriori 算法[2]以来,出现了很多基于它的改进算法,如基于划分的方法,基于hash 的方法,基于采样的方法和减少交易个数的方法等。此外,也有学者探索出全新的挖掘算法,以避开Apriori 算法自身的缺陷,如HAN 等提出的FP-Growth 算法等。还有一些学者提出了某些模型,注重对所挖掘规则的价值进行评估[3]。
当今的互联网领域凭借自身获取信息全面与实时的优势,在关联推荐方面已有比较成熟的应用。如亚马逊就提供了包括“经常一起购买的商品”,“购买此商品的顾客也同时购买”等卓有成效的关联推荐;另外,京东商城、优酷、豆瓣等也提供各自的关联推荐服务。然而,由于数字家庭还处于发展阶段,各种软硬件技术还不够成熟,目前很少有学者进行数字家庭领域的关联推荐研究,大部分仍停留在对互联网商品、数字电视节目的推荐上。如赵宏霞等研究单一商品不同时间下需求量的关联性[4],王磊等研究周期性出现的不同商品之间的空间关联性[5],LAI 等提出基于云的数字电视节目推荐平台[6],徐江山等提出利用Rankboost 排序算法、Bayes 统计算法和简单统计算法3 种基于统计模型的算法实现数字电视用户特征的提取与节目推荐[7]。目前,几乎还没有针对数字家庭领域的其他服务类型进行关联推荐的方法研究。因此,有必要立足于数字家庭自身的技术特点,所提供的服务类型和需要达到的推荐目标等,应用合适的关联技术来建立面向数字家庭的关联推荐体系。
1 数字家庭与关联推荐技术
数字家庭因其特有的应用技术与服务,同互联网等领域鲜明地区分开来,但其并不完善的用户交互渠道也决定了在现阶段它并不适合所有推荐技术。关联推荐基于其共性推荐的特征,用户的消费记录就是其数据源,简单易得,适合为数字家庭用户发现其感兴趣的服务资源。
笔者采用的关联推荐技术主要包括两种:关联规则推荐和时序关联规则推荐。前者通过对用户消费记录进行挖掘,找出经常被一起消费的服务资源。若大量用户单次消费了相同的某几种服务资源,可能表明这几种服务资源间存在某种关联关系,用户可能存在进行一次性消费的需要,如牛奶与面包。在数字家庭中主要考虑在数字高清交互购物平台中进行应用。后者则考虑了用户消费的时间先后顺序,以关联规则挖掘为基础,并考虑消费时间先后与间隔来获得时序关联规则,并根据规则进行推荐。当用户消费某时序规则中的第一个服务资源时,推荐系统则将相应规则中的下一个或若干个服务资源推荐给用户。比如在数字医疗中,数字家庭将提供包括电视挂号、医院查询、医师介绍、医院地图等服务,这组服务在被使用时大多存在某种时间先后顺序,这也就决定了建立基于时序关联规则推荐的必要性。
2 数字家庭服务资源关联推荐体系的设计
根据数字家庭技术特征和用户的消费特点,笔者提出了数字家庭服务资源关联推荐体系。通过结合关联规则推荐和时序关联规则推荐两种主要形式,以用户交易库和服务资源库为主要数据源,利用相应的挖掘技术进行关联规则挖掘,并经由推荐模块进行推荐资源输出。其体系结构如图1 所示。
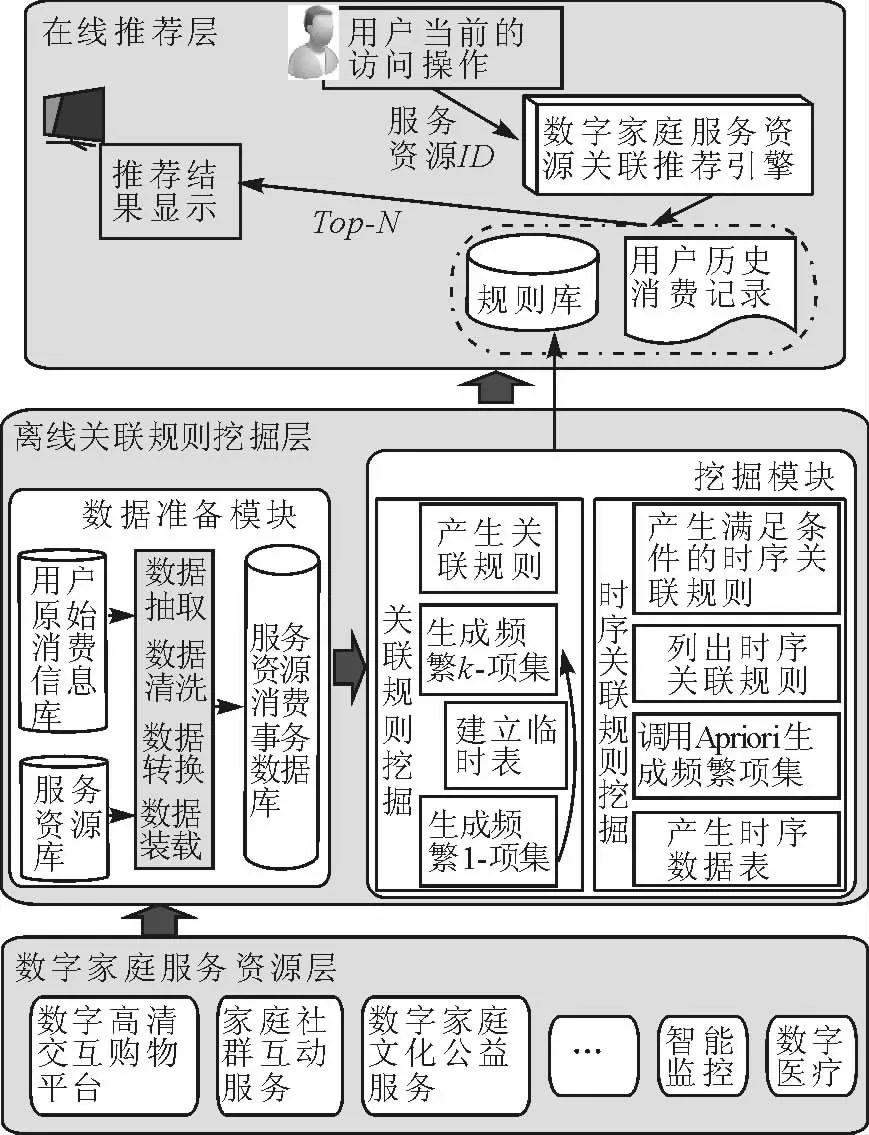
图1 数字家庭服务资源关联推荐系统体系结构
该结构分为3 个部分,即服务资源层、离线关联规则挖掘层和在线推荐层。服务资源层主要是数字家庭系统所提供的各类服务资源,是进行挖掘和推荐的基础。离线关联规则挖掘层是进行规则挖掘的过程,首先采用数据仓库技术对用户原始消费数据进行预处理产生标准消费数据,然后利用挖掘模块从数据仓库中提取相关数据进行关联规则挖掘和时序关联规则挖掘,最后将生成的规则存入关联规则库和时序关联规则库。在线推荐层是与用户进行实时交互,根据用户选择消费的服务资源,将离线部分生成的关联规则与数据库中该用户的历史消费数据信息进行分析,剔除用户已消费过的服务资源,产生最终推荐,并利用数字电视终端将推荐结果推送给用户。
3 离线关联规则挖掘
3.1 系统阈值的设定
在进行(时序)关联规则挖掘前,首先需要确定最小支持度和最小置信度两个阈值。在Apriori算法中,支持度是对关联规则重要性的衡量,表示该规则出现的频度;置信度则是对关联规则准确度的衡量,表示该规则的有趣性。另外,针对数字家庭自身的特征,用户一般很少一次性消费多项服务资源,而是存在一定的时间间隔,这与进行关联规则挖掘所需要的数据要求不符。因此,在进行系统阈值设定时,需要确定一个时间阈值,以预设定的时间为单位采集用户的消费项来组成事务,如以每两天为采集单元。最后还要设定提供推荐时的TOP-N 值。
3.2 数据准备
数字家庭关联推荐技术所需要的数据源主要有服务资源库和所有用户的消费记录,后者包含消费的资源ID 和消费时间。由于涉及到多个数据源,多种数据类型,同时也面临许多不完整的、有噪声的和不一致的脏数据,因此在挖掘模块进行挖掘工作之前,系统还需要对源数据进行预处理。数据预处理的主要任务是数据清洗、数据集成、数据转换和数据归约。主要完成以下目标:扫描用户消费数据表,以每两天为采集单元整合单用户的消费项目,生成事务表,事务表包括唯一的ID、消费项目及消费时间;丢弃只包含一个项目的事务;并将各事务中的消费项按字典序排列。而进行时序规则挖掘的事务则要求用一个二元组<I,T >表示记录中的每个项(即时序项),其中,I为项,T 为该时序项的时间戳,每一条记录中的时序项以各自时间戳的大小进行升序排列。
3.3 关联规则挖掘
关联规则挖掘的基础是Apriori 经典算法,而针对该算法的一些固有缺陷与不足[8],笔者采用基于临时表的Apriori 改进算法[9],即通过将(k-1)-项集的首项集加入到临时表中,再把尾项与其不同的其他项集加入到表中,生成k-项集,再计算k-项集的频度,若大于最小支持度,则认定其为频繁项并保存,否则删除,依次循环,直至生成所有的频繁项。算法步骤如下:
关联规则挖掘要输入用户消费事务数据库D;最小支持度阈值min_sup;最小置信度阈值min_conf。输出关联规则。
(1)扫描用户消费事务数据库D,计算各1-项集出现的频次,找到所有支持度大于最小支持度阈值的项集,即频繁1-项集;并建立临时数据库表D1;
(2)删除不存在频繁(k-1)-项集的事务,减少下次扫描数据库的记录数;
(3)将频繁(k-1)-项集按字典序进行两两连接,产生候选k-项集;
(4)从数据库中删除其中仅含(k-1)项的项集,减少下次扫描数据库的记录数;
(5)扫描数据库,找到所有支持度大于最小支持度阈值的项集,即频繁k-项集,更新临时数据库表Dk;重复步骤(2)~步骤(5);
(6)根据得到的频繁k-项集建立关联规则,形如A B,计算规则置信度,若大于最小置信度阈值,则认定为有意义的关联规则。
3.4 时序关联规则挖掘
输入用户消费服务资源的事务数据库D;认定兴趣连接时间段TL;最小支持度阈值min_sup;最小置信度阈值min_conf。输出时序关联规则。
(1)调用预定义算法,将输入的原始关系型数据表转换为时序数据表。将用户消费的服务资源记录转化成形如<Ii,Ti>的样式,Ii为项集I的第i 个消费的资源,Ti为消费的时间;
(2)调用Apriori 算法,对步骤(1)所生成的时序数据表进行挖掘,找出所有支持度大于预设最小支持度阈值的频繁项集;
(3)对于步骤(2)找出的频繁项集,经过数据库扫描得到包含该项集的所有记录,组成临时数据表;
(4)列出该项集所有可能的时序关联规则,对每一个时序关联规则进行如下操作,找到所有满足最小支持度、置信度的时序关联规则[10]。①将输入的时序关联规则按照“ ”符拆分为左部项集L和右部项集R;②定位到临时数据表的第i 条记录(i =1,i+ +),提取对应于项集L 和项集R 的时序项(集)<L,TLi>和<R,TRi>;③计算时序项之间的时间差:△Ti= TRi-TLi,若△Ti>0,保存该结果,返回第②步,直至处理完临时数据表中的所有记录;④将所有保存的结果进行时间规则判别运算,输出该时序关联规则满足最小支持度,且时间差△Ti在TL 内的时序关联规则。
4 在线推荐设计
系统对用户进行在线推荐时,首先提取用户当前消费服务资源的ID 并遍历规则表,找出左部项为该ID 的所有关联规则,并提取相应右部项的资源ID作为候选推荐集;同时识别用户,获取该用户的历史消费记录;然后将候选推荐集和用户的历史消费记录进行去重操作,获得最终的推荐集;最后将结果按置信度排序,按所设定的系统阈值把TOP-N 返回给用户,其具体推荐流程如图2 所示。

图2 在线推荐流程
在数字家庭中,关联推荐主要用于如图3 所示的业务场景:①时序关联的应用。用户选择进入“数字医疗”频道,当用户点击某个医院的标识时,系统可以通过由时序关联挖掘出的有效规则进行判断,大部分用户选定医院后都会在TL 时间内选择电视挂号,于是系统自动为用户推送电视挂号服务,用户可以在了解医师情况后进行挂号,然后按时前往医院就医。②电子商务应用。用户进入数字高清交互购物平台,浏览各商品资源,当用户有意于某商品而进入该单品浏览界面时,系统根据关联规则挖掘出的规则库内容,查找与该商品规则匹配的右部项,并进行推荐;在达成交易后同样进行一次推荐项的推送。

图3 关联推荐方法应用的业务场景示例
5 结论
笔者以知识发现中的关联规则挖掘理论为基础,针对数字家庭的特点,设计了基于时序关联规则的推荐体系。所提出的关联关系挖掘方法能满足关联推荐服务的基本需求,达到为用户提供关联服务资源的基本目的,为日后建立数字家庭智能推荐系统提供有力的技术支撑,有助于提高数字家庭用户的消费体验。
[1] 刘建国,周涛,汪秉宏.个性化推荐系统的研究进展[J].自然科学进展,2009,19(1):1-15.
[2] AGRAWAL R,IMIELINSKI T,SWAMI A. Mining association rules between sets of items in large database[C]// Proc of the 1993 ACM SIGMOD Conference.Washington:[s.n.],1993:207-216.
[3] ZAILANI A,TUTUT H,NORAZIAH A.Mining significant association rules from educational data using critical relative support approach [J]. Procedia-Social and Behavioral Sciences,2011,28(1):97-101.
[4] 赵宏霞,杨皎平,郭嗣琮.基于时序关联规则的客户需求预测方法研究[J]. 科技和产业,2004,4(11):22-26.
[5] 王磊,谭跃进. 基于聚类的快速时域关联规则发现算法[J].计算机仿真,2005,22(7):36-39.
[6] LAI C F,CHANG J H,HUB C C,et al. A cloud-based program recommendation system for digital TV platforms[J]. Future Generation Computer Systems,2011,27(3):823-835.
[7] 徐江山,卢增祥,路海明.数字电视节目推荐系统中的统计算法[J].清华大学学报:自然科学版,2008,48(10):1562-1564.
[8] 张云涛,于治楼,张化祥.关联规则中频繁项集高效挖掘的研究[J]. 计算机工程与应用,2011,47(3):139-141.
[9] 高伟峰,胡勇,胡江洪.基于临时表的Apriori 改进算法[J].计算机与信息技术,2005(11):1-3.
[10]章杰鑫,张烈平.基于时序关联规则的商品需求预测[J].计算机工程,2009,35(22):65-67.
