一种模式匹配和统计学习相结合的文本情感分类方法
2013-12-19潘正高
潘正高,张 磊
1.宿州学院信息工程学院,安徽宿州,234000;2.宿州学院智能信息处理重点实验室,安徽宿州,234000 3.宿州市第二中学,安徽宿州,234000
随着Web2.0技术在互联网上的广泛应用,网络上出现了大量的评论信息,这些信息大多以文本的形式出现。通过文本情感分析技术可以从网络评论信息中自动地分析评论者的立场、观点,为政府、企业决策提供重要的参考信息。
文本情感分析主要包括情感评价信息的抽取和情感倾向性分类,其中,情感倾向性分类可以转化为文本分类问题。本文在充分考虑网络在线评论的情感词语之间存在一些固定的搭配规则,提出了一种基于模式匹配和统计学习相结合的文本情感分类方法。
1 文本情感分析的相关研究
文本情感分析按照研究对象的粒度可以分为词语级、句子级及篇章级的情感分析[1]。其中,词语的粒度最小,是文本情感分析的基础。词语的情感分析主要有基于词典和基于语料库两类方法。
基于词典的方法是利用语义词典中的语义关系,计算词语w与语义词典中种子情感词语的情感倾向相似度来确定w的情感倾向。常用的语义词典有HowNet[2]、WordNet[3]、SentiwordNet[4]等。设语义词典的情感种子集为Seed_Set={WP,WN},其中的WP和WN分别表示褒义和贬义种子词集合,则词语w的情感倾向性可以定义为:
(1)
其中wpi∈WP,wnj∈WN,sim(w1,w2)表示两个词的语义相似度,M表示种子集中褒义词的个数,L表示种子集中贬义词的个数。
基于语料库的方法是通过统计词语w和种子情感词的共现信息来计算w的情感倾向度的。该类方法以Turney提出的逐点互信息 (Point-wise Mutual Information,PMI)方法[5]最具代表性。该方法将两个词的逐点互信息PMI定义为:
(2)
其中P(wi)代表词语wi在语料中出现的概率,P(w1,w2)表示词w1、w2同时出现在语料中的概率。
B.Pang[7]采用机器学习的方法,使用Unigram、Bigram、part of speech information以及它们的位置作为特征,对电影评论进行正、反两类情感倾向性分析。Qiang Ye[8]等采用基于信息检索的逐点互信息(PMI)方法对中文评论文档中的情感词进行统计识别,将文档中情感词的平均语义倾向性作为文档的整体语义倾向性。
2 基于机器学习的文本情感分类方法
基于机器学习的文本情感分类方法一般需要先提取情感文本的特征来构建特征向量空间,再使用机器学习算法完成文本情感分类。情感文本的特征提取将在后面详细介绍,本节只讨论最大熵模型、贝叶斯分类器、支持向量机等几个常用于文本情感分类的机器学习方法。
最大熵方法(Maximum Entropy, ME)的主要思想是在只掌握关于未知分布的部分知识时,应该选取符合这些知识且熵值最大的概率分布。ME用于文本情感分类时,从训练集中选择“特征词-类别”作为特征集,将文档d的类别指定为c,以使得式(3)最大。
(3)
其中Z(d)是归一化因子:
(4)
Fi,c(d,c)是值为0或1的二值特征函数,表示是否包含某特征;λi,c是特征函数的权重,其值可以通过IIS(Improved Iterative Scaling)算法在训练集上学习得到。
贝叶斯(Naive Bayes,NB)理论是建立在特征互相独立前提下的,通过贝叶斯公式(5)计算文档di属于类别cj(j=1,2)的条件概率,其中j=1,2,分别表示文本的褒、贬情感倾向。
(5)
其中P(di)是选择文档di的概率,对分类无影响。P(cj)表示一篇文档属于cj的概率,P(di|cj)可以通过条件概率求得。通过训练已标注的语料,计算文档di中的每个特征词fj在每一个类的值P(fj|cj),则:
(6)
支持向量机(Support Vector Machine, SVM)是一种常用于分类问题的基于风险最小化原理的机器学习方法。基于SVM的情感分类,就是要在训练样本中求一个能够把样本点分开的线性函数f(x)=w·x+b,在yi[w·x+b]≥±1约束下间隔最大,其优化问题为:
(7)
s.t.yi[
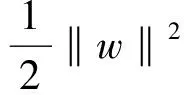
研究结果表明[9],SVM和NB方法在文本分类时表现出较好的性能。
3 基于模式匹配和统计学习的文本情感分类
3.1 情感词语搭配模式的提取
传统的基于机器学习的情感分类方法按词语的统计信息进行特征选择,没有考虑文本的情感特征,容易出现特征维度灾难和数据稀疏问题,分类性能很难进一步提高[10]。事实上,评论文本中包含了丰富的情感信息,分析评论文本的结构,提取蕴含情感类别的信息作为特征,会提高文本情感分类的效果。
通过情感语料库的分析发现,基于主题的情感文本中名词、动词、形容词、副词构成一些固定的搭配规则。王素格的研究表明,情感分析应主要考察形容词、副词,其他类型的词语只在上下文中体现情感倾向性[11]。基于文献[12]研究的基础上,考虑网络在线评论篇幅较小,笔者将词语搭配模式的窗口长度设置为3,并归纳出如表1所示的8种模式。其中a表示形容词,d表示副词,v表示动词,n表示名词,fd表示否定词。
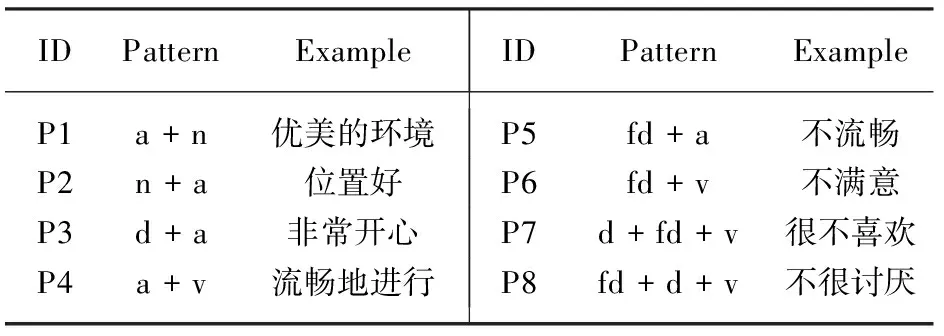
表1 8种词语搭配模式
3.2 评论文本的情感倾向度计算
评论文本中词语的情感倾向性要以种子情感词为基础,而不同的评论主题存在不同的种子情感词集。本文依据Hownet基础情感词表,对酒店领域网络在线评论语料进行高频情感词语统计,人工选择其中的462个基准词语构建酒店领域评论基础情感词典(Hotel Review Sentiment Library, HRSL)。其中正向情感词语244个,负向词语218个。
对于情感基准词以外的词语,其语义情感倾向性计算采用刘群等提出方法[13],如式(8):
(8)
其中α是一个可调节参数,Dis(w1,w2)是词语w1、w2在义原层次树中的距离,由义原层次树的深度和密度决定,是一个常量。
在确定词语之间相似度计算方法的基础上,可以用本文前面介绍的(1)式来得到任意一个词语w的语义倾向性度量值。
与情感词语相同,匹配成功后的模式也需要计算特征的倾向值。考虑到程度副词、否定词对情感倾向性的影响情况不同,需要对表1中的8个模式分别进行情感倾向性计算。因为模式P1、P2中的名词不改变情感极性,可以直接将形容词的极性作为模式的情感极性。模式P3、P7和P8需要考虑程度副词对情感强度的影响,笔者按照程度的强弱将它们划分为“强”、“中”、“弱”三类,如“极其,非常”、“稍微,比较”、“有点,少许”,将每个等级依次设置为2、1、0.5。模式P4中的动词若带情感色彩,如“喜爱”、“讨厌”等,则按照模式P3方式来处理;若不带情感色彩,则按照模式P1方式来处理。模式P5、P6中的否定词则会改变后面形容词、动词的倾向性。
3.3 基于模式匹配和统计学习(Pattern matching and Statistics learning, PS)的文本情感分类方法
Web评论文本中普遍存在表1所示的各种情感词语搭配模式,以这些情感模式为特征,结合传统的机器学习算法,笔者提出了基于模式匹配和统计学习的文本情感分类方法,其工作流程如图1所示。
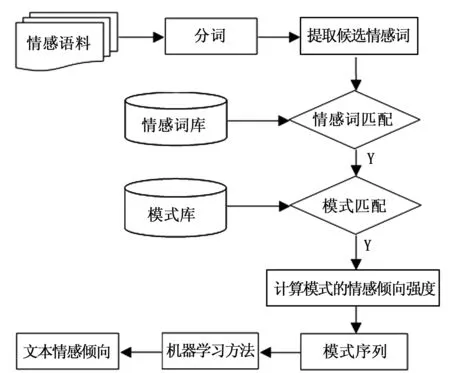
图1 PS方法流程图
首先对训练评论文本进行情感倾向人工标注;从已经标注情感的文本中提取形容词、动词、副词、否定词、转折连词等情感相关词语构成情感词库;再提取在训练集中对情感分类贡献度大的情感词语组合构成模式库。测试集中的文本经分词后,按照匹配、生成情感模式特征,计算匹配成功的模式的情感倾向值,得到模式特征序列,最后使用机器学习方法得到文本情感倾向。
4 实验结果及分析
本文选择谭松波[14]提供的酒店类网络评论语料,该数据集包括已经标注情感标签的正负评论各2 000篇,是第三届中文倾向性分析评测使用的评测语料之一。实验随机选取正负各1 300篇作为训练集,剩下的正负各700篇作为测试集。
本文采用两种方法来提取特征:1)N-gram的特征选择方法,即从文本中无序地选择词语,分别按照Unigram、Bigram、Trigram三种方式提取特征;2)再用本文介绍的模式匹配(Pattern Matching, PM)结合N-gram的方法提取特征。分类器采用SVM进行对比分类实验。实验在Matlab7.1下进行,使用SVM toolbox工具包,核函数选择Sigmoid函数,设置a=1,b=1。
采用准确率和召回率评价分类的性能,用PP、RP表示正向准确率、召回率,用PN、RN表示反向准确率、召回率。实验结果如表2、表3所示。
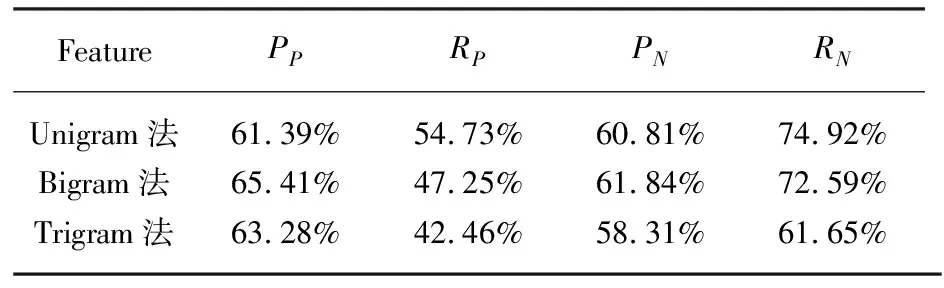
表2 N-gram的分类性能
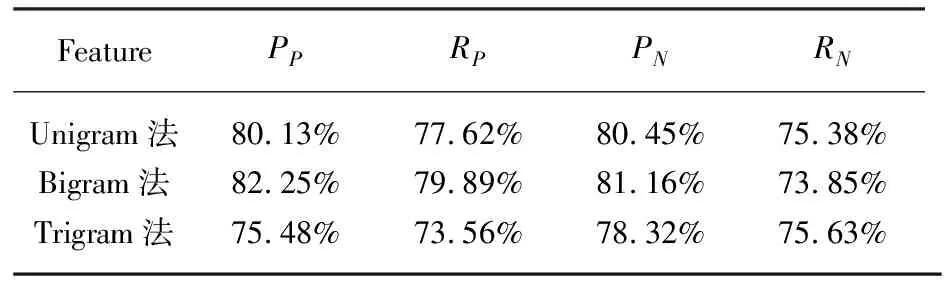
表3 PM+N-gram的分类性能
从表2和表3的分类结果中可以看出:1)N-gram的分类方法的准确率、召回率都很差,这与网络评论文本语言使用不规范,表达风格多样化有关。2)采用Bigram方法作为特征项分类要比其他两种分类效果好,说明评论语料中2个词语构成的情感词概率较大。3)PM+N-gram方法在准确率、召回率两个方面都比N-gram方法分类效果更好,其中,最好的准确率达82.25%,说明本文总结的8种词语搭配情感模式作为特征在情感分类中是有效的。
上述实验结果说明,文本情感分类时提取文本中的情感词语搭配模式特征,可以明显地提高分类的性能。
5 结束语
本文在分析网络评论文本中的情感词语之间存在的固定搭配模式的基础上,提出基于模式匹配和统计学习相结合的文本情感分类方法。该方法将N-gram与8种情感词语搭配模式相结合,从评论文本提取特征,再利用机器学习方法实现文本情感分类。实验结果显示,本文提出的这种文本情感分类方法,与传统机器学习方法相比,明显提高了情感分类的效果。
参考文献:
[1]昝红英,左维松,张坤丽,等.规则和统计相结合的情感分类研究[J].计算机工程与科学,2011,33(5):146-150
[2]董振东,董强.HowNet[EB/OL].[2012-10-22].http://www.keenage.com/html/c_index.html
[3]Fellbaum C.WordNet:An Electronic Lexical Database[M].Boston,America:MIT Press,1998:1-445
[4]Esuli A,Sebastiani F.SentiwordNet:A Publicly available lexical resource for Opinion mining[C]//In Proceedings of the 5th Conference on Language Resources and Evaluation.Genoa,Italy:European Language Resources Association,2006:417-422
[5]Turney P D.Thumbs up Or Thumbs Down? Semantic Orientation Applied to Unsupervised Classfication of Reviews[C]//Proceedings of 40th Annual Meeting of the Association for Computational Linguistics.Philadelphia:ACL,2002:417-424
[6]梅家驹,竺一鸣,高蕴琦,等.同义词辞林[M].2版,上海:上海辞书出版社,1996:1-607
[7]Pang B,Lee L,Vaithyananthan S.Thumbs up Sentiment classification using machine learning techniques[C]//Proceedings of the Conference on Empirical Methods in Natural Language Processing.Philadelphia,2002:79-86
[8]YE Qiang,Shi Wen,LI Yijun.Sentiment Classification for Movie Reviews in Chinese by Improved Semantic Oriented Approach[C]//Proceedings of the 39th Annual Hawaii International Conference on System Sciences:Vol.3,2006:53-57
[9]白鸽,左万利,赵乾坤.使用机器学习对汉语评论进行情感分类[J].吉林大学学报:理学版,2009,47(6):1260-1263
[10]万源.基于语义统计分析的网络舆情挖掘技术研究[D].武汉:武汉理工大学理学院,2012:56-75
[11]王素格.基于Web的评论文本情感分类问题[D].上海:上海大学计算机工程与科学学院,2008:20-36
[12]王素格,杨军玲,张武.自动获取汉语词语搭配[J].中文信息学报,2006,20(6):31-37
[13]刘群,李素建.基于《知网》的词汇语义相似度计算[C].北京:第三届汉语词汇语义学研讨会,2002:76-80
[14]谭松波.中文情感文本语料[EB/OL].[2012-05-18].http://www.searchforum.org.cn/tansongbo/corpus-senti.htm
